数据库之记录操作
mysql关于记录的增删改查
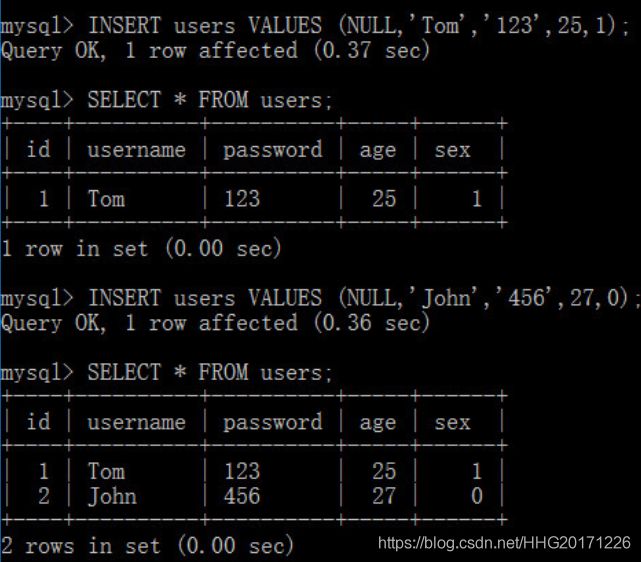
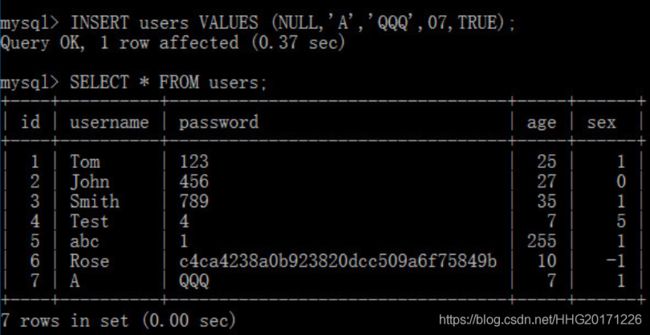
插入记录
INSERT [INTO] tbl_name [(col_name,...)] {VALUES|VALUE} ({expr|DEFAULT},...),(...),...
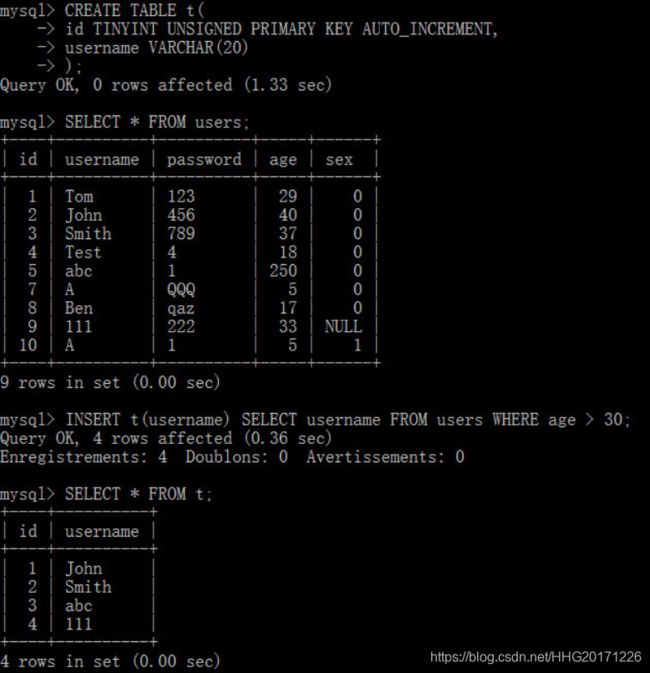
创建一个简单的数据表

如果省略col_name,则意味着所有的字段按照顺序依次赋值。因为id字段是自动编号的,该字段可以赋值为NULL或DEFAULT
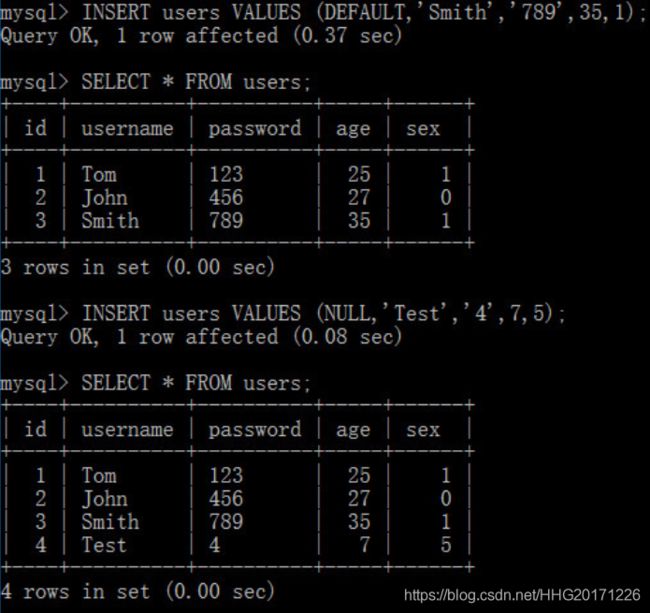
通过逗号分隔,可以一次性写入多条记录;而且,值可以使用表达式表示
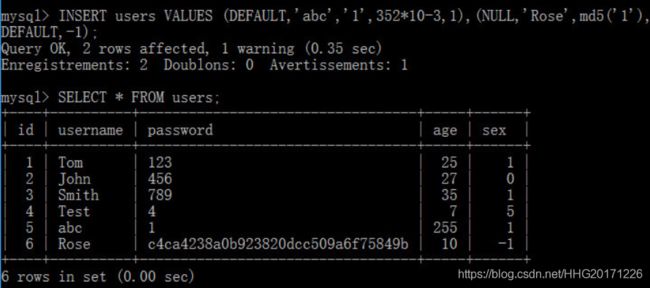
数据库并没有布尔类型BOOLEAN,如果声明类型为BOOLEAN,则会被转换为TINYINT类型,true转换为1,false转换为0
方法二
INSERT [INTO] tb1_name SET col_name={expr|DEFAULT},...
与第一种方法的区别在于,此方法可以使用子查询(SubQuery),以及一次性只能插入一条记录

方法三
INSERT [INTO] tb1_name [(col_name,...)] SELECT ...
此方法可以将查询结果插入到指定数据表
更新记录
UPDATE [LOW_PRIORITY][IGNORE] table_reference SET col_name1={expr1|DEFAULT}[,col_name2={expr2|DEFAULT}]...[WHERE where_condition]
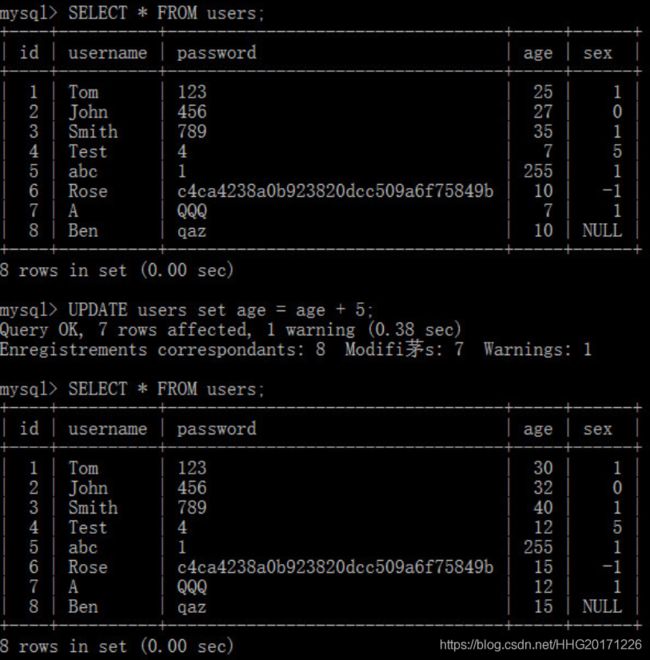
UPDATE语法可以用新值更新原有表行中的各列。
SET子句指示要修改哪些列和要给予哪些值。
WHERE子句指定应更新哪些行。如没有WHERE子句,则更新所有的行。
将所有人的年龄都增加5岁
将所有人的年龄更新为原有年龄减去其id值,将所有人的性别改成0

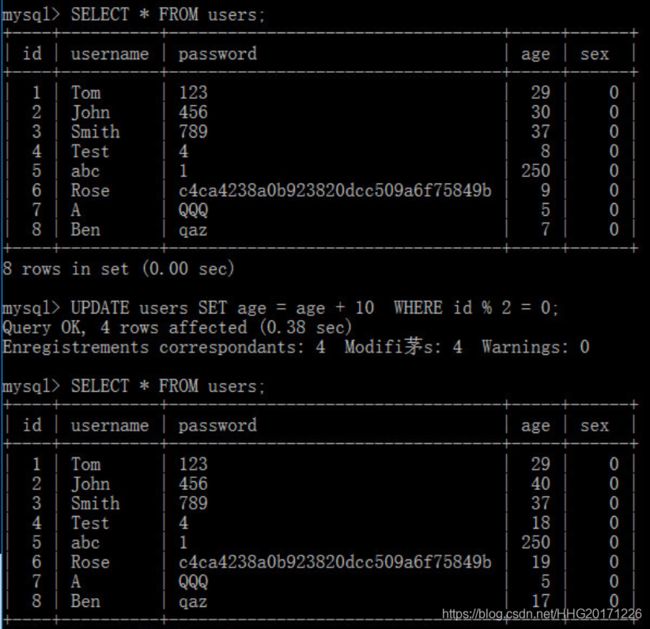
将所有id值为偶数的人的年龄加10岁
删除记录
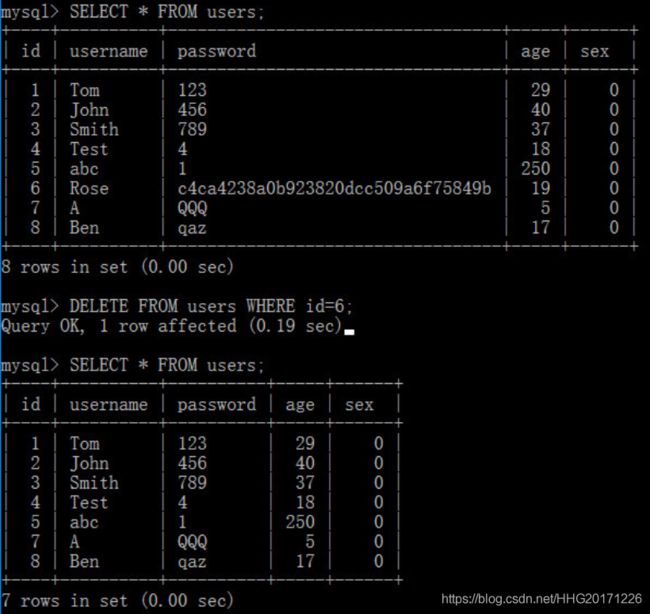
DELETE FROM tbl_name [WHERE where_condition]
如果不跟where语句则删除整张表中的数据
delete只能用来删除一行记录
delete语句只能删除表中的内容,不能删除表本身,想要删除表,用drop
TRUNCATE TABLE也可以删除表中的所有数据,词语句首先摧毁表,再新建表。此种方式删除的数据不能在事务中恢复。
– 删除表中名称为’alex’的记录。
delete from employee_new where name=‘alex’;
– 删除表中所有记录。
delete from employee_new;-- 注意auto_increment没有被重置:alter table employee auto_increment=1;
– 使用truncate删除表中记录。
truncate table emp_new;
[注意]删除某条记录后,再插入一条新的记录,自动编号不会补到删除记录的编号上,而是基于原有记录最大编号继续增加

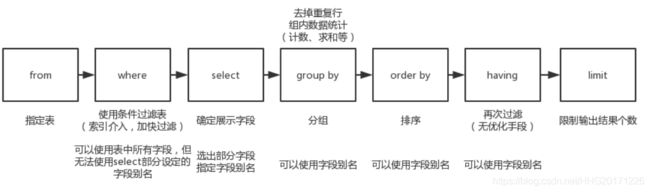
查询表达式
SELECT *|field1,filed2 ... FROM tab_name
WHERE 条件
GROUP BY field
HAVING 筛选
ORDER BY field
LIMIT 限制条数
查询表达式的每个表达式表示想要查找的一列,必须有至少一个。多个列之间以英文逗号分开
– (1)select [distinct] *|field1,field2,… from tab_name
– 其中from指定从哪张表筛选,*表示查找所有列,也可以指定一个列
– 表明确指定要查找的列,distinct用来剔除重复行。
-- 查询表中所有学生的信息。
select * from ExamResult;
-- 查询表中所有学生的姓名和对应的英语成绩。
select name,JS from ExamResult;
-- 过滤表中重复数据。
select distinct JS ,name from ExamResult;
查询表达式的每个表达式表示想要查找的一列,必须有至少一个。多个列之间以英文逗号分开
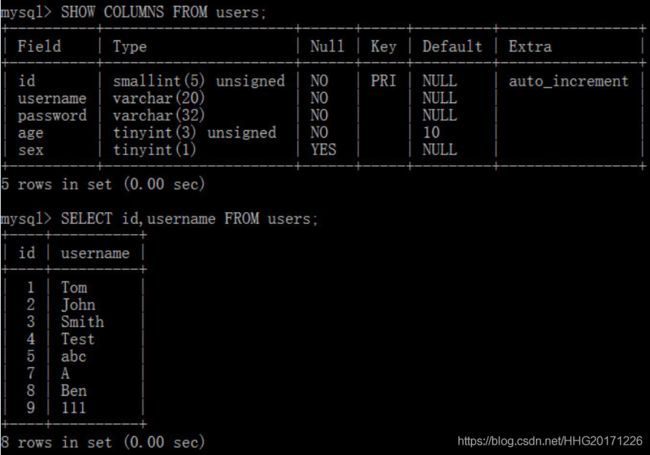
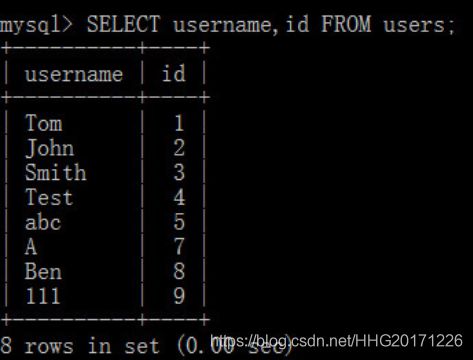
查询表达式的顺序可以和原表中字段的顺序不一致
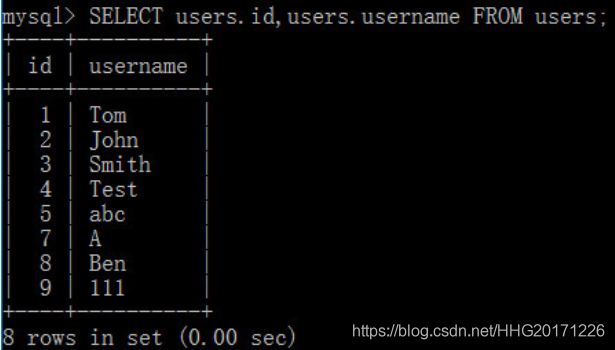
在使用多表连接时,可能会出现不同的表中存在名称相同的字段,如果直接写字段,分不清到底是哪张数据表的字段。在字段名前加上数据表可以分辨出隶属于哪张数据表
星号*号表示所有的列。tbl_name.*可以表示命名表的所有列

查询表达式可以使用[AS] alias_name为其赋予别名,别名可用于GROUP BY, ORDER BY,HAVING字句
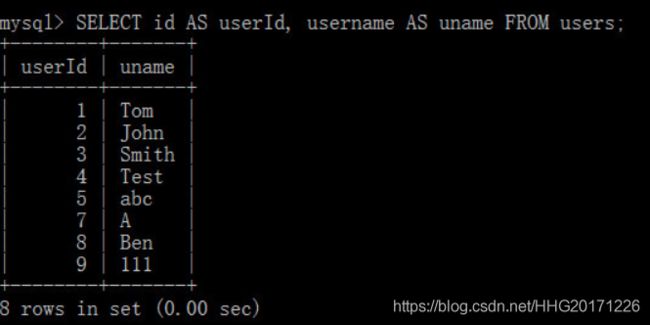
– select 也可以使用表达式,并且可以使用: 字段 as 别名或者:字段 别名
[注意]在使用查询表达式设置别名查询,AS可以使用,也可以不使用。但如果不使用,可能会出现二义性情况
select name,JS+10,Django+10,OpenStack+10 from ExamResult;
-- 统计每个学生的总分。
select name,JS+Django+OpenStack from ExamResult;
-- 使用别名表示学生总分。
select name as 姓名,JS+Django+OpenStack as 总成绩 from ExamResult;
select name,JS+Django+OpenStack 总成绩 from ExamResult;
select name JS from ExamResult; -- what will happen?---->记得加逗号,解析为JS 作为name 的别名
结果处理
[GROUP BY {col_name | position} [ASC | DESC],...]
查询结果分组(GROUP BY)的参数中,ASC是升序,是默认的;DESC是降序
– 注意,按分组条件分组后每一组只会显示第一条记录
-- group by字句,其后可以接多个列名,也可以跟having子句,对group by 的结果进行筛选。
-- 按位置字段筛选
select * from order_menu group by 5;
-- 练习:对购物表按类名分组后显示每一组商品的价格总和
select class,SUM(price)from order_menu group by class;
-- 练习:对购物表按类名分组后显示每一组商品价格总和超过150的商品
select class,SUM(price)from order_menu group by class
HAVING SUM(price)>150;
/*
having 和 where两者都可以对查询结果进行进一步的过滤,差别有:
<1>where语句只能用在分组之前的筛选,having可以用在分组之后的筛选;
<2>使用where语句的地方都可以用having进行替换
<3>having中可以用聚合函数,where中就不行。
*/
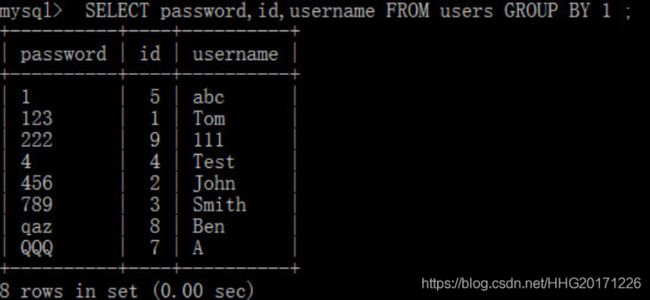
-- GROUP_CONCAT() 函数
SELECT id,GROUP_CONCAT(name),GROUP_CONCAT(JS) from ExamResult GROUP BY id;

col_name代表字段名,position以数字代表位置,如1代表SELECT语句中第一次出现的字段
分组条件
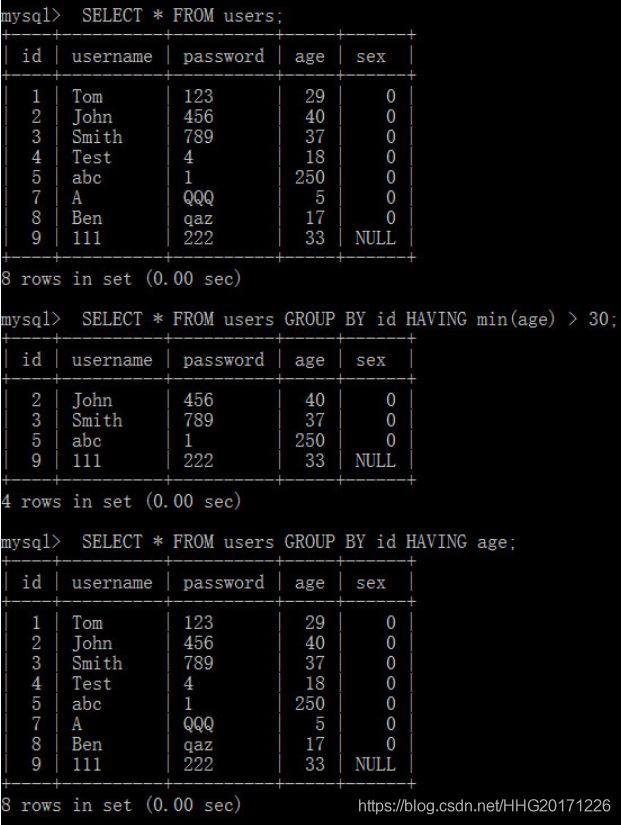
[HAVING where_condition]
在设置分组(HAVING)时,一定要保证分组条件(where_condition)要么是聚合函数(max,min,avg,count,sum),要么其中的字段必须是SELECT中的一个查询字段,否则会报错
– (6)聚合函数: 先不要管聚合函数要干嘛,先把要求的内容查出来再包上聚合函数即可。
– (一般和分组查询配合使用)
--<1> 统计表中所有记录
-- COUNT(列名):统计行的个数
-- 统计一个班级共有多少学生?先查出所有的学生,再用count包上
select count(*) from ExamResult;
-- 统计JS成绩大于70的学生有多少个?
select count(JS) from ExamResult where JS>70;
-- 统计总分大于280的人数有多少?
select count(name) from ExamResult
where (ifnull(JS,0)+ifnull(Django,0)+ifnull(OpenStack,0))>280;
-- 注意:count(*)统计所有行; count(字段)不统计null值.
-- SUM(列名):统计满足条件的行的内容和
-- 统计一个班级JS总成绩?先查出所有的JS成绩,再用sum包上
select JS as JS总成绩 from ExamResult;
select sum(JS) as JS总成绩 from ExamResult;
-- 统计一个班级各科分别的总成绩
select sum(JS) as JS总成绩,
sum(Django) as Django总成绩,
sum(OpenStack) as OpenStack from ExamResult;
-- 统计一个班级各科的成绩总和
select sum(ifnull(JS,0)+ifnull(Django,0)+ifnull(Database,0))
as 总成绩 from ExamResult;
-- 统计一个班级JS成绩平均分
select sum(JS)/count(*) from ExamResult ;
-- 注意:sum仅对数值起作用,否则会报错。
-- AVG(列名):
-- 求一个班级JS平均分?先查出所有的JS分,然后用avg包上。
select avg(ifnull(JS,0)) from ExamResult;
-- 求一个班级总分平均分
select avg((ifnull(JS,0)+ifnull(Django,0)+ifnull(Database,0)))
from ExamResult ;
-- Max、Min
-- 求班级最高分和最低分(数值范围在统计中特别有用)
select Max((ifnull(JS,0)+ifnull(Django,0)+ifnull(OpenStack,0)))
最高分 from ExamResult;
select Min((ifnull(JS,0)+ifnull(Django,0)+ifnull(OpenStack,0)))
最低分 from ExamResult;
-- 求购物表中单价最高的商品名称及价格
---SELECT id, MAX(price) FROM order_menu;--id和最高价商品是一个商品吗?
SELECT MAX(price) FROM order_menu;
-- 注意:null 和所有的数计算都是null,所以需要用ifnull将null转换为0!
-- -----ifnull(JS,0)
-- with rollup的使用
--<2> 统计分组后的组记录
分组排序
[ORDER BY {col_name | expo | position} [ASC | DESC],...]
可以使用分组排序(order by)对查询结果进行排序
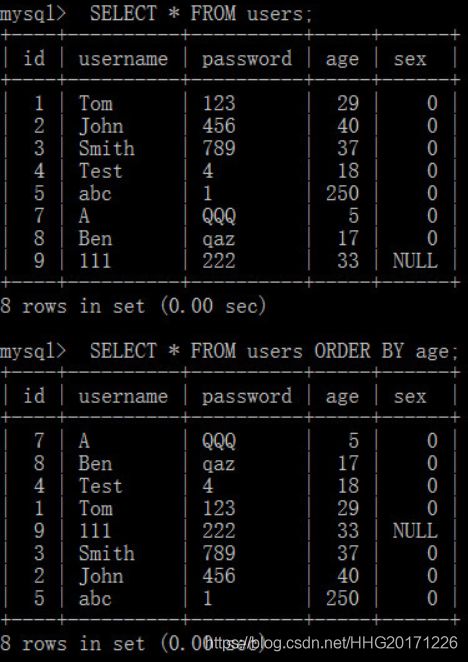
同时可以用几个条件来排序,按输入顺序来进行优先级的选择

– 重点:Select from where group by having order by
-- Mysql在执行sql语句时的执行顺序:
-- from where select group by having order by
-- 分析:
select JS as JS成绩 from ExamResult where JS成绩 >70; ---- 不成功
select JS as JS成绩 from ExamResult having JS成绩 >90; --- 成功
限制结果
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
限制查询结果(LIMIT)默认情况下,返回所有查找到的结果
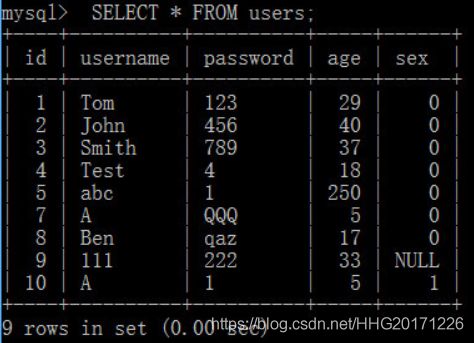
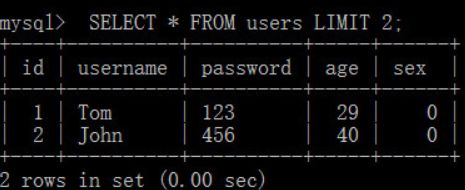
== 如果LIMIT后面只有一个数字,表示从第一条开始返回,并返回相应数字个数的记录==
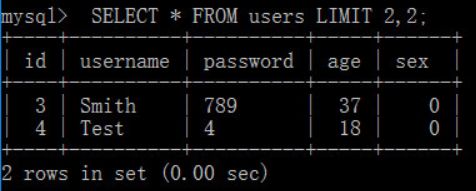
SELECT语句默认从0开始编号如果想从第三条开始返回,则需要offset参数和row_count参数一起使用
— 使用正则表达式查询
SELECT * FROM employee WHERE emp_name REGEXP '^yu';
SELECT * FROM employee WHERE emp_name REGEXP 'yun$';
SELECT * FROM employee WHERE emp_name REGEXP 'm{2}';
【补充】
INSERT [INTO] tbl_name [(col_name,...] SELECT ...
与一开始介绍的插入记录的方法不同,现在这种方法可以将查找的结果存储到指定的数据表