【目标检测】39、一文看懂计算机视觉中的数据增强
文章目录
-
- 一、Cutout
- 二、Random Erasing
- 三、Mixup
- 四、CutMix
- 五、Mosaic
- 五、Copy-paste
- 六、Grid-Mask
- 七、Fence-Mask
计算机视觉任务在深度神经网络的推进下,取得了很好的效果,深度神经网络能够学习复杂的多级特征,从而解决不同的视觉任务。现在的深层网络之所以能够取得很好的效果,一个很重要的原因在于其参数量巨大,能够很好的学习到复杂的特征表达,但这也同样容易导致过拟合,影响模型的对不同场景的泛化能力。
故此,出现了很多不同的正则化方法,如数据增强,通过对输入数据做镜像、扣取、翻转、旋转、随机擦除等操作,用于增强模型的鲁棒性。一些常用的数据增强方法介绍如下。
现有的数据增强的方法一般可以分为如下三个类别,前两类主要是让训练数据更好的适应真实世界的情况,最后一种是人为的丢弃一些特征,目标遮挡、覆盖等难处理的情况:
- Spatial transformation:基础的数据增强方法,如 random scale、crop、flip、random rotation 等
- Color distortion:亮度、通道、hue 等变换
- Information dropping or mix:random erasing、cutout、HaS、cutmix、mixup、copy-paste、grid-mask、fence-mask 等
代码大都可以在这里找到:https://github.com/open-mmlab/mmdetection/blob/master/mmdet/datasets/pipelines/transforms.py
目前几个用的比较多的方法:
- Cutout:随机丢弃图中的一个固定大小的正方形区域,并赋予 0
- Random erasing:随机擦除一个不固定大小和纵横比的矩形区域,并赋予 [0,255] 中的随机值
- Mixup:对两幅图像进行加权求和
- Cut-Mix:将图像 A 的某个小块粘贴到图像 B 的某个位置上去
- Mosaic:将 4 个图像进行翻转、缩放、色彩变换,然后拼接成一个图形,丰富图像的上下文信息,降低对 batch 大小的需求
- Copy-paste:将图像上的实例抠图下来,经过缩放、旋转等操作后粘贴到其他经过缩放、旋转的图像上去
- Grid-mask:对图像上进行有规律的多个正方形区域抠除,等间距、等大小的正方形框抠除
- Fence-mask:在图像上有规律的布上多个平行的横条和纵条,类似于网格的形状抠除
一、Cutout
论文:Improved Regularization of Convolutional Neural Networks with Cutout
1、动机:
- 主要是为了对抗目标检测中的目标遮挡问题
- 使用随机丢弃某些图像块的方法,来模拟物体被遮挡的情况
2、灵感来源:Cutout 的灵感其实是来源于 dropout 方法(随机丢弃某些神经元),但有两点不同,具体示意如图 1 所示:
- 第一点是只在 CNN 输入层丢弃某些单元
- 第二点是丢弃连续的部分,而非丢弃单独的像素点
- Cutout 的早期版本其实是 maxdrop,随机移除响应最大的区域


3、Cutout 具体做法:
- 在输入图像中随机选择一个像素位置,作为中心点,然后放置一个 fixed-size 一个小正方形,在这个区域内设置像素都为 0(为什么固定大小,因为作者发现固定大小的方法效果也能达到很好)
- 每个图像有 50% 的概率被使用 cutout
4、Cutout 的优点:
- 能够让网络更关注图像的全局信息,不过分关注某些位置
- 可以在 CPU 上进行,可以和其他数据增加方法配合使用
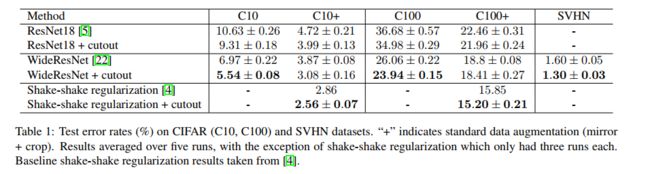
5、Cutout 的效果:
- 实验数据集:CIFAR-10/CIFAR-100
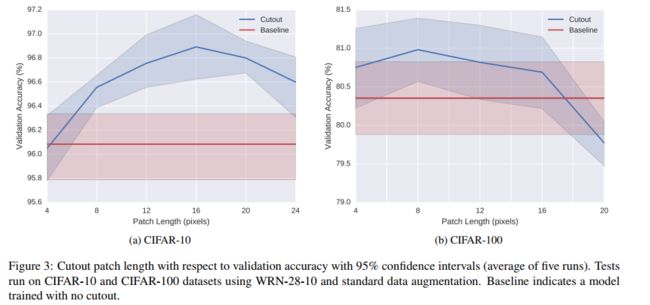
- 小正方形大小的选择:16x16 在 CIFAR-10 效果最优,8x8 在 CIFAR-100 效果最优,如图 3,也可以理解为随着类别的增加,cutout 的尺寸要随之减小,因为类别增加了,细小的纹理等更重要了。
二、Random Erasing
论文:Random Erasing Data Augmentation
代码:https://github.com/zhunzhong07/Random-Erasing
1、动机
目标间的相互遮挡是一个很普遍的现象,所以,为了应对遮挡带来的问题,Random Erasing 被提出,该方法通过随机选择一个随机大小的矩形区域,并给该区域赋予随机数值来实现。以此来模拟目标被遮挡的场景,比 cutout 的相同大小的抠图更灵活多变,且模拟引入了噪声。
2、具体方法
- 首先设定图像被随机擦除的概率 p p p
- 在整幅图像中随机选择一个点 P P P,随机设置随机擦除的面积大小 S e S_e Se 和擦除位置的纵横比 r e r_e re
- 在随机擦除的位置,给每个像素随机赋 [0,255] 之间的值


3、对不同任务使用随机擦除的可视化效果

4、和 Random Croping 的对比

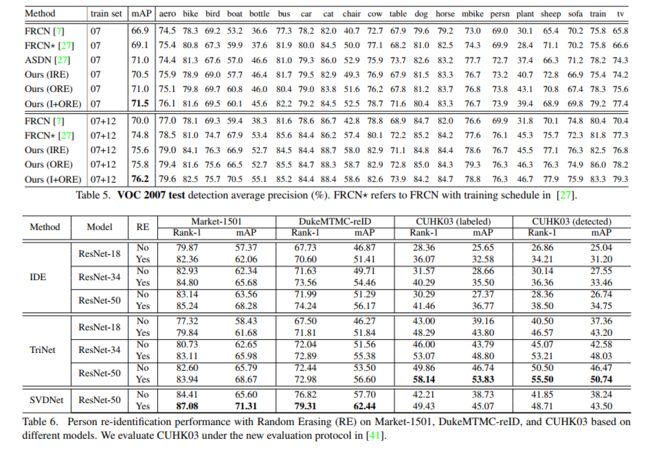
5、效果对比


5、优点:
- 不引入多余的参数,可以嵌入任何 CNN 模型中
- 和已有的数据增强方法是相互补充的,可以结合起来使用
- 在分类、检测、行人 reID 上都能提升效果
- 能够提升模型的鲁棒性
三、Mixup
论文:Mixup: beyond empirical risk minimization
1、动机
现有的数据增强方法,大都是在单个图像内部进行丢弃,没有多个图像之间的融合。
2、方法
对 batch 中的所有图像,两两进行加权加和,进行类间-类内的图像混合,为网络引入了更多不确定因素
在 mini-batch 内部:
- 对输入图像进行加权线性加和,作为输入图像
- 对真是 label 进行加权线性加和,作为预测目标
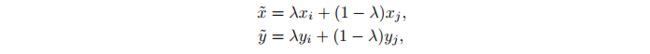
- 其中:KaTeX parse error: Undefined control sequence: \labmda at position 1: \̲l̲a̲b̲m̲d̲a̲ ̲~(\alpha, alpha…

优点:
- 思路简单、实现方便
- 提升了模型的鲁棒性和泛化性
- 模型训练更稳定(如图 2 所示,梯度模值小,训练更稳定)
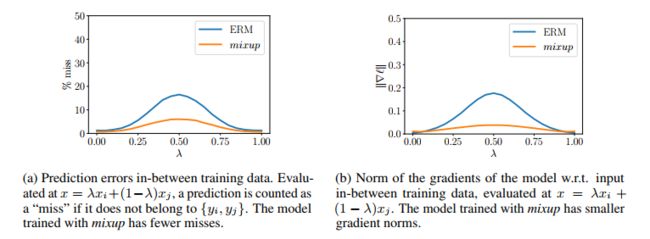
四、CutMix
论文:CutMix: Regularization Strategy to Train Strong Classififiers with Localizable Features
1、动机:
虽然 CNN 会过拟合,但总的来说还是 data-angry 的,也就行需要更丰富的数据,别的方法擦除某些区域但也让网络接收的信息更少了,所以能不能在擦除的同时,用别的特征补上去呢?
2、方法:
CutMix 可以看做 cutout 的优化,也就是擦除图像中的某个随机区域,然后使用同 batch 中的其他图像的区域来填补上去,真值 label 也同样被 mixed。
CutMix 的过程如下面公式所示:
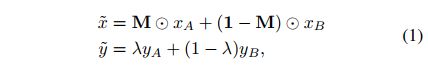
- KaTeX parse error: Undefined control sequence: \timesH at position 15: M\in {0, 1}^{W\̲t̲i̲m̲e̲s̲H̲},也就是非 A 即 B 的过程
- λ \lambda λ 是结合比率,从 Beta ( α , α ) \text{Beta}(\alpha, \alpha) Beta(α,α) 得到,且 α = 1 \alpha=1 α=1,也就服从标准 (0, 1) 分布
CutMix 的过程如下: ( x A , y A ) (x_A, y_A) (xA,yA) 和 ( x B , y B ) (x_B, y_B) (xB,yB) 表示两个训练样本的图像和真值
- 首先,选定 cropping region,用 region box 的坐标来表示 B = ( r x , r y , r w , r h ) B=(r_x, r_y, r_w, r_h) B=(rx,ry,rw,rh),该 box 坐标根据如下方式来采样:

- 接着,根据上面选定的 box 位置,选定矩形 mask M ∈ { 0 , 1 } W × H M\in\{0, 1\}^{W \times H} M∈{0,1}W×H,其纵横比和原图纵横比相同,在 bbox 内部,用 0 填充
- 在训练过程中,会在 batch 里边随机选择两个训练样本进行 CutMix。
CutMix 方法伪代码:

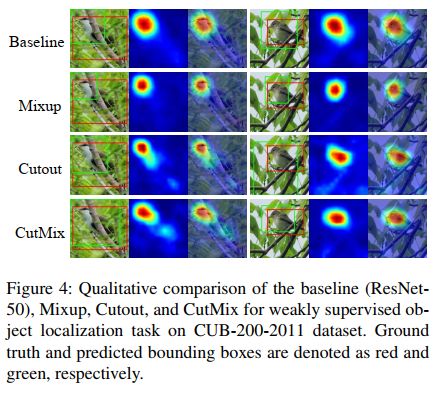
3、CutMix 学到了什么?
CutMix 提出的动机在于图像分类主要依赖于目标的全局特征,
- Cutout:能够让网络关注那些具有区分力的区域,如 Saint Bernard 的腹部,但由于丢弃了一些像素,所以效率较低
- Mixup:虽然使用了所有的 pixel,但引入了一些干扰,从可视化结果可以看出,特征图是比较混乱的,不太明显,且这种目标混合的操作对分类和定位来说都是不太友好的
- CutMix:基于 Cutout,从特征图中可以看出两个目标的定位都是比较清晰的,表 2 展示了三者的不同


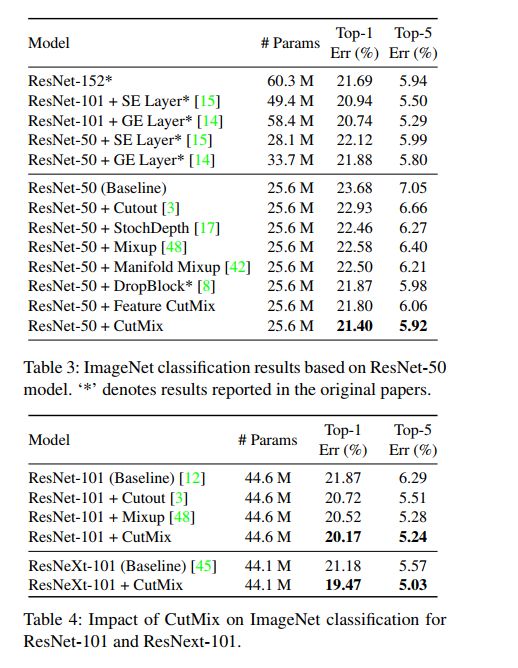
4、效果


五、Mosaic
Mosaic 数据增强是在 YOLOv4 中提出来的,其实也是基于 Cutmix 的一个改进版本,能同时引入 4 个图像的信息。将 4 个训练图像进行混合,引入 4 种不同的上下文信息(CutMix 是混合 2 个图像),让网络能得到更多额外的上下文信息,而且,BN 也在每层接受了来自 4 个图像的信息,能够降低 “大 batch size” 的需求。
操作:
- 选择 4 个图像,随机缩放、翻转、色域变化
- 将随机缩放后的图像进行随机顺序拼接,对过小的进行丢弃
优势:
大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好


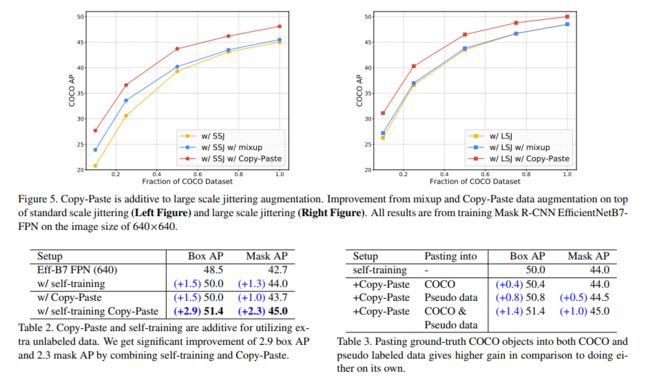
五、Copy-paste
论文:Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation
出处:CVPR20221(Oral)
1、动机
如前所述,神经网络是 data-hungry 的,但人工标注费时费力,且之前的 cutmix、mosaic 等方法,难以适用于实例分割,Copy-paste 能够使用简单的方法,将实例扣下来并粘贴到别的图像上,很方便的解决了实例分割(也可用于有实力分割标签的目标检测)的数据增强问题。

2、方法
- 对所有的图像使用随机尺度抖动好随机水平翻转
- 随机在一些图像上选择一些实例,然后粘贴到其他图像上去,混合的时候会使用高斯滤波将边缘平滑
- 移除完全被遮挡的目标的真实,给那些部分遮挡的目标更新 mask 和 bbox
处理后的图像是什么样子的?说实话和真实场景的图像也很不一样,如图 2 所示,长颈鹿和人出现在一张图里了,而且尺度和平常的有很大不同。

3、效果



六、Grid-Mask
论文:GridMask Data Augmentation
1、动机
Grid-mask 方法和 cutout、HaS 等方法类似,都是通过丢弃一部分图像信息来让网络更加鲁棒。但是作者认为移除的图像大小难以把控,移除过多会导致信息丢弃过多,保存的部分可能不足以支撑后续任务,移除过少会使得网络不够鲁棒,所以移除信息的多少难以把控。
Cutout 和 random erasing 方法,都是随机移除图中的某一个小块,有很大的随机性,如果移除的好则效果好,如果移除的效果不好,则会影响模型效果。
HaS 将图像切分为几个小块,然后随机移除其中的多个小块,但仍可能出现某些地方移除过多,有些地方移除过少的情况。
所以作者提出了均匀移除图像块的方法:Grid-mask

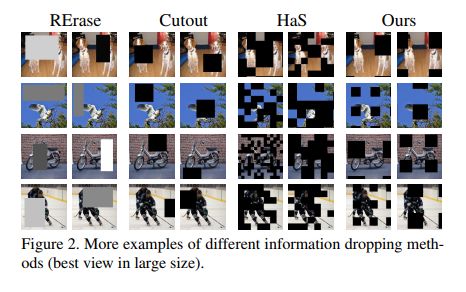
2、方法
- 设定每个图像被进行 grid-mask 的概率 p p p,随着训练的进行概率会增加到最大值 P P P,这样比整个训练过程都使用相同的 p p p 效果好一些
- 假设输入图像为 x x x
- Binary mask 为 M ∈ { 0 , 1 } H × W M \in \{0,1\}^{H \times W} M∈{0,1}H×W,如果为 1,则保留该位置的图像像素,否则移除。 M M M 的形状如图 3 所示,是一个网格状的,使用 4 个参数来表示: ( r , d , δ x , δ y ) (r, d, \delta_x, \delta_y) (r,d,δx,δy),每个 mask 就像图 4 中的一个小块,这四个参数都是随机的,对不同的任务需要实验来确定如何选定
- 经过 grid-mask 后为 x = x × M x=x\times M x=x×M


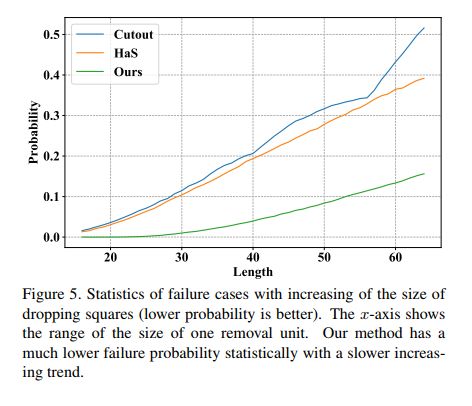
3、效果
① 和其他方法的错误率对比
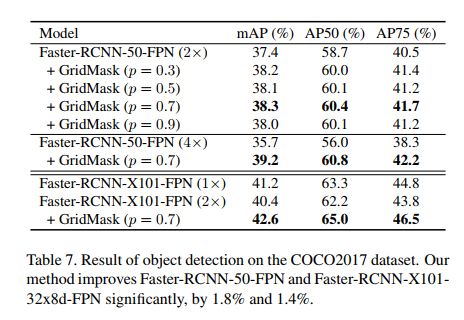
② 对不同模型添加 grid-mask 的效果


③ p 的影响
七、Fence-Mask
1、动机
Information drop 方法中,如何平衡丢弃部分和保留部分是很重要的,尤其是在复杂的真实场景,目标的大小是不确定的,随机的生成丢弃区域可能会导致重要信息丢失,误导模型。
所以作者提出了一个有规律且稀疏的数据增强方法——fence-mask,虽然打破了图像中像素的连续性,但是可以接受的。
图 2 展示了细粒度的图像分类中,不同目标的差别很小,如果把这些主要差别丢失了,则会严重影响结果。


2、方法
Fence-mask 是一个类似篱笆的形状,其 drop 的区域(或者说模拟遮挡的区域,因为有透明度)是稀疏且有规律的,整幅图像被均匀的遮挡,如图 3 所示。


Fence-mask 的参数: ( W m i n , W m a x , G m i n , G m a x , F ) (W_{min}, W_{max}, G_{min}, G_{max}, F) (Wmin,Wmax,Gmin,Gmax,F)
- 横向栅栏的宽度: W x W_x Wx
- 纵向栅栏的宽度: W y W_y Wy
- 横向栅栏间隔: G x G_x Gx
- 纵向栅栏间隔: G y G_y Gy
- 随机旋转角度:0°~30°
- F:fence 填充的 RGB 值,一直为 0
给定各个参数的范围,就可以从范围中随机拿值来组成对应的栅栏:

3、效果
