数学建模-线性回归
多元线性回归
回归分析: 通过研究自变量X和因变量Y的相关关系,尝试去解释Y的形成机制,进而达到通过X去预测Y的目的。
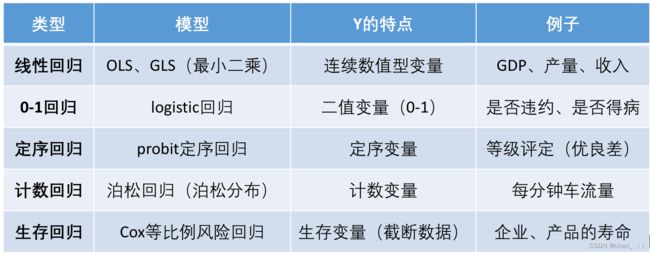
本次主要学习线性回归。(划分依据是因变量Y的类型)
ps. other 0-1回归,定序回归,计数回归,生存回归
(一)基本概念
a. 关键词
关键词: 相关性,Y,X
相关性 != 因果性
Y 是需要研究的核心变量(因变量)
X是解释变量(自变量)
b. 回归分析的作用
- 分析哪些X变量是同Y真的相关,哪些不是 (变量选择) -----采用 逐步回归法
- 除去与Y不相关的X变量之后,需要分析这些重要的X同Y相关系数 正负 的关系
- 赋予不同X不同的权值(即不同的回归系数,进而知道不同变量之间的相对重要性)
三个使命:
一. 识别重要变量
二. 判断相关性的方向
三. 要估计权重(回归系数)
c. 线性回归的要求
模型: OLS 、GLS (最小二乘)
Y的特点:连续数值型变量
栗子: GDP、产量、收入
ps. 区分
d. 数据分类
- 横截面数据: 同一时间点收集的不同对象的数据 (各对象)
- 时间序列数据: 同一对象在不同时间连续观察的数据 (各时间)
- 面板数据:1和2的综合 (各对象+各时间)
ps.

所以在多元线性回归中重点关注 横截面数据
e. 一元线性回归
类似拟合的做法(一元线性函数拟合)
数学建模-拟合算法
(二)基础概念解释
a. 线性关系
线性假设不要求初始模型都呈现严格的线性关系
自变量和因变量可以通过变量替换转化成线性模型
所以 在进行线性回归模型进行建模前,需要对数据进行预处理(Excel、Matlab、Stata)
b. 回归系数的解释
在保持其他变量不变的情况下,XXX 每增加or减少一个单位,该产品的平均XXX 增加or减少 …
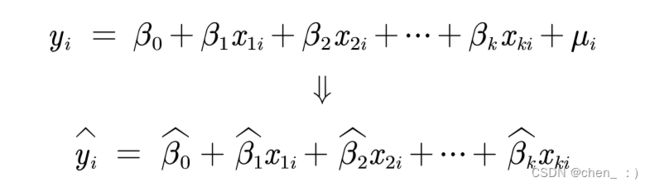
β0_h 的数值意义一般不讨论
βi_h 可以用数学中的偏导数来定义, 在保持其他变量不变的情况下,自变量xi的变化 对 yi 的影响
c. 内生性的探究
遗漏变量会导致内生性

假设的模型中u表示无法观测且满足一定条件的扰动项
如果满足误差项u和所有的自变量x均不相关,则该模型具有外生性
(如果相关则满足内生性,将会导致回归系数估计的不准确:不满足无偏和一致性)
u包含了所有与y相关,但未添加到回归模型中的变量
如果这些变量和我们已经添加的自变量相关,则存在内生性
在一般模型中,被解释变量应该是内生的,解释变量应该是外生的,解释变量的取值是不能被我们的模型所决定的。
内生性产生的原因
- 测量误差(measurement error)
- 遗漏解释变量(explanatory variable omitted)
- 互为因果(simultaneity)
重点关注第2点
具体分析与解释: 内生性问题及其产生原因
我们也可以利用内生性的蒙特卡罗仿真进行模拟
蒙特卡罗方法详解
代码:数学建模多元线性回归内生性问题的蒙特卡洛模拟matlab代码
若要满足无内生性的条件很难满足,可以适当弱化条件:
将解释变量分成核心解释变量和控制变量两类
只需满足核心解释变量与u不相关即可
d. 虚拟变量X
对于定性变量(性别、地域 and so on),可以利用虚拟变量给予数值定义
注意为了避免完全多重共线性的影响,引入虚拟变量的个数一般是分类数减1 (在stata会进行自动处理,无需关心)
eg. from 清风数学建模

e. 含交互项的自变量
f. 球型扰动项
在之前的回归分析中,我们都默认了扰动项是球型扰动项。
球型扰动项:满足“同方差”和“无自相关”两个条件。
但是:
横截面数据容易出现异方差的问题
时间序列数据容易出现自相关的问题。
g. 异方差概念
这里的异方差可以理解为对于模型的稳定程度所做的贡献
异方差是指各个扰动项的方差不相同,那么方差较大的扰动项破坏模型稳定性的程度就较大
扰动项存在异方差:
- OLS估计出来的回归系数是无偏、一致的
- 假设检验无法使用(构造的统计量失效了)
- OLS估计量不再是最优线性无偏估计量(BLUE)
解决异方差:
- 使用OLS + 稳健的标准误
- 广义最小二乘估计法GLS
方差较小的数据给予更大的权重
方差较小的数据包含的信息较多,我们可以给予信息量大的数据更大的权重
e. 异方差的检验方法
采用假设检验法 (H0 & H1)
- BP检验
方法:见 stata
原假设:扰动项不存在异方差
P值小于0.05,说明在95%的置信水平下拒绝原假设,即我们认为扰动项存在异方差。 - 怀特检验
方法:见stata
怀特检验原假设:不存在异方差
f. 异方差的处理方法
-
使用OLS + 稳健的标准误
仍然进行OLS 回归,但使用稳健标准误
这是最简单,也是目前通用的方法
只要样本容量较大,即使在异方差的情况下,若使用稳健标准误,则所 有参数估计、假设检验均可照常进行。 -
广义最小二乘法GLS
原理:方差较大的数据包含的信息较少,我们可以给予信息量大的数据(即方差
较小的数据更大的权重)
缺点:我们不知道扰动项真实的协方差矩阵,因此我们只能用样本数据来估计,
这样得到的结果不稳健,存在偶然性。
Stock and Watson (2011)推荐,在大多数情况下应该使用“OLS + 稳健标准误”。
g. 多重共线性
from 清风数学建模课件


处理方法:
-
不关心具体的回归系数,而只关心整个方程预测被解释变量的能力,则
通常可以 不必理会多重共线性(假设你的整个方程是显著的) -
关心具体的回归系数,但多重共线性并不影响所关心变量的显著性,那
么也可以不必理会。 -
多重共线性影响到所关心变量的显著性,则需要增大样本容量,剔除导
致严重共线性的变量(不要轻易删除,因为可能会有内生性的影响),或对
模型设定进行修改。
h. 逐步回归分析
-
向前逐步回归
将自变量逐个引入模型,每引入一个自变量后都要进行检验,显著时才加入回归模型。
(缺点:随着以后其他自变量的引入,原来显著的自变量也可能又变为不显著了,
但是,并没有将其及时从回归方程中剔除掉。) -
向后逐步回归
与向前逐步回归相反
先将所有变量均放入模型,之后尝试将其中一个自变量从模型中剔除,看整个模型解释因变量的变异是否有显著变化,之后将最没有解释力的那个自变量剔除;此过程不断迭代,直到没有自变量符合剔除的条件。
(缺点:计算量大。当然随着现在计算机的能力的提升,已经变得不成问题)
一般采用向后逐步回归
注意:
- 向前逐步回归和向后逐步回归的结果可能不同
- 不要轻易使用逐步回归分析,因为剔除了自变量后很有可能会产生新的问
题,例如内生性问题 - 更加优秀的筛选方法:每种情况都尝试一次,最终一共有排列组合种可能。如果自变量很多,那么计算相当费时
(三)线性回归常用建模方法
a. 取对数ln处理
经验法则:

取对数的好处:
- 减弱数据的异方差性
- 如果变量本身不符合正态分布,取了对数后可能渐近服从正态分布
- 模型形式的需要,让模型具有经济学意义
 ps. 详细见ppt
ps. 详细见ppt
证明见 多元线性回归分析 II
b. 标准化回归系数
目的:去除量纲的影响
为了更为精准的研究影响评价量的重要因素
方法: 对数据进行标准化处理
将原始数据减去它的均数后,再除以该变量的标准差,计算得到新的变量值
新变量构成的回归方程称为标准化回归方程,回归后相应可得到标准化回归系数。
标准化系数的绝对值越大,说明对因变量的影响就越大(只关注显著的回归系数)
注意:
常数项没有标准化回归系数: 常数的均值是其本身,经过标准化后变成了0.
和之前的回归结果完全相同,除了多了最后那一列标准化回归系数:
对数据进行标准化处理不会影响回归系数的标准误,也不会影响显著性.
c. 使用 OLS + 稳健的标准误 解决异方差问题
e. 利用逐步回归选取重要的变量
(四)利用Stata软件进行建模
a. 导入excel
import excel " "
b. 描述性统计
- 对于定量数据
summarize 变量1 变量2 ....
可以直接图表中点击加入
- 对于定性数据
tabulate 变量名,gen(A)
返回对应的这个变量的频率分布表,并生成对应的虚拟变量(以A开头)。
也可以利用Excel的数据透视表进行分析
Excel 数据透视表怎么做
Excel的透视表:概念、用途、应用
c. 回归
regress y x1 x2 ... xk
ps. 在变量窗口中按住Shift不放,可同时选中一列,然后再直接拖动到输入区域
默认使用OLS:普通最小二乘估计法
from 清风数学建模课件

Stata会自动检测数据的完全多重共线性问题
e. 拟合优度 R2
若拟合优度较低
可以:
- 对模型进行调整,例如对数据取对数或者平方后再进行回归。
- 回归分为解释型回归和预测型回归
预测型回归一般才会更看重2
解释型回归更多的关注模型整体显著性以及自变量的统计显著性和经济意义显著 - 数据中可能有存在异常值或者数据的分布极度不均匀
我们引入的自变量越多,拟合优度会变大
倾向于使用调整后的拟合优度

f. 标准化回归
regress y x1 x2 ... xk, beta
g. 检验异方差
在回归结束后运行命令:
rvfplot (画残差与拟合值的散点图)
rvpplot x (画残差与自变量x的散点图)
h. BP检验
在回归结束后使用:
estat hettest ,rhs iid
属于异方差的假设检验
i. 怀特检验
在回归结束后使用:
estat imtest,white
j. OLS + 稳健的标准误
regress y x1 x2 … xk,robust
k. 检验多重共线性
Stata计算各自变量VIF的命令(在回归结束后使用):
estat vif
l. 向前逐步回归Forward selection
stepwise regress y x1 x2 … xk, pe(#1)
pe(#1) specifies the significance level for addition to the model; terms with p<#1 are eligible for addition(显著才加入模型中).
m. 向后逐步回归Backward elimination
tepwise regress y x1 x2 … xk, pr(#2)
pr(#2) specifies the significance level for removal from the model; terms with p>= #2 are eligible for removal(不显著就剔除出模型).
注:
(1)x1 x2 … xk之间不能有完全多重共线性 (和regress不同,要自己手动去设置)
(2)可以在后面再加参数b和r,即标准化回归系数或稳健标准误
(五)参考资料
清风数学建模
数学建模-拟合算法
内生性问题及其产生原因
蒙特卡罗方法详解
数学建模多元线性回归内生性问题的蒙特卡洛模拟matlab代码
Excel 数据透视表怎么做
Excel的透视表:概念、用途、应用
多元线性回归分析 II