Lenet 进行手写数字识别(pytorch)
注:初入门深度学习,记录自己第一个成功的小实验,无参考意义
在我的Python项目下一共两个文件,一个用来定义模型,一个用来训练
目录
- 定义模型
- 训练函数
- 实验效果
定义模型
注意:由于Minist 手写数字是灰色图片即单通道,所以我们在经过两个卷积层之后只有16个通道,并且我在Lenet 的网络中加入了BatchNormal 正则化,经实验可以提高模型精度这里提出一个值得注意的点: x = x.view(-1, 16 x 4 x 4),这里是将卷积层展开为全连接层,但是我看到网上都是写的(16 x 5 x 5),我将自己图片经过卷积层后的输出通过计算得到的是(16 x 4 x 4),于是我将它写为(16 x 4 x 4)并成功运行,经过实验我的想法是对的(原来我发现我的第一层卷积填充padding=0,所以计算后是(16 x 4 x4)),所以有些东西一定要自己思考且实践验证,这里给出一个计算卷积后输出大小的公式 ⌊(nh − kh + ph + sh)/sh⌋ × ⌊(nw − kw + pw + sw)/sw⌋. 即:输入高或宽nh 卷积核大小kernal_size(kh) 填充 padding(ph) 步幅 strid(sh) ,一定要对应好输出
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(1, 6, kernel_size=5)
self.pool1 = nn.AvgPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(6, 16, kernel_size=5)
self.pool2 = nn.AvgPool2d(kernel_size=2, stride=2)
self.bn1 = nn.BatchNorm2d(6)
self.bn2 = nn.BatchNorm2d(16)
self.fc1 = nn.Linear(16*4*4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x): # ⌊(nh − kh + ph + sh)/sh⌋ × ⌊(nw − kw + pw + sw)/sw⌋.
x = F.relu(self.bn1(self.conv1(x))) # input(1, 28, 28) output(6, 24, 24)
x = self.pool1(x) # output(6, 12, 12)
x = F.relu(self.bn2(self.conv2(x))) # output(16, 8, 8)
x = self.pool2(x) # output(16, 4, 4)
x = x.view(-1, 16*4*4) # output(256)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x

训练函数
这里可以给出一个常用的步骤:
1.数据预处理,由于 minist 手写数字已经内嵌在了pytorch中,我们只需要简单的调用函数即可,无需复杂的数据预处理 transform 是一个比较重要的步骤,我们需要在这里定义读数据的处理方式,值得注意的是,Minist是灰度图像,所以Normalize里面只能对一个维度进行处理,RGB是对三个维度处理例如:将数据转换为tensor类型(必要的),对数据进行标准化(正则化)处理,图像增广(翻转,改变色调,缩放),以训练集为例: train_set = torchvision.datasets.MNIST(root='./data', train=True, download=False, transform=transform)
` 这一步是将数据加载,如果没有下载数据集,download选项需等于True
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32, shuffle=True, num_workers=0) 这一步是将数据加载到内存中,batch_size 表示每次加载多少,shuffle表示是否打乱顺序
2.定义模型,损失函数,优化函数,这里无需多言
3.训练,同样无需多言
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
def main():
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])]
)
train_set = torchvision.datasets.MNIST(root='./data', train=True,
download=False, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32,
shuffle=True, num_workers=0)
val_set = torchvision.datasets.MNIST(root='./data', train=False,
download=False, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=1000,
shuffle=False, num_workers=0)
val_data_iter = iter(val_loader)
val_images, val_labels = val_data_iter.next()
net = LeNet()
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
for epoch in range(5):
running_loss = 0.0
for step, (images, labels) in enumerate(train_loader, start=0):
optimizer.zero_grad()
outputs = net(images)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if step % 500 == 499:
with torch.no_grad():
outputs = net(val_images)
predict_y = torch.max(outputs, dim=1)[1]
accuracy = torch.eq(predict_y, val_labels).sum().item() / val_labels.size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0
print('Finished Training')
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
if __name__=='__main__':
main()
实验效果
这里可以给出一个对比一个是没有在网络里面加 BatchNormal , 一个是添加 BatchNormal
图一,无正则化
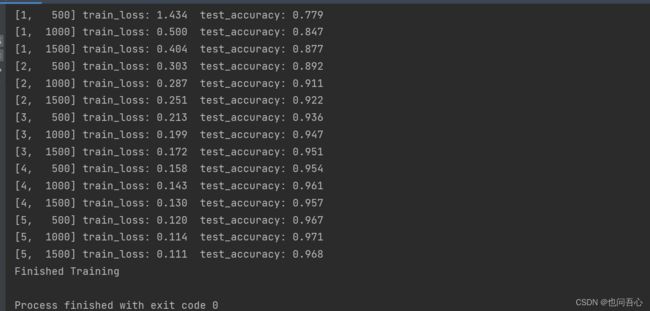
图二,加上正则化

可以很明显的看到精度有提升