Pytorch实战_神经网络的压缩(Network Compression)
1. 神经网络的压缩
对于一些大型的神经网络,它的网络结构是十分复杂的(听说华为的一些神经网络有上亿的神经元组成),我们很难在很小的设备中(比如我们的apple watch)上面将这个这个神经网络放上去。这就要求我们能有能力将神经网络进行压缩,也就是 Network Compression。
李宏毅老师在课程中提到了5中神经网络的压缩方式:
- Network Pruning
- Knowledge Distillation
- Parameter Quantization
- Architec Design
- Dynamic Computation
下面我们来一一简单地介绍
1.1 Network Pruning
神经网络的修剪主要是从两个角度去完成:
- 权重的重要性
- 神经元的重要性
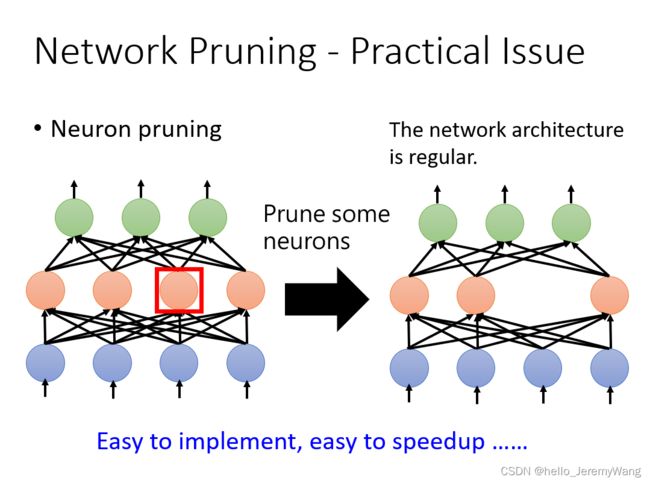
其中权重的重要性可以使用常见的 L1 或者 L2 范数去刻画;而神经元的重要性可以通过该神经元在给定数据集时不为零的次数来决定。(仔细想想,这和决策树的剪枝也挺像的)。从下面两幅图,我们也可以看出两种修剪方式的不同。通常情况下,为了使得我们的网络更好搭建,我们选择根据神经元的重要性进行修剪。

1.2 Knowledge Distillation
Knowledge Distillation 就是训练一个小的网络去模拟已经训练出来的大网络的输出结果。如下图所示,小的网络的输出应该尽量和大网络的输出一致。我们一般通过交叉熵损失来衡量这种一致性的好坏。

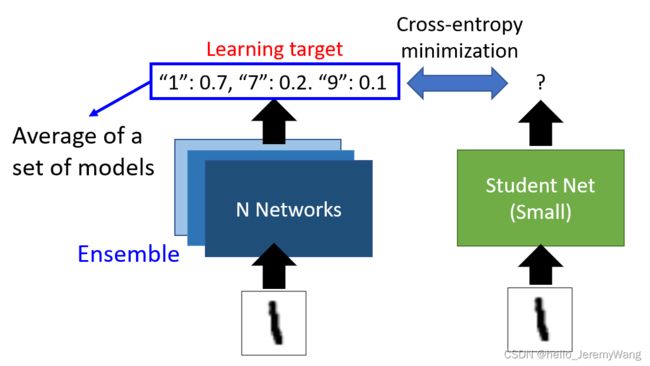
有时候,我们会去让小网络去模拟一群大网络集成后的结果,具体操作如下图所示:
1.3 Parameter Quantization
Parameter Quantization 的主要思想是使用聚类的方法将相似的权重聚在一起,并统一使用一个值去代替。如下图所示:

1.4 Architec Design
Architec Design 是通过改变网络的结构,以使得网络的参数大大减少。我们先来看一个例子。这个例子有点像矩阵分解里面的 SVD ,对于一个 N × M N \times M N×M 的全连接层,我们通过在其中再加一个长度为 K K K 的线性层,来达到减少参数的目的。我们可以近似地把这个操作看做将 N × M N \times M N×M 的矩阵用 N × K N \times K N×K 和 K × M K \times M K×M 两个矩阵的乘积去代替,当 K K K 远小于 M M M 和 N N N 的时候,参数的减少是很明显的。

对于我们常见的 CNN 网络,如下图这个2个channel的图像,一般的卷积操作是每次都使用一个2个channel的卷积核去做卷积,粉色的卷积核操作后得到粉色的一个矩阵,黄的卷积核操作后得到黄色的一个矩阵,以此类推。

对于Architec Design,通常使用Depthwise convolution 和 Pointwise convolution 相结合来达到上述的卷积效果。其中二者的具体操作如下图所示:(卷积后的结果是由相同颜色的卷积核在经过卷积操作后得到的)

2. Pytorch代码
下面的代码使用 Architec Design 的思想对 CNN 网络进行了简化,实验结果发现,简化后的效果还是不错的。
Depthwise convolution 和 Pointwise convolution 可以通过如下代码实现:
# 一般的Convolution, weight大小 = in_chs * out_chs * kernel_size^2
nn.Conv2d(in_chs, out_chs, kernel_size, stride, padding)
# Depthwise Convolution, 输入chs=输出chs=Groups数目, weight大小 = in_chs * kernel_size^2
nn.Conv2d(in_chs, out_chs=in_chs, kernel_size, stride, padding, groups=in_chs)
# Pointwise Convolution, 也就是1 by 1 convolution, weight大小 = in_chs * out_chs
nn.Conv2d(in_chs, out_chs, 1)
网络的代码如下:
import torch.nn as nn
import torch.nn.functional as F
import torch
class StudentNet(nn.Module):
'''
在这个Net里面,我们会使用Depthwise & Pointwise Convolution Layer求解model。
你会发现,将原本的Convolution Layer换成Dw & Pw后,Accuracy通常不会降很多。
另外,取名为StudentNet是因为这个Model等会可以接着做Knowledge Distillation。
'''
def __init__(self, base=16, width_mult=1):
'''
Args:
base: 这个model一开始的ch数量,每通过一层都会*2,直到base*16为止。
width_mult: 为了之后的Network Pruning使用,在base*8 chs的Layer上会 * width_mult代表剪枝后的ch数量。
'''
super(StudentNet, self).__init__()
multiplier = [1, 2, 4, 8, 16, 16, 16, 16]
# bandwidth: 每一层Layer所使用的ch数量
bandwidth = [ base * m for m in multiplier]
# 我们只Pruning第三层以后的Layer
for i in range(3, 7):
bandwidth[i] = int(bandwidth[i] * width_mult)
self.cnn = nn.Sequential(
# 第一次我们通常不会拆解Convolution Layer。
nn.Sequential(
nn.Conv2d(3, bandwidth[0], 3, 1, 1),
nn.BatchNorm2d(bandwidth[0]),
nn.ReLU6(),
nn.MaxPool2d(2, 2, 0),
),
# 接下來每一个Sequential Block都一样,所以我们只讲Block
nn.Sequential(
# Depthwise Convolution
nn.Conv2d(bandwidth[0], bandwidth[0], 3, 1, 1, groups=bandwidth[0]),
# Batch Normalization
nn.BatchNorm2d(bandwidth[0]),
# ReLU6 是限制Neuron最小只会到0,最大只会到6。 MobileNet系列都是使用ReLU6。
# 使用ReLU6的原因是因为如果数字太大,会不好压到float16 / or further qunatization,因此才给限制。
nn.ReLU6(),
# Pointwise Convolution
nn.Conv2d(bandwidth[0], bandwidth[1], 1),
# 用完Pointwise Convolution不需要再做ReLU,经验上Pointwise + ReLU效果都会变差。
nn.MaxPool2d(2, 2, 0),
# 每过完一个Block就Down Sampling
),
nn.Sequential(
nn.Conv2d(bandwidth[1], bandwidth[1], 3, 1, 1, groups=bandwidth[1]),
nn.BatchNorm2d(bandwidth[1]),
nn.ReLU6(),
nn.Conv2d(bandwidth[1], bandwidth[2], 1),
nn.MaxPool2d(2, 2, 0),
),
nn.Sequential(
nn.Conv2d(bandwidth[2], bandwidth[2], 3, 1, 1, groups=bandwidth[2]),
nn.BatchNorm2d(bandwidth[2]),
nn.ReLU6(),
nn.Conv2d(bandwidth[2], bandwidth[3], 1),
nn.MaxPool2d(2, 2, 0),
),
# 到目前为止因为图片已经被Down Sample很多次了,所以就不做MaxPool
nn.Sequential(
nn.Conv2d(bandwidth[3], bandwidth[3], 3, 1, 1, groups=bandwidth[3]),
nn.BatchNorm2d(bandwidth[3]),
nn.ReLU6(),
nn.Conv2d(bandwidth[3], bandwidth[4], 1),
),
nn.Sequential(
nn.Conv2d(bandwidth[4], bandwidth[4], 3, 1, 1, groups=bandwidth[4]),
nn.BatchNorm2d(bandwidth[4]),
nn.ReLU6(),
nn.Conv2d(bandwidth[5], bandwidth[5], 1),
),
nn.Sequential(
nn.Conv2d(bandwidth[5], bandwidth[5], 3, 1, 1, groups=bandwidth[5]),
nn.BatchNorm2d(bandwidth[5]),
nn.ReLU6(),
nn.Conv2d(bandwidth[6], bandwidth[6], 1),
),
nn.Sequential(
nn.Conv2d(bandwidth[6], bandwidth[6], 3, 1, 1, groups=bandwidth[6]),
nn.BatchNorm2d(bandwidth[6]),
nn.ReLU6(),
nn.Conv2d(bandwidth[6], bandwidth[7], 1),
),
# 这里我们采用Global Average Pooling。
# 如果输入图片大小不一样的话,就会因为Global Average Pooling变成一样的形状,这样子接下来做FC就不会对不起来。
nn.AdaptiveAvgPool2d((1, 1)),
)
self.fc = nn.Sequential(
# 这里我们直接Project到11维输出答案。
nn.Linear(bandwidth[7], 11),
)
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1)
return self.fc(out)