M²BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Bird’s-Eye View Representation
M²BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Bird’s-Eye View Representation 论文笔记
原文链接:https://arxiv.org/pdf/2204.05088.pdf
1.引言
本文设计一个联合训练多视图图像3D目标检测和BEV分割任务的统一网络。此外,本文提出了几个能提高精度并减小空间耗费的方法:
- 高效BEV编码器:使用“空间到通道”(S2C)操作将4D体素张量转化为3D BEV张量以避免使用3D卷积;
- 针对3D检测的动态框分配:以学习匹配策略为真实边界框分配锚框;
- 针对BEV分割的BEV中心性:考虑到BEV下远距离区域对应图像的像素少,根据像素到自车距离重新加权,对远距离像素分配更大的权重。
- 在2D图像编码器中的2D检测预训练和辅助监督:可加速训练过程,并提升性能。
3.方法
整体结构如下图所示。
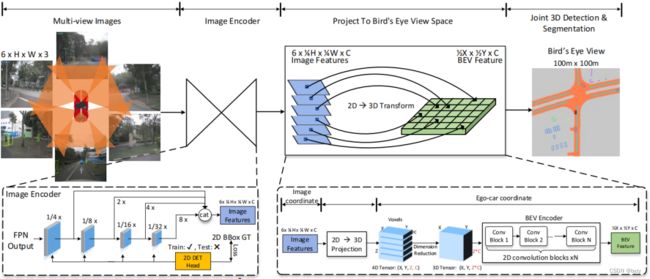
3.1 M²BEV流程
整体结构:多视图图像首先输入图像编码器得到2D特征,然后投影到3D空间得到体素。体素输入到高效BEV编码器得到BEV特征,最后使用检测头和分割头进行预测。
2D图像编码器:对每个视图图像,使用共享的CNN网络(如ResNet)以及特征金字塔网络(FPN)来建立多级特征,然后上采样到相同大小,拼接后通过![]() 卷积融合得到张量
卷积融合得到张量 。
。
2D到3D投影:该模块是使本方法可以实现多任务训练的关键模块。该模块将多视图特征组合并投影为体素 ,见3.2节。体素特征包含了来自各个视图图像的特征,因此是一个统一的表达。
,见3.2节。体素特征包含了来自各个视图图像的特征,因此是一个统一的表达。
3D BEV编码器:目的是将 轴压缩,得到BEV特征。最直接的方法就是在轴方向使用多个带步长的3D卷积,但该方法缓慢而低效。本文使用“空间到通道”(S2C)操作,见3.3节。
轴压缩,得到BEV特征。最直接的方法就是在轴方向使用多个带步长的3D卷积,但该方法缓慢而低效。本文使用“空间到通道”(S2C)操作,见3.3节。
3D检测头:基于BEV特征,可直接使用基于激光雷达的检测头。本文直接使用PointPillars的检测头(生成密集3D锚框然后预测类别、尺寸和朝向),仅包含3个并行的![]() 卷积。但在分配策略上,本文使用动态框分配,见3.3节。
卷积。但在分配策略上,本文使用动态框分配,见3.3节。
BEV分割头:由若干 卷积和一个
卷积和一个![]() 卷积组成。还使用了BEV中心性策略为像素重新加权损失,见3.3节。
卷积组成。还使用了BEV中心性策略为像素重新加权损失,见3.3节。
3.2 高效的2D到3D投影
设 为内参矩阵,
为内参矩阵, 为外参矩阵,
为外参矩阵, 为图像,为体素张量,则投影公式为
为图像,为体素张量,则投影公式为
![]()
其中 为像素
为像素![]() 的深度。若未知,则中每个像素对应中在相机射线上的一组点。
的深度。若未知,则中每个像素对应中在相机射线上的一组点。
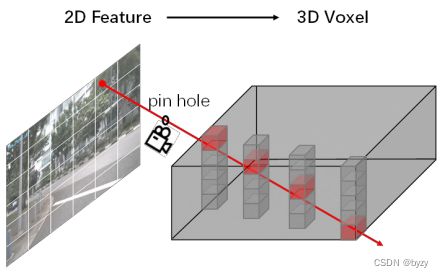
本文假设沿相机射线的深度为均匀分布的,即所有像素射线上的体素特征均与该像素特征相同,如下图所示。这样可以通过减小可学习参数量来提高计算和存储效率。
3.3 改进设计
高效BEV编码器:S2C操作即将4D体素张量![]() 变形为
变形为![]() 大小的3D张量,然后使用2D卷积减小通道维度。
大小的3D张量,然后使用2D卷积减小通道维度。
动态框分配:通常的基于IoU阈值的手工匹配方法在本文问题上可能是次优的,因为BEV特征没有考虑深度,包含的几何信息不太准确。因此本文使用学习匹配策略(类似FreeAnchor方法):在训练时先对每个锚框预测类别和位置,再基于IoU为每个真实边界框选择一批锚框,然后使用分类分数和位置精度的加权和来区分正锚框。这样,分类分数低以及定位误差大的锚框为负锚框。
BEV中心性:
中心性(centerness)的概念被广泛用于2D检测,重新加权正样本。
考虑到BEV下远距离区域对应图像的像素少,因此需要让模型更关注远处区域。中心性定义如下:

其中 是BEV点的坐标,
是BEV点的坐标,![]() 是BEV中心坐标(即自车坐标)。该值在1到2的范围内,作为损失函数的计算权重,以给远处的分割错误更大的惩罚。
是BEV中心坐标(即自车坐标)。该值在1到2的范围内,作为损失函数的计算权重,以给远处的分割错误更大的惩罚。
实验表明该值的引入对不同距离的分割精度均有提升,且距离越远提升越大。
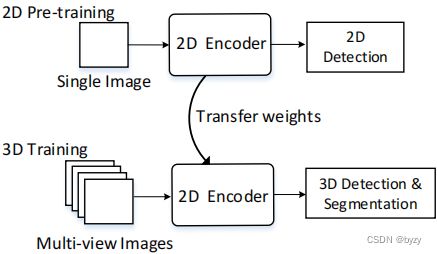
2D检测预训练:如下图所示,在大型2D检测数据集上进行预训练后能够大幅提升3D检测性能。
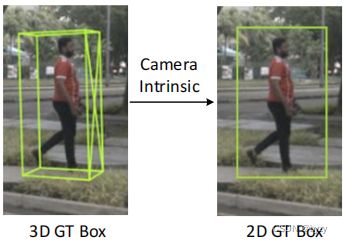
2D辅助监督:如图1所示,在得到多尺度图像特征后,添加2D检测头并计算与2D真实边界框(由3D真实边界框投影到图像后产生;见下图)的损失。该2D检测头仅在训练时使用。
2D检测作为预训练和辅助监督能提高图像特征对物体的感知,从而提高3D检测性能。
3.4 训练损失
最终损失是3D检测损失、BEV分割损失和辅助2D检测损失之和。
3D检测损失与PointPillars相同,即
![]()
其中分类损失为focal损失;边界框损失为SmoothL1损失,包含位置、尺寸、速度和朝向角;朝向分类损失为二元交叉熵。
BEV分割损失为Dice损失和二元交叉熵损失的加权和。
辅助2D检测损失与FCOS中相同,为分类损失、边界框损失和中心性损失之和。
4.实验
4.2 与SotA的比较
3D检测:本文的方法能超过需要额外训练数据的方法。
BEV分割:本文方法极大地超过LSS,说明深度估计对BEV分割来说不是必要的。
此外,相比于分开训练两个任务,联合训练时的性能略有下降。
4.3 消融研究
3D检测:动态框分配和2D检测预训练均能大幅提高性能;S2C操作和2D检测辅助监督能略微提高性能。
预训练的性能提升取决于数据集之间的domain gap;且其余3D检测模型也能够通过预训练提高性能;此外预训练能加快网络收敛。
此外,预训练以后,最终仅使用一半的训练数据就能达到和全部训练数据相似的结果。这说明更易获取的2D标注能减少对3D标注的需求。
BEV分割:2D检测预训练和S2C操作能大幅提高性能;BEV中心性能提升远处的分割效果。高效BEV编码器的2D卷积可以更多地堆叠以细化BEV特征,且仍比3D卷积的堆叠更高效。
多任务联合训练:3D检测和BEV分割不能相互促进,这可能是因为物体的位置分布和地图没有强相关性(如许多汽车不位于可行驶区域)。但由于联合网络极大节省了推断时间,其重要性不可忽略。
运行效率:相比于在后处理阶段融合结果的FCOS以及使用昂贵的transformer解码器的DETR3D,本文方法更加高效。
对校正误差的鲁棒性:测试时,在外参低噪声情况下,本文方法有相对较强的鲁棒性,但进一步增大外参噪声会使得性能大幅下降。
4.4 局限性
在复杂的道路情况下可能会出现错误预测;与基于激光雷达的方法仍有一定差距;测试时不可避免的外参噪声会造成性能下降。
附录
A.其他实施细节
检测头:使用3D旋转非最大抑制(NMS)移除冗余边界框。
数据预处理:使用图像归一化操作,但并未使用其他数据增广。