小目标检测的注意特征金字塔网络

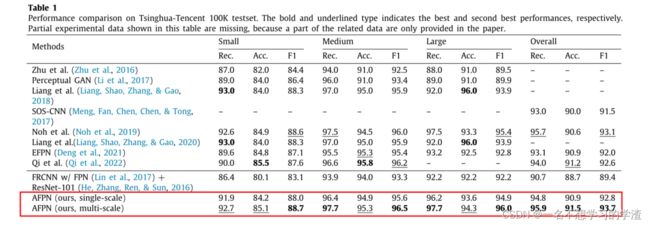
这是一篇小目标检测的文章,当然也是没有源代码的,自己只是为了学习它的创新点部分,看能不能给自己带来灵感。首先我们看看它的效果,如下图所示,感觉对小目标检测的效果还是非常不错的,证明作者提供的方法还是比较有效的。在本文中,我有一点比较佩服作者,那就是作者的用词实在是太棒了虽然方法不是特别难,但是作者硬生生地说的我有点看不懂。
学习小目标检测的小伙伴都知道哈,小目标本身就是存在像素面积小,特征不明显,容易与背景发生混乱等等原因,从而导致小目标检测的效果不是很好。作者说了三种原因:(1)负责小目标检测的浅特征包含分散注意特征(其实也就是噪声或者背景信息)(在这里可以使用FPN等操作比较好解决,因为有高级的语义信息)。(2)高密度分布下背景噪声过大,检测小目标的低水平特征判别能力较弱。(3)由于缺乏详细信息,小对象感兴趣区域(RoI)太小,难以识别(在这里一般是使用高分辨率的输入图像或者输入特征能够解决,但是计算量太大)。那么对于一般的目标检测的改进方法,比如FPN等方法,它们虽然一定程度上增加了大中目标的检测精度,但是对于小目标检测的精度提升并不是特别大。
针对这些问题,我们提出了一种新的特征金字塔结构——注意特征金字塔网络(Attention Feature Pyramid Network),它由动态纹理注意(Dynamic Texture Attention)、前景感知协同注意(前景感知Co-Attention)和细节上下文注意(Detail Context Attention)三个部分组成,以增强小目标的检测能力。首先,Dynamic Texture Attention通过过滤多余的语义来突出低层的小对象(这里面多余的语义信息是指噪声还是只背景信息,或者指的是大中目标信息,这就不得而知了),通过放大可信的细节来强调高层的大对象,动态地增强纹理特征。然后,通过前景相关背景增强目标特征,抑制背景噪声,探索了前景感知协同注意方法来检测排列密集的小目标。最后,为了更好地捕捉小对象的特征,Detail Context Attention自适应聚合不同尺度RoI特征的细节线索,以获得更精确的特征表示。
通过在Faster R-CNN中用AFPN代替FPN,我们的方法在清华-腾讯100K上的性能与最先进的性能相当。此外,我们在PASCAL VOC和MS COCO的小品类上都取得了极具竞争力的结果。
本文的主要贡献如下:
1、我们提出了注意特征金字塔网络(AFPN),一种新的特征金字塔网络,利用动态纹理注意、前景感知协同注意和细节上下文注意来检测像素较少且分布密集的小物体。
2、动态纹理注意(Dynamic Texture Attention)通过过滤多余的语义来强调下层的小对象,通过增强可信的细节来突出上层的大对象,从而生成纹理放大特征。
3、为了解决密集分布的小物体的噪声问题,我们开发了前景感知联合注意,增强与前景相关的特征,并抑制信息不足的区域。
4、对于包含有限和扭曲信息的小对象,我们引入细节上下文注意,自适应聚合不同尺度RoI特征的细节线索,以获得更精确的特征表示。
5、文章提出的方法显著增强了Faster R-CNN在三个基准数据集上的小目标检测能力,分别是:清华-腾讯100K (Zhu等人,2016)、PASCAL VOC (Everingham, Van Gool, Williams, Winn, & Zisserman, 2010)和MS COCO (Lin等人,2014)。当用AFPN代替Faster R-CNN中的FPN时,我们的方法达到了与清华腾讯上最先进的性能相当的性能(Zhu等人,2016)。此外,我们在PASCAL VOC (Everingham等人,2010)和MS COCO (Lin等人,2014)的一个小类别上获得了非常有竞争力的结果,用于一般物体检测。
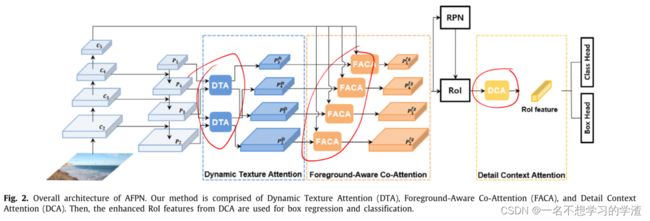
如上图所示就是本文提出的整体结构,首先输入图片通过主干网络以及FPN网络得到了特征图,在YOLO系列中,得到这样的特征图就可以直接进行目标检测了,但是在本文中作者认为,此处得到的特征并不好,因为小目标的信息并不多,而且还存在着噪音的影响,所以作者就做了后面的操作,即将相应的特征再通过DTA/FACA/DCA等操作才能真正的凸显出小目标的特征信息。
一、Dynamic Texture Attention
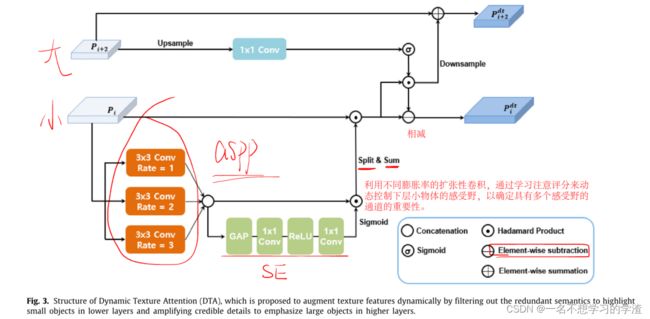
首先如上图所示就是文章提出的DAT模块。我们直接一眼看过去其实发现没有特别复杂,里面就是用了空洞卷积以及注意力机制,然后再有就是一些按元素相加、相减、相乘等操作。现在就开始看看作者是怎么说的:FPN利用固有的特征层次结构来实现不同分辨率的特征映射。为了聚合多尺度上下文,FPN通过自上而下路径中的横向连接将高级语义和低级细节结合起来。假设有两个特征层,分别为FPN的第一层和第三层。这两个特征层分别是用来预测小目标和大目标的。但是第一层的特征包含噪声,从而导致了无法很好地对小目标进行预测。第三层特征其实也包含一些小目标的信息,但是它是用来进行预测大目标的,所以在一定程度上检测器会混淆小对象和大对象的模糊语义。因此该论文提出了动态纹理注意(Dynamic Texture Attention, DTA),通过减少冗余语义来强调低层的小对象,通过增加可信细节来突出高层的大对象,动态放大纹理信息,从而提高对小对象的检测性能。那么这句话的潜在意思就是说删除浅层特征中的大目标信息,那么也要突出深层特征的大目标信息。
为了更好地表示较低的特征,我们提出利用不同膨胀率的扩张性卷积,通过动态利用各种膨胀率的膨胀卷积来更准确地表示小物体,通过学习注意评分来动态控制下层小物体的感受野,以确定具有多个感受野的通道的重要性。
二、Foreground-Aware Co-Attention
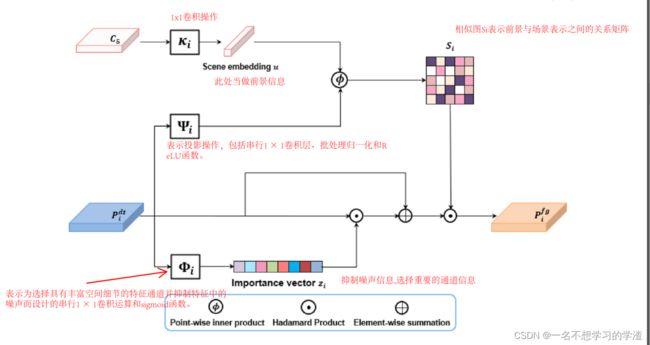 小物体通常只包含少量像素,从形状或外观相似的背景中提取出不同的前景特征是小物体检测的一大挑战。这个问题可能会导致对不感兴趣的背景错误地分类为前景类,因为类内部的差异较大。因此,弱化非客体区域,增强客体线索至关重要。为了更有效地捕捉复杂背景下小物体的线索,提出了前景感知协同注意(FACA),通过关联与场景相关的上下文来增强前景特征的识别。此外,我们通过自适应选择具有丰富空间细节的特征图,增加一个额外的分支来减少噪声,并在一定程度上改善目标信息(就是最下面的Important vector)。
小物体通常只包含少量像素,从形状或外观相似的背景中提取出不同的前景特征是小物体检测的一大挑战。这个问题可能会导致对不感兴趣的背景错误地分类为前景类,因为类内部的差异较大。因此,弱化非客体区域,增强客体线索至关重要。为了更有效地捕捉复杂背景下小物体的线索,提出了前景感知协同注意(FACA),通过关联与场景相关的上下文来增强前景特征的识别。此外,我们通过自适应选择具有丰富空间细节的特征图,增加一个额外的分支来减少噪声,并在一定程度上改善目标信息(就是最下面的Important vector)。
如上图所示:我们首先对特征通道的重要性进行建模(就是最下面的Important vector),并对其进行相应的校正以抑制噪声。然后,明确定义前景与场景之间的关系(就是最最上面的两部分),并采用潜在场景嵌入方法与前景特征进行关联(此处的相似度计算就是直接使用点乘的方式进行的)。利用该关系对特征进行增强,改善了前景与背景特征之间的差异,从而提高了对小目标的前景特征识别能力。至于后面的一些公式可以看可以不看,都是为了凑理论知识而已。
三、Detail Context Attention
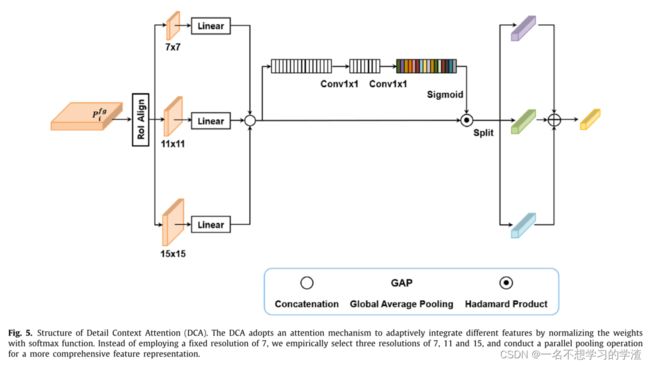
精炼的特性随后被传递到RPN,在那里生成区域建议。将特征和建议作为输入,进行RoI Align模块提取特征,用于最终类的预测和边界框的回归。通常,池化操作在初始实现中以固定分辨率7进行。小对象的识别需要更多的上下文信息,而固定的池分辨率在RoI池过程中很可能导致大量上下文信息的丢失。对于包含有限和扭曲信息的小型roi,这种类型的信息丢失可能是严重的问题,这容易导致次优检测性能。这是一种适应性注意机制可以将特定的注意力集中在局部特征和上下文细节上,可以帮助保持小对象的上下文信息。为此,我们提出了细节上下文注意(DCA)。
我们没有采用固定的7分辨率,而是经验地选择了7、11和15三个分辨率(这是经过实验分析出来的),并执行并行池操作,以获得更全面的特征表示。特别是对于小物体,大分辨率往往强调局部细节的上下文信息,从而以灵活简单的方式缓解信息丢失的问题。因为每个生成的特性包含不同级别的详细信息和语义信息,我们打算有效地集成从不同RoI池规模创建的特性。因此,采用注意机制对池化结果进行自适应聚合。如图5所示,我们首先用线性运算提取每个嵌入向量,然后与向量进行拼接运算。然后,为连接的向量添加一个注意分支。分支学习使用自适应参数创建增强的RoI特征,以改进不同分辨率RoI区域内特征的显著性度量。最后,我们通过对产生的权重进行软最大归一化运算来平衡每个RoI向量的贡献。最后的输出向量与三个RoI向量通过加权求和进行聚合。
总的来说,这篇文章写的还是不错的,自己也还在持续的看,兴许后面自己也会用到里面的相关思想呢。后面就是论文的实验部分了,实验做得还是非常详细的,在一些参数的选择上都给出的实验,因为没有代码,所以无法去跑代码,有兴趣的同学可以自己学一下。