独家 | 利用深度学习来预测Spotify上的Hip-Hop 流行程度

作者:Nicholas Indorf翻译:Gabriel Ng校对:zrx
本文约10000字,建议阅读13分钟
项目中收集并使用了 Spotify 数据库中最近发布的hip-hop曲目的音频预览样本和相关的流行度分数。摘要
在这个项目里面,我想构建一个工具来帮助我的表弟,一位名叫“KC Makes Music”的Hip-Hop艺术家。这个工具将会评估他尚未发布的歌曲是否有在Spotify上流行的潜力。
项目中只收集并使用了 Spotify 数据库中最近发布的hip-hop曲目的音频预览样本和相关的流行度分数。这些数据被处理成频谱图(spectrogram)和二进制响应目标(流行/不流行),然后被输入到神经网络中,该网络随着迭代构建,其复杂度也会逐渐提高。
其中,基于循环神经网络的最复杂的模型表现最好,准确率为 59.8%,而ROC-AUC 为 0.646。这意味着比起基准情况,其准确度提高了 9.1% 和 0.146。考虑到这个模型只使用到曲目的预览音频,这虽然不是一个令人兴奋的结果,但它也并不是一无是处!尽管我不建议将此模型用于单一乐曲的层面,但对于大量样本来说,其仍然是能够发挥一定作用的。它可以把艺术家的注意力引导到要关注的子集上,从而节省精力,体现出模型的价值。相信进一步的改进会使模型可供客户使用的更加强大的工具。
https://github.com/Nindorph/HipHopPopularity
问题背景
音频分类(Audio classification)是神经网络模型的经典用例。例如在之前的项目中,我所在的一个团队构建了一个分类器来区分来自该数据集的音乐类别。这已经在多个博客文章(博客 1、博客 2)中完成,并且似乎是一个相当有知名度的项目。此外,Kaggle 上也进行着音频分类比赛,其参赛模型将会是未来类似项目的主要候选对象。两个重要的例子是Google Brain的语音识别比赛和康奈尔鸟类学实验室的鸟叫识别比赛。
考虑到这些,我想知道音频分类能走多远。音乐流派、人类语言和鸟叫声所涉及的类别当中的差异对人耳来说是显然的。爵士乐听起来不同于金属,不同的音节听起来不同,不同的鸟有不同的叫声。这些对于人类观察者来说都是显而易见的。我知道机器有着比人类更高的区分能力,奇怪的是,我发现在音频领域中,给机器提供的问题是人耳可以轻松解决的。我能找到的最困难的音频分类问题是将区分 COVID-19 的咳嗽声与正常咳嗽声,然而一个训练有素的呼吸科医生很大机率能很好地完成这项任务。相比之下,我们有着可以根据大量关于水井的数据点来预测坦桑尼亚的水井是否正常运行的模型。在神经网络领域,Nature 发表了一个可以通过查看心电图来预测心脏诊断的深度神经网络。而凭人力则很难通过任一数据集以做出这样的预测(除了第二个数据集,一个心脏病专家也许能做到)。
因此,我想选择一个涉及音频的项目来在人类难以做到的事情上进行预测。我想挑战极限,去做一些有野心的项目。因为我喜欢音乐,所以我想看看仅在歌曲样本上训练的模型是否可以预测曲目的流行程度。这是一个很常见的想法(博客 1、博客 2、博客 3),但这些项目都使用了 Spotify 提供的音频功能(例如跳舞性、乐器性等)。它们实际上并不使用音频样本,而我认为利用神经网络和原始歌曲样本的表现可能会更好。而因为你不需要依赖 Spotify 的指标,并且可以在歌曲发布之前进行此分析,这也显得模型更加有用。
流行程度是一个有难度的响应目标——上述博客文章把成功程度与更传统的(即非神经网络)技术混合起来。此外,神经网络通常用于人耳相对容易辨别的音频数据。但是一个人不能够听一首歌然后说“哦,这听起来很流行”。他们可能会说这听起来不错,但流行程度则有点难以量化。
KC Makes Music 是我表弟的艺名,他是 Spotify 上的Hip-Hop艺术家。我认为如果我利用我的数据科学技能能尝试帮助他在平台上取得听众数,这将是一次有趣的学习体验。他也取得了一些成功,截至 2021 年 12 月,他的每月听众数约为 2.45 万,但了解获得每月听众和追随者的方法往往是神秘的。Spotify 有一个非常强大的数据库,所以我知道有实际机会能帮助我的表弟增加他的听众群,从而扩大他作为艺术家的影响力。
在查看了这个项目的可行切入角度之后,我决定解决这个问题的其中一种方法是调查最近的 hip-hop 曲目并尝试建立一个模型来预测以前的未发行歌曲是否有可能在当前流行.我会随机收集各种歌曲(所有流行分数),获取他们的预览音频文件,将它们转换为频谱图,然后把它们输入神经网络。从而希望转化出一个模型,该模型可以捕捉流行歌曲中的共同特征,以便它判断一首新歌是否会流行。我的表弟有许多未发行的、已完成的曲目,而我们可以通过模型进行预测。如果模型足够准确,它可以找出哪些音轨会有好的表现。如果它们都表现得不好,那么可以跟我的表弟说明他的曲目需要更多的工作和改进,而我们可以利用迭代的方式重新测试它们。此外,我可以使用 LIME 之类的工具来找出模型输出中特别重要的结果,再让我的表弟接收到这些信息,让他能更专注于它们上。
对于这个项目,我决定将目标简化为流行/不流行的二进制标签,因为对于模型来说区分两个类会较确定某物的流行程度更容易一些。而对于我的商业目的,区分流行/不流行和确立流行程度之间没有太大区别。如果我得到了惊喜的结果,我总是可以在稍后将其转换成回归类型的模型,但就目前而言,简化标签有助我更容易地看到模型的有效性。此外,最重要的是模型可以将两个类分开。一个混合了流行歌曲和不流行歌曲的模型是没有用的。Type I错误(假阳性)意味着我的表弟发行了表现不好的歌曲,而Type II错误(假阴性)则意味着我的表弟在一首原来就很好的歌曲上付出了过多精力。不管怎样,我们得不到好的结果。考虑到这一点,准确度是一个有用的指标,但 ROC-AUC 是首选指标,因为它衡量的是两个类的分离程度。
数据采集
所有数据均来自 Spotify Web API。选择 Spotify 不仅是因为它是我们尝试进行优化的平台,还因为它是最全面的音乐数据库之一。使用 Spotify Web API 的 Python 接口 Spotipy,我收集了2019-2021年发布的“Hip-Hop”类型的随机歌曲的信息。随机音轨是根据此处概述的方法生成的。
有关我是怎样获取数据的更多详细信息,请参阅 GitHub。
最终,16168 首曲目被选择进行收录。数据中最关键的部分是约 30 秒 mp3 预览音频文件的 http 链接和流行度分数。分数的范围是 0-100,其中 100 代表最受欢迎。流行度是三峰的,在 0 处有一个巨大的峰值,在 ~28 处有一个小峰值,而在 ~45 处有一个大峰值。
数据集:完整性和代表性的检验
通过查看一些我认识的在过去 3 年中发行歌曲的代表性艺术家,有关数据的完整性和代表性的检验能很容易完成。我挑选了Drake、Kanye West 和 KC Makes Music(我的表弟)。有关代码的更多详细信息,请查看 Github。
Drake 有大约 140 首曲目。似乎是对的。
Kanye West 有 9 个。绝对不准确,因为在不久前他才发布了 Donda。
KC Makes Music 完全不见了!
这个数据集似乎并不完整。其中有很多歌曲有着非常多样化的艺术家和流行程度,但它缺少我期望出现的歌曲。例如,Kanye West 不久前发布了 Donda,但我在这里看不到这张专辑的任何内容。此外,这里根本没有我表弟的音乐的代表内容。
正如我所说,它仍然有一定数量的歌曲,所以对于现在来说可能已经足够好了。我会利用目前的数据集来进行项目,而如果我需要更多样本,我会在之后进行挖掘更多。
流行程度:对目标的考察
track_df['popularity'].hist(bins=100)
Fig 1 流行程度(x轴)对照数量(y轴)
40 或更高似乎是一个不错的截断值,但我会在训练-测试-保持拆分后选择截断值,以将数据泄漏降至最低。
在文章稍后会看到39 是最终的截断数字,所以这个估计很接近。
另一个有趣的发现是没有 mp3 预览的歌曲更受欢迎,这令人十分意外!
track_df[track_df['preview_url'].isna()]\
['popularity'].hist(bins=100)
Fig 2 流行程度(x轴)对照数量(y轴)
# before removal of nulls/duplicate links
track_df['popularity'].hist(bins=100)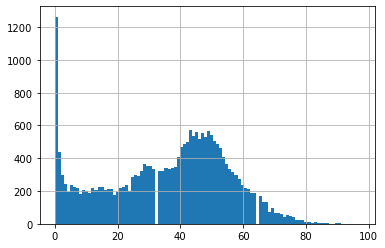
Fig 3 流行程度(x轴)对照数量(y轴)
# after removal of nulls/duplicate links
mp3s['popularity'].hist(bins=100)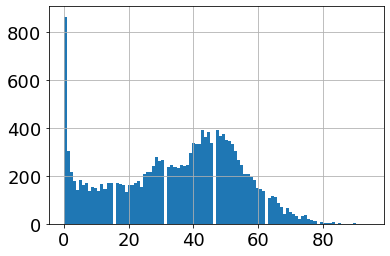
Fig 4 流行程度(x轴)对照数量(y轴)
如你所见,带有预览 mp3 的歌曲,和所有收集到的没有重复的歌曲的分布大致相同。这是因为上述结论在没有 mp3 的歌曲上仍是正确的,因此删除没有预览 mp3 的歌曲并不会引入统计上的误差。
艺人:对平均流行程度的考察
一方面为了满足我的好奇心,而另一方面把流行度值放入下文中,我查看了数据中艺人平均歌曲流行度的分布。同样地,我使用了上面相同的 track_df_expart 来查看。
很多我认为非常受欢迎的艺人的平均流行度低于 70,而我从未听说过的许多艺术家的平均流行程度则非常高……
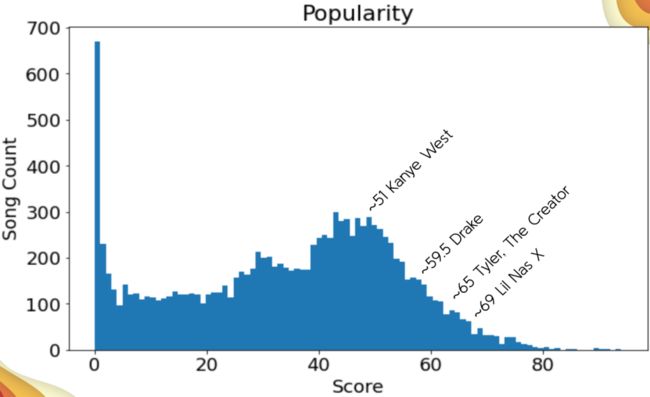
Fig 5 某部分有名气的艺人的平均流行程度
考虑到这一点,以上 40 的截断值估计似乎是一个用来描绘“流行”的可靠准则。同样,我将只查看训练数据,但由于样本量大,我认为它也会有相似的分布。
歌曲:对重复值的考察
我留意到有些歌曲有不同的 mp3 预览 http 链接,但实际上是同一首歌,只是在不同的专辑中。我会进一步看看具体情况。
# find duplicates based on track name and the duration
# lots of repeats -- 652 in the dataset
mp3s[mp3s.duplicated(subset=['track', 'duration_ms'], keep=False)]['track'].value_counts()6 'N the Mornin' 6
3 Headed Goat (feat. Lil Baby & Polo G) 6
Zulu Screams (feat. Maleek Berry & Bibi Bourelly) 4
How TF (feat. 6LACK) 4
durag activity (with Travis Scott) 4
..
Zu Besuch 2
50 in Da Safe (feat. Pink Sweat$) 2
The Announcement (Sex Drugs & Rock and Roll) 2
Shotta Flow 2
I'LL TAKE YOU ON (feat. Charlie Wilson) 2
Name: track, Length: 652, dtype: int64如您所见,有许多重复值。让我们看一下在上部分的例子。
mp3s[mp3s['track'] == "3 Headed Goat (feat. Lil Baby & Polo G)"]
Fig 6 最多重复值的歌曲, 以表格呈现
哇,这首歌有2个单曲,2个专辑,2个豪华专辑,且都有不同的预览mp3链接(图中没有展示)。而且它们都有不同的流行程度得分。
尽管有来自不同专辑(单曲、专辑等)的重复歌曲,但它们通常有不同的流行程度,所以这仍然是有用的信息。故只要它们的流行程度不同,我就会保持这些重复值。最后我仅删除了 26 个条目:
mp3s[mp3s.duplicated(subset=['track','duration_ms','popularity'],
keep=False)]['track'].value_counts()
6 'N the Mornin' 6
9ja Hip Hop 3
Face Off 2
8 Figures 2
80's - Instrumental - Remastered 2
3 Headed Goat (feat. Lil Baby & Polo G) 2
Studio 54 2
SAME THING 2
One Punch Wulf 2
50/50 Love 2
96 Freestyle 2
6itch remix - feat. Nitro 2
6565 2
Zero Survivors 2
Jazz Hands 2
Just Mellow - Norman Cook 7'' Remix 2
Aries (feat. Peter Hook and Georgia) 2
60% 2
Sex Cells 2
Seven Day Hustle 2
Ring (feat. Young Thug) 2
8 Missed Calls 2
Name: track, dtype: int64目标处理和 Librosa 处理
现在有了提取好的数据集,我就需要将我的目标处理成为二进制编码的变量,并利用Librosa把 mp3 预览链接转换成 Mel 频谱图,然后才能将两者都输入到神经网络中。
正如我之前提到的,流行程度会被简化成一个二进制标签,使模型更简单,因为流行程度的多少与是否受欢迎相比并没有更多的描述性质。
梅尔频谱图是一种广为人知的以图像格式来表示音频数据的工具。它将音频分解为频率(梅尔频率是一种更接近人类听觉的频率尺度)并显示频率随时间的分布。这样,模型可以侦测到有关于节拍、音色等等的样式。
# making train test holdout splits
# train = 75%, test = 15%, holdout = 10%
X = mp3s.drop(columns=['popularity'])
y = mp3s['popularity']
X_pretr, X_holdout, y_pretr, y_holdout = train_test_split(X, y, test_size=0.10, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X_pretr, y_pretr, test_size=15/90, random_state=42)
print(X_train.shape, X_test.shape, X_holdout.shape)
(12125, 9) (2426, 9) (1617, 9)流行程度
39看起来是一个不错的截断值。
fig, ax = plt.subplots(figsize=(10,6))
y_train.hist(bins=95, ax=ax)
ax.grid(False)
ax.set(title='Popularity', xlabel='Score', ylabel='Song Count')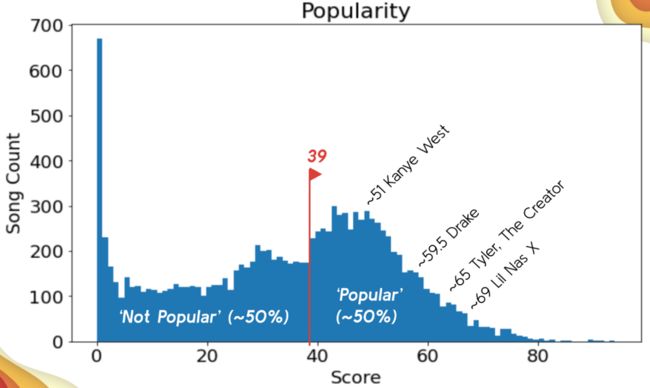
Fig 7 最终流行程度截断值(文字和截断值的记号在图表生成后才加上)
# defining popular as >= 39 and encoding (1 = popular)
y_train = y_train.map(lambda x: 1 if x >= 39 else 0)
y_train.value_counts(normalize=True)0 0.512
1 0.488
Name: popularity, dtype: float64y_test = y_test.map(lambda x: 1 if x >= 39 else 0)
y_test.value_counts(normalize=True)0 0.516076
1 0.483924
Name: popularity, dtype: float64y_holdout = y_holdout.map(lambda x: 1 if x >= 39 else 0)
y_holdout.value_counts(normalize=True)0 0.506494
1 0.493506
Name: popularity, dtype: float64梅尔频谱图的处理
查看 github 以获取有关代码的更多详细信息,因为它的内容对于一篇博客文章来说实在是太多了。
一般来说,处理流程是这样的:
1. 从 http 链接取得 .mp3
2. 使用 pydub.AudioSegment 将 .mp3 转换为 .wav
3. 获取梅尔频谱图以供训练、测试和Holdout的拆分
4. 缩放频谱图(简单的最小值-最大值,用来拟合训练数据)
让我们看一个波形的示例。这是 Lil Nas X 的“INDUSTRY BABY (feat. Jack Harlow)”—一首非常受欢迎的歌曲,它的原始流行程度得分为 90。如你所见,它长达 30 秒并具有各种幅度。
# visualize waveform
y, sr = librosa.load('data/X_train/wav/10564.wav',duration=30)
fig, ax = plt.subplots(figsize=(10,6))
librosa.display.waveshow(y, sr=sr, ax=ax);
ax.set(title='Waveform', xlabel='Time (sec)', ylabel='Amplitude')
plt.savefig('images/waveform.png');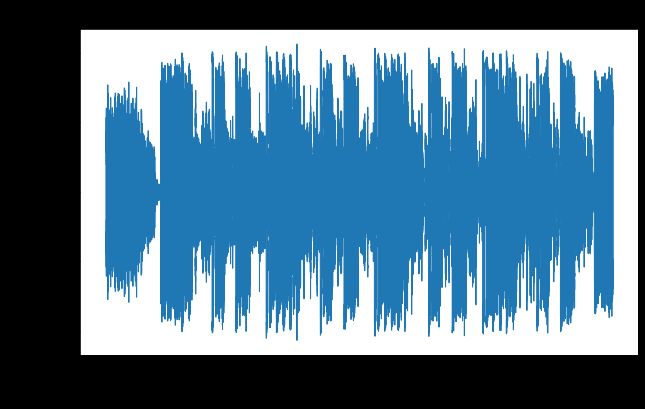
下面是相对应的梅尔频谱图。有趣的是,随着歌曲的进行,您可以分辨出和弦、旋律和节奏(以及其他内容)的形状。这些对模型来说非常重要。
fig, ax = plt.subplots(figsize=(10,6))
img = librosa.display.specshow(X_train[4118][:,:,0], x_axis='time',
y_axis='mel', fmax=11025, ax=ax)
fig.colorbar(img, ax=ax, format='%+.1f dB')
ax.set(title='Mel Spectrogram', xlabel='Time (sec)', ylabel='Frequency (mels)')
plt.savefig('images/melspec.png');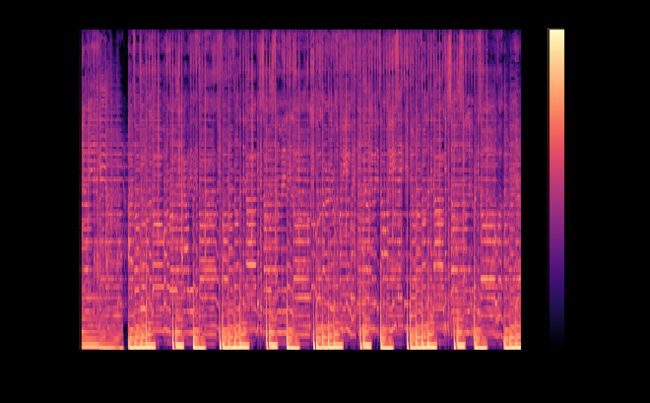
Fig 8 相对应的梅尔频谱图(未缩放)
建模
频谱图也是一种图像的一种,因此整个模型流程类似于使用神经网络的图像分类问题。
我从基准模型开始,然后转向传统的多层感知器。我用几种不同的卷积配置来建立神经网络,然后用一个包含门控循环单元(Gated recurrent unit)的卷积神经网络来完成,该模型是一种递归/循环神经网络。
随着我增加模型的复杂性,我的目标是增加的复杂度来加强模型在与目标相关的频谱图中获取潜在样式的能力。在介绍每个模型迭代时,我会详细解释我的设计思路。
理解基准模型
当我在训练神经网络时,我需要了解未经训练/无用处的神经网络会有怎样的表现。通过查看一个虚拟分类器(dummy classifier)来我可以了解到这一结果,该分类器仅预测每首歌曲的主要类别。
dummy = DummyClassifier(random_state=42)
dummy.fit(X_train, y_train)
dummypreds = dummy.predict(X_test)
print(f"Dummy Accuracy: {accuracy_score(y_test, dummypreds)}")
print(f"Dummy ROC-AUC: {roc_auc_score(y_test, dummypreds)}")Dummy Accuracy: 0.516075845012366
Dummy ROC-AUC: 0.5正如预期一样,模型的表现很差。对于仅预测“不受欢迎”的模型的表现,以上数字是值得参照的结果。
多层感知器
现在我们已经了解了最坏的情况,可以进一步地建立最简单的神经网络类型。我认为单层感知器特别没用,所以我选择了稍微复杂但仍然简单的 2 层密集模型。
128 和 64 个节点是根据对这些类型模型的先前经验而相对任意地选择出来的。
input_shape = X_train.shape[1:]
batch_size = X_train.shape[0]/100# set random seed for reproducibility
np.random.seed(42)
set_seed(42)
# build sequentially
mlp = keras.Sequential(name='mlp')
# flatten input 3D tensor to 1D
mlp.add(layers.Flatten(input_shape=input_shape))
# two hidden layers
mlp.add(layers.Dense(128, activation='relu'))
mlp.add(layers.Dense(64, activation='relu'))
# output layer
mlp.add(layers.Dense(1, activation='sigmoid'))
# compile perceptron
mlp.compile(loss='binary_crossentropy',
optimizer="adam",
metrics=['accuracy', 'AUC'])
# take a look at model architecture
mlp.summary()Model: "mlp"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 165376) 0
dense (Dense) (None, 128) 21168256
dense_1 (Dense) (None, 64) 8256
dense_2 (Dense) (None, 1) 65
=================================================================
Total params: 21,176,577
Trainable params: 21,176,577
Non-trainable params: 0
_________________________________________________________________mlp_history = mlp.fit(X_train, y_train, epochs=20, batch_size=30,
validation_data=(X_test, y_test))Epoch 1/20
346/346 [==============================] - 10s 28ms/step - loss: 0.8132 - accuracy: 0.4975 - auc: 0.5008 - val_loss: 0.8145 - val_accuracy: 0.5161 - val_auc: 0.4437
Epoch 2/20
346/346 [==============================] - 9s 27ms/step - loss: 0.7078 - accuracy: 0.5031 - auc: 0.5002 - val_loss: 0.6934 - val_accuracy: 0.4971 - val_auc: 0.5652
Epoch 3/20
346/346 [==============================] - 10s 28ms/step - loss: 0.7144 - accuracy: 0.5046 - auc: 0.5035 - val_loss: 0.6919 - val_accuracy: 0.5161 - val_auc: 0.5573
Epoch 4/20
346/346 [==============================] - 10s 29ms/step - loss: 0.6962 - accuracy: 0.5039 - auc: 0.5015 - val_loss: 0.6923 - val_accuracy: 0.5161 - val_auc: 0.5369
Epoch 5/20
346/346 [==============================] - 11s 30ms/step - loss: 0.6930 - accuracy: 0.5097 - auc: 0.5040 - val_loss: 0.6934 - val_accuracy: 0.5161 - val_auc: 0.5004
Epoch 6/20
346/346 [==============================] - 9s 27ms/step - loss: 0.6933 - accuracy: 0.5077 - auc: 0.5010 - val_loss: 0.6926 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 7/20
346/346 [==============================] - 10s 28ms/step - loss: 0.6929 - accuracy: 0.5112 - auc: 0.4996 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 8/20
346/346 [==============================] - 10s 28ms/step - loss: 0.6930 - accuracy: 0.5112 - auc: 0.4888 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 9/20
346/346 [==============================] - 10s 28ms/step - loss: 0.6930 - accuracy: 0.5112 - auc: 0.4966 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 10/20
346/346 [==============================] - 10s 28ms/step - loss: 0.6930 - accuracy: 0.5112 - auc: 0.4961 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 11/20
346/346 [==============================] - 10s 28ms/step - loss: 0.6930 - accuracy: 0.5112 - auc: 0.4947 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 12/20
346/346 [==============================] - 10s 28ms/step - loss: 0.6929 - accuracy: 0.5112 - auc: 0.4977 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 13/20
346/346 [==============================] - 10s 28ms/step - loss: 0.6930 - accuracy: 0.5112 - auc: 0.4937 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 14/20
346/346 [==============================] - 10s 28ms/step - loss: 0.6930 - accuracy: 0.5112 - auc: 0.4994 - val_loss: 0.6928 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 15/20
346/346 [==============================] - 10s 28ms/step - loss: 0.6929 - accuracy: 0.5112 - auc: 0.5009 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 16/20
346/346 [==============================] - 10s 28ms/step - loss: 0.6930 - accuracy: 0.5112 - auc: 0.4951 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 17/20
346/346 [==============================] - 10s 30ms/step - loss: 0.6930 - accuracy: 0.5112 - auc: 0.4899 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 18/20
346/346 [==============================] - 10s 28ms/step - loss: 0.6930 - accuracy: 0.5112 - auc: 0.4937 - val_loss: 0.6926 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 19/20
346/346 [==============================] - 10s 28ms/step - loss: 0.6930 - accuracy: 0.5112 - auc: 0.5026 - val_loss: 0.6929 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 20/20
346/346 [==============================] - 10s 28ms/step - loss: 0.6930 - accuracy: 0.5112 - auc: 0.4942 - val_loss: 0.6928 - val_accuracy: 0.5161 - val_auc: 0.5000visualize_training_results(mlp_history)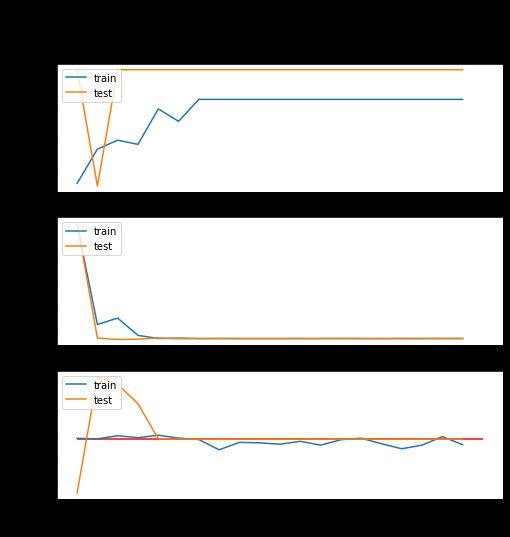
Fig 9 MLP 结果
正如预期的一样,多层感知器并没有带来特别好的结果。在 5 个迭代之后,指标趋于平稳,即使在训练数据中也是如此。这告诉我们,这个模型很难找到任何有用的东西。测试准确率和 ROC-AUC 也与虚拟分类器的结果相匹配,因此它绝对没有用处。
卷积神经网络
现在让我们添加卷积功能来帮助模型更好地解析视觉信息。一般来说,卷积架构用于图像处理,可以将越来越大的图像块组合在一起。
这项工作通常使用卷积组件完成,然后将其馈送到密集连接的感知器中。
下面的架构改编自之前的项目,我们使用与此处使用的类似过程构建了一个类别分类器。可以在此处找到该项目的 GitHub 存储库。
# set random seed for reproducibility
np.random.seed(42)
set_seed(42)
# build sequentially
cnn1 = keras.Sequential(name='cnn1')
# convolutional and max pooling layers with successively more filters
cnn1.add(layers.Conv2D(16, (3, 3), activation='relu', padding='same', input_shape=input_shape))
cnn1.add(layers.MaxPooling2D((2, 4)))
cnn1.add(layers.Conv2D(32, (3, 3), activation='relu', padding='same'))
cnn1.add(layers.MaxPooling2D((2, 4)))
cnn1.add(layers.Conv2D(64, (3, 3), activation='relu', padding='same'))
cnn1.add(layers.MaxPooling2D((2, 2)))
cnn1.add(layers.Conv2D(128, (3, 3), activation='relu', padding='same'))
cnn1.add(layers.MaxPool2D((2, 2)))
# fully-connected layers for output
cnn1.add(layers.Flatten())
cnn1.add(layers.Dense(128, activation='relu'))
cnn1.add(layers.Dropout(0.3))
cnn1.add(layers.Dense(64, activation='relu'))
cnn1.add(layers.Dropout(0.3))
# output layer
cnn1.add(layers.Dense(1, activation='sigmoid'))
# compile cnn
cnn1.compile(loss='binary_crossentropy',
optimizer="adam",
metrics=['accuracy', 'AUC'])
# take a look at model architecture
cnn1.summary()Model: "cnn1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 128, 1292, 16) 160
max_pooling2d (MaxPooling2D (None, 64, 323, 16) 0
)
conv2d_1 (Conv2D) (None, 64, 323, 32) 4640
max_pooling2d_1 (MaxPooling (None, 32, 80, 32) 0
2D)
conv2d_2 (Conv2D) (None, 32, 80, 64) 18496
max_pooling2d_2 (MaxPooling (None, 16, 40, 64) 0
2D)
conv2d_3 (Conv2D) (None, 16, 40, 128) 73856
max_pooling2d_3 (MaxPooling (None, 8, 20, 128) 0
2D)
flatten_1 (Flatten) (None, 20480) 0
dense_3 (Dense) (None, 128) 2621568
dropout (Dropout) (None, 128) 0
dense_4 (Dense) (None, 64) 8256
dropout_1 (Dropout) (None, 64) 0
dense_5 (Dense) (None, 1) 65
=================================================================
Total params: 2,727,041
Trainable params: 2,727,041
Non-trainable params: 0
_________________________________________________________________cnn1_history = cnn1.fit(X_train, y_train, epochs=20, batch_size=100,
validation_data=(X_test, y_test))Epoch 1/20
104/104 [==============================] - 152s 1s/step - loss: 0.6937 - accuracy: 0.5081 - auc: 0.4969 - val_loss: 0.6926 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 2/20
104/104 [==============================] - 152s 1s/step - loss: 0.6930 - accuracy: 0.5074 - auc: 0.5047 - val_loss: 0.6929 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 3/20
104/104 [==============================] - 151s 1s/step - loss: 0.6932 - accuracy: 0.5114 - auc: 0.4907 - val_loss: 0.6928 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 4/20
104/104 [==============================] - 151s 1s/step - loss: 0.6929 - accuracy: 0.5112 - auc: 0.5015 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5043
Epoch 5/20
104/104 [==============================] - 151s 1s/step - loss: 0.6930 - accuracy: 0.5112 - auc: 0.4978 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 6/20
104/104 [==============================] - 151s 1s/step - loss: 0.6929 - accuracy: 0.5112 - auc: 0.4984 - val_loss: 0.6926 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 7/20
104/104 [==============================] - 150s 1s/step - loss: 0.6928 - accuracy: 0.5111 - auc: 0.5071 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5032
Epoch 8/20
104/104 [==============================] - 148s 1s/step - loss: 0.6929 - accuracy: 0.5120 - auc: 0.5002 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 9/20
104/104 [==============================] - 149s 1s/step - loss: 0.6930 - accuracy: 0.5114 - auc: 0.4937 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 10/20
104/104 [==============================] - 152s 1s/step - loss: 0.6930 - accuracy: 0.5116 - auc: 0.4982 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 11/20
104/104 [==============================] - 152s 1s/step - loss: 0.6930 - accuracy: 0.5108 - auc: 0.4994 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 12/20
104/104 [==============================] - 155s 1s/step - loss: 0.6928 - accuracy: 0.5112 - auc: 0.5051 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 13/20
104/104 [==============================] - 150s 1s/step - loss: 0.6930 - accuracy: 0.5111 - auc: 0.4957 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 14/20
104/104 [==============================] - 150s 1s/step - loss: 0.6930 - accuracy: 0.5112 - auc: 0.4986 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 15/20
104/104 [==============================] - 153s 1s/step - loss: 0.6930 - accuracy: 0.5118 - auc: 0.4976 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 16/20
104/104 [==============================] - 150s 1s/step - loss: 0.6930 - accuracy: 0.5112 - auc: 0.4946 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 17/20
104/104 [==============================] - 149s 1s/step - loss: 0.6929 - accuracy: 0.5112 - auc: 0.4928 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 18/20
104/104 [==============================] - 155s 1s/step - loss: 0.6930 - accuracy: 0.5112 - auc: 0.4981 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 19/20
104/104 [==============================] - 150s 1s/step - loss: 0.6930 - accuracy: 0.5112 - auc: 0.4974 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 20/20
104/104 [==============================] - 149s 1s/step - loss: 0.6929 - accuracy: 0.5112 - auc: 0.4956 - val_loss: 0.6927 - val_accuracy: 0.5161 - val_auc: 0.5000visualize_training_results(cnn1_history)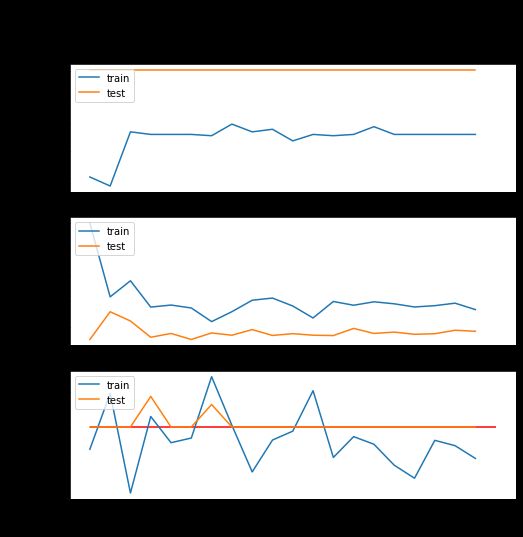
Fig 10 第一个CNN的结果
第一个CNN没有太好的表现。它似乎比多层感知器更具反应,但不是产生有用结果的形式。测试数据最终变成了虚拟分类器值,所以这也是一个没有用的模型。
卷积神经网络(第 2 次尝试)
这里采用与上面完全相同的架构,只是没有第二个密致层。这和我之前提到的 Music Genre Classification 项目中的第一个迭代模型是一样的。
在进行项目时,我注意到如果将 CNN 连接到单个密致层,它的表现会更好。这虽然不直观,但我仍然想尝试一下。
# set random seed for reproducibility
np.random.seed(42)
set_seed(42)
# build sequentially
cnn2 = keras.Sequential(name='cnn2')
# convolutional and max pooling layers with successively more filters
cnn2.add(layers.Conv2D(16, (3, 3), activation='relu', padding='same', input_shape=input_shape))
cnn2.add(layers.MaxPooling2D((2, 4)))
cnn2.add(layers.Conv2D(32, (3, 3), activation='relu', padding='same'))
cnn2.add(layers.MaxPooling2D((2, 4)))
cnn2.add(layers.Conv2D(64, (3, 3), activation='relu', padding='same'))
cnn2.add(layers.MaxPooling2D((2, 2)))
cnn2.add(layers.Conv2D(128, (3, 3), activation='relu', padding='same'))
cnn2.add(layers.MaxPool2D((2, 2)))
# fully-connected layer for output
cnn2.add(layers.Flatten())
cnn2.add(layers.Dense(128, activation='relu'))
# output layer
cnn2.add(layers.Dense(1, activation='sigmoid'))
# compile cnn
cnn2.compile(loss='binary_crossentropy',
optimizer="adam",
metrics=['accuracy', 'AUC'])
# take a look at model architecture
cnn2.summary()Model: "cnn2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 128, 1292, 16) 160
max_pooling2d_4 (MaxPooling (None, 64, 323, 16) 0
2D)
conv2d_5 (Conv2D) (None, 64, 323, 32) 4640
max_pooling2d_5 (MaxPooling (None, 32, 80, 32) 0
2D)
conv2d_6 (Conv2D) (None, 32, 80, 64) 18496
max_pooling2d_6 (MaxPooling (None, 16, 40, 64) 0
2D)
conv2d_7 (Conv2D) (None, 16, 40, 128) 73856
max_pooling2d_7 (MaxPooling (None, 8, 20, 128) 0
2D)
flatten_1 (Flatten) (None, 20480) 0
dense_2 (Dense) (None, 128) 2621568
dense_3 (Dense) (None, 1) 129
=================================================================
Total params: 2,718,849
Trainable params: 2,718,849
Non-trainable params: 0
_________________________________________________________________cnn2_history = cnn2.fit(X_train, y_train, epochs=20, batch_siz=100,
validation_data=(X_test, y_test))Epoch 1/20
104/104 [==============================] - 144s 1s/step - loss: 0.6943 - accuracy: 0.5069 - auc: 0.5027 - val_loss: 0.6929 - val_accuracy: 0.5161 - val_auc: 0.4861
Epoch 2/20
104/104 [==============================] - 140s 1s/step - loss: 0.6932 - accuracy: 0.5074 - auc: 0.4978 - val_loss: 0.6930 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 3/20
104/104 [==============================] - 139s 1s/step - loss: 0.6932 - accuracy: 0.5088 - auc: 0.5013 - val_loss: 0.6930 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 4/20
104/104 [==============================] - 139s 1s/step - loss: 0.6930 - accuracy: 0.5095 - auc: 0.4984 - val_loss: 0.6928 - val_accuracy: 0.5161 - val_auc: 0.5102
Epoch 5/20
104/104 [==============================] - 140s 1s/step - loss: 0.6929 - accuracy: 0.5121 - auc: 0.5119 - val_loss: 0.6926 - val_accuracy: 0.5161 - val_auc: 0.5000
Epoch 6/20
104/104 [==============================] - 139s 1s/step - loss: 0.6928 - accuracy: 0.5112 - auc: 0.5153 - val_loss: 0.6925 - val_accuracy: 0.5161 - val_auc: 0.5096
Epoch 7/20
104/104 [==============================] - 138s 1s/step - loss: 0.6927 - accuracy: 0.5144 - auc: 0.5148 - val_loss: 0.6915 - val_accuracy: 0.5474 - val_auc: 0.5670
Epoch 8/20
104/104 [==============================] - 137s 1s/step - loss: 0.6934 - accuracy: 0.5106 - auc: 0.5047 - val_loss: 0.6924 - val_accuracy: 0.5161 - val_auc: 0.5395
Epoch 9/20
104/104 [==============================] - 137s 1s/step - loss: 0.6925 - accuracy: 0.5115 - auc: 0.5183 - val_loss: 0.6931 - val_accuracy: 0.5161 - val_auc: 0.4675
Epoch 10/20
104/104 [==============================] - 137s 1s/step - loss: 0.6923 - accuracy: 0.5163 - auc: 0.5186 - val_loss: 0.6936 - val_accuracy: 0.4918 - val_auc: 0.5717
Epoch 11/20
104/104 [==============================] - 138s 1s/step - loss: 0.6926 - accuracy: 0.5178 - auc: 0.5260 - val_loss: 0.6917 - val_accuracy: 0.5260 - val_auc: 0.5594
Epoch 12/20
104/104 [==============================] - 140s 1s/step - loss: 0.6896 - accuracy: 0.5247 - auc: 0.5415 - val_loss: 0.6869 - val_accuracy: 0.5400 - val_auc: 0.5728
Epoch 13/20
104/104 [==============================] - 136s 1s/step - loss: 0.6876 - accuracy: 0.5356 - auc: 0.5477 - val_loss: 0.6862 - val_accuracy: 0.5396 - val_auc: 0.5769
Epoch 14/20
104/104 [==============================] - 136s 1s/step - loss: 0.6863 - accuracy: 0.5379 - auc: 0.5572 - val_loss: 0.6863 - val_accuracy: 0.5408 - val_auc: 0.5772
Epoch 15/20
104/104 [==============================] - 137s 1s/step - loss: 0.6854 - accuracy: 0.5460 - auc: 0.5625 - val_loss: 0.6850 - val_accuracy: 0.5433 - val_auc: 0.5788
Epoch 16/20
104/104 [==============================] - 143s 1s/step - loss: 0.6835 - accuracy: 0.5496 - auc: 0.5703 - val_loss: 0.6855 - val_accuracy: 0.5400 - val_auc: 0.5811
Epoch 17/20
104/104 [==============================] - 137s 1s/step - loss: 0.6878 - accuracy: 0.5363 - auc: 0.5500 - val_loss: 0.6854 - val_accuracy: 0.5412 - val_auc: 0.5762
Epoch 18/20
104/104 [==============================] - 136s 1s/step - loss: 0.6839 - accuracy: 0.5442 - auc: 0.5686 - val_loss: 0.6882 - val_accuracy: 0.5466 - val_auc: 0.5743
Epoch 19/20
104/104 [==============================] - 136s 1s/step - loss: 0.6833 - accuracy: 0.5532 - auc: 0.5707 - val_loss: 0.6856 - val_accuracy: 0.5425 - val_auc: 0.5710
Epoch 20/20
104/104 [==============================] - 136s 1s/step - loss: 0.6832 - accuracy: 0.5545 - auc: 0.5717 - val_loss: 0.6837 - val_accuracy: 0.5453 - val_auc: 0.5821visualize_training_results(cnn2_history)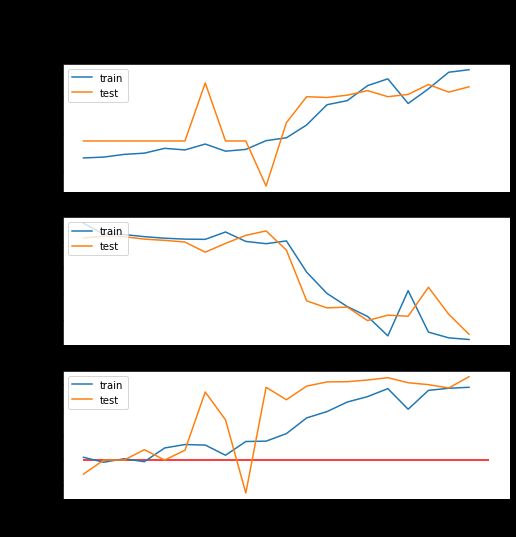
Fig 11 第二个CNN的结果
哇,模型有一点进展了!太好了!它并没有像第一个模型以虚拟分类器值结束,所以我可以确定它确实有学到了一些东西。最后,我们可以看到,模型开始在训练数据上过度拟合,但在训练结束时,测试分数趋于稳定于一个较好的水平。
循环神经网络
最后,我们尝试套用一下循环神经网络。我会采用这篇论文内的架构,然后将它改为二进制分类的形式。在该篇文献中,作者尝试这种技术能分类音乐创作人。
模型一开始使用卷积元件,如同先前的两个模型一样,但之后输出会反馈到一个门控循环单元,其功能是”根据2D卷积总结时间结构”。换句话说,该单元可以使神经网络根据先前卷积部分学习到的东西,找到时间上的样式。
挺有趣的,不是吗?
# set random seed for reproducibility
np.random.seed(42)
set_seed(42)
# build sequentially
rnn = keras.Sequential(name='rnn')
# convolutional and max pooling layers with successively more filters
rnn.add(layers.Conv2D(64, (3, 3), activation='elu', padding='same', input_shape=input_shape))
rnn.add(layers.MaxPooling2D((2, 2)))
rnn.add(layers.Dropout(0.1))
rnn.add(layers.Conv2D(128, (3, 3), activation='elu', padding='same'))
rnn.add(layers.MaxPooling2D((4, 2)))
rnn.add(layers.Dropout(0.1))
rnn.add(layers.Conv2D(128, (3, 3), activation='elu', padding='same'))
rnn.add(layers.MaxPooling2D((4, 2)))
rnn.add(layers.Dropout(0.1))
rnn.add(layers.Conv2D(128, (3, 3), activation='elu', padding='same'))
rnn.add(layers.MaxPool2D((4, 2)))
rnn.add(layers.Dropout(0.1))
rnn.add(layers.Reshape((80,128)))
rnn.add(layers.GRU(units=32, dropout=0.3, return_sequences=True))
rnn.add(layers.GRU(units=32, dropout=0.3))
# output layer
rnn.add(layers.Dense(1, activation='sigmoid'))
# compile cnn
rnn.compile(loss='binary_crossentropy',
optimizer="adam",
metrics=['accuracy', 'AUC'])
# take a look at model architecture
rnn.summary()Model: "rnn"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 128, 1292, 64) 640
max_pooling2d (MaxPooling2D (None, 64, 646, 64) 0
)
dropout (Dropout) (None, 64, 646, 64) 0
conv2d_1 (Conv2D) (None, 64, 646, 128) 73856
max_pooling2d_1 (MaxPooling (None, 16, 323, 128) 0
2D)
dropout_1 (Dropout) (None, 16, 323, 128) 0
conv2d_2 (Conv2D) (None, 16, 323, 128) 147584
max_pooling2d_2 (MaxPooling (None, 4, 161, 128) 0
2D)
dropout_2 (Dropout) (None, 4, 161, 128) 0
conv2d_3 (Conv2D) (None, 4, 161, 128) 147584
max_pooling2d_3 (MaxPooling (None, 1, 80, 128) 0
2D)
dropout_3 (Dropout) (None, 1, 80, 128) 0
reshape (Reshape) (None, 80, 128) 0
gru (GRU) (None, 80, 32) 15552
gru_1 (GRU) (None, 32) 6336
dense (Dense) (None, 1) 33
=================================================================
Total params: 391,585
Trainable params: 391,585
Non-trainable params: 0
_________________________________________________________________rnn_history = rnn.fit(X_train, y_train, epochs=30, batch_size=100,
validation_data=(X_test, y_test))Epoch 1/30
104/104 [==============================] - 948s 9s/step - loss: 0.6970 - accuracy: 0.5051 - auc: 0.4990 - val_loss: 0.6913 - val_accuracy: 0.5223 - val_auc: 0.5421
Epoch 2/30
104/104 [==============================] - 933s 9s/step - loss: 0.6932 - accuracy: 0.5156 - auc: 0.5170 - val_loss: 0.6940 - val_accuracy: 0.5161 - val_auc: 0.5173
Epoch 3/30
104/104 [==============================] - 953s 9s/step - loss: 0.6932 - accuracy: 0.5153 - auc: 0.5186 - val_loss: 0.6908 - val_accuracy: 0.5161 - val_auc: 0.5515
Epoch 4/30
104/104 [==============================] - 947s 9s/step - loss: 0.6906 - accuracy: 0.5260 - auc: 0.5372 - val_loss: 0.6883 - val_accuracy: 0.5289 - val_auc: 0.5532
Epoch 5/30
104/104 [==============================] - 960s 9s/step - loss: 0.6881 - accuracy: 0.5328 - auc: 0.5526 - val_loss: 0.6876 - val_accuracy: 0.5317 - val_auc: 0.5649
Epoch 6/30
104/104 [==============================] - 955s 9s/step - loss: 0.6874 - accuracy: 0.5369 - auc: 0.5558 - val_loss: 0.6875 - val_accuracy: 0.5441 - val_auc: 0.5646
Epoch 7/30
104/104 [==============================] - 951s 9s/step - loss: 0.6868 - accuracy: 0.5429 - auc: 0.5609 - val_loss: 0.6863 - val_accuracy: 0.5276 - val_auc: 0.5869
Epoch 8/30
104/104 [==============================] - 961s 9s/step - loss: 0.6896 - accuracy: 0.5329 - auc: 0.5498 - val_loss: 0.6909 - val_accuracy: 0.5293 - val_auc: 0.5688
Epoch 9/30
104/104 [==============================] - 966s 9s/step - loss: 0.6870 - accuracy: 0.5451 - auc: 0.5639 - val_loss: 0.6830 - val_accuracy: 0.5540 - val_auc: 0.5773
Epoch 10/30
104/104 [==============================] - 978s 9s/step - loss: 0.6857 - accuracy: 0.5511 - auc: 0.5658 - val_loss: 0.6826 - val_accuracy: 0.5556 - val_auc: 0.5868
Epoch 11/30
104/104 [==============================] - 963s 9s/step - loss: 0.6865 - accuracy: 0.5436 - auc: 0.5640 - val_loss: 0.6810 - val_accuracy: 0.5676 - val_auc: 0.5884
Epoch 12/30
104/104 [==============================] - 972s 9s/step - loss: 0.6835 - accuracy: 0.5565 - auc: 0.5793 - val_loss: 0.6790 - val_accuracy: 0.5750 - val_auc: 0.6003
Epoch 13/30
104/104 [==============================] - 960s 9s/step - loss: 0.6837 - accuracy: 0.5563 - auc: 0.5772 - val_loss: 0.6851 - val_accuracy: 0.5478 - val_auc: 0.5953
Epoch 14/30
104/104 [==============================] - 969s 9s/step - loss: 0.6816 - accuracy: 0.5640 - auc: 0.5863 - val_loss: 0.6784 - val_accuracy: 0.5709 - val_auc: 0.6051
Epoch 15/30
104/104 [==============================] - 961s 9s/step - loss: 0.6807 - accuracy: 0.5679 - auc: 0.5901 - val_loss: 0.6771 - val_accuracy: 0.5697 - val_auc: 0.6011
Epoch 16/30
104/104 [==============================] - 967s 9s/step - loss: 0.6793 - accuracy: 0.5719 - auc: 0.5957 - val_loss: 0.6834 - val_accuracy: 0.5668 - val_auc: 0.5973
Epoch 17/30
104/104 [==============================] - 961s 9s/step - loss: 0.6801 - accuracy: 0.5682 - auc: 0.5927 - val_loss: 0.6785 - val_accuracy: 0.5783 - val_auc: 0.5988
Epoch 18/30
104/104 [==============================] - 967s 9s/step - loss: 0.6793 - accuracy: 0.5716 - auc: 0.5932 - val_loss: 0.6931 - val_accuracy: 0.5602 - val_auc: 0.5948
Epoch 19/30
104/104 [==============================] - 972s 9s/step - loss: 0.6811 - accuracy: 0.5654 - auc: 0.5888 - val_loss: 0.6843 - val_accuracy: 0.5441 - val_auc: 0.5977
Epoch 20/30
104/104 [==============================] - 958s 9s/step - loss: 0.6759 - accuracy: 0.5754 - auc: 0.6050 - val_loss: 0.6764 - val_accuracy: 0.5779 - val_auc: 0.6049
Epoch 21/30
104/104 [==============================] - 972s 9s/step - loss: 0.6741 - accuracy: 0.5849 - auc: 0.6108 - val_loss: 0.6796 - val_accuracy: 0.5688 - val_auc: 0.5943
Epoch 22/30
104/104 [==============================] - 972s 9s/step - loss: 0.6706 - accuracy: 0.5895 - auc: 0.6195 - val_loss: 0.6898 - val_accuracy: 0.5581 - val_auc: 0.5958
Epoch 23/30
104/104 [==============================] - 968s 9s/step - loss: 0.6727 - accuracy: 0.5821 - auc: 0.6149 - val_loss: 0.6797 - val_accuracy: 0.5767 - val_auc: 0.6058
Epoch 24/30
104/104 [==============================] - 966s 9s/step - loss: 0.6705 - accuracy: 0.5877 - auc: 0.6203 - val_loss: 0.6753 - val_accuracy: 0.5717 - val_auc: 0.6027
Epoch 25/30
104/104 [==============================] - 974s 9s/step - loss: 0.6667 - accuracy: 0.5915 - auc: 0.6289 - val_loss: 0.6816 - val_accuracy: 0.5660 - val_auc: 0.6017
Epoch 26/30
104/104 [==============================] - 973s 9s/step - loss: 0.6664 - accuracy: 0.5997 - auc: 0.6308 - val_loss: 0.6820 - val_accuracy: 0.5730 - val_auc: 0.6105
Epoch 27/30
104/104 [==============================] - 971s 9s/step - loss: 0.6701 - accuracy: 0.5872 - auc: 0.6207 - val_loss: 0.6792 - val_accuracy: 0.5775 - val_auc: 0.5988
Epoch 28/30
104/104 [==============================] - 976s 9s/step - loss: 0.6669 - accuracy: 0.5958 - auc: 0.6298 - val_loss: 0.6959 - val_accuracy: 0.5350 - val_auc: 0.6071
Epoch 29/30
104/104 [==============================] - 1424s 14s/step - loss: 0.6650 - accuracy: 0.5948 - auc: 0.6336 - val_loss: 0.6758 - val_accuracy: 0.5787 - val_auc: 0.6059
Epoch 30/30
104/104 [==============================] - 971s 9s/step - loss: 0.6666 - accuracy: 0.6011 - auc: 0.6315 - val_loss: 0.6716 - val_accuracy: 0.5837 - val_auc: 0.6152visualize_training_results(rnn_history)
Fig 12 CNN-GRU的结果
结果一点也不坏!明显地,结果没有惊喜之处,但也不是没有价值。我们可以清楚地看到,这一种神经网络架构有发掘到音乐中存在的一些特征。模型在准确度有~7-8%的提升,而ROC-AUC则进步了~0.1,这是一个明显的改进。这绝对对其可行性给予了肯定,甚至在一定程度上有应用价值。
Holdout 测试
models_dict = {'Dummy': dummy, 'MP': mlp_dict, 'CNN 1': cnn1_dict, 'CNN 2': cnn2_dict,
'RNN': rnn_dict}acc_dict, roc_auc_dict = evaluate_holdout(models_dict, X_holdout, y_holdout)# numerical scores for all the models
print("Accuracy Scores:")
for model, score in acc_dict.items():
print(f'{model}: {score}')
print("<>"*10)
print("ROC-AUC Scores:")
for model, score in roc_auc_dict.items():
print(f'{model}: {score}')Accuracy Scores:
Dummy: 0.5065015479876162
MP: 0.5065015479876162
CNN 1: 0.5065015479876162
CNN 2: 0.5523219814241486
RNN: 0.5981424148606811
<><><><><><><><><><>
ROC-AUC Scores:
Dummy: 0.5
MP: 0.5
CNN 1: 0.5
CNN 2: 0.5742730226123023
RNN: 0.645901654431502# graph!
plt.rcParams.update({'font.size': 20})
fig, (ax1, ax2) = plt.subplots(2, figsize=(9,9))
plt.tight_layout(pad=2.5)
fig.suptitle('Holdout Data Results')
ax1.bar(list(acc_dict.keys()), list(acc_dict.values()))
ax1.set_ylabel('Accuracy')
ax1.set_ylim(0.5, 1)
ax1.tick_params(axis='x', rotation=45)
ax2.bar(list(roc_auc_dict.keys()), list(roc_auc_dict.values()))
ax2.set_ylabel('ROC-AUC')
ax2.set_ylim(0.5, 1)
ax2.tick_params(axis='x', rotation=45)
plt.show()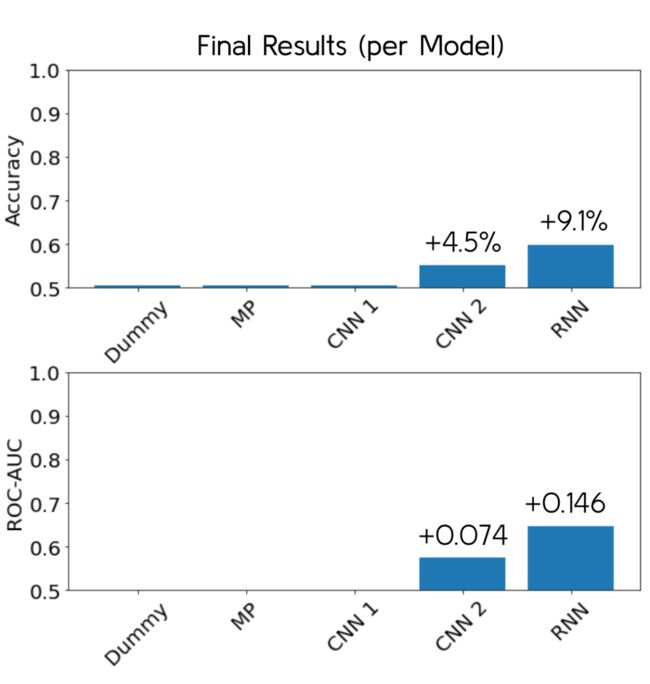 Fig 13 在 Holdout 集合上的最终结果
Fig 13 在 Holdout 集合上的最终结果
模型评估
如你所见,即使我们使用了一些非常复杂和前沿的神经网络架构,我们仍然没有在所选择的度量:准确度和ROC-AUC上取得大幅度的提升。这说明在利用模型成功分辨两个组别时,机器学习在其中所能起到的作用是有限的。
即使如此,我们仍然得到59.8%的准确度和0.646 ROC-AUC,这个结果也是没用的,该结果实际上是9,1%的准确度提升和0.146 ROC-AUC提升。进一步地,这个结果是在holdout集合上得到的,所以模型的确有得到样本中潜在的抽象样式,这是有趣和有用的。
如果我们让模型继续学习,它最终会过拟合训练集数据。无论如何,如果我使用LIME来分析的话,我相信我绝对可以得到有关模型实际上找到的样式的一些确切洞察。
总结
从一开始我便知道这个建模项目是十分有野心的。现在我已经完成它了,我可以从事后的角度说它做得并没有十分好,但它的表现也确实值得令人欣赏。坦白地说,我甚至一度认为模型会因为我设定的限制条件——即仅使用音频样本,而注定会在一定程度上失败。。但是,我的结果表明存在一些实用性。更重要的是,它确实展示了一个非常强大的概念证明。
建立一个能做到人耳难以胜任的事情的模型是一项挑战。不但数据难以通过任何类型的基本模式组合在一起,而且流行程度这一目标是模糊,且在本质上难以被量化。流行程度当中有很多因素,而我知道在音乐本身之外还有一些因素会对其结果产生很大影响。例如,许多糟糕的歌曲因与流行艺术家有关联而变得流行。
到最后,我得到了 59.8% 的准确率和 0.646 ROC-AUC,这是非常有希望的结果(有9.1% 的准确率和 0.146 ROC-AUC的提高 )。尽管在完成这个项目时所用到的方式必然会受到限制,但我仍能够建立一个利用流行歌曲的一些共同特征,并做出一些成功的预测的模型,。
这改变了我的模型可能有用的使用形式。我一开始着手建立一个模型来用作艺人在创作歌曲时的工具,以判断特定歌曲是否有流行的希望。而我最终得到的是可以接收许多有可能性的歌曲,并指出会流行的几首歌曲的一个模型。巧合的是,我的客户也经营着一家录音室,并与数十位艺术家保持联系,而他们每个人都有自己的歌曲合集。在模型的当前形式下,我们可以输入一组歌曲样本供它预测,然后可以把焦点放在它认为会“流行”的歌曲。此选择不能完全确定哪些歌曲会受欢迎,但它可以为艺人和我客户的录音室节省一点时间。
下一步的工作
在完成一定量的工作以后,我相信模型被充分地工具化,从而能对评估单个歌曲起到作用。显然,除了我为这个项目收集的数据之外,还有其他影响流行程度的因素,所以第一步是尝试将这些因素纳入模型之中。
在音频本身中,我们可以对样本进行不同的处理并提取其他相关信息。也许更关键的是,我们可以看看音乐本身之外存在的因素。当我打电话给我的客户谈论模型的表现时,他说的第一句话是“我并不感到惊讶”,因为他非常熟悉看似随意的因素是如何导致一首歌曲变得受欢迎的。曝光量是决定一首歌是否流行或者有多么流行的一个巨大因素。最好的例子——我的客户在 Spotify 上的热门歌曲是一些 TikTok 圈子中的配乐,其他非音乐本身因素包括发布时间和艺人信息。
此外,我在更高级的神经网络架构方面取得了一点成功——特别是门控循环单元(一种循环/递归神经网络)。通过研究其他架构并进一步调整现有架构有可能提高模型性能。
我在文章前面提到过,其中一个数据集的重大限制是曲目列表似乎并不完整。为了更全面地捕捉当代Hip-hop音乐的全貌,我需要重新评估我的收集方法以收集更多歌曲。
除了扩展现在所有的东西之外,我还想看看有什么有用的东西。我在文章的介绍中提到了使用 LIME(或类似的工具),但在这次模型中并没有最终使用它。这将是一个非常有用的工具,利用它我可以深入了解对模型预测产生最大影响的因素。特别是当我开始整合更多或者不同的输入、输入类型和架构,这类工具将帮助我深入了解实际发生的情况。此外,这也能告知艺人模型正在查看的歌曲的重要部分到底是什么。
原文标题︰
Using Deep Learning to Predict Hip-Hop Popularity on Spotify
编辑:于腾凯
校对:林亦霖
译者简介

Gabriel Ng,清华大学概率统计方向本科生在读,一个热爱于数据分析和语言学习(和音乐)的THUer,平日活动离不开学习、健身和音乐。喜欢从数据探勘各类问题的本质,从语言认识不同文化的故事。希望通过学习和经验的累积,能以不同的角度,理性地分析问题,感性地认识问题。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织