K折交叉验证大集合(KFold 、Stratified k-fold、Group k-fold、StratifiedGroupKFold)
最近在看kaggle比赛,其中用的最多的trick都有多折交叉验证,首先,交叉验证是区分训练集合验证集的一种方法,不同的交叉验证方法就是根据不同的规则来指定训练集合验证集,今天就来深扒一下每个多折交叉验证方法的详细内容和他们之间的区别吧!
1.KFold
KFold是最基本的K折交叉验证,表示将数据集拆分为k个连续group(默认情况下不进行打乱顺序)。然后,每个group被用作一次验证,而剩余的k-1个group形成训练集。KFold不会受到class和group的影响。
>>> import numpy as np
>>> from sklearn.model_selection import KFold
>>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
>>> y = np.array([1, 2, 3, 4])
>>> kf = KFold(n_splits=2)
>>> kf.get_n_splits(X)
2
>>> print(kf)
KFold(n_splits=2, random_state=None, shuffle=False)
>>> for train_index, test_index in kf.split(X):
... print("TRAIN:", train_index, "TEST:", test_index)
... X_train, X_test = X[train_index], X[test_index]
... y_train, y_test = y[train_index], y[test_index]
TRAIN: [2 3] TEST: [0 1]
TRAIN: [0 1] TEST: [2 3]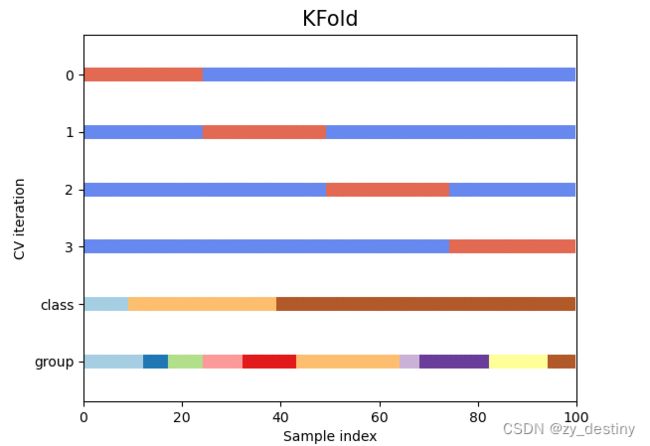
2.Stratified k-fold
Stratified k-fold是KFold的变体,它会根据数据集的类别占比分布来划分训练集和验证集,使得划分后的数据集的类别占比和原始数据集近似。
>>> import numpy as np
>>> from sklearn.model_selection import StratifiedKFold
>>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
>>> y = np.array([0, 0, 1, 1])
>>> skf = StratifiedKFold(n_splits=2)
>>> skf.get_n_splits(X, y)
2
>>> print(skf)
StratifiedKFold(n_splits=2, random_state=None, shuffle=False)
>>> for train_index, test_index in skf.split(X, y):
... print("TRAIN:", train_index, "TEST:", test_index)
... X_train, X_test = X[train_index], X[test_index]
... y_train, y_test = y[train_index], y[test_index]
TRAIN: [1 3] TEST: [0 2]
TRAIN: [0 2] TEST: [1 3]
3.Group k-fold
GroupKFold 会保证同一个group的数据不会同时出现在训练集和验证集上。因为如果训练集中包含了每个group的几个样例,可能训练得到的模型能够足够灵活地从这些样例中学习到特征,在验证集上也会表现很好。但一旦遇到一个新的group它就会表现很差。
>>> from sklearn.model_selection import GroupKFold
>>> X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 8.8, 9, 10]
>>> y = ["a", "b", "b", "b", "c", "c", "c", "d", "d", "d"]
>>> groups = [1, 1, 1, 2, 2, 2, 3, 3, 3, 3]
>>> gkf = GroupKFold(n_splits=3)
>>> for train, test in gkf.split(X, y, groups=groups):
... print("%s %s" % (train, test))
[0 1 2 3 4 5] [6 7 8 9]
[0 1 2 6 7 8 9] [3 4 5]
[3 4 5 6 7 8 9] [0 1 2]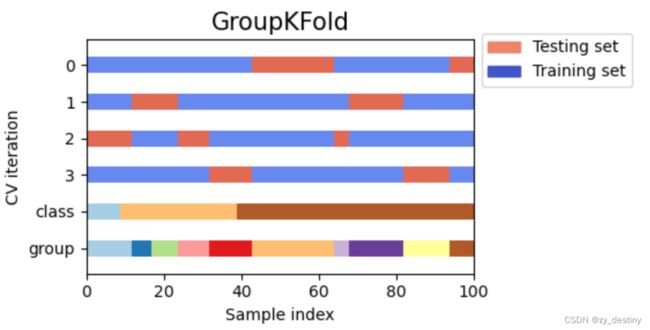
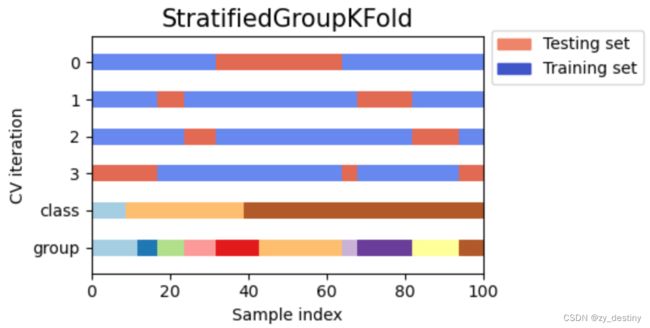
4.StratifiedGroupKFold
StratifiedGroupKFold要求数据集划分时既要考虑类别占比大致不变,又要保证同一个group的数据不能同时出现在训练集和验证集上。
>>> from sklearn.model_selection import StratifiedGroupKFold
>>> X = list(range(18))
>>> y = [1] * 6 + [0] * 12
>>> groups = [1, 2, 3, 3, 4, 4, 1, 1, 2, 2, 3, 4, 5, 5, 5, 6, 6, 6]
>>> sgkf = StratifiedGroupKFold(n_splits=3)
>>> for train, test in sgkf.split(X, y, groups=groups):
... print("%s %s" % (train, test))
[ 0 2 3 4 5 6 7 10 11 15 16 17] [ 1 8 9 12 13 14]
[ 0 1 4 5 6 7 8 9 11 12 13 14] [ 2 3 10 15 16 17]
[ 1 2 3 8 9 10 12 13 14 15 16 17] [ 0 4 5 6 7 11]