传统量化与ai量化对比
A Testing Perspective of Unwanted AI Bias
不需要的AI偏差的测试角度
Bias refers to prejudice in favor of or against one thing, person, or group compared with another, usually in a way considered to be unfair.
偏见是指偏向于赞成或反对一个事物,个人或群体与另一个事物,个人或群体的偏见,通常以一种不公平的方式。
世界充满了偏见 (The World is Filled with Bias)
A quick search on bias reveals a list of nearly 200 cognitive biases that psychologists have classified based on human beliefs, decisions, behaviors, social interactions, and memory patterns. Certainly, recent events stemming from racial inequality and social injustice are raising greater awareness of the biases that exist in the world today. Many would argue that our social and economic system is not designed to be fair and is even engineered in a way that marginalizes specific groups and benefits others. However, before we can improve such a system, we first have to be able to identify and measure where and to what degree it is unfairly biased.
对偏见的快速搜索显示了心理学家根据人类的信念,决策,行为,社交互动和记忆模式分类的近200种认知偏见的列表 。 当然,由于种族不平等和社会不公正而引起的最近事件正在提高人们对当今世界上存在的偏见的认识。 许多人会争辩说,我们的社会和经济体系的设计不公平,甚至在设计上会边缘化特定群体并使他人受益。 但是,在改进这种系统之前,我们首先必须能够识别和衡量该系统在不公正的地方和偏向程度。
Since the world is filled with bias, it follows that any data we collect from it contains biases. If we then take that data and use it to train AI, the machines will reflect those biases. So how then do we start to engineer AI-based systems that are fair and inclusive? Is it even practical to remove bias from AI-based systems, or is it too daunting of a task? In this article, we explore the world of AI bias and take a look at it through the eyes of someone tasked with testing the system. More specifically, we describe a set of techniques and tools for preventing and detecting unwanted bias in AI-based systems and quantifying the risk associated with it.
由于世界充满了偏差,因此我们从中收集的任何数据都包含偏差。 如果我们随后获取这些数据并将其用于训练AI,则这些机器将反映出这些偏差。 那么,我们如何开始设计公平,包容的基于AI的系统呢? 从基于AI的系统中消除偏见甚至可行,还是一项任务太艰巨? 在本文中,我们探索了AI偏差的世界,并通过负责测试系统的人员的眼光进行了研究。 更具体地说,我们描述了一套技术和工具,用于预防和检测基于AI的系统中的有害偏差并量化与之相关的风险。
并非所有偏见都是平等产生的 (Not All Bias is Created Equally)
While there is definitely some irony in this heading, one of the first things to recognize when designing AI-based systems is that there will be bias, but not all bias necessarily results in unfairness. In fact, if you examine the definition of bias carefully, the phrase “usually in a way considered to be unfair” implies that although bias generally carries a negative connotation, it isn’t always a bad thing. Consider any popular search engine or recommendation system. Such systems typically use AI to predict user preferences. Such predictions can be viewed as a bias in favor of or against some items over others. However, if the problem domain or target audience calls for such a distinction, it represents desired system behavior as opposed to unwanted bias. For example, it is acceptable for a movie recommendation system for toddlers to only display movies rated for children ages 1–3. However, it would not be acceptable for that system to only recommend movies preferred by male toddlers when the viewers could also be female. To avoid confusion, we typically refer to the latter as unwanted or undesired bias.
W¯¯往往微不足道肯定是有本品目的第一件事情认识到一个具有讽刺意味的一些设计时,基于人工智能的系统是会有偏差,但并非所有的偏见必然导致不公平。 实际上,如果仔细检查偏见的定义,短语“通常以一种不公平的方式表示”意味着,尽管偏见通常带有负面含义,但这并不总是一件坏事。 考虑任何流行的搜索引擎或推荐系统。 这样的系统通常使用AI来预测用户偏好。 可以将此类预测视为赞成或反对某些项目相对于其他项目的偏见。 但是,如果问题域或目标受众要求进行这种区分,则它表示所需的系统行为,而不是不需要的偏见。 例如,对于幼儿的电影推荐系统,仅显示额定为1-3岁儿童的电影是可以接受的。 但是,当观众也可能是女性时,该系统仅推荐男性幼儿喜欢的电影是不可接受的。 为避免混淆,我们通常将后者称为不必要或不希望有的偏见。
AI偏差周期 (The AI Bias Cycle)
A recent survey on bias and fairness in machine learning by researchers at the University of Southern California’s Information Sciences Institute defines several categories of bias definitions in data, algorithms, and user interactions. These categories of bias are summed up in a cycle depicted in Figure 1, and can be described as follows:
最近 在机器学习的偏见和公正的调查 ,研究人员在南加州的信息科学研究所大学定义了几种类型的数据,算法和用户交互偏置定义。 这些偏差类别在图1所示的一个周期中汇总,可以描述如下:
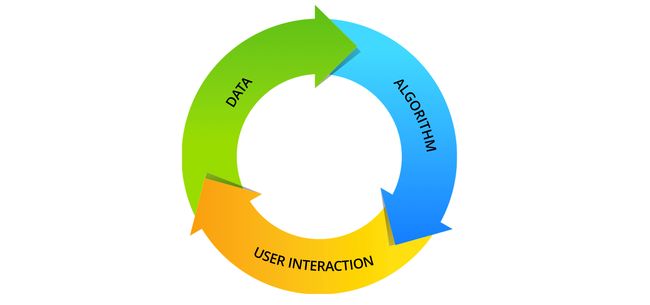
Data Bias: The cycle starts with the collection of real-world data that is inherently biased due to cultural, historical, temporal, and other reasons. Sourced data is then sampled for a given application which can introduce further bias depending on the sampling method and size.
数据偏差 :周期始于收集现实世界的数据,这些数据由于文化,历史,时间和其他原因而固有地存在偏差。 然后针对给定的应用对源数据进行采样,这可能会导致进一步的偏差,具体取决于采样方法和大小。
Algorithmic Bias: The design of the training algorithm itself or the way it is used can also result in bias. These are systematic and repeatable errors that cause unfair outcomes such as privileging one set of users over others. Examples include popularity, ranking, evaluation, and emergent bias.
算法偏差 :训练算法本身的设计或使用方法也会导致偏差。 这些是系统性且可重复的错误,会导致不公平的结果,例如使一组用户享有特权。 例子包括受欢迎程度,排名,评估和紧急偏见。
User Interaction Bias: Both the user interface and user can be the source of bias in the system. As such, care should be taken in how user input, output, and feedback loops are designed, presented, and managed. User interactions typically produce new or updated data that contains further bias, and the cycle repeats.
用户交互偏差 :用户界面和用户均可成为系统偏差的源头。 因此,应注意如何设计,呈现和管理用户输入,输出和反馈循环。 用户交互通常会产生包含进一步偏差的新数据或更新数据,并且循环会重复。
人工智能中的偏见资源 (Resources on Bias in AI)
Interested in learning more about the unwanted AI bias and the bias cycle? Check out these video resources by Ricardo Baeza-Yates, Director of Graduate Data Science Programs at Northeastern University, and former CTO of NTENT. In the first video, Baeza-Yates does a great job of introducing bias and explaining the bias cycle in less than four minutes. In the second video, he takes a deeper dive into the data and algorithmic bias, providing several real-world examples of the different types of bias. Baeza-Yates is clearly an expert in the field and I highly recommend that you check out his Google Scholar Profile for additional resources and publications on this topic.
我想了解更多有关不必要的AI偏差和偏差周期的信息吗? 东北大学研究生数据科学计划主任,前NTENT首席技术官Ricardo Baeza-Yates观看这些视频资源。 在第一个视频中,Baeza-Yates出色地介绍了偏差并在不到四分钟的时间内解释了偏差周期。 在第二个视频中,他更深入地介绍了数据和算法偏差,并提供了几种不同类型偏差的真实示例。 Baeza-Yates显然是该领域的专家,我强烈建议您查看他的Google Scholar个人资料,以获取有关此主题的其他资源和出版物。
Bias on the Web: A Quick Introduction with Ricardo Baeza-Yates. 网络上的偏见:Ricardo Baeza-Yates的快速入门。 Data and Algorithmic Bias on the Web: A Deeper Dive with Ricardo Baeza-Yates. 网络上的数据和算法偏差:与Ricardo Baeza-Yates的更深入的探讨。During last year’s Quest for Quality conference, I had the pleasure of meeting Davar Ardalan, founder and storyteller in chief of IVOW. Her recent post: “AI Fail: To Popularize and Scale Chatbots We Need Better Data” has a list of resources on different topics related to AI bias.
在去年的质量追求会议上,我很高兴见到了IVOW的创始人兼讲故事者Davar Ardalan 。 她最近发表的文章“ AI失败:要普及和扩展聊天机器人,我们需要更好的数据 ”列出了与AI偏见相关的不同主题的资源列表。
不需要的AI偏差:测试角度 (Unwanted AI Bias: A Testing Perspective)
Having spent my career studying and practicing the discipline of software testing, it is evident that the testing community has a role to play in the engineering of AI-based systems. More specifically, on the issue of AI bias, I believe testers have the necessary skills to directly contribute to tackling the problem of unwanted bias in AI systems.
^ h AVING花了我职业生涯的学习和实践软件测试的纪律,这是显而易见的是,测试社区有一定的作用基于AI-系统的工程发挥。 更具体地说,在AI偏差问题上,我相信测试人员具有必要的技能,可以直接为解决AI系统中不希望有的偏差问题做出贡献。
Shortly after my friend and colleague Jason Arbon gave a keynote at PNSQC 2019 on testing AI and bias and released a free e-book on the topic, we started brainstorming about what testers can bring to the table today to help with the challenge of unwanted AI bias. Here are the answers that came — testing heuristics for preventing and detecting AI bias, and a quantitative tool for assessing the risk of unwanted bias in AI systems. As life would have it, nearly a year later we’re only just getting around to putting these ideas out into the community.
在我的朋友和同事Jason Arbon在PNSQC 2019关于测试AI和偏见的主题演讲并发布了有关该主题的免费电子书之后不久,我们开始集思广益,讨论今天的测试人员可以带什么来帮助应对不需要的AI挑战偏压。 这是得出的答案-测试启发式算法以预防和检测AI偏差,以及定量工具以评估AI系统中不必要偏差的风险。 就像生活一样,将近一年后,我们才刚刚开始将这些想法传播到社区中。
AI偏见测试启发式 (AI Bias Testing Heuristics)
It’s a myth that testers don’t like shortcuts. Tester’s actually love shortcuts — just not the kind of shortcuts that compromise quality. However, shortcuts that take complex testing problems and reduce them into simpler judgments are welcomed with open arms. That is exactly what testing heuristics are — cognitive shortcuts that help us to solve problems while testing software. We provide three types of heuristic-based artifacts to support testing AI for unwanted bias: a set of mnemonics and a questionnaire checklist.
我 T的一个神话,测试者不喜欢的快捷键。 测试人员真正喜欢的快捷方式-只是不影响质量的快捷方式。 但是,张开双臂欢迎采用复杂的测试问题并将其简化为简单判断的捷径。 这正是测试启发式技术的本质-认知捷径,可帮助我们在测试软件时解决问题。 我们提供了三种基于启发式的工件,以支持对AI进行不必要的偏见测试:一组助记符和一个调查表清单 。
用于测试AI偏差的助记符 (Mnemonics for Testing AI Bias)
If you’ve forgotten them, mnemonics are memory tools! just kidding :) But seriously, mnemonics help our brains package information, store it safely, and retrieve it at the right moment. To this day, I still recall many of the mnemonics I learned in math class such as Never Eat Shredded Wheat for remembering the cardinal points and BODMAS or PEMDAS for the order of mathematical operations.
如果您忘记了它们,助记符就是记忆工具! 只是在开玩笑:)但是,认真的说,助记符可以帮助我们的大脑打包信息,安全地存储它们,并在适当的时候进行检索。 直到今天,我仍然记得我在数学课上学到的许多记忆法,例如“ 永不吃切丝的小麦”,因为它记住了基点和BODMAS或 佩达斯 用于数学运算的顺序。
As a starting point for developing a set of practical techniques for testing AI systems, we’ve created seven mnemonics to help engineers remember the key factors associated with unwanted AI bias. These mnemonics are displayed graphically over the AI bias cycle in Figure 2 and are described as follows:
作为开发一组用于测试AI系统的实用技术的起点,我们创建了七个助记符,以帮助工程师记住与有害的AI偏差相关的关键因素。 这些助记符在图2中的AI偏置周期上以图形方式显示,描述如下:
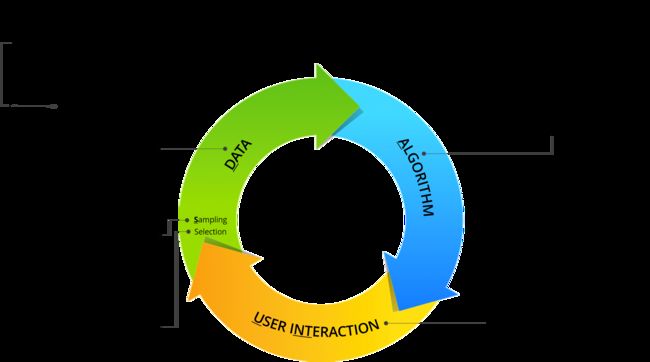
Mnemonic #1: DAUNTSThe challenge of testing AI for bias can seem daunting and so it is only fitting that DAUNTS is our first mnemonic. It is a reminder of the top-level categories in the AI bias cycle — Data, Algorithm, User iNTeraction, Selection/Sampling
助记符1: DAUNTS测试AI的偏见挑战似乎令人生畏,因此, DAUNTS是我们的第一个助记符是很合适的。 这是的顶层类别在AI偏压周期的提醒- d ATA,A lgorithm,U SER我 NT eraction,S 选举/采样
Mnemonic #2: CHAT Since the 70’s, the real-time transmission of text has been a signature of the Internet. CHATS is meant to remind us of the biases in data sourced from the web — Cultural, Historical, Aggregation, and Temporal.
助记键2: CHAT自70年代以来,文本的实时传输一直是Internet的签名。 CHATS意于r emind我们从网页源数据的偏见- Visual C ultural,H istorical,A ggregation和 T emporal。
Mnemonic #3: Culture > Language + GeographyTo break the monotony of all the acronyms, this mnemonic is in the form of a math equation. Actually, it’s more of an acronym hidden in an equation when in natural language: Culture is GREATER than Language and Geography. This mnemonic represents all the sub-types of cultural bias which in addition to language and geography include these seven other aspects of humanity — Gender, Race, Economics, Age, Tribe, Education, and Religion.
助记符3: 文化>语言+地理为了消除所有首字母缩写词的单调性,此助记符采用数学方程式的形式。 其实,它更隐藏在自然语言时,在方程中的首字母缩写的: 文化 大于 语言 和 地理。 这助记符表示所有子类型的文化偏见的它除了语言和地域包括人类的这七个其他方面- 摹 安德,R 王牌,E conomics, 通用电气,T 里伯,E 知识教育,和 R eligion。
Mnemonic #4: SMSWe’ve repurposed the well-known mobile acronym SMS to help refine the sampling bias category by indicating the need to check for diversity in data sources and appropriate sampling — Sources, Sampling Method, and Size.
助记符#4: 短信我们已经通过指示需要检查数据源和适当的采样多样性改变用途的知名移动缩写短信帮助改进抽样偏差类别- S OURCES,抽样 中号 ethod和 S IZE。
Mnemonic #5: MOVReminiscent of both the Quicktime movie file type and the machine instruction that moves data from one location to another, MOV now gives us an easy way to remember the types of selection bias — Measurement, and Omitted Variable.
助记符#5:QuickTime影片文件类型和机器指令移动数据从一个位置到另一个位置,MOV,现在给我们一个简单的方法来记住类型选择偏差的两个MOV让人联想- 中号 easurement和 O mitted V 良莠不齐。
Mnemonic #6: A PEERInspired by the peer-to-peer (P2P) architecture made popular by the music sharing application Napster, A PEER encompasses five key biases — Algorithmic, Popularity, Evaluation, Emergent, and Ranking.
助记符#6:由对等网络(P2P)架构的启发对等制成流行的音乐共享应用的Napster, 对等涵盖五个关键偏差- 甲 lgorithmic,P opularity,E 估值,E 子公司Mergent和 R 安庆。
Mnemonic #7: Some People Only Like Buying Cool ProductsA set of testing mnemonics would not be complete without a good rhyme that feels a bit random and unscripted. This final mnemonic for the types of user interaction bias is just that — Social, Presentation, Observer, Linking, Behavioral, Cause-Effect, and Production.
助记符#7:S OME P eople 唯一一句 大号 IKE 乙 uyingÇOOL ==产品目录==一组测试的助记符将是不完整的好韵说感觉有点随意和即兴。 该最终助记符类型的用户交互偏置的仅仅是- S ocial,P resentation,O- bserver,L 输墨,B ehavioral,C 澳洲英语效应,和 P roduction。
It should be noted that the aforementioned sub-categories of bias are heavily intertwined, and do not necessarily fit cleanly into the separate boxes as depicted in Figure 2. The goal is to place them where they have the most impact and relevance in your problem domain or application space.
应当注意,前面提到的偏见子类别相互交织在一起,不一定完全适合如图2所示的单独的框。目标是将它们放置在问题领域中影响最大和最相关的位置或应用程序空间。
测试AI偏见的问卷调查表 (Questionnaire Checklist for Testing AI Bias)
Good testers ask questions, but great testers seem to know the right questions to ask and where they should look for the answer. This is what makes the questionnaire checklist a useful tool for understanding and investigating software quality. Such artifacts provide questions that provoke answers that reveal whether desirable attributes of the product or process have been met.
优秀的测试人员会提出问题,但是优秀的测试人员似乎知道应该提出的正确问题以及应该在哪里寻找答案。 这就是使问卷清单成为理解和调查软件质量的有用工具的原因。 此类工件提供了引发答案的问题,这些答案揭示了是否已满足产品或过程的理想属性。
Based on our experiences testing AI systems, we have created a questionnaire checklist. The goal of the questionnaire is to ensure that people building AI-based systems are aware of unwanted bias, stability, or quality problems. If an engineer cannot answer these questions, it is likely that the system produced contains unwanted, and possibly even liable versions of bias.
根据我们测试AI系统的经验,我们创建了一个调查表清单。 问卷的目的是确保构建基于AI的系统的人员意识到不必要的偏差,稳定性或质量问题。 如果工程师不能回答这些问题,则可能是所生成的系统包含不需要的,甚至可能是可靠的偏差版本。
Questionnaire Checklist for Testing AI and Bias 测试AI和偏差的问卷清单AI偏差风险评估工具 (AI Bias Risk Assessment Tool)
Although the mnemonics and questionnaire are a good start, let’s take it a step further and bring another contribution to the table — one that undeniably spells T-E-S-T-E-R. Surely nothing spells tester better than R-I-S-K. After all, testing is all about risk. One of the main reasons we test software is to identify risks with the release. Furthermore, if a decision is made to not test a system or component, then we’re probably going to want to talk to stakeholders about the risks of not testing.
一个 lthough助记符和问卷是一个良好的开端,让我们把它更进一步,带来的表另一个贡献-一个不可否认的法术测试仪。 当然,没有什么比RISK更能说明测试人员了。 毕竟,测试完全是关于风险的。 我们测试软件的主要原因之一就是要确定发行版中的风险。 此外,如果决定不测试系统或组件,那么我们可能要与利益相关者讨论未测试的风险。
Risk is anything that threatens the success of a project. As testers, we are constantly trying to measure and communicate quality and testing-related risks. It is clear that unwanted bias poses several risks to the success of AI, and therefore we are happy to contribute a tool for assessing the risk of AI bias.
风险是任何威胁项目成功的因素。 作为测试人员,我们一直在努力衡量和传达质量以及与测试相关的风险。 显然,不必要的偏见对AI的成功构成了若干风险,因此我们很乐意为评估AI偏见的风险提供一种工具。
The idea behind the tool is that, like the checklist questionnaire, it serves as a way to capture responses to questions about characteristics of the data, including its sampling and selection process, machine learning algorithm, and user interaction model. However, as responses are entered into the system, it quantifies the risk of unwanted bias.
该工具背后的想法是,像清单调查表一样,它可以用作捕获对有关数据特征的问题的响应的方法,包括数据的采样和选择过程,机器学习算法以及用户交互模型。 但是,随着响应输入到系统中,它可以量化不必要的偏差的风险。
AI BRAT简介 (Introducing the AI BRAT)
Our first version of the AI bias risk calculation tool was a quick and easy Google sheet template. However, Dionny Santiago and the team at test.ai have transformed it from template to tool and launched a mobile-friendly web application codenamed AI BRAT — AI Bias Risk Assessment Tool.
我们的AI偏差风险计算工具的第一个版本是一个快速简便的Google表格模板 。 然而, Dionny圣地亚哥和团队test.ai从模板工具把它改造,并推出代号为AI小子移动友好的Web应用程序- AI偏差的风险评估工具 。
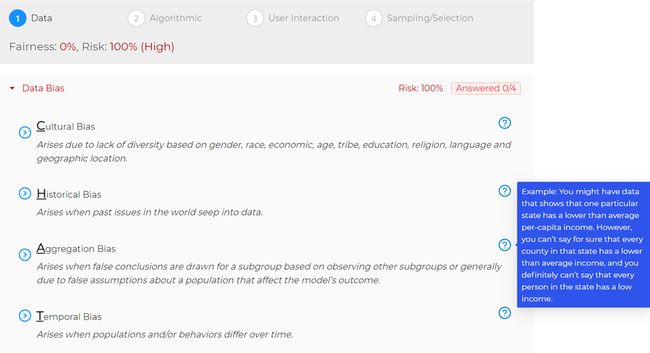
To promote learning and application of the heuristics described in this article, questions in AI BRAT are grouped and ordered according to the mnemonics. Definitions for each type of bias appear below each sub-heading, and tooltips with examples can be viewed by hovering over or tapping on the question mark icon to the right.
为了促进本文所述启发式方法的学习和应用,AI BRAT中的问题根据助记符进行了分组和排序。 每种偏见的定义都出现在每个子标题的下方,可以通过将鼠标悬停在或点击右侧的问号图标来查看带有示例的工具提示。
Expanding a sub-heading reveals questions associated with the considerations made for detecting and/or mitigating each type of bias and the likelihood of it occurring in the dataset. AI BRAT tracks answered questions from each section to ensure each type of bias is being covered.
展开子标题将揭示与为检测和/或减轻每种类型的偏差以及在数据集中出现偏差的可能性而进行的考虑有关的问题。 AI BRAT跟踪每个部分的已回答问题,以确保涵盖每种偏见。

风险计算 (Risk Calculation)
As questions are answered, values for the severity and likelihood of AI bias are assigned to responses. Responses contribute to severity (impact) and likelihood (probability) values as follows:
在回答问题时,会将AI偏倚的严重性和可能性值分配给响应。 响应对严重性(影响)和可能性(概率)值的贡献如下:
Severity/ImpactI do not know or have not considered this type of bias (3 Points)I have discovered unwanted bias and am unable to mitigate it (3 Points)I have discovered unwanted bias but implemented bias mitigation (2 Points)I have not discovered unwanted bias or determined it is acceptable (1 Point)
严重程度/影响我不知道或未考虑这种偏见(3分)我发现了不想要的偏见并且无法缓解(3分)我发现了不想要的偏见但实施了偏见缓解(2分)我没有发现不必要的偏差或确定可接受的偏差(1分)
Likelihood/ProbabilityLikely (3 Points), Somewhat Likely (2 Points), Not Likely (1 Point)
可能性/概率 (3分), 可能性 (2分),不太可能(1分)
AI BRAT then calculates a risk score using a 3x3 risk matrix and classifies it into high, medium, or low based on the result of multiplying the likelihood and severity values.
然后,AI BRAT使用3x3风险矩阵计算风险评分,并根据可能性和严重性值相乘的结果将其分为高,中或低。

解释,使用和保存结果 (Interpreting, Using and Saving the Results)
AI BRAT is initialized with a risk score of 100%. In other words, there is a 0% chance that the system is fair and each section is highlighted red. As users respond to each question, the goal is to drive the risk of bias score down until the section turns green, or until the value is as low as possible (in this case 11% which is 1 out of 9).
AI BRAT的风险得分为100%。 换句话说,系统公平的几率是0%,并且每个部分都以红色突出显示。 当用户回答每个问题时,目标是降低偏差评分的风险,直到该部分变为绿色,或者直到该值尽可能低(在这种情况下为11%,即9分之一)。
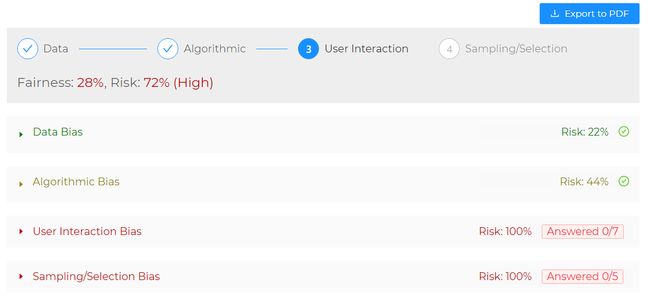
Results can also be saved to a report using the Export to PDF button at the top-right. Check out AI BRAT today at https://bias.test.ai and let us know what you think.
也可以使用右上角的“ 导出为PDF”按钮将结果保存到报告中。 立即在https://bias.test.ai上查看AI BRAT,让我们知道您的想法。
测试AI偏差的其他资源和工具 (Other Resources and Tools on Testing AI Bias)
Technology giants Google, Microsoft ,and IBM have all developed tools and guides for testing AI for bias and/or fairness.
牛逼李有成巨头谷歌,微软和IBM都开发工具和指南,用于测试AI的偏差和/或公平性。
Google的假设工具 (Google’s What-If Tool)
In this Google AI Blog, James Wexler describes the What-If Tool, a feature of the open-source TensorBoard web application, that facilitates visually probing the behavior of trained machine learning models. Watch the video below for an introduction to the tool, including an overview of its major features.
詹姆斯·韦克斯勒(James Wexler)在这个Google AI博客中描述了假设工具 ( What-If Tool) ,这是开源TensorBoard Web应用程序的一项功能,该工具有助于直观地探究经过训练的机器学习模型的行为。 观看下面的视频,以了解该工具,包括其主要功能概述。
Introducing the What-If Tool for Visually Probing Trained Machine Learning Models 引入用于可视化探究训练过的机器学习模型的假设工具微软的Fairlearn工具包 (Microsoft’s Fairlearn Toolkit)
Microsoft is tackling bias in machine learning through its new open-source Fairlearn Toolkit. Fairlearn is a Python package that enables ML engineers to assess their system’s fairness and mitigate observed unfairness issues. It contains mitigation algorithms as well as a Jupyter widget for model assessment. Besides the source code, this repository also contains Jupyter notebooks with examples of Fairlearn usage. In the video below, Mehrnoosh Sameki, Senior Product Manager at Azure AI, takes a deep-dive into the latest developments in Fairlearn.
微软正在通过其新的开源Fairlearn Toolkit解决机器学习方面的偏见。 Fairlearn是一个Python软件包,使ML工程师能够评估其系统的公平性并减轻观察到的不公平性问题。 它包含缓解算法以及用于模型评估的Jupyter小部件。 除了源代码外,该存储库还包含Jupyter笔记本,其中包含Fairlearn用法示例。 在下面的视频中,Azure AI的高级产品经理Mehrnoosh Sameki深入研究了Fairlearn的最新开发。
IBM的AI Fairness 360工具包 (IBM’s AI Fairness 360 Toolkit)
The staff members of the Trusted AI group of IBM Research have released AI Fairness 360 — an open-source toolkit that helps you examine, report, and mitigate discrimination and bias in machine learning models throughout the AI application lifecycle. The toolkit contains over 70 fairness metrics and 10 state-of-the-art bias mitigation algorithms that have been developed by the research community. Check out a quick demo of AI Fairness 360 below.
IBM Research的Trusted AI组的工作人员已经发布了AI Fairness 360 ,这是一个开源工具包,可帮助您检查,报告和减轻在整个AI应用程序生命周期中机器学习模型中的歧视和偏见。 该工具包包含由研究团体开发的70多个公平性指标和10个最新的偏差缓解算法。 在下面查看AI Fairness 360的快速演示。
下一步是什么? (What’s Next?)
Wondering how to get involved? Here are some ways we believe folks can have an impact on testing AI and bias:
w ^ ondering如何参与? 我们认为,以下是人们可以对测试AI和偏见产生影响的一些方式:
- Devising practical testing methods and processes for preventing and detecting unwanted bias in datasets. 设计实用的测试方法和过程,以防止和检测数据集中不必要的偏差。
- Developing new coverage models and static/dynamic analysis tools for validating AI and ML systems. 开发新的覆盖模型和静态/动态分析工具以验证AI和ML系统。
- Mastering and contributing to the existing open-source toolkits for measuring fairness and detecting/mitigating unwanted AI bias. 掌握并为现有的开源工具包做出贡献,这些工具包用于衡量公平性并检测/减轻不希望的AI偏差。
翻译自: https://levelup.gitconnected.com/quantifying-the-risk-of-ai-bias-998a5542a5e0
传统量化与ai量化对比