缓存数据库Redis之三:内存淘汰策略及优化
目录
一、Redis的内存淘汰策略
1.1. 概念
1.2.策略一:全局的键空间选择性移除
1.3.策略二:设置过期时间的键空间选择性移除
1.4.LRU、LFU和volatile-ttl都是近似随机算法
1.4.1.LRU算法
1.4.2.LFU算法
1.5.过期删除策略
1.6.AOF和RDB的过期删除策略
二、REDIS的消耗及优化
2.1.消耗状态
2.2.优化
2.2.1.Redis的内存优化
2.2.2.避免使用KEYS
2.2.3.设置 key 有效期
2.2.4.选择回收策略
2.2.5.限制redis的内存大小
2.2.6.部署和场景应用优化
一、Redis的内存淘汰策略
1.1. 概念
Redis的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。
1.2.策略一:全局的键空间选择性移除
- - noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。
- - allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。(这个是**最常用**的)
- - allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。
1.3.策略二:设置过期时间的键空间选择性移除
- - volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
- - volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
- - volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
注:Redis的内存淘汰策略的选取并不会影响过期的key的处理。内存淘汰策略用于处理内存不足时的需要申请额外空间的数据;过期策略用于处理过期的缓存数据。
1.4.LRU、LFU和volatile-ttl都是近似随机算法
使用下面的参数maxmemory-policy配置淘汰策略:
#配置文件
maxmemory-policy noeviction
#命令行
127.0.0.1:6379> config get maxmemory-policy
1) "maxmemory-policy"
2) "noeviction"
127.0.0.1:6379> config set maxmemory-policy allkeys-random
OK
127.0.0.1:6379> config get maxmemory-policy
1) "maxmemory-policy"
2) "allkeys-random"
- 在缓存的内存淘汰策略中有FIFO、LRU、LFU三种,其中LRU和LFU是Redis在使用的。
- FIFO是最简单的淘汰策略,遵循着先进先出的原则,这里简单提一下:

1.4.1.LRU算法
LRU(Least Recently Used)表示最近最少使用,该算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
- LRU算法的常见实现方式为链表:
新数据放在链表头部 ,链表中的数据被访问就移动到链头,链表满的时候从链表尾部移出数据。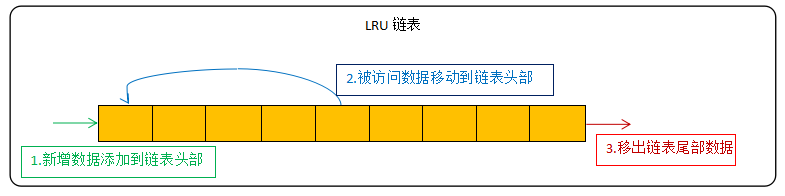
而在Redis中使用的是近似LRU算法,为什么说是近似呢?Redis中是随机采样5个(可以修改参数maxmemory-samples配置)key,然后从中选择访问时间最早的key进行淘汰,因此当采样key的数量与Redis库中key的数量越接近,淘汰的规则就越接近LRU算法。但官方推荐5个就足够了,最多不超过10个,越大就越消耗CPU的资源。
但在LRU算法下,如果一个热点数据最近很少访问,而非热点数据近期访问了,就会误把热点数据淘汰而留下了非热点数据,因此在Redis4.x中新增了LFU算法。
注:在LRU算法下,Redis会为每个key新增一个3字节的内存空间用于存储key的访问时间;
1.4.2.LFU算法
LFU(Least Frequently Used)表示最不经常使用,它是根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
解决LRU算法的漏洞:LFU算法反映了一个key的热度情况,不会因LRU算法的偶尔一次被访问被误认为是热点数据。
- LFU算法的常见实现方式为链表:
新数据放在链表尾部 ,链表中的数据按照被访问次数降序排列,访问次数相同的按最近访问时间降序排列,链表满的时候从链表尾部移出数据。

1.5.过期删除策略
前面介绍的LRU和LFU算法都是在Redis内存占用满的情况下的淘汰策略,那么当内存没占满时在Redis中过期的key是如何从内存中删除以达到优化内存占用的呢?
在Redis中过期的key不会立刻从内存中删除,而是会同时以下面两种策略进行删除:
- 惰性删除:当key被访问时检查该key的过期时间,若已过期则删除;已过期未被访问的数据仍保持在内存中,消耗内存资源;
- 定期删除:每隔一段时间,随机检查设置了过期的key并删除已过期的key;维护定时器消耗CPU资源;
扫描周期:Redis每10秒进行一次过期扫描:
- 随机取20个设置了过期策略的key;
- 检查20个key中过期时间中已过期的key并删除;
- 如果有超过25%的key已过期则重复第一步;
- 这种循环随机操作会持续到过期key可能仅占全部key的25%以下时,并且为了保证不会出现循环过多的情况,默认扫描时间不会超过25ms;
1.6.AOF和RDB的过期删除策略
前面介绍了Redis的持久化策略RDB和AOF,当Redis中的key已过期未删除时,如果进行RDB和AOF的持久化操作时候会怎么操作呢?
- 在RDB持久化模式中我们可以使用save和bgsave命令进行数据持久化操作
- 在AOF持久化模式中使用rewriteaof和bgrewriteaof命令进行持久化操作
注: 这四个命令都不会将过期key持久化到RDB文件或AOF文件中,可以保证重启服务时不会将过期key载入Redis。
为了保证一致性,在AOF持久化模式中,当key过期时候,会同时发送DEL命令给AOF文件和所有节点;从节点不会主动的删除过期key除非它升级为主节点或收到主节点发来的DEL命令;
二、REDIS的消耗及优化
2.1.消耗状态
Redis主要消耗什么物理资源?那自然是内存,大家都知道,内存资源一旦使用完,那么Redis会怎么样呢?
如果达到设置的上限,Redis的写命令会返回错误信息(但是读命令还可以正常返回)或者你可以配置内存淘汰机制,当Redis达到内存上限时会冲刷掉旧的内容。
2.2.优化
2.2.1.Redis的内存优化
利用Hash,list,sorted set,set等集合类型数据,因为通常情况下很多小的Key-Value可以用更紧凑的方式存放到一起。尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该尽可能的将你的数据模型抽象到一个散列表里面。比如你的web系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的key,而是应该把这个用户的所有信息存储到一张散列表里面。
- redis内存碎片查询
[root@localhost ~]# redis-cli
127.0.0.1:6379> info memory #查看内存使用总量和内存碎片率
# Memory
used_memory:11315280 #内存使用总量
used_memory_human:10.79M
mem_fragmentation_ratio:1.76 #内存碎片率
mem_fragmentation_bytes:8566768- 内存碎片率稍大于1是合理的,这个值表示内存碎片率比较低
- 内存碎片率超过1.5,说明redis消耗了实际需要物理内存的150%,其中50%是内存碎片率
- 内存碎片率低于1的,说明Redis内存分配超出了物理内存,操作系统正在进行内存交换(内存碎片率稍大于1是最佳,低于1访问速度会慢,高于1.5说明碎片太多)
注:那么内存使用率超过可用最大内存,redis响应速度会变慢,这个时候操作系统将开始进行内存与swap空间交换,就需要设置内存淘汰策略
2.2.2.避免使用KEYS
- keys *, 这个命令是阻塞的,即操作执行期间,其它任何命令在你的实例中都无法执行。可以去使用[SCAN]来代替。
- keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用scan指令,scan指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长 。
2.2.3.设置 key 有效期
应该尽可能的利用key有效期。比如一些临时数据(短信校验码),过了有效期Redis就会自动为你清除!
2.2.4.选择回收策略
当 Redis 的实例空间被填满了之后,将会尝试回收一部分key。根据你的使用方式,强烈建议使用 volatile-lru(默认)策略——前提是你对key已经设置了超时。
2.2.5.限制redis的内存大小
数据量不可预估,并且内存也有限的话,尽量限制下redis使用的内存大小,这样可以避免redis使用swap分区或者出现OOM错误。(使用swap分区,性能较低,如果限制了内存,当到达指定内存之后就不能添加数据了,否则会报OOM错误。可以设置maxmemory-policy,内存不足时删除数据。)
2.2.6.部署和场景应用优化
- 尽可能地使用slot哈希存储,哈希槽(以集群方式部署)。
- 当业务场景不需要数据持久化时,关闭所有的持久化方式可以获得最佳的性能。