2022第二届中国高校大数据竞赛A题思路分享三
A题题目
制造业是国民经济的主体,近十年来,嫦娥探月、祝融探火、北斗组网,一大批重大标志性创新成果引领中国制造业不断攀上新高度。作为制造业的核心,机械设备在工业生产的各个环节都扮演着不可或缺的重要角色。但是,在机械设备运转过程中会产生不可避免的磨损、老化等问题,随着损耗的增加,会导致各种故障的发生,影响生产质量和效率。
实际生产中,若能根据机械设备的使用情况,提前预测潜在的故障风险,精准地进行检修维护,维持机械设备稳定运转,不但能够确保整体工业环境运行具备稳定性,也能切实帮助企业提高经济效益。
某企业机械设备的使用情况及故障发生情况数据见“train data.xlsx”,用于设备故障预测及故障主要相关因素的探究。数据包含 9000 行,每一行数据记录了机械设备对应的运转及故障发生情况记录。因机械设备在使用环境以及工作强度上存在较大差异,其所需的维护频率和检修问题也通常有所不同。
数据提供了实际生产中常见的机械设备使用环境和工作强度等指标,包含不同设备所处厂房的室温(单位为开尔文K),其工作时的机器温度(单位为开尔文K)、转速(单位为每分钟的旋转次数rpm)、扭矩(单位为牛米Nm)及机器运转时长(单位为分钟min)。除此之外,还提供了机械设备的统一规范代码、质量等级及在该企业中的机器编号,其中质量等级分为高、中、低(H\M\L)三个等级。对于机械设备的故障情况,数据提供了两列数据描述——“是否发生故障” 和“具体故障类别”。其中“是否发生故障”取值为 0/1,0 代表设备正常运转,1 代 表设备发生故障;“具体故障类别”包含 6 种情况,分别是NORMAL、TWF、HDF、PWF、OSF、RNF,其中,NORMAL代表设别正常运转(与是否发生故障”为 0相对应),其余代码代表的是发生故障的类别,包含 5 种,其中TWF代表磨损故障,HDF代表散热故障,PWF代表电力故障,OSF代表过载故障,RNF代表其他故障。
基于赛题提供的数据,自主查阅资料,选择合适的方法完成如下任务:
任务 1:观察数据“train data.xlsx”,自主进行数据预处理,选择合适的指标用于机械设备故障的预测并说明原因。
任务 2:设计开发模型用于判别机械设备是否发生故障,自主选取评价方式和评价指标评估模型表现。
任 务 3 : 设 计 开 发 模 型 用 于 判 别 机 械 设 备 发 生 故 障 的 具 体 类 别(TWF/HDF/PWF/OSF/RNF),自主选取评价方式和评价指标评估模型表现
任务 4:利用任务 2 和任务 3 开发的模型预测“forecast.xlsx”中是否发生故障以及故障类别。数据“forecast.xlsx”。与数据“train data.xlsx”格式类似,要求在“forecast.xlsx”第 8 列说明设备是否发生故障(0 或 1),在第 9 列标识出具体的故障类型(TWF/HDF/PWF/OSF/RNF)
任务 5:探究每类故障(TWF/HDF/PWF/OSF/RNF)的主要成因,找出与其相关的特征属性,进行量化分析,挖掘可能存在的模式/规则。
第三问
第三问就是一个多分类问题,可以先将正常样本Normal的样本删除,保留TWF、HDF、PWF、OSF、RNF,并对它们打标签,分别为TWF对应‘1’,HDF对应‘2’,PWF对应‘3’,OSF对应‘4’,RNF对应‘5’,总共为5类故障。废话不多说,直接上代码。也可以考虑无监督学习方法,例如聚类方法,这一思路可做参考。
PNN部分代码
clc
clear
%%导入数据
data = xlsread('C:\大数据杯A题\第三问\第三题数据.xlsx');
rng(1)
input = data(:,1:end-1);
output = data(:,end);
%第一类42组
[i1 i2]=sort(rand(42,1));
train(1:30,:)=input(i2(1:30),:); train_label(1:30,1)=output(i2(1:30),1);
test(1:12,:)=input(i2(31:42),:); test_label(1:12,1)=output(i2(31:42),1);
%第二类有95组
[i1 i2]=sort(rand(95,1));
train(31:100,:)=input(40+i2(1:70),:); train_label(31:100,1)=output(40+i2(1:70),1);
test(13:37,:)=input(40+i2(71:95),:); test_label(13:37,1)=output(40+i2(71:95),1);
%第三类有73组
[i1 i2]=sort(rand(73,1));
train(101:150,:)=input(137+i2(1:50),:); train_label(101:150,1)=output(137+i2(1:50),1);
test(38:60,:)=input(137+i2(51:73),:); test_label(38:60,1)=output(137+i2(51:73),1);
%第4类有85组
[i1 i2]=sort(rand(85,1));
train(151:210,:)=input(210+i2(1:60),:); train_label(151:210,1)=output(210+i2(1:60),1);
test(61:85,:)=input(210+i2(61:85),:); test_label(61:85,1)=output(210+i2(61:85),1);
%第5类有6组
[i1 i2]=sort(rand(6,1));
train(211:214,:)=input(295+i2(1:4),:); train_label(211:214,1)=output(295+i2(1:4),1);
test(86:87,:)=input(295+i2(5:6),:); test_label(86:87,1)=output(295+i2(5:6),1);
clear i1 i2 input output
p_train = mapminmax(train',0,1);
T_train = train_label';
p_test = mapminmax(test',0,1);
T_test = test_label';
%% ELM创建/训练
%% 性能评价
% 正确率accuracy
accuracy_pnn = [];
accuracy_2 = length(find(T_sim_pnn == T_test))/length(T_test);
% 绘图
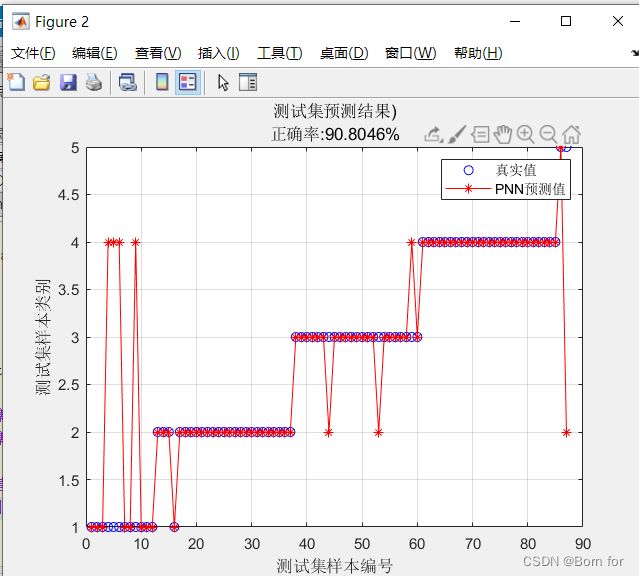
figure(2)
plot(1:87,T_test,'bo',1:87,T_sim_pnn,'r-*')
grid on
xlabel('测试集样本编号')
ylabel('测试集样本类别')
title(string)
legend('真实值','PNN预测值')结果展示

ANN代码部分代码
clc
clear
%%导入数据
data = xlsread('C:\Desktop\大数据杯A题\第三问\第三题数据.xlsx');
rng(1)
input = data(:,1:end-1);
output = data(:,end);
%第一类42组
[i1 i2]=sort(rand(42,1));
train11(1:30,:)=input(i2(1:30),:); train_label(1:30,1)=output(i2(1:30),1);
test(1:12,:)=input(i2(31:42),:); test_label(1:12,1)=output(i2(31:42),1);
%第二类有95组
[i1 i2]=sort(rand(95,1));
train11(31:100,:)=input(40+i2(1:70),:); train_label(31:100,1)=output(40+i2(1:70),1);
test(13:37,:)=input(40+i2(71:95),:); test_label(13:37,1)=output(40+i2(71:95),1);
%第三类有73组
[i1 i2]=sort(rand(73,1));
train11(101:150,:)=input(137+i2(1:50),:); train_label(101:150,1)=output(137+i2(1:50),1);
test(38:60,:)=input(137+i2(51:73),:); test_label(38:60,1)=output(137+i2(51:73),1);
%第4类有85组
[i1 i2]=sort(rand(85,1));
train11(151:210,:)=input(210+i2(1:60),:); train_label(151:210,1)=output(210+i2(1:60),1);
test(61:85,:)=input(210+i2(61:85),:); test_label(61:85,1)=output(210+i2(61:85),1);
%第5类有6组
[i1 i2]=sort(rand(6,1));
train11(211:214,:)=input(295+i2(1:4),:); train_label(211:214,1)=output(295+i2(1:4),1);
test(86:87,:)=input(295+i2(5:6),:); test_label(86:87,1)=output(295+i2(5:6),1);
clear i1 i2 input output
p_train = mapminmax(train11',0,1);
T_train = train_label';
p_test = mapminmax(test',0,1);
T_test = test_label';
%% 绘图
figure(1)
plot(1:87,T_test,'ro',1:87,T_sim_bp1','b*')
xlabel('测试集样本编号')
ylabel('测试集样本类别')
string = {'测试集预测结果对比BP)';['正确率:' num2str(accuracy_2*100) '%(BP)']};
title(string)
结果展示
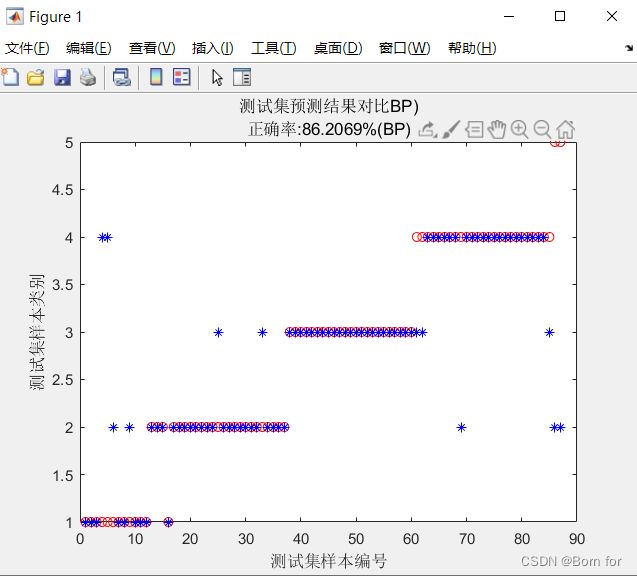
明显可以看出使用PNN的精度比选用ANN的精度高出了3.87%
代码见正在为您运送作品详情