【ML】聚类:Kmeans算法与DBSCAN算法
聚类是无监督学习问题,没有标签,难点在于模型评估及调参。
Kmeans聚类算法
假设我们想要将数据聚类成 K K K个组,K-means方法的工作流程为:
- 首先选择 K K K个随机的点,称为聚类中心(cluster centroids)或质心;
- 对于数据集中的每一个数据,按照距离 K K K个中心点的距离,将其与距离最近的中心点关联起来,与同一个中心点关联的所有点聚成一类;
- 计算每一个组的平均值,将该组质心移动到平均值的位置;
- 重复步骤,直至中心点不再变化。
Kmeans可视化
K-means最小化问题,是要最小化所有的数据点与其所关联的聚类中心点之间的距离之和,因此 K-均值的代价函数(又称畸变函数 Distortion function)为:
J ( c ( 1 ) , . . . , c ( N ) ; μ 1 , . . . , μ k ) = 1 N ∑ i = 1 N ∥ x ( i ) − u c ( i ) ∥ 2 J(c^{(1)},...,c^{(N)};\mu_1,...,\mu_k)=\frac{1}{N}\sum_{i=1}^{N}\Vert x^{(i)}-u^{c(i)}\Vert^2 J(c(1),...,c(N);μ1,...,μk)=N1i=1∑N∥x(i)−uc(i)∥2
其中, N N N为样本个数, μ c ( i ) \mu_{c^{(i)}} μc(i)表示与样本 x ( i ) x^{(i)} x(i)最近的聚类中心点。
K-means算法具有如下特点,
- 简单,快速,适合常规数据集,调参的参数仅为簇数 K K K,可解释性比较强。
- 对离群点敏感。
- 无法保证收敛到全局最优值,常使用不同的初始值进行多次试验,对初始值敏感。
- K值是人为给定的,如果让机器自己去找类别的个数,有AP聚类算法。K值难以事先选取,交叉验证不大适合,所以常采用“拐点法”(肘部法则)。
- K-Means的一个重要的假设是:数据之间的相似度可以使用欧氏距离度量,如果不能使用欧氏距离度量,要先把数据转换到能用欧氏距离度量,这一点很重要(注:可以使用欧氏距离度量的意思就是欧氏距离越小,两个数据相似度越高)。由于采用欧氏距离,无法直接计算类别型变量。一般需要对数据先作标准化处理。
- 复杂度与样本呈线性关系。
- 很难发现任意形状的簇。
- 相对于高斯混合模型而言收敛速度快,因而常用于高斯混合模型的初始值选择。
从EM算法角度看K-Means
K-means的目标是将样本集划分为K个簇,使得同一个簇内样本的距离尽可能小,不同簇之间的样本距离尽可能大,即最小化每个簇中样本与质心的距离。K-means属于原型聚类(prototype-based clustering),原型聚类指聚类结构能通过一组原型刻画,而原型即为样本空间中具有代表性的点。在K-means中,这个原型就是每个簇的质心 μ \mu μ。
从EM算法的观点来看,K-means的参数就是每个簇的质心 μ \mu μ,隐变量为每个样本的所属簇。如果事先已知每个样本属于哪个簇,则直接求平均即可得到 μ \mu μ。但现实中不知道的情况下,则需要运用EM的思想:
假设有 K K K个簇,先随机选定 K K K个点作为质心 μ 1 , μ 2 , . . . , μ k \mu_1,\mu_2,...,\mu_k μ1,μ2,...,μk:
- 固定 μ k \mu_k μk,将样本划分到距离最近的 μ k \mu_k μk所属的簇中。若用 r n k r_{nk} rnk表示第n个样本所属的簇,则
r n k = { 1 if k = argmin j ∥ x n − μ j ∥ 2 0 otherwise r_{n k}=\left\{\begin{array}{ll}{1} & {\text { if } k=\operatorname{argmin}_{j}\left\|\mathbf{x}_{n}-\boldsymbol{\mu}_{j}\right\|^{2}} \\ {0} & {\text { otherwise }}\end{array}\right. rnk={10 if k=argminj∥∥xn−μj∥∥2 otherwise - 固定 r n k r_{nk} rnk,根据上一步的划分结果重新计算每个簇的质心。由于我们的目标是最小化每个簇中样本与质心的距离,可将目标函数表示为 J = ∑ n = 1 N r n k ∥ x n − μ k ∥ 2 J=\sum_{n=1}^{N}r_{nk}\Vert x_n-\mu_k\Vert^2 J=∑n=1Nrnk∥xn−μk∥2,要最小化 J J J则对 μ k \mu_k μk求导得 2 ∑ n = 1 N r n k ( x n − μ k ) = 0 2\sum_{n=1}^{N}r_{nk}(x_n-\mu_k)=0 2∑n=1Nrnk(xn−μk)=0,则
μ k = ∑ n r n k x n ∑ n r n k \mu_k=\frac{\sum_{n}r_{nk}x_n}{\sum_{n}r_{nk}} μk=∑nrnk∑nrnkxn
即簇中每个样本的均值向量。
上面两步分别更新 r n k r_{nk} rnk和 μ k \mu_k μk就对应了EM算法中的E步和M步。和EM算法一样,K-means每一步都最小化目标函数 J J J,因而可以保证收敛到局部最优值,但在非凸目标函数的情况下不能保证收敛到全局最优值。
应用:
图像压缩:将像素点聚类。
DBSCAN算法
基本概念
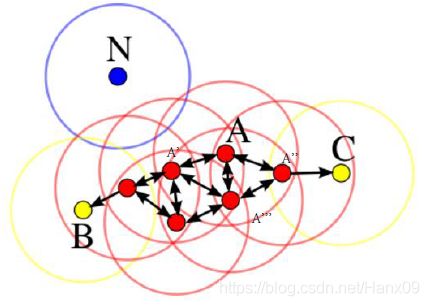
- ϵ \epsilon ϵ邻域的距离阈值: ϵ > 0 \epsilon>0 ϵ>0,对象O的 ϵ \epsilon ϵ邻域是指,以O为中心, ϵ \epsilon ϵ为半径的空间。
- 邻域密度阈值MinPts: 核心对象的 ϵ \epsilon ϵ邻域中包含的对象数量的最小值。
- 核心对象: 如果某个对象的 ϵ \epsilon ϵ邻域内的至少包含MinPts个对象,则该对象是核心对象。(A)
- 直接密度可达: 如果对象 p p p在核心对象 q q q的 ϵ \epsilon ϵ邻域内,则 p p p是从 q q q直接密度可达的。
- 密度可达: 若存在对象序列 q 0 , q 1 , . . . , q k q_0,q_1,...,q_k q0,q1,...,qk,对任意的 i i i, q i q_{i} qi是从 q i − 1 q_{i-1} qi−1直接密度可达的,则称从 q 0 q_0 q0到 q k q_k qk密度可达。这实际上是直接密度可达的“传播”。
- 密度相连: 若存在对象 q q q,使得 p 1 p_1 p1和 p 2 p_2 p2从 q q q都是密度可达的,则称 p 1 p_1 p1和 p 2 p_2 p2是密度相连的。
- 边界点: 属于某一个类的非核心点,不能发展下线了,即不存在从该点直接密度可达的点。(B、C)
- 噪声点: 不属于任何一个类簇的点,从任何一个核心点出发都是密度不可达的。(N)
工作流程
输入:数据集 D D D,半径 ϵ \epsilon ϵ,密度阈值 M i n P t s MinPts MinPts。

参数选择
k-距离:
给定数据集 P = p ( i ) ; i = 0 , 1 , … n P={p(i); i=0,1,…n} P=p(i);i=0,1,…n,对于任意点 P ( i ) P(i) P(i),计算点 P ( i ) P(i) P(i)到集合 P P P的子集 S = p ( 1 ) , p ( 2 ) , … , p ( i − 1 ) , p ( i + 1 ) , … , p ( n ) S={p(1), p(2), …, p(i-1), p(i+1), …, p(n)} S=p(1),p(2),…,p(i−1),p(i+1),…,p(n)中所有点之间的距离,距离按照从小到大的顺序排序,假设排序后的距离集合为 D = d ( 1 ) , d ( 2 ) , … , d ( k − 1 ) , d ( k ) , d ( k + 1 ) , … , d ( n ) D={d(1), d(2), …, d(k-1), d(k), d(k+1), …,d(n)} D=d(1),d(2),…,d(k−1),d(k),d(k+1),…,d(n),则 d ( k ) d(k) d(k)就被称为k-距离。也就是说,k-距离是点 p ( i ) p(i) p(i)到所有点(除了 p ( i ) p(i) p(i)点)之间距离第k近的距离。对待聚类集合中每个点 p ( i ) p(i) p(i)都计算k-距离,最后得到所有点的k-距离集合 E = e ( 1 ) , e ( 2 ) , … , e ( n ) E={e(1), e(2), …, e(n)} E=e(1),e(2),…,e(n)。
根据经验计算半径Eps:
根据得到的所有点的k-距离集合 E E E,对集合 E E E进行升序排序后得到k-距离集合 E ’ E’ E’,需要拟合一条排序后的 E ’ E’ E’集合中k-距离的变化曲线图,然后绘出曲线,通过观察,将急剧发生变化的位置所对应的k-距离的值,确定为半径Eps的值。
根据经验计算最少点的数量MinPts:
确定MinPts的大小,实际上也是确定k-距离中k的值,一般取得小一些,多次尝试。
优势与劣势
优势:
- 不需要指定簇个数
- 擅长找到离群点(检测任务)
- 可以发现任意形状的簇
- 指定两个参数就够了
劣势:
- 高维数据有些困难(可以做降维)
- Sklearn中效率很慢(数据削减策略)
- 参数难以选择(参数对结果的影响非常大)
DBSCAN可视化
评估聚类模型
轮廓系数
s ( i ) = b ( i ) − a ( i ) max { a ( i ) , b ( i ) } s(i)=\frac{b(i)-a(i)}{\max \{a(i),b(i)\}} s(i)=max{a(i),b(i)}b(i)−a(i)
s ( i ) = { 1 − a ( i ) b ( i ) , a ( i ) < b ( i ) 0 , a ( i ) = b ( i ) a ( i ) b ( i ) − 1 , a ( i ) > b ( i ) s(i)=\begin{cases} 1-\frac{a(i)}{b(i)},\quad a(i)
- 计算样本 i i i到同簇其他样本的平均距离 a ( i ) a(i) a(i)。 a ( i ) a(i) a(i)越小,说明样本i越应该被聚类到该簇。将 a ( i ) a(i) a(i)称为样本i的簇内不相似度。
- 计算样本 i i i到其他某簇Cj 的所有样本的平均距离 b i j bij bij,称为样本 i i i与簇Cj 的不相似度。定义为样本i的簇间不相似度: b ( i ) = m i n b i 1 , b i 2 , . . . , b i k b(i) =min{bi1, bi2, ..., bik} b(i)=minbi1,bi2,...,bik
- s ( i ) s(i) s(i)接近1,则说明样本 i i i聚类合理
- s ( i ) s(i) s(i)接近-1,则说明样本 i i i更应该分类到另外的簇
- 若 s ( i ) s(i) s(i)近似为0,则说明样本 i i i在两个簇的边界上。
>>> from sklearn import metrics
>>> scores = []
>>> for k in range(2,20):
>>> labels = KMeans(n_clusters=k).fit(X).labels_
>>> score = metrics.silhouette_score(X, labels)
>>> scores.append(score)
>>> scores#不同k的轮廓系数
[0.6917656034079486,
0.6731775046455796,
0.5267665961530135,
0.422548733517202,
0.4559182167013377,
0.43776116697963124,
0.38946337473125997,
0.39746405172426014,
0.3915697409245163,
0.32472080133848924,
0.3459775237127248,
0.31221439248428434,
0.30707782144770296,
0.31834561839139497,
0.2849514001174898,
0.23498077333071996,
0.1588091017496281,
0.08423051380151177]
————————————————
参考:
DBSCAN聚类原理