MySQL语句执行过程
1. server层组件介绍
MySQL分为server层和存储引擎层,
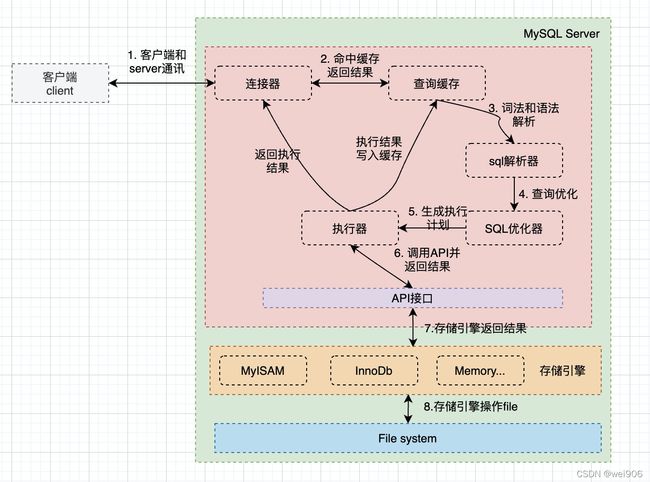
Server 层:主要包括连接器、查询缓存、分析器、优化器、执行器等,所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图,函数等,还有一个通用的日志模块 binglog 日志模块。
存储引擎: 主要负责数据的存储和读取。
连接器:负责跟客户端建立连接、获取权限、维持和管理连接。在完成经典的TCP握手后,连接器会做身份鉴权。一旦连接建立成功后,权限就不会再受到影响,即使你用管理员账号对这个用户的权限做了修改。连接建立完成后会放入连接池,超过wait_timeout后没使用就会断开,再次使用会出现Lost connection to MySQL server during query。 MySQL 5.7或更新版本,可以在每次执行一个比较大的操作后,通过执行 mysql_reset_connection来重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
查询缓存:缓存key是查询的语句,value是查询的结果。MySQL拿到一个查询请求后,会先到查询缓存看看,命中缓存直接返回缓存结果。MySQL 8.0 版本后移除,因为查询缓存的失效非常频繁,其他版本可以将参数query_cache_type设置成DEMAND,这样对于默认的SQL语句都不使用查询缓存。
分析器: 没有命中缓存的话,SQL 语句就会经过分析器,分析器先会做词法分析,然后根据词法做“语法分析”,判断输入SQL语句是否满足MySQL语法。
优化器: 优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。按照 MySQL 认为最优的方案去执行。
执行器: 执行语句,然后从存储引擎返回数据。
2. update/insert/delete 语句执行过程
buffer bool : innodb为了提升读写效率,设计了一个缓冲区buffer bool 每次从磁盘读取固定大小的数据存储到缓冲区buffer pool。缓冲区还没有从内存区同步到磁盘的时候,叫做脏页,因为断电等其他操作可能会导致与磁盘数据不一致。由后台线程同步到磁盘,不断进行,动作叫刷脏。
redo log:为了解决缓存刷新到磁盘的不一致问题,innoDb设计了redolog。redo log 写入日志是采用的是顺序IO,减少了寻址次数,加快IO的读写速度。这也是经常说到的WAL技术,WAL的全称是Write-Ahead Logging。redo log 默认 48M ib_logfile0 ib_logfile1 ,记录在某个数据页进行了什么修改,属于物理日志。redolog 写满了触发刷盘操作,可以尽量设置的大一点,延缓redolog 的刷盘频率。
undo log: 记录事物发生之前的数据状态,发生异常时候回滚,保证数据的原子性。作用场景:如果一个操作包含多个sql语句,如果执行了一半失败了,保证所有的sql失败或者成功,实现原子性。没有独立的日志~
Binlog: mysql server层自己的日志记录称之为binlog,有三种模式:statement 格式的话是记sql语句, row格式会记录行的内容,记两条,更新前和更新后都有; MIXED模式,一般的复制使用 STATEMENT 模式保存 bin log ,对于 STATEMENT 模式无法复制的操作使用 ROW 模式保存 bin log。
2.1 insert 操作过程
- 会话session状态转换为update
- 激活事务状态由 not_active 变为 active
- 查找定位数据
- 进行乐观插入
- 记录insert的undo记录
- 记录undo的redo log 入redo buffer
- 进行insert 元组插入,及实际的插入操作
- 记录插入的redo log 入redo buffer
- binlog event 写入到 binlog cache
- 会话状态转换为query end
-
进入提交准备
-
binlog准备
-
innodb层事物准备,状态由 active变为 prepare
-
-
进入提交阶段
1) innodb进行组提交,确保redo落盘
2) binlog cache 进行flush到binlog文件
3) sync binlog文件进行os缓存落盘
4) innodb 进行提交,事物状态由 prepare 变为 not_active
2.2 update 执行过程
update 语句经过连接、解析、优化和执行后,进入引擎层。
1. 首先判断该SQL涉及到的页是否存在于缓存中,如果不存在则从磁盘读取该行记录所在的数据页并加载到BP缓冲池。通过B+树方式把磁盘索引页添加到BP中,具体过程为 space id 和 page no 哈希计算之后把 索引页加载到指定的 buffer pool instance 中。判断 free list 是否有空闲页可用(Innodb_buffer_pool_pages_free、 Innodb_buffer_pool_wait_free),没有则淘汰脏页或者lru list的Old页,把数据页 copy到 free list中,然后加载到 lru list的 old区的 midpoint(头部);
2. 通过二分法查找该页对应的记录,试图给这个SQL涉及到的行记录加上排他锁,过程如下
- 如果事务当前记录的行锁被其他事务占用的话,就需要进入锁等待;
- 进入锁等待之后,同时判断会不会由于自己的加入导致了死锁;
- 检测到没有锁等待和不会造成死锁之后,行记录加上排他锁。
3. 写逻辑的undo:
- 将修改前的记录写入undo中;
- 修改当前行的值,填写事务编号,使用回滚指针指向undo log中的修改前的行,从而构建回滚段,用于回滚数据和实现MVCC的多版本;
- 写redo log buffer:先判断redo log buffer是否够用,redo log buffer不够用就等待,因为redo group commit的原因,这次事务所产生的redo log buffer可能会跟随其它事务一同flush并且sync到磁盘上;
- 字段值在BP缓冲池更新成功以后,对应的数据页就是脏页了
4. 写binlog cache:同时修改的信息,会按照event的格式,记录到binlog_cache中。
5. 写change buffer: 之后把这条sql, 需要在二级索引上做的修改,写入到change buffer page,等到下次有其他sql需要读取该二级索引时,再去与二级索引做merge。
6. 事务commit or rollback。此时update语句已经完成,需要commit或者rollback。这里讨论双1即sync_binlog=1 和 innodb_flush_log_at_trx_commit=1;
事务的COMMIT 分为prepare阶段与COMMIT阶段
事务的COMMIT操作,在存储引擎层与server层之间采用的是内部XA;两阶段提交协议, 保证两个事务的一致性,这里主要保证redo log和binlog的原子性;
redo log prepare:
- 写入redo log处于prepare状态并且写入事务的xid;
- 将 redo log buffer 刷新到 redo log磁盘文件中,用于崩溃恢复;
- binlog write&fsync: 执行器把 binlog cache 里的完整事务和 redo log prepare中的XID 写入到 binlog 中。
- 事务执行过程中,先把日志写到 binlog cache,事务提交的时候,再把 binlog cache 写到 binlog file中;dump线程从binlog_cache里把event主动发送给slave的I/O线程,同时执行 fsync刷盘(大事务的话这步非常耗时),并清空 binlog cache。
redo log commit:
commit阶段,由于之前该事务产生的redo log已经sync到磁盘了。所以这步只是在redo log里标记commit,说明事务提交成功。
7. 事务提交成功,释放行记录持有的排他锁;
8. 当binlog和redo log都已经落盘以后,如果触发了刷新脏页的操作,先把该脏页复制到doublewrite buffer里,其次把doublewrite buffer里的刷新到共享表空间(ibdata),然后才是把脏页写入到磁盘中;
事务ROLLBACK
如果事务显示rollback,要借助undolog中的数据来进行恢复。对于in-place(原地)更新,将数据回滚到最老版本;对于delete+insert方式进行的,标记删除的记录清理删除标记,同时把插入的聚集索引和二级索引记录也会被直接删除。

参考:mysql 一条sql执行流程 - 简书