数据挖掘(二)朴素贝叶斯
数据挖掘(二)朴素贝叶斯
1.朴素贝叶斯 概述
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。本章首先介绍贝叶斯分类算法的基础——贝叶斯定理。最后,我们通过实例来讨论贝叶斯分类的中最简单的一种: 朴素贝叶斯分类。
2.贝叶斯理论 & 条件概率
2.1贝叶斯理论
我们现在有一个数据集,它由两类数据组成,数据分布如下图所示:
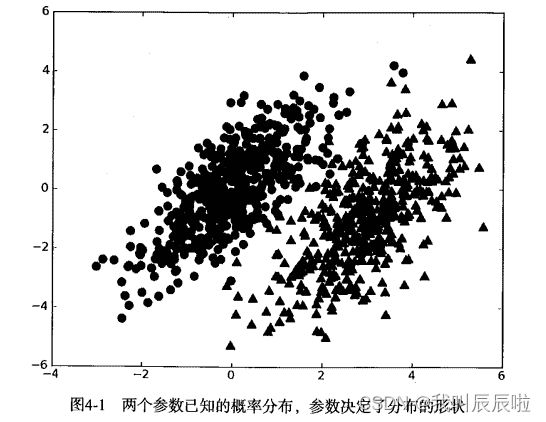
我们现在用 p1(x,y) 表示数据点 (x,y) 属于类别 1(图中用圆点表示的类别)的概率,用 p2(x,y) 表示数据点 (x,y) 属于类别 2(图中三角形表示的类别)的概率,那么对于一个新数据点 (x,y),可以用下面的规则来判断它的类别:
- 如果 p1(x,y) > p2(x,y) ,那么类别为1
- 如果 p2(x,y) > p1(x,y) ,那么类别为2
也就是说,我们会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。
2.2使用条件概率来分类
上面我们提到贝叶斯决策理论要求计算两个概率 p1(x, y) 和 p2(x, y):
- 如果 p1(x, y) > p2(x, y), 那么属于类别 1;
- 如果 p2(x, y) > p1(X, y), 那么属于类别 2.
这并不是贝叶斯决策理论的所有内容。使用 p1() 和 p2() 只是为了尽可能简化描述,而真正需要计算和比较的是 p(c1|x, y) 和 p(c2|x, y) .这些符号所代表的具体意义是: 给定某个由 x、y 表示的数据点,那么该数据点来自类别 c1 的概率是多少?数据点来自类别 c2 的概率又是多少?注意这些概率与概率 p(x, y|c1) 并不一样,不过可以使用贝叶斯准则来交换概率中条件与结果。具体地,应用贝叶斯准则得到:
![]()
使用上面这些定义,可以定义贝叶斯分类准则为:
- 如果 P(c1|x, y) > P(c2|x, y), 那么属于类别 c1;
- 如果 P(c2|x, y) > P(c1|x, y), 那么属于类别 c2.
在文档分类中,整个文档(如一封电子邮件)是实例,而电子邮件中的某些元素则构成特征。我们可以观察文档中出现的词,并把每个词作为一个特征,而每个词的出现或者不出现作为该特征的值,这样得到的特征数目就会跟词汇表中的词的数目一样多。
我们假设特征之间 相互独立 。所谓 独立(independence) 指的是统计意义上的独立,即一个特征或者单词出现的可能性与它和其他单词相邻没有关系,比如说,“我们”中的“我”和“们”出现的概率与这两个字相邻没有任何关系。这个假设正是朴素贝叶斯分类器中 朴素(naive) 一词的含义。朴素贝叶斯分类器中的另一个假设是,每个特征同等重要。

Note: 朴素贝叶斯分类器通常有两种实现方式: 一种基于伯努利模型实现,一种基于多项式模型实现。这里采用前一种实现方式。该实现方式中并不考虑词在文档中出现的次数,只考虑出不出现,因此在这个意义上相当于假设词是等权重的。
3.朴素贝叶斯 场景
机器学习的一个重要应用就是文档的自动分类。
在文档分类中,整个文档(如一封电子邮件)是实例,而电子邮件中的某些元素则构成特征。我们可以观察文档中出现的词,并把每个词作为一个特征,而每个词的出现或者不出现作为该特征的值,这样得到的特征数目就会跟词汇表中的词的数目一样多。
朴素贝叶斯是上面介绍的贝叶斯分类器的一个扩展,是用于文档分类的常用算法。下面我们会进行一些朴素贝叶斯分类的实践项目。
3.朴素贝叶斯 原理
朴素贝叶斯 工作原理
提取所有文档中的词条并进行去重
获取文档的所有类别
计算每个类别中的文档数目
对每篇训练文档:
对每个类别:
如果词条出现在文档中-->增加该词条的计数值(for循环或者矩阵相加)
增加所有词条的计数值(此类别下词条总数)
对每个类别:
对每个词条:
将该词条的数目除以总词条数目得到的条件概率(P(词条|类别))
返回该文档属于每个类别的条件概率(P(类别|文档的所有词条))
朴素贝叶斯 开发流程
收集数据: 可以使用任何方法。
准备数据: 需要数值型或者布尔型数据。
分析数据: 有大量特征时,绘制特征作用不大,此时使用直方图效果更好。
训练算法: 计算不同的独立特征的条件概率。
测试算法: 计算错误率。
使用算法: 一个常见的朴素贝叶斯应用是文档分类。可以在任意的分类场景中使用朴素贝叶斯分类器,不一定非要是文本。
朴素贝叶斯 算法特点
优点: 在数据较少的情况下仍然有效,可以处理多类别问题。
缺点: 对于输入数据的准备方式较为敏感。
适用数据类型: 标称型数据。
4.实验

使用sklearn实现朴素贝叶斯分类。
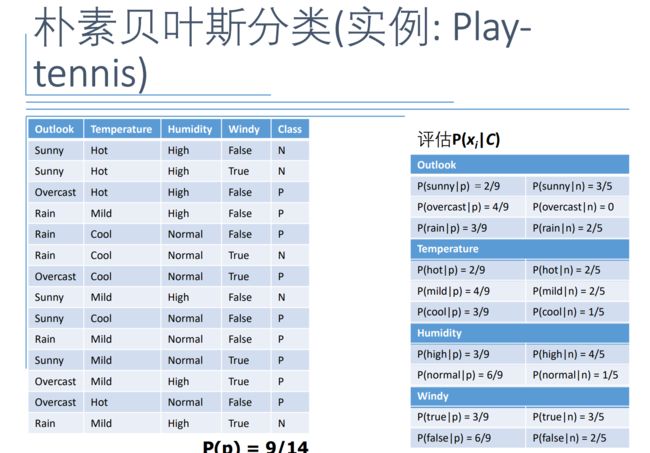
sklearn中关于朴素贝叶斯的介绍;

使用sklearn库中的高斯朴素贝叶斯,GaussianNB 实现了运用于分类的高斯朴素贝叶斯算法。特征的可能性(即概率)假设为高斯分布。
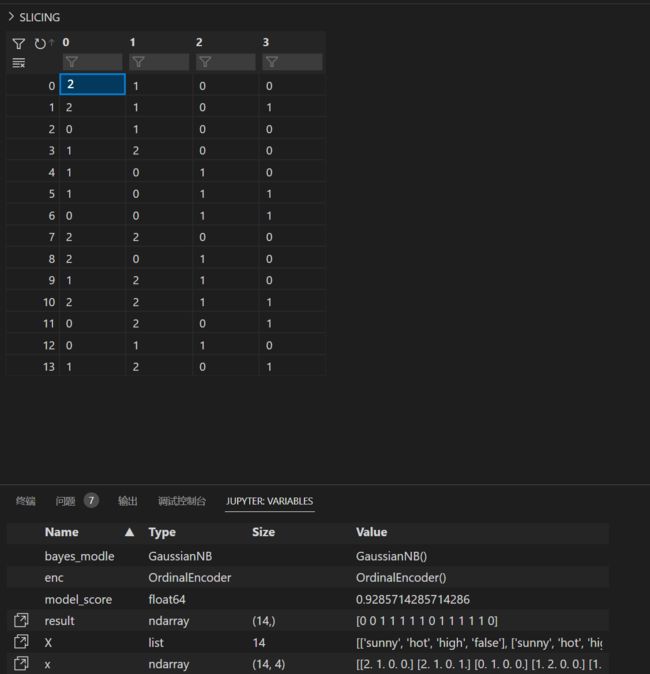
编码后的x:
from sklearn.naive_bayes import GaussianNB
from sklearn import preprocessing
X = [['sunny', 'hot', 'high', 'false'],
['sunny', 'hot', 'high', 'true'],
['overcast', 'hot', 'high', 'false'],
['rain', 'mild', 'high', 'false'],
['rain', 'cool', 'normal', 'false'],
['rain', 'cool', 'normal', 'true'],
['overcast', 'cool', 'normal', 'true'],
['sunny', 'mild', 'high', 'false'],
['sunny', 'cool', 'normal', 'false'],
['rain', 'mild', 'normal', 'false'],
['sunny', 'mild', 'normal', 'true'],
['overcast', 'mild', 'high', 'true'],
['overcast', 'hot', 'normal', 'false'],
['rain', 'mild', 'high', 'true']]
y = [0, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0]
# 这里使用 Ordinal Encoding - 序数编码 将字符串编码即labelecoding便于后续处理
# 这个编码方式非常容易理解,就是把所有的相同类别的特征编码成同一个值,例如女=0,男=1,狗狗=2,所以最后编码的特征值是在[0, n-1]之间的整数。
# 这个编码的缺点在于它随机的给特征排序了,会给这个特征增加不存在的顺序关系,也就是增加了噪声。
# 假设预测的目标是购买力,那么真实Label的排序显然是 女 > 狗狗 > 男,与我们编码后特征的顺序不存在相关性。
# 注意不同编码方式在不同情景下的选择
enc = preprocessing.OrdinalEncoder()
enc.fit(X)
x=enc.transform(X)
bayes_modle=GaussianNB()
#训练数据
bayes_modle.fit(x,y)
#使用模型进行分类预测
result=bayes_modle.predict(x)
print(result)
#对模型评分
model_score=bayes_modle.score(x,y)
print(model_score)