【项目实战】Python实现AdaBoost分类模型(AdaBoostClassifier算法)项目实战
说明:这是一个机器学习实战项目(附带数据+代码+文档+代码讲解),如需数据+代码+文档+代码讲解可以直接到文章最后获取。
1.项目背景
AdaBoost是最优秀的Boosting算法之一, 有着坚实的理论基础, 在实践中得到了很好的推广和应用。算法能够将比随机猜测略好的弱分类器提升为分类精度高的强分类器, 为学习算法的设计提供了新的思想和新的方法。AdaBoost算法的特点是对不同的样本赋予不同的权重。Ada,就是adaptive,翻译过来也就是自适应。AdaBoost是给不同的样本分配不同的权重,被分错的样本的权重在Boosting过程中会增大,新模型会因此更加关注这些被分错的样本,反之,样本的权重会减小。然后,将修改过权重的新数据集输入下层模型进行训练,最后将每次得到的基模型组合起来,也根据其分类错误率对模型赋予权重,集成为最终的模型。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
数据详情如下(部分展示):
3.数据预处理
真实数据中可能包含了大量的缺失值和噪音数据或人工录入错误导致有异常点存在,非常不利于算法模型的训练。数据清洗的结果是对各种脏数据进行对应方式的处理,得到标准的、干净的、连续的数据,提供给数据统计、数据挖掘等使用。数据预处理通常包含数据清洗、归约、聚合、转换、抽样等方式,数据预处理质量决定了后续数据分析挖掘及建模工作的精度和泛化价值。以下简要介绍数据预处理工作中主要的预处理方法:
3.1 用Pandas工具查看数据
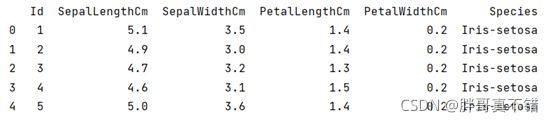
使用Pandas工具的head()方法查看前五行数据:
关键代码:
3.2查看数据集摘要
使用Pandas工具的info()方法查看数据集的摘要信息:
从上图可以看到,总共有150条数据,6个数据项,所有数据中没有缺失值。
关键代码:
3.3数据描述性统计分析
使用Pandas工具的describe()方法查看数据描述性统计分析信息:
通过上图可以看到,Id列无意义不用分析,总数据量150条,每个数据项的平均值、标准差、最大值、最小值以及分位数值。其中SepalLengthCm平均值为5.84、标准差为0.83、最小值为4.30、最大值为7.90。
关键代码:
4.探索性数据分析
4.1绘制特征与标签的小提琴图
用seaborn工具的violinplot()方法进行绘图,图形化展示如下:
从上面图中可以看到,品种与每个特征之间的数据分布,例如:花萼长度特征,可以看到中位数、最大值、最小值等,品种为山鸢尾的中位数在5左右、品种为杂色鸢尾的中位数为5.5左右、品种为维吉尼亚鸢尾的中位数为6.3左右,以及针对每个品种 花萼长度数据的一个分布情况,其它特征的分析一样,就不一个一个分析。
4.2绘制特征与标签的点图
用seaborn工具的pointplot ()方法进行绘图,图形化展示如下:
从上面图中可以看到,品种与每个特征之间的数据分布,例如:花萼长度特征,可以看到平均值,品种为山鸢尾的平均值在5左右、品种为杂色鸢尾的平均值为5.8左右、品种为维吉尼亚鸢尾的平均值为6.5左右,就不一个一个分析。
4.3生成各特征之间关系的矩阵图
用seaborn工具的pairplot ()方法进行绘图,图形化展示如下:
从上图可以看到,花萼长度越小、花瓣宽度越窄 品种越偏向于山鸢尾;其它特征的分析以此类推。
4.4多维数据线性可视化
用seaborn工具的andrews_curves()方法进行绘图,图形化展示如下:
通过上图可以清晰地看到每一个品种的鸢尾花数据的一个趋势,方便看到是否有异常的数据;本次可以看到无异常的数据。
4.5基于花萼和花瓣做线性回归可视化
用seaborn工具的lmplot()方法进行绘图,图形化展示如下:
通过上图可以看到三种品种鸢尾花的花萼宽度与花萼长度的线性数据分布。
通过上图可以看到三种品种鸢尾花的花瓣宽度与花瓣长度的线性数据分布。
4.6相关性分析
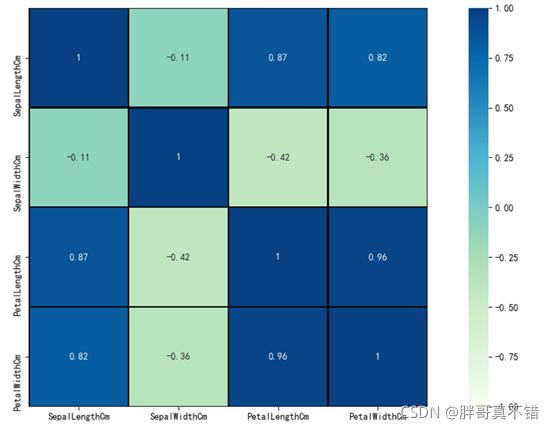
用Pandas工具的corr()方法 matplotlib seaborn进行相关性分析,结果如下:
通过上图可以看到,数据项之间正值是正相关/负值是负相关,数值越大 相关性越强;花萼长度与花萼宽度不相关、花萼长度与花瓣长度、花瓣宽度相关性比较大。
5.特征工程
5.1 建立特征数据和标签数据
Species为标签数据,除Species之外的为特征数据。关键代码如下:
5.2标签数据数字化
通过上图可以看到,品种的数据类型是文本的,不符合建模的需要,所以使用LabelEncoder()方法把类型数据转化为数字,转化后的数据如下图:
关键代码:
5.3数据集拆分
训练集拆分,分为训练集和验证集,70%训练集和30%验证集。关键代码如下:
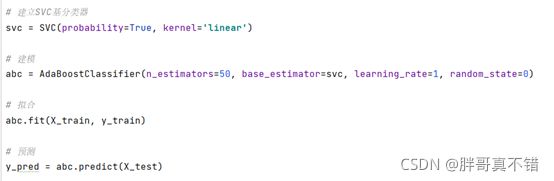
6.构建Adaboost分类模型
主要使用使用AdaBoostClassifier算法,用于目标分类。
6.1建模
关键代码如下:
7.模型评估
7.1评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
从上表可以看出,SVC基分类器准确率为100% F1分值为100%,以SVC为基分类器的Adaboost分类模型效果更好。
关键代码如下:
7.2 查看是否过拟合
查看训练集和测试集的分数:
通过结果可以看到,训练集分数和测试集分数基本相当,所以没有出现过拟合现象。
关键代码:
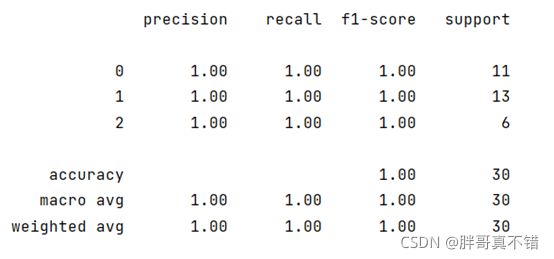
7.3 分类报告
Adaboost分类模型分类报告:
从上图可以看到,分类类型为0的F1分值为1.00;分类类型为1的F1分值为1.00;分类类型为2的F1分值为1.00;整个模型的准确率为100%.
8.结论与展望
综上所述,本文采用了Adaboost分类模型,最终证明了我们提出的模型效果良好。准确率达到了100%,可用于日常生活中进行建模预测,以提高价值。


















本次机器学习项目实战所需的资料,项目资源如下:
项目说明:
链接:https://pan.baidu.com/s/1dW3S1a6KGdUHK90W-lmA4w
提取码:bcbp网盘如果失效,可以添加博主微信:zy10178083