计算机组成原理---冯诺依曼体系结构及性能和功耗
文章总结摘要自徐文浩老师的《深入浅出计算机组成原理》
文章目录
- 一、计算机的基本硬件组成
- 二、冯诺依曼体系结构
- 性能
-
- 计算机的计时单位:CPU 时钟
- 功耗
-
- 并行优化,理解阿姆达尔定律
- 总结
一、计算机的基本硬件组成
早年,要自己组装一台计算机,要先有三大件,CPU、内存和主板。在这三大件中,我们首先要说的是 CPU,它是计算机最重要的核心配件,全名你肯定知道,叫中央处理器(Central Processing Unit)。为什么说 CPU 是“最重要”的呢?因为计算机的所有“计算”都是由 CPU 来进行的。自然,CPU 也是整台计算机中造价最昂贵的部分之一。
第二个重要的配件,就是内存(Memory)。你撰写的程序、打开的浏览器、运行的游戏,都要加载到内存里才能运行。程序读取的数据、计算得到的结果,也都要放在内存里。内存越大,能加载的东西自然也就越多。存放在内存里的程序和数据,需要被 CPU 读取,CPU 计算完之后,还要把数据写回到内存。然而 CPU 不能直接插到内存上,反之亦然。于是,就带来了最后一个大件——主板(Motherboard)。
主板是一个有着各种各样,有时候多达数十乃至上百个插槽的配件。我们的 CPU 要插在主板上,内存也要插在主板上。主板的芯片组(Chipset)和总线(Bus)解决了 CPU 和内存之间如何通信的问题。芯片组控制了数据传输的流转,也就是数据从哪里到哪里的问题。总线则是实际数据传输的高速公路。因此,总线速度(Bus Speed)决定了数据能传输得多快。

有了三大件,只要配上电源供电,计算机差不多就可以跑起来了。但是现在还缺少各类输入(Input)/ 输出(Output)设备,也就是我们常说的 I/O 设备。如果你用的是自己的个人电脑,那显示器肯定必不可少,只有有了显示器我们才能看到计算机输出的各种图像、文字,这也就是所谓的输出设备。同样的,鼠标和键盘也都是必不可少的配件,它们也就是所谓的输入设备。
还有一个很特殊的设备,就是显卡(Graphics Card)。现在,使用图形界面操作系统的计算机,无论是 Windows、Mac OS 还是 Linux,显卡都是必不可少的。有人可能要说了,我装机的时候没有买显卡,计算机一样可以正常跑起来啊!那是因为,现在的主板都带了内置的显卡。如果你用计算机玩游戏,做图形渲染或者跑深度学习应用,你多半就需要买一张单独的显卡,插在主板上。显卡之所以特殊,是因为显卡里有除了 CPU 之外的另一个“处理器”,也就是 GPU(Graphics Processing Unit,图形处理器),GPU 一样可以做各种“计算”的工作。
二、冯诺依曼体系结构
无论是个人电脑、服务器、智能手机,还是 Raspberry Pi 这样的微型卡片机,都遵循着同一个“计算机”的抽象概念。这是怎么样一个“计算机”呢?这其实就是,计算机祖师爷之一冯·诺依曼(John von Neumann)提出的冯·诺依曼体系结构(Von Neumann architecture),也叫存储程序计算机。
这里面其实暗含了两个概念,一个是“可编程”计算机,一个是“存储”计算机。
说到“可编程”,什么是“不可编程”。计算机是由各种门电路组合而成的,然后通过组装出一个固定的电路板,来完成一个特定的计算程序。一旦需要修改功能,就要重新组装电路。这样的话,计算机就是“不可编程”的,因为程序在计算机硬件层面是“写死”的。最常见的就是老式计算器,电路板设好了加减乘除,做不了任何计算逻辑固定之外的事情。

再来看“存储”计算机。这其实是说,程序本身是存储在计算机的内存里,可以通过加载不同的程序来解决不同的问题。有“存储程序计算机”,自然也有不能存储程序的计算机。典型的就是早年的“Plugboard”这样的插线板式的计算机。整个计算机就是一个巨大的插线板,通过在板子上不同的插头或者接口的位置插入线路,来实现不同的功能。这样的计算机自然是“可编程”的,但是编写好的程序不能存储下来供下一次加载使用,不得不每次要用到和当前不同的“程序”的时候,重新插板子,重新“编程”。

可以看到,无论是“不可编程”还是“不可存储”,都会让使用计算机的效率大大下降。而这个对于效率的追求,也就是“存储程序计算机”的由来。
冯诺依曼体系结构
任何一台计算机的任何一个部件都可以归到运算器、控制器、存储器、输入设备和输出设备中,而所有的现代计算机也都是基于这个基础架构来设计开发的。
而所有的计算机程序,也都可以抽象为从输入设备读取输入信息,通过运算器和控制器来执行存储在存储器里的程序,最终把结果输出到输出设备中。而我们所有撰写的无论高级还是低级语言的程序,也都是基于这样一个抽象框架来进行运作的。

性能
什么是性能?时间的倒数
计算机的性能,其实和我们干体力劳动很像,好比是我们要搬东西。对于计算机的性能,我们需要有个标准来衡量。这个标准中主要有两个指标。第一个是响应时间(Response time)或者叫执行时间(Execution time)。想要提升响应时间这个性能指标,你可以理解为让计算机“跑得更快”。第二个是吞吐率(Throughput)或者带宽(Bandwidth),想要提升这个指标,你可以理解为让计算机“搬得更多”。
所以说,响应时间指的就是,我们执行一个程序,到底需要花多少时间。花的时间越少,自然性能就越好。而吞吐率是指我们在一定的时间范围内,到底能处理多少事情。这里的“事情”,在计算机里就是处理的数据或者执行的程序指令。
提升吞吐率的办法有很多。大部分时候,我们只要多加一些机器,多堆一些硬件就好了(cpu的8 核、16 核)。但是响应时间的提升却没有那么容易,因为 CPU 的性能提升其实在 10 年前就处于“挤牙膏”的状态了。
我们一般把性能,定义成响应时间的倒数,也就是:性能 = 1/ 响应时间
计算机的计时单位:CPU 时钟
程序的 CPU 执行时间 =CPU 时钟周期数×时钟周期时间
我们先来理解一下什么是时钟周期时间。你在买电脑的时候,一定关注过 CPU 的主频。比如我手头的这台电脑就是 Intel Core-i7-7700HQ 2.8GHz,这里的 2.8GHz 就是电脑的主频(Frequency/Clock Rate)。这个 2.8GHz,我们可以先粗浅地认为,CPU 在 1 秒时间内,可以执行的简单指令的数量是 2.8G 条。
如果想要更准确一点描述,这个 2.8GHz 就代表,我们 CPU 的一个“钟表”能够识别出来的最小的时间间隔。就像我们挂在墙上的挂钟,都是“滴答滴答”一秒一秒地走,所以通过墙上的挂钟能够识别出来的最小时间单位就是秒。
而在 CPU 内部,和我们平时戴的电子石英表类似,有一个叫晶体振荡器(Oscillator Crystal)的东西,简称为晶振。我们把晶振当成 CPU 内部的电子表来使用。晶振带来的每一次“滴答”,就是时钟周期时间。
在一个主频为 2.8GHz 的 CPU 上,这个时钟周期时间,就是 1/2.8G。
如果更准确一点,对于 CPU 时钟周期数,我们可以再做一个分解,把它变成“指令数×每条指令的平均时钟周期数(Cycles Per Instruction,简称 CPI)”
则程序的 CPU 执行时间 = 指令数×CPI×Clock Cycle Time(时钟周期时间)
因此,如果我们想要解决性能问题,其实就是要优化这三者。
1.时钟周期时间,就是计算机主频,这个取决于计算机硬件。我们所熟知的摩尔定律就一直在不停地提高我们计算机的主频。
2.每条指令的平均时钟周期数 CPI,就是一条指令到底需要多少 CPU Cycle。现代的 CPU 通过流水线技术(Pipeline),让一条指令需要的 CPU Cycle 尽可能地少。因此,对于 CPI 的优化,也是计算机组成和体系结构中的重要一环。
3.指令数,代表执行我们的程序到底需要多少条指令、用哪些指令。这个很多时候就把挑战交给了编译器。同样的代码,编译成计算机指令时候,就有各种不同的表示方式。
功耗
功耗:CPU 的“人体极限”
我们的 CPU,一般都被叫作超大规模集成电路(Very-Large-Scale Integration,VLSI)。这些电路,实际上都是一个个晶体管组合而成的。CPU 在计算,其实就是让晶体管里面的“开关”不断地去“打开”和“关闭”,来组合完成各种运算和功能。想要计算得快,一方面,我们要在 CPU 里,同样的面积里面,多放一些晶体管,也就是增加密度;另一方面,我们要让晶体管“打开”和“关闭”得更快一点,也就是提升主频。而这两者,都会增加功耗,带来耗电和散热的问题。
功耗 ~= 1/2 ×负载电容×电压的平方×开关频率×晶体管数量
那么,为了要提升性能,我们需要不断地增加晶体管数量。同样的面积下,我们想要多放一点晶体管,就要把晶体管造得小一点。这个就是平时我们所说的提升“制程”。从 28nm 到 7nm,相当于晶体管本身变成了原来的 1/4 大小。这个就相当于我们在工厂里,同样的活儿,我们要找瘦小一点的工人,这样一个工厂里面就可以多一些人。我们还要提升主频,让开关的频率变快,也就是要找手脚更快的工人。
但是,功耗增加太多,就会导致 CPU 散热跟不上,这时,我们就需要降低电压。这里有一点非常关键,在整个功耗的公式里面,功耗和电压的平方是成正比的。这意味着电压下降到原来的 1/5,整个的功耗会变成原来的 1/25。
并行优化,理解阿姆达尔定律
虽然制程的优化和电压的下降,在过去的 20 年里,让我们的 CPU 性能有所提升。但是从上世纪九十年代到本世纪初,软件工程师们所用的“面向摩尔定律编程”的套路越来越用不下去了。“写程序不考虑性能,等明年 CPU 性能提升一倍,到时候性能自然就不成问题了”,这种想法已经不可行了。因为cpu硬件的提升越来越有限。于是,Intel 意识到通过提升主频比较“难”去实现性能提升,边开始推出 Core Duo 这样的多核 CPU,通过提升“吞吐率”而不是“响应时间”,来达到目的,也就是现在的多核cpu。
这个思想在很多地方都可以使用。举个例子,我们做机器学习程序的时候,需要计算向量的点积,比如向量 W=[W0,W1,W2,…,W15] 和向量 X=[X0,X1,X2,…,X15],W⋅X=W0∗X0+W1∗X1+ W2∗X2+…+W15∗X15。这些式子由 16 个乘法和 1 个连加组成。如果你自己一个人用笔来算的话,需要一步一步算 16 次乘法和 15 次加法。如果这个时候我们把这个任务分配给 4 个人,同时去算 W0~W3, W4~W7, W8~W11, W12~W15 这样四个部分的结果,再由一个人进行汇总,需要的时间就会缩短。
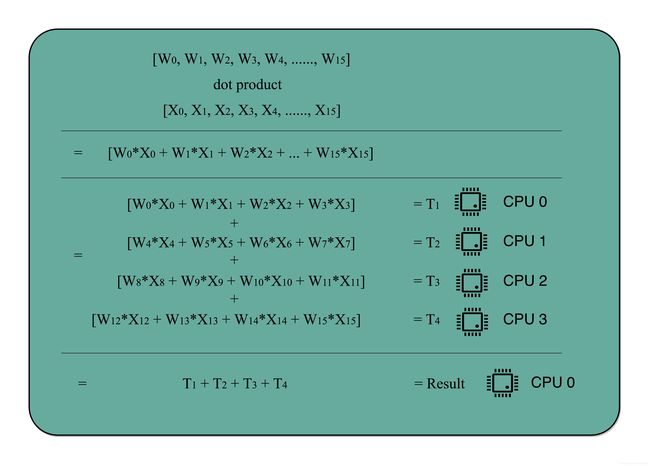
但是,并不是所有问题,都可以通过并行提高性能来解决。如果想要使用这种思想,需要满足这样几个条件。
第一,需要进行的计算,本身可以分解成几个可以并行的任务。好比上面的乘法和加法计算,几个人可以同时进行,不会影响最后的结果。
第二,需要能够分解好问题,并确保几个人的结果能够汇总到一起。
第三,在“汇总”这个阶段,是没有办法并行进行的,还是得顺序执行,一步一步来。
这就引出了我们在进行性能优化中,常常用到的一个经验定律,阿姆达尔定律
优化后的执行时间 = 受优化影响的执行时间 / 加速倍数 + 不受影响的执行时间
在刚刚的向量点积例子里,4 个人同时计算向量的一小段点积,就是通过并行提高了这部分的计算性能。但是,这 4 个人的计算结果,最终还是要在一个人那里进行汇总相加。这部分汇总相加的时间,是不能通过并行来优化的,也就是上面的公式里面不受影响的执行时间这一部分。
比如上面的各个向量的一小段的点积,需要 100ns,加法需要 20ns,总共需要 120ns。这里通过并行 4 个 CPU 有了 4 倍的加速度。那么最终优化后,就有了 100/4+20=45ns。即使我们增加更多的并行度来提供加速倍数,比如有 100 个 CPU,整个时间也需要 100/100+20=21ns。
总结
冯诺依曼体系结构
任何一台计算机的任何一个部件都可以归到运算器、控制器、存储器、输入设备和输出设备中,而所有的现代计算机也都是基于这个基础架构来设计开发的。
拓展:图灵机是一种思想模型(计算机的基本理论基础),是一种有穷的、构造性的问题的问题求解思路,图灵认为凡是能用算法解决的问题也一定能用图灵机解决;
冯诺依曼提出了“存储程序”的计算机设计思想,并“参照”图灵模型设计了历史上第一台电子计算机,即冯诺依曼机。
性能
我们一般把性能,定义成响应时间的倒数,也就是:性能 = 1/ 响应时间
CPU 执行时间 = 指令数×CPI×Clock Cycle Time(时钟周期时间)
因此,如果我们想要解决性能问题,其实就是要优化这三者。
功耗
功耗 ~= 1/2 ×负载电容×电压的平方×开关频率×晶体管数量
因此,从上述几方面降低功耗
在“摩尔定律”和“并行计算”之外,在整个计算机组成层面,还有这样几个原则性的性能提升方法。
1.加速大概率事件
2.通过流水线提高性能
3.通过预测提高性能。