K8S学习之深入剖析Docker容器镜像
K8S学习之深入剖析Docker容器镜像
- 容器技术
- Docker
-
- Namespace
- Cgroups
- Mount Namespace
- rootfs
- 总结
- 参考链接
容器技术
-
基本概念
Docker 实际上是在创建容器进程时,指定了这个进程所需要启用的一组 Namespace 参数。这样,容器就只能“看”到当前 Namespace 所限定的资源、文件、设备、状态,或者配置。而对于宿主机以及其他不相关的程序,它就完全看不到了。
容器,其实就是操作系统在启动进程时通过设置一些参数实现了隔离不相关资源后的一个特殊进程。
-
核心功能
通过约束和修改进程的动态表现,从而为其创造出一个“边界”。
-
虚拟机和容器

这幅图的左边,画出了虚拟机的工作原理。其中,名为 Hypervisor 的软件是虚拟机最主要的部分。它通过硬件虚拟化功能,模拟出了运行一个操作系统需要的各种硬件,比如 CPU、内存、I/O 设备等等。然后,它在这些虚拟的硬件上安装了一个新的操作系统,即 Guest OS。
这样,用户的应用进程就可以运行在这个虚拟的机器中,它能看到的自然也只有 Guest OS 的文件和目录,以及这个机器里的虚拟设备。这就是为什么虚拟机也能起到将不同的应用进程相互隔离的作用。
而这幅图的右边,则用一个名为 Docker Engine 的软件替换了 Hypervisor。这也是为什么,很多人会把 Docker 项目称为“轻量级”虚拟化技术的原因,实际上就是把虚拟机的概念套在了容器上。
在这个对比图里,我们应该把 Docker 画在跟应用同级别并且靠边的位置。
-
基本特点
首先,既然容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核。
其次,在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,最典型的例子就是:时间。
-
优劣分析
“敏捷”和“高性能”是容器相较于虚拟机最大的优势,也是它能够在 PaaS 这种更细粒度的资源管理平台上大行其道的重要原因。
基于 Linux Namespace 的隔离机制相比于虚拟化技术也有很多不足之处,其中最主要的问题就是:隔离得不彻底。
基于虚拟化或者独立内核技术的容器实现,则可以比较好地在隔离与性能之间做出平衡。
Docker
-
基本介绍
对于 Docker 等大多数 Linux 容器来说,Cgroups 技术是用来制造约束的主要手段(资源限制),而 Namespace 技术则是用来修改进程视图的主要方法(隔离资源)。
-
核心原理
对 Docker 项目来说,它最核心的原理实际上就是为待创建的用户进程:
-
启用 Linux Namespace 配置;
-
设置指定的 Cgroups 参数;
-
切换进程的根目录(Change Root)。
这样,一个完整的容器就诞生了。不过,Docker 项目在最后一步的切换上会优先使用 pivot_root 系统调用,如果系统不支持,才会使用 chroot。这两个系统调用虽然功能类似,但是也有细微的区别,这里就不进行详细探讨。
-
Namespace
-
作用
Namespace 技术实际上修改了应用进程看待整个计算机“视图”,即它的“视线”被操作系统做了限制,只能“看到”某些指定的内容。但对于宿主机来说,这些被“隔离”了的进程跟其他进程并没有太大区别。
Cgroups
-
主要作用
Linux Cgroups 的全称是 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
Linux Cgroups 就是 Linux 内核中用来为进程设置资源限制的一个重要功能。
-
结构组成
Cgroups 的每一个子系统都有其独有的资源限制能力,比如:
blkio,为块设备设定I/O 限制,一般用于磁盘等设备;
cpuset,为进程分配单独的 CPU 核和对应的内存节点;
memory,为进程设定内存使用的限制。 -
设计理念
Linux Cgroups 的设计还是比较易用的,简单粗暴地理解呢,它就是一个子系统目录加上一组资源限制文件的组合。
而对于 Docker 等 Linux 容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程的 PID 填写到对应控制组的 tasks 文件中就可以了。
echo PID > /sys/fs/cgroup/cpu/container/tasks -
命令分析
控制组下面的资源文件里填上什么值,就靠用户执行 docker run 时的参数指定
# 启动容器设置资源限制参数 $ docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash在启动这个容器后,我们可以通过查看 Cgroups 文件系统下,CPU 子系统中,“docker”这个控制组里的资源限制文件的内容来确认:
# 这两个参数需要组合使用,可以用来限制进程在长度为 cfs_period 的一段时间内 $ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_period_us 100000 # 只能被分配到总量为 cfs_quota 的 CPU 时间 $ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_quota_us 20000
Mount Namespace
-
基本内容
Mount Namespace 跟其他 Namespace 的使用略有不同的地方:它对容器进程视图的改变,一定是伴随着挂载操作(mount)才能生效。
Mount Namespace 正是基于对 chroot 的不断改良才被发明出来的,它也是 Linux 操作系统里的第一个 Namespace。
chroot命令
在 Linux 操作系统里,有一个名为 chroot 的命令可以帮助你在容器进程启动之前重新挂载它的整个根目录“/”。顾名思义,它的作用就是帮你“change root file system”,即改变进程的根目录到你指定的位置。
rootfs
-
基本内容
rootfs(根文件系统,也叫容器镜像),是一个挂载在容器根目录上、用来为容器进程提供隔离后执行环境的文件系统,就是所谓的“容器镜像”。
-
组成结构
一个最常见的 rootfs,或者说容器镜像,会包括如下所示的一些目录和文件,比如 /bin,/etc,/proc 等等。
镜像的层都放置在 /var/lib/docker/aufs/diff 目录下,然后被联合挂载在 /var/lib/docker/aufs/mnt 里面,表现为一个完整的 Ubuntu 操作系统供容器使用。
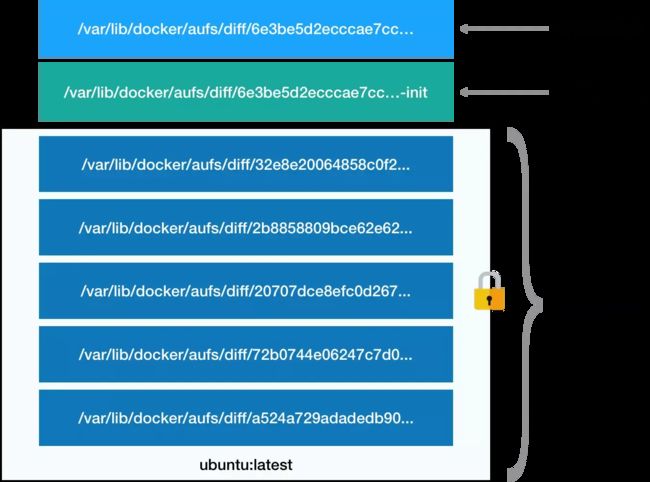
第一部分:只读层
它是这个容器的 rootfs 最下面的五层,对应的正是 ubuntu:latest 镜像的五层。可以看到,它们的挂载方式都是只读的(ro+wh,即 readonly+whiteout)
第二部分:可读写层
它是这个容器的 rootfs 最上面的一层(6e3be5d2ecccae7cc),它的挂载方式为:rw,即 read write。在没有写入文件之前,这个目录是空的。而一旦在容器里做了写操作,你修改产生的内容就会以增量的方式出现在这个层中。
为了实现删除只读层里的一个文件操作,AuFS 会在可读写层创建一个 whiteout 文件,把只读层里的文件“遮挡”起来。例如:你要删除只读层里一个名叫 foo 的文件,那么这个删除操作实际上是在可读写层创建了一个名叫.wh.foo 的文件。这样,当这两个层被联合挂载之后,foo 文件就会被.wh.foo 文件“遮挡”起来,“消失”了。这个功能,就是“ro+wh”的挂载方式,即只读 +whiteout 的含义。我喜欢把 whiteout 形象地翻译为:“白障”。
主要作用:专门用来存放你修改 rootfs 后产生的增量,无论是增、删、改,都发生在这里。
第三部分:Init 层
这是一个以“-init”结尾的层,夹在只读层和读写层之间。Init 层是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。
需要这样一层的原因是,这些文件本来属于只读的 Ubuntu 镜像的一部分,但是用户往往需要在启动容器时写入一些指定的值比如 hostname,所以就需要在可读写层对它们进行修改。可是,这些修改往往只对当前的容器有效,我们并不希望执行 docker commit 时,把这些信息连同可读写层一起提交掉。
-
打包方式
由于 rootfs 里打包的不只是应用,而是整个操作系统的文件和目录,也就意味着,应用以及它运行所需要的所有依赖,都被封装在了一起。
依赖概念
对一个应用来说,操作系统本身才是它运行所需要的最完整的“依赖库”。
这种深入到操作系统级别的运行环境一致性,打通了应用在本地开发和远端执行环境之间难以逾越的鸿沟。
-
制作流程
Docker 公司在实现 Docker 镜像时并没有沿用制作 rootfs 的标准流程,而是做了一个小小的创新:Docker 在镜像的设计中,引入了层(layer)的概念。
也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量 rootfs。
-
注意事项
rootfs 只是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。在 Linux 操作系统中,这两部分是分开存放的,操作系统只有在开机启动时才会加载指定版本的内核镜像。
正是由于 rootfs 的存在,容器才有了一个被反复宣传至今的重要特性:一致性。
总结
-
容器是一个“单进程”模型
一个正在运行的 Docker 容器,其实就是一个启用了多个 Linux Namespace 的应用进程,而这个进程能够使用的资源量,则受 Cgroups 配置的限制。这也是容器技术中一个非常重要的概念,即:容器是一个“单进程”模型。
-
同一容器中无法同时运行两个不同的应用
用户的应用进程实际上就是容器里 PID=1 的进程,也是其他后续创建的所有进程的父进程。这就意味着,在一个容器中,你没办法同时运行两个不同的应用,除非你能事先找到一个公共的 PID=1 的程序来充当两个不同应用的父进程,这也是为什么很多人都会用 systemd 或者 supervisord 这样的软件来代替应用本身作为容器的启动进程。
-
容器和应用同生命周期
容器本身的设计,就是希望容器和应用能够同生命周期,这个概念对后续的容器编排非常重要。否则,一旦出现类似于“容器是正常运行的,但是里面的应用早已经挂了”的情况,编排系统处理起来就非常麻烦。
-
/proc 文件系统不了解 Cgroups 限制的存在
Linux 下的 /proc 目录存储的是记录当前内核运行状态的一系列特殊文件,用户可以通过访问这些文件,查看系统以及当前正在运行的进程的信息,比如 CPU 使用情况、内存占用率等,这些文件也是 top 指令查看系统信息的主要数据来源。
但是,你如果在容器里执行 top 指令,就会发现,它显示的信息居然是宿主机的 CPU 和内存数据,而不是当前容器的数据。
造成这个问题的原因就是,/proc 文件系统并不知道用户通过 Cgroups 给这个容器做了什么样的资源限制,即:/proc 文件系统不了解 Cgroups 限制的存在。
参考链接
- 深入剖析Kubernetes