PyTorch学习记录——PyTorch生态
Pytorch的强大并不仅局限于自身的易用性,更在于开源社区围绕PyTorch所产生的一系列工具包(一般是Python package)和程序,这些优秀的工具包极大地方便了PyTorch在特定领域的使用,比如:
-
计算机视觉,有TorchVision、TorchVideo等用于图片和视频处理;
-
自然语言处理,有torchtext;
-
图卷积网络,有PyTorch Geometric;
-
…
下面仅对图像、视频、文本领域的工具包和程序进行介绍。
1.torchvision
" The torchvision package consists of popular datasets, model architectures, and common image transformations for computer vision. "
torchvision中包含有当前流行的数据集、模型结构和常用的图像变换等功能模块。因此,torchvision模块主要用于调用预训练模型、加载数据集和对图片进行数据增强操作等。torchvision主要包括有如下工具包:
-
torchvision.dataset
-
torchvision.models
-
torchvision.transformations
-
torchvision.io
-
torchvision.ops
-
torchvision.utils
这之中,前三项即为我们进行数据加载、预训练模型加载以及图像增强处理等操作时常用的工具包。
1.1 torchvision.dataset
torchvision.dataset中包含了常用的数据集(在第一次使用时需要下载):Caltech、CelebA、CIFAR、Cityscapes、EMNIST、
| 数据集 | 说明 | 数据集 | 说明 |
|---|---|---|---|
| Caltech | 加州理工学院的行人数据集。 | KMNIST | 古日文手写识别数据集。 |
| CelebA | CeleA是香港中文大学的开放数据(人脸数据集),包含10177个名人身份的202599张图片,并且都做好了特征标记。 | PhotoTour | 旅游景点图片数据集。 |
| CIFAR | 经典的10分类(CIFAR-10)/100分类(CIFAR-100)图像数据集。 | Places365 | 场景识别数据集。 |
| Cityscapes | 自动驾驶数据集,包括了国外多个城市街道场景图片。 | QMNIST | MNIST的重构数据集。 |
| EMNIST | Extended MNIST (EMNIST),是MNIST数据集的扩展,包含手写数字、字母等。 | SBD | VOC数据集的扩展。 |
| FakeData | SEMEION | 手写数字识别数据集。 | |
| Fashion-MNIST | 类似于MNIST数据集,是服装的分类(T恤、衣服、裤子、鞋子等)。 | STL10 | 用于开发无监督特征学习、深度学习和自学学习算法的图像识别数据集,类似于CIFAR-10,但每个类标记训练示例较少。 |
| Flickr | 图文匹配数据集。 | SVHN | 街景门牌号码图片数据集。 |
| ImageNet | 经典的图像识别数据集。 | UCF101 | 截至2012年最大的动作识别类数据集(视频数据),包含101个类别和13320个视频。 |
| Kinetics-400 | 人体动作识别数据集,包括至少400种人体动作类别,每个类别有至少400段视频。 | VOC | Visual Object Class,目标检测、图像分割等视觉任务数据集。 |
| KITTI | 自动驾驶场景下的计算机视觉算法评测数据集。 | WIDERFace | 人脸检测的一个benchmark数据集。 |
1.2 torchvision.transforms
在图像类任务的处理中,图像数据的格式或者大小通常存在不统一的情况,需要进行归一化,大小缩放等预处理操作。同时,当图片数据有限时,我们还需要通过对现有图片数据进行各种变换,如缩小或放大、水平或垂直翻转等,以对现有数据集进行扩充和增强。下面我们通过例子来学习如何实现上述过程。原始图像及其信息通过下述代码给出
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
# 加载原始图片
img = Image.open("./naruto.jpeg")
print(img.size)
plt.imshow(img)
plt.show()
图像尺寸为
(500, 263)
图像为
1.2.1 对给定图片进行切割
(1)沿中心线切割
采用transform.CenterCrop方法,对图片进行如下处理:
-
对图片沿中心放大切割,超出图片大小的部分填0
-
对图片沿中心缩小切割,超出期望大小的部分剔除
# 对图片沿中心放大切割,超出图片大小的部分填0
img_centercrop1 = transforms.CenterCrop((500, 500))(img)
print(img_centercrop1.size)
# 对图片沿中心缩小切割,超出期望大小的部分剔除
img_centercrop2 = transforms.CenterCrop((224, 224))(img)
print(img_centercrop2.size)
得到输出为
(500, 500)
(224, 224)
得到图像处理结果为
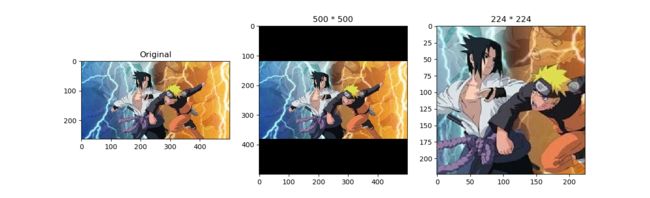
(2)随机切割
随机切割主要使用函数transforms.RandomCrop实现,通过指定大小,对图片进行随机切割,且切割后对超出期望大小的部分予以剔除。
import torch
torch.manual_seed(31)
# 随机裁剪
img_randowm_crop1 = transforms.RandomCrop(224)(img)
img_randowm_crop2 = transforms.RandomCrop(224)(it.show()
得到结果为

(3)随机裁剪成指定大小
随机切割主要使用函数transforms.RandomResizedCrop实现,通过指定大小,将图片进行随机选择位置裁剪,并随机进行缩放。
# 随机裁剪成指定大小
img_random_resizecrop_1 = transforms.RandomResizedCrop(224, scale=(0.5, 0.5))(img)
img_random_resizecrop_2 = transforms.RandomResizedCrop(224, scale=(0.5, 1.0))(img)
如上代码得到如下图所示结果(左图为img_random_resizecrop_1的结果,右图为img_random_resizecrop_2的结果)

从图中背景里鸣人的形象大小比例可以看出两张图像虽然都进行了裁剪,但是进行的缩放有所不同。
1.2.2 对给定图像进行颜色变换
图像的颜色变换可以通过transforms.ColorJitter函数实现,对图像的亮度、对比度、饱和度、色调等进行调整和改变,如下
# 对图片的亮度,对比度,饱和度,色调进行改变
img_CJ = transforms.ColorJitter(brightness=1,contrast=0.5,saturation=0.5,hue=0.5)(img)
得到
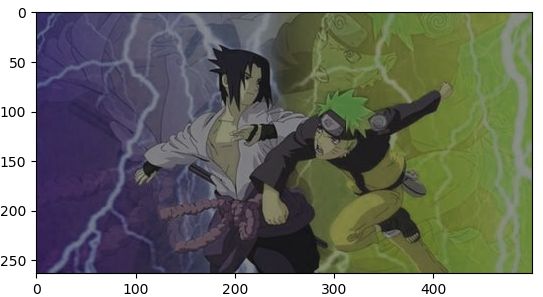
除使用上述调色方法外,还可以使用transforms.Grayscale函数,通过对输出通道数的控制调整图片色彩,如
img_grey_c3 = transforms.Grayscale(num_output_channels=3)(img)
img_grey_c1 = transforms.Grayscale(num_output_channels=1)(img)
可得到
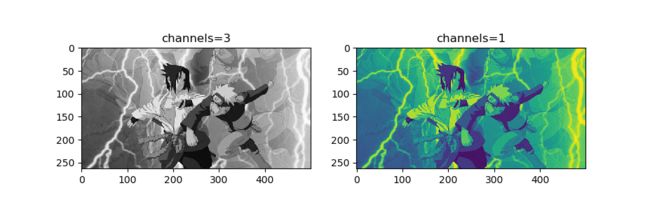
1.2.3 对给定图像进行随机翻转
对给定图像进行翻转主要包括随机水平翻转和随机竖直翻转两种方式,分别采用transforms.RandomHorizontalFlip和transforms.RandomVerticalFlip两个方法实现,如下
img_random_H = transforms.RandomHorizontalFlip()(img)
img_random_V = transforms.RandomVerticalFlip()(img)
得到

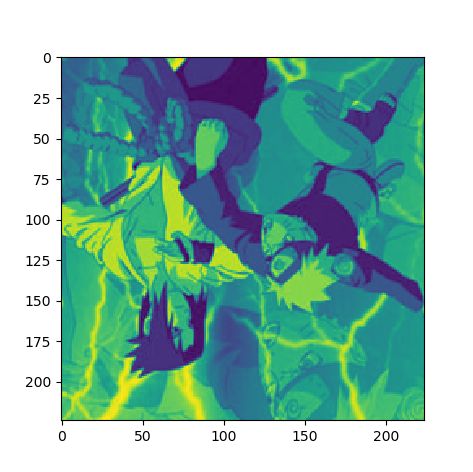
1.2.4 对给定图像进行组合变换
基于上述操作函数,我们可以使用transform.Compose函数将上述处理进行组合,从而形成图像处理流,如下
torch.manual_seed(30)
transformer = transforms.Compose([
transforms.Grayscale(num_output_channels=1),
transforms.transforms.RandomResizedCrop((224), scale = (0.5,1.0)),
transforms.RandomVerticalFlip(),
transforms.RandomHorizontalFlip()
])
img_transform = transformer(img)
则可得到如下变换后的图像
1.3 torchvision.models
为了提高训练效率,减少不必要的重复劳动,PyTorch官方也提供了一些预训练好的模型供我们使用,可以点击这里进行查看现在有哪些预训练模型。现有的预训练模型主要包括:
-
分类模型(Classification)
AlexNet VGG ResNet SqueezeNet DenseNet Inception v3 GoogLeNet ShuffleNet v2 MobileNetV2 MobileNetV3 ResNext Wide ResNet MNASNet EfficientNet RegNet -
语义分割模型(Semantic Segmentation ): 语义分割的预训练模型是在COCO train2017的子集上训练。
FCN ResNet50 FCN ResNet101 DeepLabV3 ResNet50 DeepLabV3 ResNet101 LR-ASPP MobileNetV3-Large DeepLabV3 MobileNetV3-Large -
物体检测(Object Detection),实例分割(Instance Segmentation)和人体关键点检测(Keypoint Detection)
Faster R-CNN Mask R-CNN RetinaNet SSDlite SSD -
视频分类(Video classification):视频分类模型是在 Kinetics-400上进行预训练
ResNet 3D 18 ResNet MC 18 ResNet (2+1) D
2.PyTorchVideo库
PyTorchVideo 是一个专注于视频理解工作的深度学习库。PytorchVideo 提供了加速视频理解研究所需的可重用、模块化和高效的组件。PyTorchVideo 是使用Pytorch开发的,支持不同的深度学习视频组件,如视频模型、视频数据集和视频特定转换。
PytorchVideo 提供了加速视频理解研究所需的模块化和高效的API。它还支持不同的深度学习视频组件,如视频模型、视频数据集和视频特定转换,最重要的是,PytorchVideo也提供了model zoo,使得人们可以使用各种先进的预训练视频模型及其评判基准。PyTorchVideo主要亮点如下:
-
基于 PyTorch: 使用 PyTorch 构建。使所有 PyTorch 生态系统组件的使用变得容易。
-
Model Zoo: PyTorchVideo提供了包含I3D、R(2+1)D、SlowFast、X3D、MViT等SOTA模型的高质量model zoo(目前还在快速扩充中,未来会有更多SOTA model),并且PyTorchVideo的model zoo调用与PyTorch Hub做了整合,大大简化模型调用。
-
数据预处理和常见数据: PyTorchVideo支持Kinetics-400, Something-Something V2, Charades, Ava (v2.2), Epic Kitchen, HMDB51, UCF101, Domsev等主流数据集和相应的数据预处理,同时还支持randaug, augmix等数据增强trick。
-
模块化设计: PyTorchVideo的设计类似于torchvision,也是提供许多模块方便用户调用修改,在PyTorchVideo中具体来说包括data, transforms, layer, model, accelerator等模块,方便用户进行调用和读取。
-
支持多模态: PyTorchVideo现在对多模态的支持包括了visual和audio,未来会支持更多模态,为多模态模型的发展提供支持。
-
移动端部署优化: PyTorchVideo支持针对移动端模型的部署优化(使用前述的PyTorchVideo/accelerator模块),模型经过PyTorchVideo优化了最高达7倍的提速,并实现了第一个能实时跑在手机端的X3D模型(实验中可以实时跑在2018年的三星Galaxy S8上,具体请见Android Demo APP)。
3.torchtext
torchtext是Pytorch用于自然语言处理(NLP)的工具包,由于NLP和CV在数据预处理中的不同,因此NLP的工具包torchtext和torchvision等CV相关工具包也有一些功能上的差异,如:
-
数据集(dataset)定义方式不同
-
数据预处理工具
-
没有琳琅满目的model zoo(主要是由于NLP常用的网络结构比较固定,torchtext并不像torchvision那样提供一系列常用的网络结构。模型主要通过torch.nn中的模块来实现,比如torch.nn.LSTM、torch.nn.RNN等。)
torchtext可以方便的对文本进行预处理,例如截断补长、构建词表等。torchtext主要包含了以下的主要组成部分:
-
数据处理工具 torchtext.data.functional、torchtext.data.utils
-
数据集 torchtext.data.datasets
-
词表工具 torchtext.vocab
-
评测指标 torchtext.metrics
3.1 torchtext.data.datasets
Field是torchtext中定义数据类型以及转换为张量的指令。torchtext 认为一个样本是由多个字段(文本字段,标签字段)组成,不同的字段可能会有不同的处理方式,所以才会有 Field 抽象。定义Field对象是为了明确如何处理不同类型的数据,但具体的处理则是在Dataset中完成的。
例如
tokenize = lambda x: x.split() # 字符串分割函数
TEXT = data.Field(sequential=True, tokenize=tokenize, lower=True, fix_length=200)
LABEL = data.Field(sequential=False, use_vocab=False)
其中:
-
sequential设置数据是否是顺序表示的;
-
lower设置是否将字符串全部转为小写;
-
fix_length设置此字段所有实例都将填充到一个固定的长度,方便后续处理;
-
use_vocab设置是否引入Vocab object,如果为False,则需要保证之后输入field中的data都是numerical的。
基于Field的构建结果,即可借助torchtext.data库来构建数据集:
from torchtext import data
def get_dataset(csv_data, text_field, label_field, test=False):
fields = [("id", None), # we won't be needing the id, so we pass in None as the field
("comment_text", text_field),
("toxic", label_field)]
examples = []
if test:
# 如果为测试集,则不加载label
for text in tqdm(csv_data['comment_text']):
examples.append(data.Example.fromlist([None, text, None], fields))
else:
for text, label in tqdm(zip(csv_data['comment_text'], csv_data['toxic'])):
examples.append(data.Example.fromlist([None, text, label], fields))
return examples, fields
上述中csv文件中仅有两列,分别为comment_text和toxic,前者是文本,后者是标签。通过上述get_dataset方法,分别传入csv文件名以及TEXT和LABEL两个Field即可获取数据集。
3.2 torchtext.vocab
在NLP中,将字符串形式的词语(word)转变为数字形式的向量表示(embedding)是非常重要的一步,被称为Word Embedding。这一步的基本思想是收集一个比较大的语料库(尽量与所做的任务相关),在语料库中使用word2vec之类的方法构建词语到向量(或数字)的映射关系,之后将这一映射关系应用于当前的任务,将句子中的词语转为向量表示。
在torchtext中可以使用Field自带的build_vocab函数完成词汇表构建。
TEXT.build_vocab(train)
3.3 torchtext.Iterator
数据迭代器,用于在训练过程中动态载入训练数据,和torchvision中相似。
from torchtext.data import Iterator, BucketIterator
# 若只针对训练集构造迭代器
train_iter = data.BucketIterator(dataset=train, batch_size=8, shuffle=True, sort_within_batch=False, repeat=False)
# 同时对训练集和验证集进行迭代器的构建
train_iter, val_iter = BucketIterator.splits(
(train, valid), # 构建数据集所需的数据集
batch_sizes=(8, 8),
device=-1, # 如果使用gpu,此处将-1更换为GPU的编号
sort_key=lambda x: len(x.comment_text), # the BucketIterator needs to be told what function it should use to group the data.
sort_within_batch=False
)
test_iter = Iterator(test, batch_size=8, device=-1, sort=False, sort_within_batch=False)
参考资料
第八章:PyTorch生态简介 — 深入浅出PyTorch