【项目实战】基于Python实现随机森林分类模型(RandomForestClassifier)项目
说明:这是一个机器学习实战项目(附带数据+代码),如需数据+完整代码可以直接到文章最后获取。
1.项目背景
高质量的产品不仅能很好地满足顾客对产品使用功能的需要,获得良好的使用体验,提升企业形象和商誉,同时能为企业减少售后维修成本,增加利润。燃气灶市场已成为继家电市场之后各大电器公司竞争的新战场。某电器公司的燃气灶产品销售额一直在国内处于领先地位,把产品质量视为重中之重,每年都要对其产品质量数据进行分析研究,以期不断完善,精益求精。
2.获取数据
本次建模数据来源于某电器公司某月燃气灶质量情况统计数据,记录到的燃气灶故障现象均为“打不着火”,其主要的数据基本统计概况如下:
特征变量数:8
数据记录数:1245
是否有NA值:否
是否有异常值:否
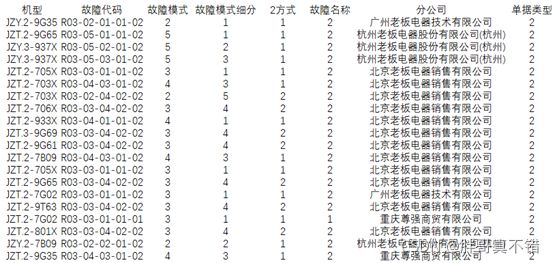
去除异常值和NA值后的数据共计1245条,其特征变量详情如下:
(1)机型:代表所售燃气灶的型号,共计204个型号。
(2)故障代码:代表燃气灶维修部分的记录,分别代表故障模式、故障模式细分、维修方式、故障名称等。
(3)故障模式:表示燃气灶故障的基本情况,分为“微动开关坏”、“热电偶坏”、“电极针坏”、“电磁阀坏”、“脉冲器坏”等5种。
(4)故障模式细分:根据故障基本情况,故障类型又细分为“开裂”、“变形”、“老化”、“调整电极针位置”、“热电偶与电磁阀接触不良”等5种。
(5)维修方式:根据不同燃气灶的具体情况,采用的维修方式分为“更换”和“未更换”2种。
(6)故障名称:根据购买和维修之间的时间跨度,分为“保内”和“保外”两种。
(7)分公司:共有61个分公司负责销售和维修。
(8)单据类型:针对具体情况,每个维修单类型分为“调试”、“维修”、“改气源”、“其它”等4种。
3.数据预处理
真实数据中可能包含了大量的缺失值和噪音数据或人工录入错误导致有异常点存在,非常不利于算法模型的训练。数据清洗的结果是对各种脏数据进行对应方式的处理,得到标准的、干净的、连续的数据,提供给数据统计、数据挖掘等使用。数据预处理通常包含数据清洗、归约、聚合、转换、抽样等方式,数据预处理质量决定了后续数据分析挖掘及建模工作的精度和泛化价值。以下简要介绍数据预处理工作中主要的预处理方法:
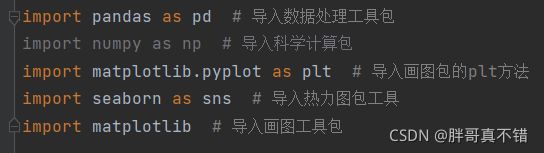
3.1导入程序库并读取数据
(1)导入程序库:将所用到的程序库导入到Python程序中,如图所示。
图程序库导入代码
(2)读取数据:使用Pandas库中read_excel方法读取Excel数据,并转为DataFrame类型。读取数据代码如图所示:
3.2数据校验和处理
通过对原始数据审查和校验,了解数据基本分布、数值类型,处理数据中异常值和缺失值等情况。
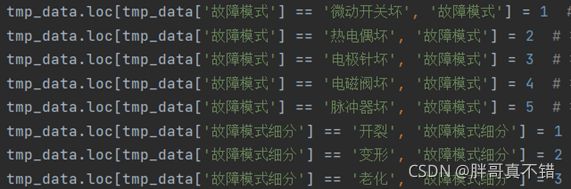
(1)数据替换:原始数据中均以文字记录各项信息,需将文字信息替换成对应的数字代码,方便后期数据挖掘和分析工作。根据故障代码,详细的替换内容如下:
a)故障模式中,将“微动开关坏”、“热电偶坏”、“电极针坏”、“电磁阀坏”、“脉冲器坏”分别替换为“1”、“2”、“3”、“4”、“5”。
b)故障模式细分中,将“开裂”、“变形”、“老化”、“调整电极针位置”、“热电偶与电磁阀接触不良”分别替换为“1”、“2”、“3”、“4”、“5”。
c)维修方式中,将“更换”和“未更换”分别替换为“1”、“2”。
d)故障名称中,将“保内”、“保外”分别替换为“1”、“2”。
e)单据类型中,将“调试”、“维修”、“改气源”、“其它”分别替换为为“1”、“2”、“3”、“4”。
使用Python代码将数据完成替换,图为替换部分代码。
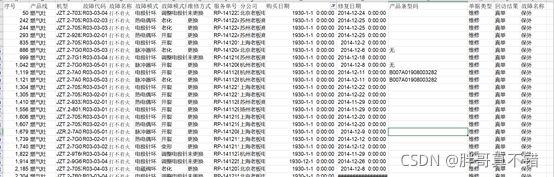
(2)数据缺失和异常处理:原始数据存在购买日期异常,购买日期记录为1930年,但数据特征变量依然不存在缺失值,异常情况如图所示。
图数据异常和缺失情况
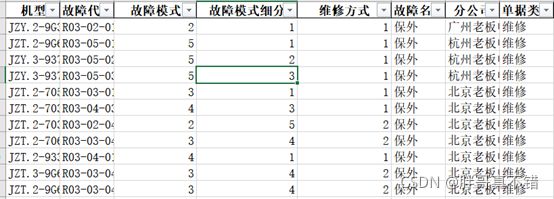
通过数据预处理、离散化之后,得到干净的燃气灶维系记录信息,如图所示。
图 经过预处理后的数据
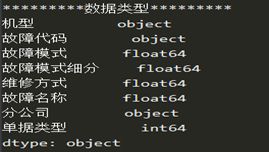
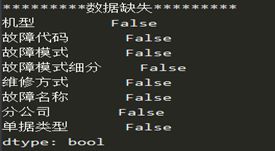
(3)数据概览:本部分通过代码对数据进行审查,检查各部分数据类型和数据缺失情况,其数据类型和缺失情况如图所示,处理后的数据不含缺失值。
4.探索性数据分析
4.1数据分析
(1)机型数量分析:在1245条维修记录中,共有209个燃气灶型号。其中,机型为JZT-7B13、JZT.2-9B13、JZT.2-7G02的燃气灶数量最多,分别有167条、102条和95条记录,分别占比14,1%、8.61%、7.67%。
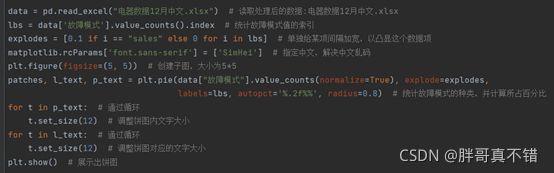
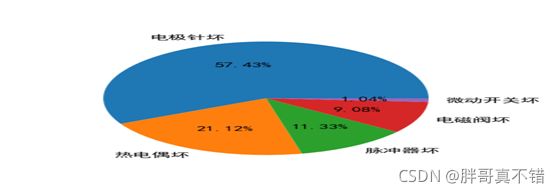
(2)故障分析:在维修记录中不同部件维修数量不同,其中“电极针坏”的数量占比最多,占全部维修记录的57.43%。“热电偶坏”和“电磁阀坏”的占比次之,分别为21.12%和11.33%。图8为绘制统计图的Python代码,图为故障模式各项占比统计图。
图 绘制统计图的Python代码
图 故障模式各项统计图
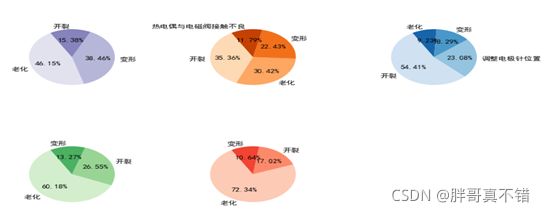
5种故障模式又分别细分为5项:“开裂”、“变形”、“老化”、“调整电极针位置”、“热电偶与电磁阀接触不良”,分别对5项故障模式统计细分故障模式,统计故障模式细分的Python如图所示,统计结果如图所示。
图 故障模式细分统计
图中按顺序分别对应“微动开关坏”、“热电偶坏”、“电极针坏”、“电磁阀坏”、“脉冲器坏”等5种故障模式。故障模式中出现“开裂”、“老化”、“变形”的细分故障最多。
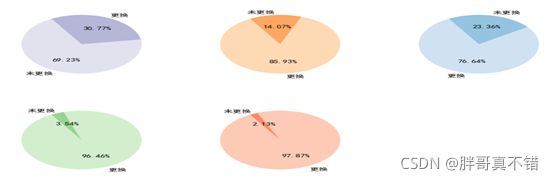
根据燃气灶的5种故障模式,统计各种故障状态的维修方式,统计是否需要更换部件,Python统计维修方式的代码如图所示,其统计结果如图所示。仅当“微动开关坏”时,“未更换”部件的占比高与“更换”部件,其余4种故障模式下,“更换”部件占比均高与“未更换”。
4.2相关性分析
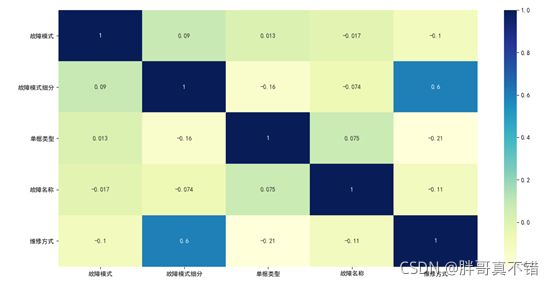
从上面相关性热力图可以看出,故障模式细分与维护方式为0.6,这个属性相关性比较强,其它都在0.3以下,相关性不强。
关键代码:
5.特征工程
根据燃气灶维修记录,通过训练机器学习模型,使之可以根据燃气灶维修记录和是否在保信息,判断所维修的燃气灶是否需要更换故障零件,以期达到动态管理常见故障零部件仓储和调配,减少后续维修工作成本,增加厂商利润。
在机器学习模型建立过程中,需要有足够的数据用与模型训练和测试。用于机器学习的数据集一般需被划分为“训练集”和“验证集”。训练集数据用于模型训练,调整模型的参数;验证集数据用于验证模型性能,评估模型分类的准确度。训练集数据和验证集数据之间互斥。
原始数据经过预处理后,剩余干净数据1245条,有4类主要的特征变量:“故障模式”、“故障模式细分”、“维修方式”和“故障名称”。
5.1哑特征处理
在此数据中,特征变量中故障名称、单据类型的数值为文本类型,不符合机器学习数据要求,需要进行哑特征处理,变为0 1数值。另外,故障模式、故障模式细分的数值为1、2、3、4、5,在建模时会当成数字进行处理,需要进行哑变量处理,转成0 1数值。
处理前:
处理后:
关键代码:
5.2 建立特征数据和标签数据
维修方式 为标签数据,除 维修方式 之外的为特征数据。关键代码如下:
5.3数据集拆分
训练集拆分,分为训练集和验证集,80%训练集和20%验证集。关键代码如下:
6.构建随机森林分类模型
根据数据中“故障模式”、“故障模式细分”、“故障名称”3种变量的特征,预测“维修方式”中是否需要更换零部件。使用RandomForestClassifier算法,用于目标分类。
6.1模型参数
编号
参数
1
n_estimators=100
2
random_state=0
关键代码如下:
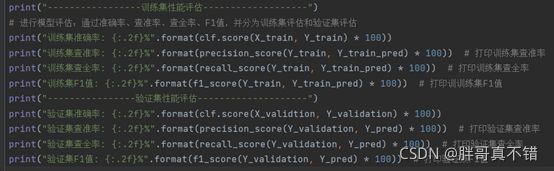
7.模型评估
7.1评估指标及结果
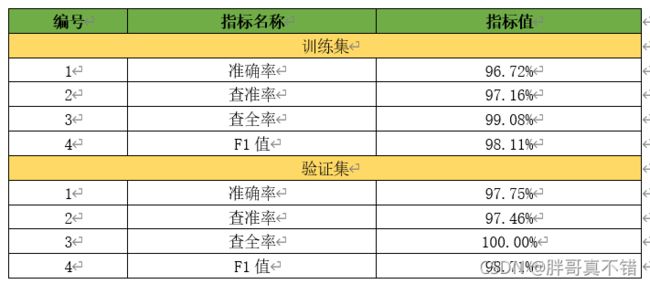
评估指标主要包括准确率、查准率、查全率、F1值等等。
关键代码如下:
8.实际应用
通过训练,RandomForestClassifier模型的性能较强,模型训练和验证结果相近,未出现严重过拟合和欠拟合现象。因此,根据“故障模式”、“故障模式细分”、“故障名称”3种属性的特征值,使用RandomForestClassifier算法模型,预测燃气灶维修方式的方法是可行的,而且模型准确率较高。通过这种方法,为降低电器厂商维修成本,增加企业利润,提高电器公司燃气灶等零部件等产品的物资仓储、运输等工作的运行效率。
预测结果数据如下:









本次机器学习项目实战所需的资料,项目资源如下: 基于Python实现随机森林分类模型(RandomForestClassifier)项目实战-Python文档类资源-CSDN下载