MySQL进阶系列:一条sql是怎么执行的
本文是在存储引擎是InnoDB的前提下
mysql中的针对表的操作可以分为增删改查四种操作,也就是常说的crud大法,根据类型分为DML(增删改)和DQL(查);今天就说下插入和查询的语句时如何在mysql中执行的。
不管是DML还是DQL都是要经过连接器,缓存,分析器,优化器,执行器调用存储引擎的API。在前四个阶段都是一样的流程,具体的可以参考 mysql基础架构篇,文章中有详细简介各个模块的作用,本文就不展开说了,后面我们详细说说执行器在存储引擎上是怎么查询和修改(删除/新增)的。
小知识:
扇区:磁盘存储的最小单位,扇区一般大小为512Byte。
磁盘块:文件系统与磁盘交互的的最小单位(计算机系统读写磁盘的最小单位),一个磁盘块由连续几个(2^n)扇区组成,块一般大小一般为4KB。
mysql的页:mysql中和磁盘交互的最小单位称为页,默认大小是16kb,也就是4个磁盘块。也就是说mysql在进行数据读取的是默认情况下一次就是读取16kb(可以修改),即是我只查询一条大小只有1kb的数据,mysql读取的也是16kb。
一条查询语句是怎么执行的
select查询比较简单,其实就是到硬盘上按照页(16kb)把数据加载到内存,然后再去匹配where条件,找出符合条件的数据;
-
如果where条件没有索引,那么就是全表扫描,遍历所有的数据页到内存,然后一个个匹配。
-
如果where条件是主键索引,那么就会把主键索引的数据页加载到内存,然后匹配到具体的行数据返回;
-
如果where条件是普通索引,那么就会把普通索引的数据页加载到内存,然后匹配到符合条件的叶子结点(B+树的叶子结点),如果能够使用覆盖索引,那么就会直接返回,如果不能使用覆盖索引,则会进行回表查询(走一次主键索引查询)。覆盖索引和回表不清楚的可以参考历史文章:需要知道的索引基础知识
一个更新语句是怎么执行的
更新语句首先要按照查询的流程执行,因为肯定要先知道是哪条记录,之后才能去更新这条记录。之后就是更新了,更新操作涉及到几个日志的记录,分别是undolog(InnoDB的回滚日志) ,redolog(InnoDB的数据持久化日志),binlog(mysql server的归档日志),下面我们看下他们之间是怎么配合完成数据更新的。
-
首先执行引擎按照条件找数据,如果内存中存在则直接返回,不存在查询后返回。
-
把查询出来的这条记录先放到undolog中,用于更新失败数据回滚,具体的使用可以参考上一篇文章mvcc
-
执行器调用存储引擎接口写入数据,在缓存池中修改这条记录,。
-
写redo日志,先把数据更新到redo日志的缓存中。
-
准备提交事务,把redo日志缓存刷入磁盘。这时候redolog 是prepare阶段(共有两个阶段prepare和commit),然后通知执行器完成。
-
执行器开始执行binlog写入磁盘。
-
然后调用存储引擎的事务提交接口,把redolog中的prepare改成commit状态,至此更新完成。
-
之后有IO线程以页为单位随机写入磁盘,把我们更新后的数据慢慢落入磁盘中。
两个日志是分开写的,所以很难保证两个日志数据一致,在恢复的时候尽量保证同时参考两个日志文件,如果一致才会提交,不一致丢弃。
假如在步骤8的时候更新失败,两种情况
-
sql执行失败,这时候使用undolog中记录的历史数据进行恢复即可。
-
断电或者进程重启,那么就会在下次重启的时候判断redolog是否是commit状态,如果是可以直接提交写入磁盘,如果不是commit状态,就会判断binlog是否完整(两阶段提交保证数据的一致性),如果完整那么数据有效,写入磁盘;如果不完整或者只有一个日志存在记录,直接丢弃即可。
我们要更新的数据是存在磁盘的任意位置,是属于随机IO,效率是很低的,这样mysql的并发无法保证,而redo日志和binlog属于预写日志,都是顺序IO,直接写入即可,效率要高很多,即是失败了也可以根据日志恢复。
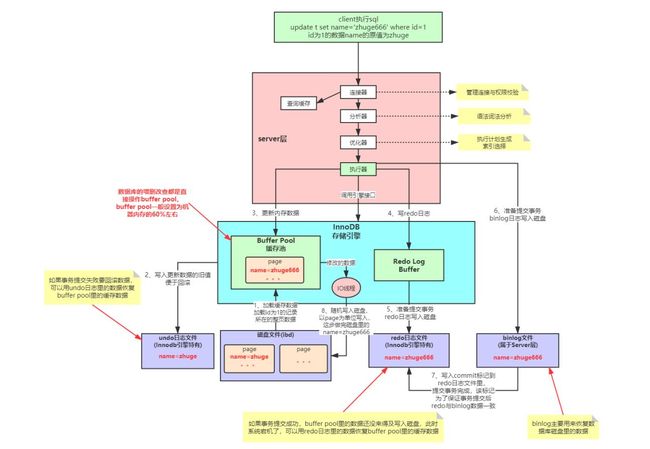
网上看的的一张图,画的非常好
为什么要设计两阶段提交:
写入的新数据属于脏页,只有更新到磁盘才能是完整的数据
反证一下:
假如先写redo log 后写binlog:如果在redolog写完,binlog还没写完,mysql崩溃重启。重启之后可以通过redolog恢复数据,但是binlog是没有这条数据的,所以后续用binlog备份数据或者进行主从同步的时候都会丢失这条数据,这样和原库的数据是不一致的。
假如先写binlog后写redolog:在binlog写完之后mysql崩溃,由于redolog 没有写入,奔溃重启之后也不会也不会恢复数据,但是binlog中已经完整记录这条记录,所以之后binlog备份和主从同步会有这条数据,这样和原库又不一致了。
总结
-
不管是查询语句还是更新语句,都要先经过连接器,查询缓存(8.0已经去掉了),分析器,优化器,执行器。
-
查询语句要选按照查询条件把数据所在的整页加载到内存。
-
更新语句在查询的基础上利用undo log,redo log,bin log 完成数据的更新。
-
undo log是用来sql执行失败之后回滚数据,保持事务的原子性。
-
redo log是用于mysql崩溃恢复,保证已提交事务的ACID特性。
-
binlog是数据记录的日志文件,用于数据备份,主从同步。
-
直接更新记录然后刷盘是随机IO,效率低下,所以使用redolog顺序写,提高效率。
-
两阶段提交能够崩溃恢复,保证数据的一致性。
原文地址:纪先生进阶指南
关注不迷路
MySQL高级相关更多内容,如事务,锁,MVCC,读写分离,分库分表等还在持续更新中,欢迎关注催更。
我是阿纪,用输出倒逼输入而持续学习,持续分享技术系列文章,以及全网值得收藏好文,欢迎关注公众号,做一个持续成长的技术人。
MySQL系列的历史文章
1. MySQL进阶系列:一文了解mysql基础架构;
2. MySQL进阶系列:一文了解mysql存储引擎;
3. MySQL进阶系列:mysql中MyISAM和InnoDB有什么区别;
4. MySQL进阶系列:mysql中表设计如何更好的选择数据类型;
5. MySQL进阶系列:数据库设计中的范式究竟该如何使用;
6. MySQL进阶系列:一文详解explain各字段含义;
7. MySQL进阶系列:为什么mysql使用B+作为索引的数据结构;
8. MySQL进阶系列: 你需要知道的一些索引基础知识;
9. MySQL进阶系列:怎么创建索引更合适;
10. MySQL进阶系列:主从复制原理和配置;
11. MySQL进阶系列:join连接的原理-3种算法;
12. MySQL进阶系列:事务及事务隔离级别;
13. MySQL进阶系列:多版本并发控制-MVCC;