本来是一个平静而美好的下午,其他部门的同事要一份数据报表临时汇报使用,因为系统目前没有这个维度的功能,所以需要写个SQL马上出一下,一个同事接到这个任务,于是开始在测试环境拼装这条 SQL,刚过了几分钟,同事已经自信的写好了这条SQL,于是拿给DBA,到线上跑一下,用客户端工具导出Excel 就好了,毕竟是临时方案嘛。
就在SQL执行了之后,意外发生了,先是等了一下,发现还没执行成功,猜测可能是数据量大的原因,但是随着时间滴滴答答流逝,逐渐意识到情况不对了,一看监控,CPU已经上去了,但是线上数据量虽然不小,也不至于跑成这样吧,眼看着要跑死了,赶紧把这个事务结束掉了。
什么原因呢?查询的条件和 join 连接的字段基本都有索引,按道理不应该这样啊,于是赶紧把SQL拿下来,也没看出什么问题,于是限制查询条数再跑了一次,很快出结果了,但是结果却大跌眼镜,出来的查询结果并不是预期的。
经过一番检查之后,最终发现了问题所在,是 join 连接中有一个字段写错了,因为这两个字段有一部分名称是相同的,于是智能的 SQL 客户端给出了提示,顺手就给敲上去了。但是接下来,更让人迷惑了,因为要连接的字段是 int 类型,而写错的这个字段是 varchar 类型,难道不应该报错吗?怎么还能正常执行,并且还有预期外的查询结果?
难道是 MySQL 有 bug 了,必须要研究一下了。
复现当时的情景
假设有两张表,这两张表的结构和数据是下面这样的。
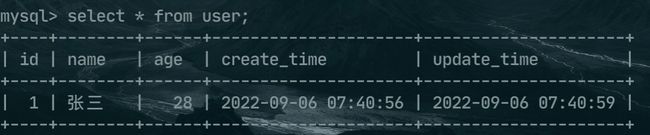
第一张 user表。
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(50) COLLATE utf8_bin DEFAULT NULL, `age` int(3) DEFAULT NULL, `create_time` datetime DEFAULT NULL, `update_time` datetime DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 COLLATE=utf8_bin; INSERT INTO `user` VALUES (1, '张三', 28, '2022-09-06 07:40:56', '2022-09-06 07:40:59');
第二张 order表
CREATE TABLE `order` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` int(11) DEFAULT NULL, `order_code` varchar(64) COLLATE utf8_bin DEFAULT NULL, `money` decimal(20,0) DEFAULT NULL, `title` varchar(255) COLLATE utf8_bin DEFAULT NULL, `create_time` datetime DEFAULT NULL, `update_time` datetime DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 COLLATE=utf8_bin; INSERT INTO `order` VALUES (1, 2, '1d90530e-6ada-47c1-b2fa-adba4545aabd', 100, 'xxx购买两件商品', '2022-09-06 07:42:25', '2022-09-06 07:42:27');

目的是查看所有用户的 order 记录,假设数据量比较少,可以直接查,不考虑性能问题。
本来的 SQL 语句应该是这样子的,查询 order表中用户iduser_id在user表的记录。
select o.* from `user` u left JOIN `order` o on u.id = o.user_id;
但是呢,因为手抖,将 on 后面的条件写成了 u.id = o.order_code,完全关联错误,这两个字段完全没有联系,而且u.id是 int 类型,o.order_code是varchar类型。
select o.* from `user` u left JOIN `order` o on u.id = o.order_code;
这样的话, 当我们执行这条语句的时候,会不会查出数据来呢?
我的第一感觉是,不仅不会查出数据,而且还会报错,因为连接的这两个字段类型都不一样,值更不一样。
结果却被啪啪打脸,不仅没有报错,而且还查出了数据。

可以把这个问题简化一下,简化成下面这条语句,同样也会出现问题。
select * from `order` where order_code = 1;

明明这条记录的 order_code 字段的值是 1d90530e-6ada-47c1-b2fa-adba4545aabd,怎么用 order_code=1的条件就把它给查出来了。
根源所在
相信有的同学已经猜出来了,这里是 MySQL 进行了隐式转换,由于查询条件后面跟的查询值是整型的,所以 MySQL 将 order_code字段进行了字符串到整数类型的转换,而转换后的结果正好是 1。
通过 cast函数转换验证一下结果。
select cast('1d90530e-6ada-47c1-b2fa-adba4545aabd' as unsigned);

再用两条 SQL 看一下字符串到整数类型转换的规则。
select cast('223kkk' as unsigned);
select cast('k223kkk' as unsigned);
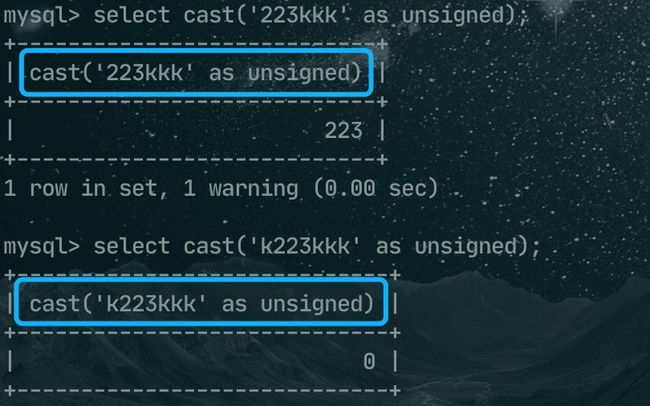
223kkk转换后的结果是 223,而k223kkk转换后的结果是0。总结一下,转换的规则是:
1、从字符串的左侧开始向右转换,遇到非数字就停止;
2、如果第一个就是非数字,最后的结果就是0;
隐式转换的规则
当操作符与不同类型的操作数一起使用的时候,就会发生隐式转换。
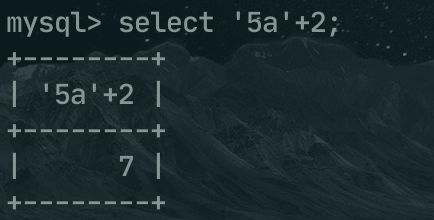
例如算数运算符的前后是不同类型时,会将非数字类型转换为数字,比如 '5a'+2,就会将5a转换为数字类型,然后和2相加,最后的结果就是 7 。
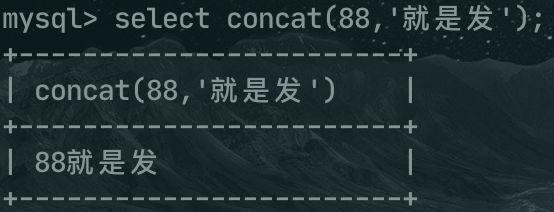
再比如 concat函数是连接两个字符串的,当此函数的参数出现非字符串类型时,就会将其转换为字符串,例如concat(88,'就是发'),最后的结果就是 88就是发。
MySQL 官方文档有以下几条关于隐式转换的规则:
1、两个参数至少有一个是 NULL 时,比较的结果也是 NULL,例外是使用 <=> 对两个 NULL 做比较时会返回 1,这两种情况都不需要做类型转换;
也就是两个参数中如果只有一个是NULL,则不管怎么比较结果都是 NULL,而两个 NULL 的值不管是判断大于、小于或等于,其结果都是1。
2、两个参数都是字符串,会按照字符串来比较,不做类型转换;
3、两个参数都是整数,按照整数来比较,不做类型转换;
4、十六进制的值和非数字做比较时,会被当做二进制字符串;
例如下面这条语句,查询 user 表中name字段是 0x61 的记录,0x是16进制写法,其对应的字符串是英文的 'a',也就是它对应的 ASCII 码。
select * from user where name = 0x61;
所以,上面这条语句其实等同于下面这条
select * from user where name = 'a';
可以用 select 0x61;验证一下。
5、有一个参数是 TIMESTAMP 或 DATETIME,并且另外一个参数是常量,常量会被转换为 时间戳;
例如下面这两条SQL,都是将条件后面的值转换为时间戳再比较了,只不过
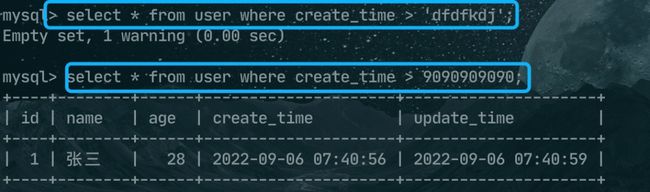
6、有一个参数是 decimal 类型,如果另外一个参数是 decimal 或者整数,会将整数转换为 decimal 后进行比较,如果另外一个参数是浮点数(一般默认是 double),则会把 decimal 转换为浮点数进行比较;
在不同的数值类型之间,总是会向精度要求更高的那一个类型转换,但是有一点要注意,在MySQL 中浮点数的精度只有53 bit,超过53bit之后的话,如果后面1位是1就进位,如果是0就直接舍弃。所以超大浮点数在比较的时候其实只是取的近似值。
7、所有其他情况下,两个参数都会被转换为浮点数再进行比较;
如果不符合上面6点规则,则统一转成浮点数再进行运算
避免进行隐式转换
我们在平时的开发过程中,尽量要避免隐式转换,因为一旦发生隐式转换除了会降低性能外, 还有很大可能会出现不期望的结果,就像我最开始遇到的那个问题一样。
之所以性能会降低,还有一个原因就是让本来有的索引失效。
select * from `order` where order_code = 1;
order_code 是 varchar 类型,假设我已经在 order_code 上建立了索引,如果是用“=”做查询条件的话,应该直接命中索引才对,查询速度会很快。但是,当查询条件后面的值类型不是 varchar,而是数值类型的话,MySQL 首先要对 order_code 字段做类型转换,转换为数值类型,这时候,之前建的索引也就不会命中,只能走全表扫描,查询性能指数级下降,搞不好,数据库直接查崩了。
到此这篇关于MySQL中隐式转换的踩坑记录以及解决方法分享的文章就介绍到这了,更多相关MySQL隐式转换内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!