Docker 深入理解概念
Docker 资源限制的幕后主使cgroup
Docker 中的资源限制技术:CGroups 。 Linux Cgroups 的全称是 Linux Control Group ,简单来说, CGroups 的作用就是限制一个进程组能够使用的资源上限, CPU ,内存等
CGroups 中有几个重要概念:
cgroup :通过 CGroups 系统进行限制的一组进程。 CGroups 中的资源限制都是以进程组为单位实现的,一个进程可以加入到某个进程组,从而受到相同的资源限制。
task :在 CGroups 中, task 可以理解为一个进程。
hierarchy :可以理解成层级关系, CGroups 的组织关系就是层级的形式,每个节点都是一个 cgroup 。 cgroup可以有多个子节点,子节点默认继承父节点的属性。
subsystem :更准确的表述应该是 resource controllers ,也就是资源控制器,比如 cpu 子系统负责控制 cpu时间的分配。子系统必须应用( attach )到一个 hierarchy 上才能起作用。
其中最核心的是 subsystem , CGroups 目前支持的 subsystem 包括:
cpu :限制进程的 cpu 使用率;
cpuacct :统计 CGroups 中的进程的 cpu 使用情况;
cpuset :为 CGroups 中的进程分配单独的 cpu 节点或者内存节点;
memory :限制进程的内存使用;
devices :可以控制进程能够访问哪些设备;
blkio :限制进程的块设备 IO ;
freezer :挂起或者恢复 CGroups 中的进程
net_cls :标记进程的网络数据包,然后可以使用防火墙或者 tc 模块( traffic controller )控制该数据包。这个控制器只适用从该 cgroup 离开的网络包,不适用到达该 cgroup 的网络包;
ns :将不同 CGroups 下面的进程应用不同的 namespace ;
perf_event :监控 CGroups 中的进程的 perf 事件(注: perf 是 Linux 系统中的性能调优工具);
pids :限制一个 cgroup 以及它的子节点中可以创建的进程数目;
rdma :限制 cgroup 中可以使用的 RDMA 资源。
通过上面列举出来的 subsystem ,我们可以简单的了解到,通过 Linux CGroups 我们可以控制的资源包括:
CPU 、内存、网络、 IO 、文件设备等
CGroups 在使用之前需要挂载一下,正常我们使用的系统都应该挂载了,我们可以通过下面的命令查看一下
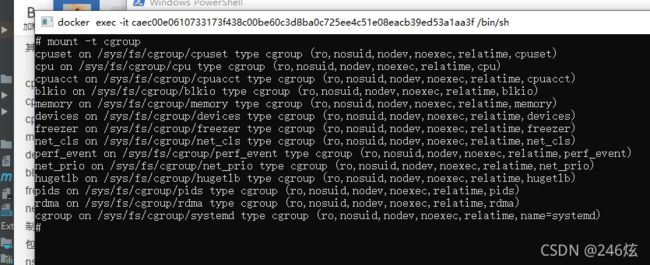
我们可以看到 CGroups 是以文件系统的形式组织起来的,为了文件系统目录 /sys/fs/cgroup/ 目录下,其中每个子目录对应一个 subsystem ,或者说资源控制器。我们看一下 cpu 和 memory 子目录中的数据。

Docker 镜像
docker 镜像分层技术
为什么说是镜像分层技术,因为 Docker 镜像是以层来组织的,我们可以通过命令 docker image inspect 或者 docker inspect 来查看镜像包含哪些层。
docker image inspect nginx:latest
 如上图所示,其中 RootFS 就是镜像 nginx:latest:latest 的镜像层,只有一层,那么这层数是存储在宿主机哪里的呢?好问题。动手实践的同学会在上面的输出中看到一个叫做 GraphDriver 的字段内容如下。
如上图所示,其中 RootFS 就是镜像 nginx:latest:latest 的镜像层,只有一层,那么这层数是存储在宿主机哪里的呢?好问题。动手实践的同学会在上面的输出中看到一个叫做 GraphDriver 的字段内容如下。

"GraphDriver": {
"Data": {
"LowerDir": "/var/lib/docker/overlay2/843afa5e78e1260340ac9b635f95ae3269b171752a1c765d9cab24b8bccc2df2/diff:/var/lib/docker/overlay2/9a33ff56da28fb1d8a98c335f47b851aac7f1f420453d8478a20be399808cd68/diff:/var/lib/docker/overlay2/ad6d02bf100801fbc4256fabf9bc42be08657b3f87adacd29c68c5848f2bc9bf/diff:/var/lib/docker/overlay2/04a72354d3692372adefdf92dcdb1fe05451ceee673df6e7d0db77371b964579/diff:/var/lib/docker/overlay2/e9df87375d3ce369a17815ce9efd584b185568f02f7da5328f552df3947006f6/diff",
"MergedDir": "/var/lib/docker/overlay2/e08491720ae547ec6cc04a79a9c7cca17277e793d8e9276c89785a78be029b40/merged",
"UpperDir": "/var/lib/docker/overlay2/e08491720ae547ec6cc04a79a9c7cca17277e793d8e9276c89785a78be029b40/diff",
"WorkDir": "/var/lib/docker/overlay2/e08491720ae547ec6cc04a79a9c7cca17277e793d8e9276c89785a78be029b40/work"
GraphDriver 负责 镜像本地的管理和存储以及运行中的容器生成镜像等工作,可以将 GraphDriver 理解成镜像管理引擎,我们这里的例子对应的引擎名字是 overlay2 ( overlay 的优化版本)。除了 overlay 之外, Docker 的GraphDriver 还支持 btrfs 、 aufs 、 devicemapper 、 vfs 等。
我们可以看到其中的 Data 包含了多个部分,这个对应 OverlayFS 的镜像组织形式,在下面我们再进行详细介绍。虽然我们上面的例子中的 busybox 镜像只有一层,但是 正常情况下很多镜像都是由多层组成的。
这个时候很多同学应该会有这么一个疑问,镜像中的层都是只读的,那么我们运行着的容器的运行时数据是存储在哪里的呢?
镜像和容器在存储上的主要差别就在于容器多了一个读写层。镜像由多个只读层组成,通过镜像启动的容器在镜像之上加了一个读写层。下图是官方的一个配图。我们知道可以通过 docker commit 命令基于运行时的容器生成新的镜像,那么 commit 做的其中一个工作就是将读写层数据写入到新的镜像中。下图是一个示例图

所有写入或者修改运行时容器的数据都会存储在读写层,当容器停止运行的时候,读写层的数据也会被同时删除掉。因为镜像层的数据是只读的,所以如果我们运行同一个镜像的多个容器副本,那么多个容器则可以共享同一份镜像存储层,下图是一个示例。
UnionFS
Docker 的存储驱动的实现是基于 Union File System ,简称 UnionFS ,中文可以叫做联合文件系统。
UnionFS 设计将其他文件系统联合到一个联合挂载点的文件系统服务。所谓联合挂载技术,是指 在同一个挂载点同时挂载多个文件系统,将挂载点的源目录与被挂载内容进行整合,
使得最终可见的文件系统将会包含整合之后的各层的文件和目录。
举个例子:比如我们运行一个 ubuntu 的容器。由于初始挂载时读写层为空,所以从用户的角度来看: 该容器的文件系统与底层的 rootfs 没有区别;然而从内核角度来看, 则是显式区分的两个层
当需要修改镜像中的文件时,只对处于最上方的读写层进行改动,不会覆盖只读层文件系统的内容,只读层的原始文件内容依然存在,但是 在容器内部会被读写层中的新版本文件内容隐藏。当 docker commit 时,读写层的内容则会被保存.
写时复制( Copy On Write )
我们知道 Linux 系统内核启动时首先挂载的 rootfs 是只读的,在系统正式工作之后,再将其切换为读写模式。Docker 容器启动时文件挂载类似 Linux 内核启动的方式,将 rootfs 设置为只读模式。不同之处在于: 在挂载完成之后,利用上面提到的联合挂载技术在已有的只读 rootfs 上再挂载一个读写层。
读写层位于 Docker 容器文件系统的最上层,其下可能联合挂载多个只读层,只有在 Docker 容器运行过程中文件系统发生变化时,才会把变化的文件内容写到可读写层,并隐藏只读层的老版本文件,这就叫做 写实复制,简称CoW
AUFS
AUFS 是 UnionFS 的一种实现,全称为 Advanced Multi-Layered Unification Filesystem ,是早期 Docker 版本默认的存储驱动,最新的 Docker 版本默认使用 OverlayFS 。
AUFS 将镜像层(只读)组织成多个目录,在 AUFS 的术语中成为 branch 。运行时容器文件会作为一层容器层( container lay ,读写)覆盖在镜像层之上。最后通过联合挂载技术进行呈现。下图是 AUFS 的文章组织架构的示意图。由于 AUFS 可以算是一种过时的技术,所以这里我们就不在赘述了。
Docker 的本质是进程
如果用精简的一句话来描述容器,应该如何来表达.容器就是进程.够简单,但是不够准确.
容器是使用 namespace 进行隔离, cgroup 进行资源限制的进程。
容器是使用 namespace 进行隔离, cgroup 进行资源限制,并且带有 rootfs 的进程
进程是程序的运行实例
我们最常见的可执行文件就是程序,不同操作系统平台.上面对应的可执行文件的组织结构不尽相同,比如 Linux 平台上的可执行文件就包含代码段、数据段等。概括来说,程序是一段操作系统可以识别的指令的集合,其中可能还包含部分数据。
- 容器
理解容器的本质最简单的方式就是类比。 进程是程序的运行实体; 容器是镜像的运行实体
像和程序的角色是一样的,只不过镜像要比程序更加的丰富。 程序只是按简单的格式存储在文件系统中,而镜像是按层,以联合文件系统的方式存储.
容器和进程的角色也是类似的,只不过容器相比于普通进程多了更多地附加属性。
很多人学习 Docker 过程中,长时间纠结于各种细枝末节而无法自拔。而一旦抓住
容器是一种特殊的进程 这一本质,
一切都将变得明朗起来
HAProxy :开源代理软件,用来提供高可用和负载均衡;
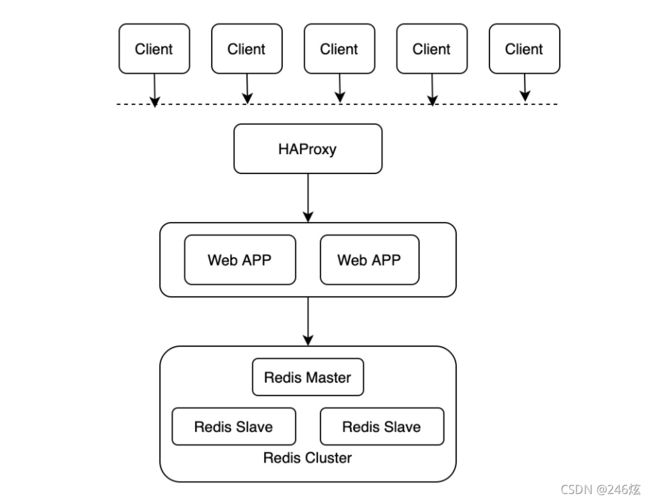
HAProxy 概览.HAProxy 是一个使用 C 语言编写的开源软件,作者是 Willy Tarreau ,其提供高可用性、负载均衡等特性,以及基于 TCP( 四层 ) 和 HTTP( 七层 ) 的应用程序代理。功能包括提供基于 cookie 的持久性、基于内容的交互、过载保护的高级流量管理、自动故障切换等。官网: http://www.haproxy.org 。
HAProxy 实现了基于事件驱动的单进程模型,这是其高性能的根本原因。相比于多进程或者多线程模型在并发上的限制,比如内存资源限制、系统调度器限制、锁竞争等, HAProxy 的单进程模型具有天然的优势。同时结合事件驱动模型,可以在用户空间更高效的处理网络请求。
HAProxy 特别适用于那些负载特大的 web 站点,比如 github 、 stackoverflow 等网站就是使用了 HAProxy 。这些站点通常又需要会话保持或七层处理。 HAProxy 运行在当前的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中, 同时可以保护你的 web 服务器不被暴露到网络上.
数据存储: Docker 数据存储的三种模式
如果我们想要在 Docker 容器停止之后创建的文件依旧存在,也就是将文件在宿主机上保存。那么我们有两种方式: volumes 、 bind mounts 。如果 Docker 是运行在 Linux 系统上,那么我们还可以使用 tmpfs ;对应在Windows 系统上,可以使用 named pipe 。我们这里主要讨论 volumes 、 bind mounts 和 tmpfs

Volumes 会把文件存储到宿主机的指定位置,在 Linux 系统上这个位置为 /var/lib/docker/volumes/ 。这些文件只能
由 Docker 进程进行修改,是 docker 文件持久化的最好的方式。
bind mounts 可以将文件存储到宿主机上面任意位置,而且别的应用程序也可以修改。
tmpfs 只会将数据存储到宿主机的内存中,并不会落盘.
Docker 最佳实践:如何构建最小的镜像
镜像作为 Docker 技术中关键的一环,我们日常开发中的一个关键工作就是将我们的应用构建成镜像,然后使用
容器集群管理框架,比如 Kubernetes
,将镜像部署集群中的多台容器中。这个过程中就涉及到镜像的分发问题,如果镜像比较大的话,会导致我们的应用启动时间比较长。虽然有一些镜像分发技术来解决镜像发布的效率问题,但是我们还是希望将镜像构建的越来越小.
Docker 最佳实践: tag 如何使用
- 镜像 tag 的使用
慎用 latest 标签
准确来说除了 demo 或者测试使用,正式环境应该禁止使用 latest 标签。因为 latest 标签表示的是镜像的最新版本,也就是说是一直变化的。这是慎用 latest 标签的根本原因。
举个例子,线上应用依赖的一个基础镜像,比如 ubuntu ,使用了 latest 的标签,那么随着基础镜像的不断发布( ubuntu 系统官方是 6 个月发布一个系统,一般都是类似 19.04 、 19.10 ,表示 19 年 4 月和 10 月的版本),我们的线上应用在不同时间 build 的时候就可能依赖的是不同的环境,很有可能引入问题。
tag 尽量指定到具体的版本
什么叫具体的版本,比如很多系统的版本都是通过三个数字来表示的,比如 x.y.z 。其中 x 是主版本号,一般当软件整体重写时,或出现不向后兼容的改变等重大更新时,增加 X ,同时重置 Y 、 Z 为 0 , X 为 0 时表示软件还在开发阶段; y 是次版本号,一般我们说的系统 release 都是保持 x 不变,增加 y ,同时重置 z 为 0 ; z 是修订号,一般主要用于 bugfix 。我们这里说的指定到具体的版本就是指定到 z ,很多系统的镜像 tag 可能同时存在 x , x.y , x.y.z 这三种形式的tag ,我们使用的时候在情况允许的情况下尽量指定到 x.y.z 版本号.
- 应用程序数据持久化.
尽量不要将应用程序的数据存储在镜像中。因为这样会增加镜像的大小,并且从 IO 的角度看也显得不够高效。
怎么理解呢?比如我们应用程序依赖一些数据,我们可以把数据打到镜像里面,这种是最省事的,但是这种方式就会带来前面说的问题.
一种推荐的方式是使用 Docker 的数据卷或者目录挂载的方式。其中目录挂载的方式是将容器内的某个目录和宿主机做映射,这种方式一般推荐在应用开发的时候使用,并不建议线上使用.
比如我们要快速调试我们的应用程序,那么我们可以将可执行文件存储在宿主机中,通过目录挂载的方式映射到容器中,这样每次本地开发出一个新的版本就可以快速在容器中进行测试.
另外我们根据应用程序数据的不同,我们可以再细化我们的技术方案。像数据库连接密码这种比较敏感的数据可以存储在 secret 中,而不敏感的数据,比如配置文件,可以使用 config .
关于 Docker 的 secret 和 config 这里就不再展开叙述了。实际上现在很少有线上单独使用 Docker 的场景了,更多是结合 Kubernetes 来部署和管理我们的容器化应用, secret 和 config 对应到 Kubernetes 中就是 Secret 和ConfigMap .
通过 CI/CD 的方式进行开发和测试
当我们使用 Docker 技术来开发和部署我们的应用的时候,我们不仅要测试程序本身的正确性,还要测试应用在Docker 容器化之后的正确性。而应用容器化的过程毫无疑问将整个开发测试链路拉长了,我们一般可以像下面这么几步来做:
- 本地 build 应用或者拷贝代码到容器中进行 build 生成可执行文件;
- 使用 docker build 编译生成我们的镜像;
- 通过 docker push 将镜像 push 到私有或者公有的镜像中心;
- 测试环境拉取新的镜像进行测试
我这里简化了操作流程和步骤,还是有 4 个步骤,在实际操作的时候很容易问题。所以更建议以一种自动化的CI/CD 的方式来进行部署和测试,比如 Jenkins 。Jenkins 是一个广泛用于持续构建的工具,展开来说,就是各种项目的 " 自动化 " 编译、打包、分发部署等。 Jenkins可以很好的支持各种语言(比如: java, c#, php 等)的项目构建,也完全兼容 ant 、 maven 、 gradle 等多种第三方构建工具,同时跟 svn 、 git 能无缝集成,也支持直接与知名源代码托管网站,比如 github 、 bitbucket 直接集成.
安全性
base 镜像最小原则
Docker 安全问题一个常见的原因就是使用的 base 镜像有安全问题。就像程序员开发中的那句话,代码写的越多, bug 越多一样, base 镜像越大则越容易暴露安全问题。针对这个问题,我们可以考虑在 base 镜像中只安装必要的依赖。
最小用户权限原则
如果 Dockerfile 中没有指定 USER ,则默认是以 root 用户运行,但是很多情况下我们的 Docker 应用并不是真正需要 root 权限。 Docker 以 root 权限启动,映射到宿主机上也具有 root 权限,而 root 权限很容易带来更多的安全问题.
为了解决这个问题,一个比较好的解决方案是在 Dockerfile 中指定特定的用户,先添加用户,然后再使用 USER 指令显示指定,下面是一个例子:
- 创建一个没有密码、没有 home 目录、没有 shell 的系统用户;
- 将该系统用户加到一个已经存在的用户组里面;
- 通过 USER 指令显示设置我们的 Docker 应用的启动用户。
FROM ubuntu
RUN mkdir /app
RUN groupadd -r lirantal && useradd -r -s /bin/false -g lirantal lirantal
WORKDIR /app
COPY . /app
RUN chown -R lirantal:lirantal /app
USER lirantal
CMD node index.js
有些 Base 镜像考虑到了这个用户的问题,已经帮我们把这件事情做了,比如 node 镜像就帮我们提前创建了一个叫 node 的用户。
FROM node:10-alpine
RUN mkdir /app
COPY . /app
RUN chown -R node:node /app
USER node
CMD [“node”, “index.js”]
不要在 Docker 镜像中泄露敏感信息
我们有时间将应用打包成 Docker 镜像时,会需要一些 secret ,比如 SSH private key 用来从私有的代码托管仓库上拉取代码、或者其他需要进行认证的情况。有些同学会直接将这些 secret 拷贝到镜像中,这是一个非常错误的做法。
使用 Docker secret 命令
secret 是 Docker 中的比较新的功能,专门用来处理敏感数据。但是使用起来也是比较简单的,下面是一个例子:
# syntax = docker/dockerfile:1.0-experimental
FROM alpine
# shows secret from default secret location
RUN --mount=type=secret,id=mysecret cat /run/secrets/mysecre
# shows secret from custom secret location
RUN --mount=type=secret,id=mysecret,dst=/foobar cat /foobar
- 使用 linter
linter 是一种代码规范检测工具,比如写过 Go 语言的应该都只有有一个小工具叫 golint 。同样的,对于 Dockerfile的编写我们也可以使用 linter 。这里要推荐的是 hadolint ,下面是 hadolint 的简介。
容器是一种特殊的进程 !!!
为什么说容器是个单进程模型???
过去两年很多大公司的一个主要技术方向就是将应用上云,在这个过程中的一个典型错误用法就是将容器当成虚拟机来使用,将一堆进程启动在一个容器内。但是容器和虚拟机对进程的管理能力是有着巨大差异的。不管在容器中还是虚拟机中都有一个一号进程,虚拟机中是 systemd 进程,容器中是 entrypoint 启动进程,然后所有的其他线程都是一号进程的子进程,或者子进程的子进程,递归下去。这里的主要差异就体现在 systemd 进程对僵尸进程回收的能力。
僵尸进程
说到僵尸进程,这里简单介绍一下 Linux 系统中的进程状态,我们可以通过 ps 或者 top 等命令查看系统中的进程,比如通过 ps aux 在我的 ecs 虚拟机上面得到如下的输出
子进程的创建一般需要父进程通过系统调用 wait() 或者
waitpid() 来等待子进程结束,从而回收子进程的资源。除了这种方式外,还可以通过异步的方式来进行回收,这种方式的基础是子进程结束之后会向父进程发送 SIGCHLD 信号,基于此父进程注册一个 SIGCHLD 信号的处理函数来进行子进程的资源回收就可以了。
僵尸进程的最大危害是对资源的一种永久性占用,比如进程号,系统会有一个最大的进程数 n 的限制,也就意味一旦 1 到 n 进程号都被占用,系统将不能创建任何进程和线程(进程和线程对于 OS 而言,使用同一种数据结构来表示, task_struct )。这个时候对于用户的一个直观感受就是 shell 无法执行任何命令,这个原因是 shell 执行命令的本质是 fork。
孤儿进程
前面说到如果子进程先于父进程退出,并且父进程没有对子进程残留的资源进行回收的话将会产生僵尸进程。这里引申另外一种情况,父进程先于子进程退出的话,那么子进程的资源谁来回收呢?
父进程先于子进程退出,这个时候我们一般将还在运行的子进程称为孤儿进程,但是实际上孤儿进程并没有一个明确的定义,他的状态还是处于上面讨论的几种进程状态中。那么孤儿进程的资源谁来回收呢?类 Unix 系统针对这种情况会将这些孤儿进程的父进程置为 1 号进程也就是 systemd 进程,然后由 systemd 来对孤儿进程的资源进行回收。
虚拟机或者一个完整的 OS 是如何避免僵尸进程的。但是,在容器中, 1 号进程一般
是 entry point 进程,针对上面这种 将孤儿进程的父进程置为 1 号进程进而避免僵尸进程 处理方式,容器是处理不了的。进而就会导致容器中在孤儿进程这种异常场景下僵尸进程无法彻底处理的窘境。
所以说,容器的单进程模型的本质其实是容器中的 1 号进程并不具有管理多进程、多线程等复杂场景下的能力。如果一定在容器中处理这些复杂情况的,那么需要开发者对 entry point 进程赋予这种能力。这无疑是加重了开发者的心智负担,这是任何一项大众技术或者平台框架都不愿看到的尴尬之地。
盗链
我们首先有必要介绍一下什么是 盗链 。
有一些资源是一些网站独有的,有人通过技术手段在其它网站上访问或者下载,这就是 盗链 。比如图片,百度或者腾讯上面有狠毒图片,但是有些图片我们只能在百度或者腾讯的服务上面才能访问,我们单独把网址拿出来放到自己的服务器上面就无法访问了,这就是因为他们做了防盗链的机制。
防盗链
防盗链的方法有很多,我们这里介绍最常用的一种。
这种方式是和 HTTP 协议相关的, HTTP 协议的请求头部有一个字段叫做 Referer ,这个字段表示了当前我们访问的页面的前一个页面是从哪里来的。
讲到这里大家是不是就有一种茅塞顿开的感觉?是的,我们可以根据这个字段来进行防盗链
location ~* \.(jpeg|png|gif|jpg)$ {
valid_referers none www.test.com;
if ($invalid_referer){
return 200 "don't steal my pic";
}
}
这里可以看到当 Referer 为其他值的时候,图片不能正常的访问。
不过 HTTP Referer 可以通过程序来伪装生成的,所以通过 Referer 信息防盗链并非 100% 可靠,但是,它能够限制大部分的盗链