【数据库05】玩转SQL的高阶特性

前 言
作者简介:半旧518,长跑型选手,立志坚持写10年博客,专注于java后端
☕专栏简介:相当硬核,黑皮书《数据库系统概念》读书笔记,讲解:
1.数据库系统的基本概念(数据库设计过程、关系型数据库理论、数据库应用的设计与开发…)
2.大数据分析(大数据存储系统,键值存储,Nosql系统,MapReduce,Apache Spark,流数据和图数据库等…)
3.数据库系统的实现技术(数据存储结构,缓冲区管理,索引结构,查询执行算法,查询优化算法,事务的原子性、一致性、隔离型、持久性等基本概念,并发控制与故障恢复技术…)
4.并行和分布式数据库(集中式、客户-服务器、并行和分布式,基于云系统的计算机体系结构…)
5.更多数据库高级主题(LSM树及其变种、位图索引、空间索引、动态散列等索引结构的拓展,高级应用开发中的性能调整,应用程序移植和标准化,数据库与区块链等…)
文章简介:这篇文章将介绍如何使用通用程序设计来访问SQL的问题,接着介绍SQL的高级特性,从如过程性操作,触发器,SQL的递归查询和高级聚集特性。
文章目录
- 1.使用程序设计语言访问SQL
-
- 1.1 JDBC
-
- 1.1.1 连接到数据库
- 1.1.2 向数据库系统中传递SQL语句
- 1.1.3 异常与资源管理
- 1.1.4 获取查询结果
- 1.1.5 预备语句
- 1.1.6 可调用语句
- 1.1.7 元数据特性
- 1.1.8 其他特性
- 1.2 从Python访问数据库
- 1.3 ODBC
- 1.4 嵌入式SQL
- 2.函数和过程
-
- 2.1 声明及调用SQL函数和过程
- 2.2 用于过程和函数的语言结构
- 2.3 外部语言例程
- 3.触发器
-
- 3.1 对触发器的需求
- 3.2 SQL中的触发器
- 3.3 何时不用触发器
- 4.递归查询
-
- 4.1 使用迭代的传递闭包
- 4.2 SQL中的递归
- 5.高级聚集特性
-
- 5.1 排名
- 5.2 分窗
- 5.3 旋转
- 5.4 上卷和立方体
1.使用程序设计语言访问SQL
SQL查询不是万能的,我们还需要使用通用程序设计语言,至少有两点原因。
- SQL不能表达所有的查询,对于复杂查询,我们可以把SQL嵌入到一种更加强大的语言做到。
- 非声明式动作不能够在SQL中完成(比如打印一份报告,和用户交互)。
可以通过两种方式从通用语言中访问SQL。
- 动态SQL(dynamic SQL)。通用程序可以通过一组函数或者方法连接数据库并与之通信,动态SQL允许在程序运行时以字符串形式构建SQL查询,提交查询,然后每次以一个元组的方式把结果存入程序变量中。这一篇文章我们将介绍用于java的应用程序接口JDBC,以及ODBC(最初为C开发,后来应用于C,C++,C#,Ruby,Go,PHP和Visual Basic等)。并介绍Python Database Api怎么连接到数据库。对于为VB和C#语言设计的ADO.NET API,本文不做介绍,可以参考相关手册。
- 嵌入式SQL(embedded SQL)。SQL语句在编译时采用预处理器来进行识别,预处理器用嵌入式SQL表达的请求转换为函数调用。在运行时,这些函数调用将使用动态SQL设施的API连接到数据库,但这些API可能只适用于正在使用的数据库。
把SQL与通用语言相结合的主要挑战是SQL与这些语言操作数据的方式不匹配,在SQL中,数据的主要类型是关系,SQL操作关系,返回结果也是关系,在程序设计语言中,数据操作的基本单元是变量。需要提供一种机制做这样的转换。
1.1 JDBC
JDBC提供了java程序连接到数据库服务器的应用程序接口。
下面示例是Java使用JDBC的一个示例,Java程序必须加在java.sql.*,它包含了JDBC所提供函数的接口定义。
public static void JDBCexample(String userid,String passwd){
try(
// 获取连接
// 参数1,通信协议:主机名称:端口号:使用的特定数据库
// 参数2,数据库用户标识
// 参数3,密码
Connection conn = DriverManager.getConnection("jdbc:oracle:thin:@db.yale:edu:1521:univdb",userid, passwd);
// 创建一个Statement(在获取连接后执行SQL语句的对象)
Statement stmt = conn.createStatement();
) {
try{
//以字符串形式构建SQL语句
stmt.executeUpdate("insert into instructor values('77987','Kim','Physics',98000)");
}
catch(SQLException sqle) {
System.out.println("Could not insert tuple:" + sqle);
}
// 查询获取结构,并将结果以"元组"方式存储到变量中
ResultSet rset = stmt.executeQuery("select dept_name,avg(salary)" + " from instructor" + " group by dept_name");
while(rset.next()) {
System.out.println(rset.getString("dept_name") + " " + rset.getFloat(2));
}
}
catch(Exception sqle)
{
System.out.println("Exception:" + sqle);
}
}
1.1.1 连接到数据库
getConnection()有三个参数。
参数1,通信协议:主机名称:端口号:使用的特定数据库。JDBC驱动会支持很多种协议,我们需要选择一个数据库和驱动器都支持的协议,协议的详细内容是由产商设定的;
参数2,数据库用户标识;
参数3,密码。注意,在JDBC代码中直接指定密码会带来安全性风险,这里仅仅是为了简便这么写。
所有的主流产商都支持JDBC,这些数据库产品都会提供一个JDBC驱动程序,该驱动程序必须在连接到数据库前被动态的加载才能数显Java对数据库的访问。如果已经从产商的网站下载了合适的驱动程序,getConnection()方法将定位所需要的驱动程序,从而实现面向产品的调用。
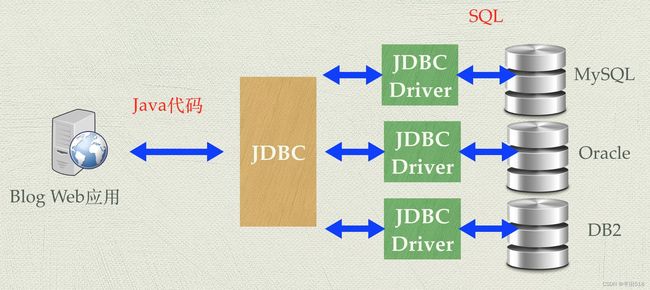
用于与数据库交换数据的协议实际上取决于JDBC驱动,协议是根据数据库产品的支持进行选择的,示例中使用的是:jdbc:oracle:thin,Mysql支持的协议是:jdbc:mysql
1.1.2 向数据库系统中传递SQL语句
我们通过连接句柄conn创建了Statement 对象,该对象用来向数据库系统中传递SQL语句。
1.1.3 异常与资源管理
try...catch结构用来处理异常。
打开连接、语句和其他JDBC对象都会消耗系统资源,必须及时关闭,否则数据库资源池会耗尽。关闭资源的一种方式是显示调用关闭,这种方式存在隐患,如果代码异常退出,此方法将会失效,你可以通过将其放在finally结构中解决或者使用示例中推荐的第二种方式。第二种方式是try-with-resources结构,它将连接和语句对象放在try中完成,简洁明了,自动隐式关闭该语句的对象,是首选方式。
1.1.4 获取查询结果
示例通过stmt.executeQuery获取查询结果,存储到ResultSet 变量中,通过getString可以获取所有类型的结果对象并且将其转化为String,也可以通过getFloat这种约束性更强的方式提取结果中的属性。提取属性可以通过名称(getString(dept_name))或者位置(getFloat(2))进行.
1.1.5 预备语句
我们可以创建一条预备语句,其中用"?"来代替某些值,以此指明以后会对其提供实际的值。数据库系统在预备查询的时候对其进行编译,在执行查询时(用新值代替“?”),数据库系统可以重用此前编译的查询形式,将新的值作为参数来应用。下面是一个示例。

在同一查询编译一次然后带不同的参数值运行多次的情况,预备语句使得执行更加高效。而且预备查询有个更大的有事,他可以避免用户手动拼接sql引入特殊字符(如多余的单引号,空格),从而生成具有语法错误的SQL。setString会自动检查用户输入,并且插入必须的转义确保语法的正确性,因此,预备语句是执行SQL的首选方法。
除此之外,使用预备语句还可以避免SQL注入来破坏或者窃取数据。
假如一个Java程序SQL如下。
"select * from instructor where name = '" + name + "'"
如果用户输入的参数name不是姓名,而是:
X' or 'Y' = 'Y
那么执行的SQL会变成:
select * from instructor where name = 'X' or 'Y' = 'Y'
本来用户只可以按姓名查找数据,现在他窃取了整个关系的数据!!!还有很多诡计多端的注入手段,窃取篡改数据。
使用预备语句可以避免这样的问题,因为查询的格式已经被预编译,用户输入的数据都被视为普通的字符串,会被插入转义字符,所以最后的查询会变成:
select * from instructor where name = 'X\' or \'Y\' = \'Y'
这是无害的查询,只会返回空的关系。
有些数据库系统允许在单个JDBC的execute方法执行多条SQL语句,语句之间用分号分隔。该特性在某些JDBC驱动中默认关闭了,因为它也可能带来SQL注入的风险。
对前面的SQL注入示例中,用户可以输入:
X';drop table instructor;--
这将导致很严重的问题。因此程序员必须使用预备语句进行查询。
1.1.6 可调用语句
JDBC还提供了CallableStatement接口,它允许调用SQL的存储过程和函数,它也用"?"来代替某些值,以此指明以后会对其提供实际的值,其返回值用registerOutParameter()方法注册,通过与结构集类似的get方法检索,可以参阅手册获取详情。
1.1.7 元数据特性
我们发现java应用程序中并不包含所存储数据的声明,这些声明是SQL DDL的一部分,因此只看java程序可能并不知道存储在数据库中的具体数据模式(当然你可以查看数据库,文档等),ResultMap接口提供了一个getMetaData()方法解决你的困难。
ResultSetMataData rsmd = rs.getMetaData();
// 获取属性个数并遍历
for(int i = 1; i <= rsdm.getColumnCount(); i++) {
// 获取属性名称
System.out.println(rsdm.getColumnName(i));
// 获取属性类型
System.out.println(rsdm.getColumnTypeName(i));
}
除了关系的属性信息,还有很多其他的元数据:产品名称,版本号,数据库系统所支持的特性等。Connection接口可以获得一个DatabaseMetaData对象,DatabaseMetaData接口提供了查找关于数据库的元数据的方法。下图使用DatabaseMetaData查找列信息,其中getColumns第一个参数为null,表示其目录名称将被忽略,最后一个参数使用通配符%,表示匹配所有的列(名称)。

还有其它API请自行查阅手册。
元数据接口可以用于各种任务,例如,他们可以用于编写数据库浏览器,该浏览器允许用户查找数据库中的表,检查他们的模式,检查表中的行,应用选择来查看所需要的行等
1.1.8 其他特性
JDBC还有很多其他的特性。
- 可更新的结果集。根据在数据库关系上执行选择或者投影来创建出可更新的结果集,对结果集的更新将导致对数据库关系对应元组的更新。
- 事务的自动提交开启/关闭,事务回滚。通过
Connection接口的setAutoCommit()方法与rollback()方法实现。 - 大对象处理接口。Result提供
getBlob()和getClob()方法。PreparedStatement类提供setBlob,setClob方法 - 行集特性,允许收集结果集将其发送给其它应用程序,行集可以向前,向后扫描,并且可以被修改。
1.2 从Python访问数据库
可以通过如下方式完成。

注意,上面示例中查询语句不会自动提交到数据库,需要调用commit()方法。
程序第一行导入的是psycopg2驱动程序,这是连接到PostgreSQL的驱动程序。其他的产商驱动与python访问数据库的语法细节可以查阅手册。
1.3 ODBC
开放数据库连接(Open DataBase Connectivity, ODBC)标准定义了一个API,应用程序可以用它来与一个数据库的连接、发送查询和更新并获取返回结果。诸如图形化用户界面、统计程序包及电子表格那样的应用程序可以使用相同的ODBC API来连接到支持ODBC的任何数据库服务器。

ODBC的语法这里不做展开,SQL标准定义了一个与ODBC接口类似的调用层接口(Call level Interface,CLI)
1.4 嵌入式SQL
SQL标准允许将SQL嵌入到其他高级程序语言,嵌入了SQL查询的语言被称为宿主语言,在宿主语言中允许使用的SQL结构构成了嵌入式SQL。
嵌入式SQL程序在编译之前必须由特殊的预处理器进行处理,该预处理器将嵌入的SQL请求替换为宿主语言的声明以及允许运行时执行数据库访问的过程调用。然后,所产生的程序由宿主语言编译器进行编译。这就是嵌入式SQL与JDBC或者ODBC的主要区别。
为了使预处理器识别出嵌入式SQL请求,我们使用EXEC SQL语句,其格式如下。
EXEC SQL <嵌入式SQL语句>;
在执行任何SQL语句之前,程序必须受限连接到数据库,在嵌入式SQL语句中可以使用宿主语言的变量,不过他们的前面必须加上冒号:以将它们与SQL变量分开来。
要遍历一个嵌入式SQL查询的结果,我们必须声明一个游标变量,它可以随后被打开,并在宿主语言循环中发出获取(fetch)命令来获取查询结果的连续行。行的属性可以提取到宿主语言变量中,数据库更新也可以通过以下方式实现:使用关系上得游标来遍历关系的行,或者使用where子句来仅遍历所选的行。嵌入式SQL命令可用于更新游标所指向的当前的行。
嵌入式SQL请求的确切语法取决于嵌入SQL的语言,请参考手册。
JDBC中,SQL语句在运行时才进行解释,但在使用嵌入式SQL时,在预处理时就有可能捕获一些与SQL程序相关的错误(包括数据类型错误)。与在程序中使用动态SQL相比,嵌入式SQL程序中的SQL查询更容易理解。但是,嵌入式SQL也存在一些缺点,预处理器会创建新的宿主语言代码,这使得程序的调试变得更加复杂。并且当宿主语言的语法迭代时,还有可能发生语法冲突。
微软语言集成查询(LINO)使用嵌入式SQL,它扩展了宿主语言以包括对查询的支持,而不是使用预处理器将嵌入式SQL查询转换为宿主语言。除此意外,动态SQL仍然是主流。
2.函数和过程
我们已经见识过内置在SQL语言里的函数,接下来我们试试自己编写函数与过程,将其存储在数据库中。函数对于诸如图像和几何对象等特定的数据类型特别有用,例如,地图数据库中使用一个线段数据类型可能需要一个相关联的函数用来监测两条线段是否会有重叠。
函数和过程允许将“业务逻辑”直接存储到数据库里,这样有至少如下几种优势:例如,它允许多个应用程序访问过程,并允许当业务规则发生改变时进行单点改变,而不必改变应用程序的其他部分。应用程序代码可以调用存储过程,而不是直接更新数据库关系。
我们阐述的概念在不同的数据库系统上都是适用的,但是不同的数据库产商的语法支持其实不同,需要查阅其手册。
2.1 声明及调用SQL函数和过程
定义函数,给定一个系的名称,返回该系的教师数量,我们可以按如下语法完成。
create or replace function dept_count(dept_name varchar(20))
returns integer
begin
declare d_count integer
select dept_name, budget
from department
where dept_name(dept_name) > 12
return d_count;
end
SQL标准支持表作为返回结果的函数,这种函数被称为表函数。下面就是一个表函数的定义,返回一个包含特定系的所有教师的表。请注意,当引用函数的参数时需要给它加上函数名作为前缀(instructor_of.dept_name)。
create or replace function instructor_of(dept_name varchar(20))
returns table(
ID varchar(5),
name varchar(20),
dept_name varchar(20),
salary numeric(8,2))
return table
(select ID,name,dept_name,salary
from instructor
where instructor.dept_name = instructor_of.dept_name);
此函数可以按如下方式使用:
select *
from table(instructor_of('Finance'));
该查询返回‘Finance’系所有的教师,在这种简单情况下不使用以表为值得函数来写这个查询也是很直观的。但是,以表为值的函数通常可以被看作参数化视图,它通过允许参数来泛化常规的视图概念。
SQL也支持过程,dept_count函数也可以写成一个过程。
create procedure dept_count_proc(in dept_name varchar(20), out d_count integer)
begin
select count(*) into d_count
from instructor
where instructor.dept_name = depart_count_proc.dept_name
end
关键字in和out分别表示待赋值的参数(入参)和为了返回结果而在过程中设置值的参数(出参)。
可以从一个SQL过程中或者嵌入式SQL中使用call语句来调用过程。
declare d_count integer;
call dept_count_proc('Physics',d_count);
过程和函数可以在动态SQL中调用。
SQL允许不止一个过程具有相同的名称,只要同名过程的参数数量是不同的,名称和参数数量一起用于标识过程。SQL中也允许不止一个函数具有相同的名称,只要同名函数的参数数量是不同的,要么对于具有同样数量参数的函数来说,它们至少有一个参数的类型是不同的。
2.2 用于过程和函数的语言结构
SQL所支持的结构赋予了它通用程序设计语言几乎所有的能力。SQL标准中处理这些结构的部分被称为持久存储模块(Persistent Storage Module, PSM)。
使用declare语句可以声明变量,变量可以是任意合法的SQL数据类型。使用set语句可以进行赋值。
复合语句具有begin ... end的形式,并且它可以在begin和end之间包含多条SQL语句。正如我们在前文2.1节看到的,可以在复合语句中声明局部变量。形如begin atomic ... end的复合语句确保其中包含的所有语句作为单个事务来执行。
while语句和repeat 语句的语法如下。
while 布尔表达式 do
语句序列;
end while
repeat
语句序列;
until 布尔表达式
end repeat
还有for循环,它允许在查询的所有结果上进行循环。
declare n integer default 0;
for r as
select budget from department
where dept_name = 'Music'
do
set n = n-r.budget
end for
该程序每次会将查询结果的一行获取到for循环变量中,leave语句可以用来退出循环,而leterate则用来跳过剩余语句。从循环的开始处理下一个元组。
SQL支持的条件语句包括使用以下语法的if-then-else语句:
if 布尔表达式
then 语句或复合语句
elseif 布尔表达式
then 语句或复合语句
else 语句或复合语句
end if
SQL也支持case语句。
下面考虑一个示例。定义registerStudent函数在确定选修一门课的学生数没有超过课程容量时,在该课程中注册一名学生。函数返回一个错误代码,这个值大于或者等于0表示成功,为负表示一种错误状态,同时以out参数的形式返回一条消息说明出错的原因。
-- 确定选修一门课的学生数没有超过课程容量时,在该课程中注册一名学生。
-- 如果成功则返回0,如果超过教室容量则返回-1
create function registerStudent(
in s_id varchar(5),
in s_course_id varchar(8),
in s_secid varchar(8),
in s_semester varchar(6),
in s_year numeric(4,0),
out errorMsg varchar(100)
return integer
begin
declare currErnrol int;
select count(*) into currErnrol
from takes
where course_id =s.course_id and sec_id = s_secid
and semester = s_semester and year = s_year
declare limit int;
select capacity into limit
from classroom natural join section
where course_id = s_courseid and sec_id = s_secid
and semester = s_semester and year = s_year;
if(currEnrol < limit)
begin
insert into takes values
(s_id, s_course_id,s_secid,s_semester,s_year, null);
return(0);
end
-- 否则,已经达到该课程的容量限制
set errorMsg = 'Enrollment limit reached for course' || s_course_id ||
'section' || s-secid
return(-1);
end;
)
SQL的过程化语言还支持对异常情况的信号发送,以及对处理异常的句柄的声明。如这段代码中所示:
declare out_of_classroom_seats condition
declare exit handler for out_of_classroom_seats
begin
语句序列;
end
begin和end之间的语句可以通过执行signal out_of_classroom_seats来引发一个异常。这个句柄说明,如果异常发生,将会采取动作来从begin end语句中退出。continue是另外一种可选动作,它从引发异常语句的下一条语句继续执行。除了明确定义的情况之外,还有一些诸如sqleception,sqlwarning和not found那样预定义的情况。
2.3 外部语言例程
尽管SQL的过程化语言很有用,但是并没有标准方式的支持,即使是最基本的特性在不同的数据库产品中都有不同的语义。这给程序员带来了困扰,要针对不同的数据库产品学习不同的数据库语言。一种解决方案是,在命令式的程序语言(Java,C#,C…)中定义过程,但允许从SQL查询和触发器的定义中调用它们。
外部过程和函数可以通过下面的方式指定(准确语法参考特定数据库手册)
create procedure dept_count_proc(in dept_name varchar(20), out count integer)
language C
external name 'usr/avi/bin/dept_count_proc'
create fuction dept_count_proc(dept_name varchar(20))
return integer
language C
external name 'usr/avi/bin/dept_count'
通常,外部语言需要处理异常情况,并返回函数或过程的执行结果状态sqlstate。如果一个函数不处理这些情况,可以在声明中额外添加一行parameter style general来指明外部过程/函数只接受显示的参数并且不处理空值或者异常。
用程序设计语言定义在数据系统之外的编译函数可以被加载并且与数据库系统的代码一起执行,不过程序中的错误可能破坏数据库的内部结构,并且可以绕过数据库系统的访问控制功能。如果关注数据库的性能胜过安全性可以这么处理,如果关注系统的安全性,可以将这种代码作为一个额外的进程来执行,并通过进程间的通信与数据库系统交互传递参数并且返回结果。不过这样会带来额外的性能开销,一次进程间的通信就足以执行数万条到数十万条指令。
如果代码用比如java或者C#那样的“安全”语言来编写,就可以在数据库查询执行本身的沙盒中执行代码。沙盒允许Java或C#的代码访问它的内存,但是阻止代码读取或者更新查询执行进程的内存。这样可以避免进程通信大大降低函数调用的开销。
当今有几个数据库系统支持在查询执行进程的沙盒里运行外部语言例程。例如,Oracle和IBM DB2允许java作为数据库进程的一部分来执行。SQL Server允许将过程编译到通用语言运行库(Common Language Runtime,CLR)中以便在数据库进程内执行。此类过程可以用C#或VB等语言编写。PostgreSQL允许用多种语言来定义函数,比如perl、python和Tcl。
3.触发器
触发器允许对数据库修改后系统自动执行一条语句,作为修改的连带效果。
3.1 对触发器的需求
触发器有如下作用:
- 实现特定的完整性约束。
- 满足特定条件时对人们发出警报或者开始执行特定的任务。
3.2 SQL中的触发器
下面示例展示了触发器的语法。
create trigger timeslot_check1 after-insert on section
referencing new row as nrow
for each row
when(nrow.time_slot_id not in (
select time_slot_id
from time_slot))
上面的referencing new row as子句创建了一个nrow变量,被称为过渡变量,它可以存储所插入或者更新行的值。类似的,referencing old row as可以创建一个变量,存储一个已经更新或已经删除的行的旧值。
触发器也可以在事件(插入、删除或更新)之前被激活,进行拦截、过滤、增补、修改等工作。比如如果插入的分数为空白,我们可以将其用空值替换。
create trigger setnull before update of takes
referencing new row as nrow
for each row
when(nrow.grade = '')
begin atomic
set nrow.grade = null
end;
我们可以对整个SQL语句执行单个操作,而不是对每个受影响的行执行一个操作。为了做到这一点,可以使用for each statement子句代替for each row子句,然后可以用referencing new table as 或者referencing old table as 来指代所有受影响的过渡表,过渡表不能够用于before触发器,但是可以用于after触发器,无论是语句触发器还是行触发器。
触发器可以被启用或者关闭,创建触发器时,它默认是开启的,可以通过alter trigger disable将其关闭,还可以通过drop trigger trigger_name将其删除。
触发器并不是SQL标准的一部分,但是其广泛的使用于各个数据库产品,不过可惜的是产品之间的语法彼此相似,但是却并不完全一致。
3.3 何时不用触发器
触发器可以替代很多别的语法,但是有的时候会使工作变得更加复杂。比如级联删除,使用触发器完成等价功能不仅需要做更多工作,还会使数据库中实现的约束组合对于用户来说难理解的多。
另外一个例子是物化视图,考虑需求,能够快速访问到每门课所注册的学生总数,可以定义一个关系section_registion(course_id,sec_id,semester,year,total_students),关系由如下SQL定义。
select course_id,sec_id,semester,year,count(ID) as total_students
from takes
group by course_id,sec_id,semester,year;
如果想要通过触发器来维持total_students,必须对增删改section_registion的元组时都编写对应的触发器,实际上很多数据库系统都能够自动的维护物化视图,没必要编写触发器。
触发器的另外一个问题是,当数据从备份副本中加载时,或者当一个站点处的数据库更新被复制到备份站点时,触发器动作意外的执行。对于可能要接管主系统的备份复制来说,必须首先显式的禁用触发器,当接管完成后,再启用触发器。另外,有一些数据库可以允许触发器被指定为not for replication或者提供系统变量用于指明备份数据库是一套副本,这样在备份数据库时无需显示的指定禁用触发器。
触发器的语法错误可能导致触发该触发器的动作语句失败,编写触发器时应该特别小心。另外,一个触发器动作可以触发另外一个触发器动作,甚至导致触发链,有些数据库会对这种情况进行检测,将其视为异常。
如果有合适的触发器替代方案,比如存储过程,推荐使用替代方案。
4.递归查询
考虑下面关系是一个课程与其先导课程的关系,如果我们希望找出一个课程的全部直接或者间接关系,同时不希望重复。

4.1 使用迭代的传递闭包
上述需求可以使用迭代的传递闭包,下图展示了这种方式的过程代码。

该过程在repeat循环之前把课程cid的所有直接先修课程插入new_c_prereq中。repeat循环受限把new_c_prereq中的所有课程加入c_prereq中,接下来,它为new_c_prereq中的所有课程计算先修课程(除了那些已经被发现是cid的直接先修课程的课程),将它们存放在临时表temp中。最后,它把new_c_prereq的内容替换成temp内容。当repeat循环找不到新的先修课程时,循环终止。
该函数中的except子句保证了即使存在先修关系的环路,该函数也能够正常工作。
4.2 SQL中的递归
上面的代码让人觉得头大,使用迭代来表达传递闭包很不方便,还有另一种可替代方法:使用递归的视图定义。
SQL标准使用with recursive子句来支持递归的受限形式。下面来看看如何实现上述需求。
with recursive rec_prereq(course_id,prereq_id) as (
select course_id,prereq_id
from prereq
union
select rec_prereq.course_id,prereq.prereq_id
from rec_prereq,prereq
where rec_prereq.prereq.id = prereq.course_id
)
select *
from rec_prereq;
任何递归视图都必须被定义为两个子查询的并:非递归的基查询和使用递归视图的递归查询。在上面示例中,基查询是prereq上的选择,而递归查询则计算prereq和rec_prereq的连接。
对递归视图的含义的最好理解方式如下:首先计算基查询,并把所有结果元组添加到递归定义的视图关系rec_prereq中(它初始为空)。然后用视图关系的当前内容计算递归查询,并将所有结果元组添加回视图关系中,持续重复上述步骤直至没有新的元组添加到视图关系中为止。所得到的视图关系实例被称为递归视图定义的不动点(fixed point)(术语不动是指不会再有进一步变化。)这样,视图关系就被定义为正好包含不动点实例中的元组。
在递归视图上进行递归查询是有一些限制的,具体地说,该查询必须是单调的(monotonic),也就是说,当一些新的元组被加入的时候,在视图中查询到的数据也必须至少与以前查询的数据集相同,并且可能包含额外的元组。
- 递归视图上的聚集
- 右侧使用递归视图上使用集差
except运算 - 在递归视图的子查询上使用
not exist运算。
例如,如果递归查询形如r-v,其中v是递归视图,那么在v中增加一个元组,那么查询到的结果可能会变得更小。可见该查询不是单调的。
只要递归查询是单调的,递归视图的含义就可以通过迭代过程来定义,否则视图的含义就很难确定。
SQL还允许通过create recursive view来代替with recursive,更多语法请查阅相关手册。
5.高级聚集特性
5.1 排名
聚合函数有很强大的功能,我们可以使用rank来获取成绩的排名,但是有一个需求我们之前的SQL很难办到,比如查询每个班级的前几名,这个需求要求分组,并且每组返回指定数量的多个值。
这个时候我们就可以使用高级聚合特性实现(Mysql中称为开窗函数)
函数名(列名) OVER(partition by 列名 order by列名)
开窗函数和聚合函数的区别:
(1)SQL 标准允许将所有聚合函数用作开窗函数,用OVER 关键字区分开窗函数和聚合函数。
(2)聚合函数每组只返回一个值,开窗函数每组可返回多个值。
我们可以用下列查询来获取学生的成绩名次。
select ID,rank() over (order by(GPA) desc) as s_rank
from student_grades
order by s_rank;
上面的查询在处理相同名次时的逻辑是,如果有两个1名,下一个名次是3名。
如果希望不产生空档,可以使用dense_rank()。这样排名时两个1名,下一个名次还是第2名。
如果在查询中存在空值,会被看做最高值。当然,SQL允许空值优先(nulls first)和空值最后(nulls last)的指定。
排名可以按照分区进行。
select ID,rank() over (partition by dept_name,order by(GPA) desc) as s_rank
from student_grades
order by dept_name,s_rank;
外层将按照系名排序,内层将对各系内部的名次进行排序。
在实际生产中,我们可能只对排名靠前的数据感兴趣。可以使用where子句过滤,当然也可以借助于部分产商提供的top n语法,不过该命令会严格按照指定的n来切割数据,无法保留最后的并列名次,而且无法进行分区排名。
percent_rank使用分数进行排名。如果某元组的排名为r,数据量为n,则其percent_rank为(r-1)/(n-1)(如果该分区只有一个元组则定义为null)
5.2 分窗
窗口查询是指在一定范围内查询,比如一个时间区间就可以被称为一个窗口。窗口可以重叠,即一个元组可以是多个窗口的成员。这与之前看到的分区是不一样的,分区一个元组只能对一个元组有贡献。
举个栗子,在微信账单里,我们可以查最近三个月的平均月消费账单,并且每个月都可以进行类似的查询,比如1-3月,2-4月…这里,一个月份的账单就可能属于不一样的窗口。
现在我们考虑应用分窗特性查询学生最近三年的平均每年选修总学分。
select year,avg(num_credits)
over (order by year rows 3 preceding)
as avg_total_credits
from tot_credits;
有一个值得注意的小细节是,如果这个学生是大一,那么它查询的最近三年数据其实只有一年的数据,因此查询结果就是当年的选修总学分。
另外考虑,有时候我们需要查询不限制固定年份,而是有记录以来。比如任意一名大学生从入学到现在的平均年度总学分。
select year,avg(num_credits)
over (order by year rows unbounded preceding)
as avg_total_credits
from tot_credits;
我们还以指定区间,这里借助关键字following,下面查询表示查询当前年(元组)的前三年到当前年后两个年的平均年度总学分。
select year,avg(num_credits)
over (order by year rows between 3 preceding and 2 following)
as avg_total_credits
from tot_credits;
另外rows ... current row表示当前元组,range... current row指代与当前元组值相同的所有元组。
5.3 旋转
考虑一个如下关系sales
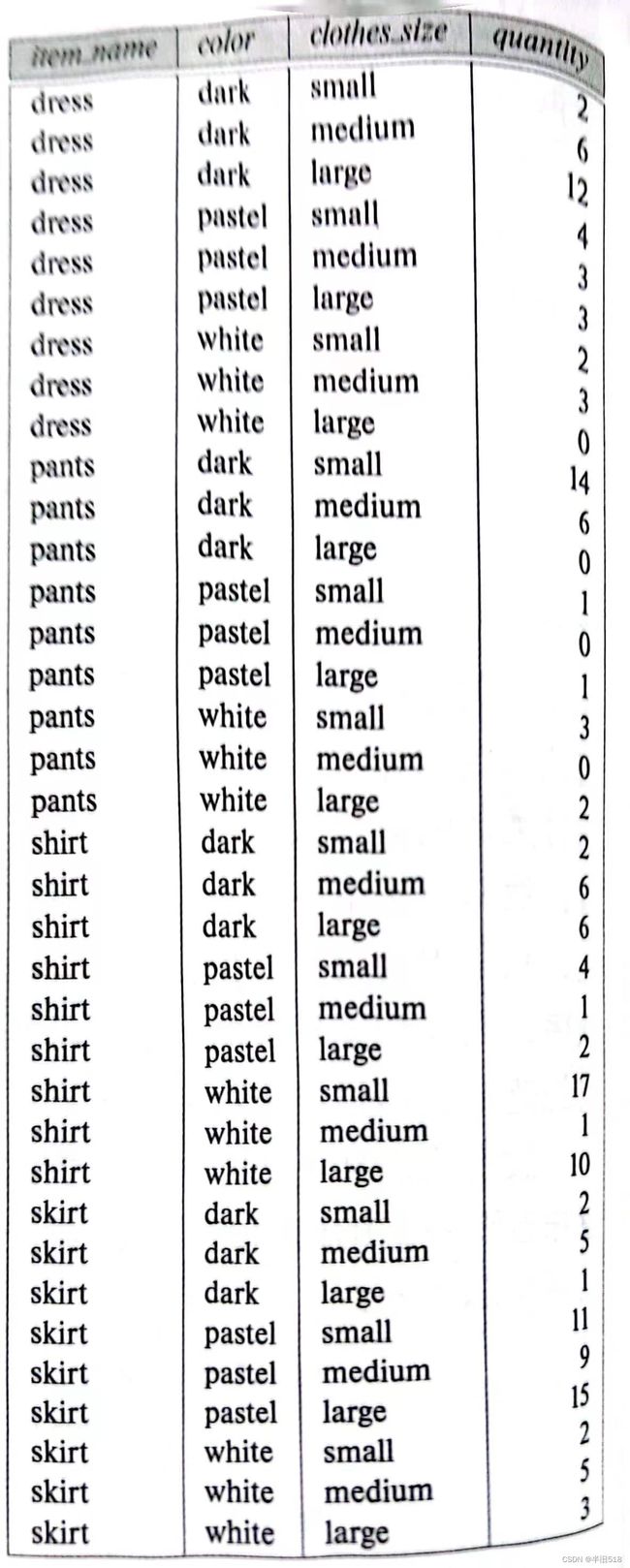
下面要求把每种商品按照如下形式展示,把color扩展为三列
 上面的表被称为交叉表(cross-tab)或者数据透视表(pivot-table),它被广泛的应用于数据分析领域。
上面的表被称为交叉表(cross-tab)或者数据透视表(pivot-table),它被广泛的应用于数据分析领域。
我们可以这样实现。
select *
from sales
pivot(
sum(quantity)
for color in('dark','pastel','white')
)
5.4 上卷和立方体
数据分析师常常需要对列表数据做各种筛选,比如下列需求(参考下图)其实很常见:按照商品种类item-name,商品颜色color分类,统计商品数量;分类(不区分颜色)商品的汇总数量;统计所有商品的总数。
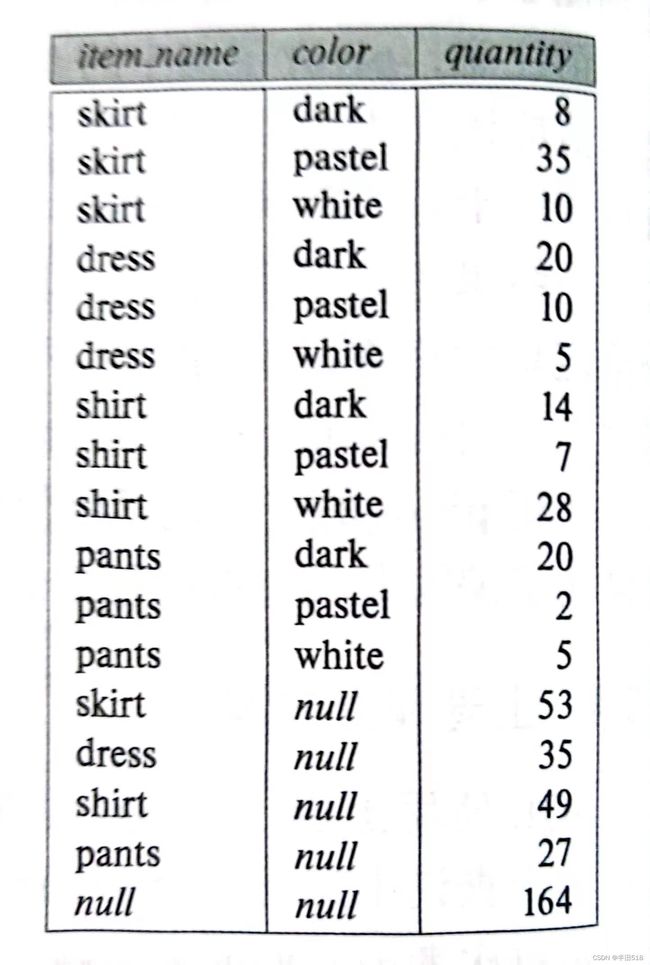
以前我们需要写三个SQL,但是使用上卷roll up,你可以一步到位。
select item_name,color,sum(quantity)
from sales
group by rollup(item_name,color);
以上查询结果的分组结构可以归纳为:{(item_name,color),(item_name),()}
应用立方体cube将分类从二维扩展到三维,可以获得更多的分组。
比如下列查询。
select item_name,color,clothes_size,sum(quantity)
from sales
group by rollup(item_name,color,clothes_size);
可以得到的分组情况是{(item_name,color,clothes_size),(item_name,color),(item_name,clothes_size),(color,clothes_size),(item_name),(color),(clothes_size),()}。
可以将多个立方体(cube)和上卷(rollup)应用到同一个group by子句中。
select item_name,color,clothes_size,sum(quantity)
from sales
group by rollup(item_name),rollup(color,clothes_size);
其结果是{(item_name,color,clothes_size),(item_name,color),(item_name),(color,clothes_size),(color),()}
如果不理解,您可以先运算rollup(item_name),结果是{(item_name),()},再运算rollup(color,clothes_size),结果是(color,clothes_size),(color),(),最后进行笛卡尔积。
我们还可以使用grouping sets结构来指定我们结果中需要的分组。比如。
select item_name,color,clothes_size,sum(quantity)
from sales
group by grouping sets((color,clothes_size),(clothes_size,item_name));
如果希望将上卷和立方体运算的空值与实际存储在数据库中或者外连接所产生的空值区分开来,可以借助于grouping()函数
select(case when grouping(item_name)=1 then 'all'
else item_name end) as item_name,
(case when grouping(color)=1 then 'all'
else color end) as color,
sum(quantity) as quantity
from sales
group by rollup(item_name,color);
)