机器学习 笔记05——特征工程之特征处理:字典特征提取、文本特征提取
目录
1、类别型特征的处理—特征编码
1.1 处理少量特征
1.2 处理大量的类别特征
1.3 字典特征提取(特征离散化) ⭐
1.4 文本特征提取(英文+中文)⭐
1.4.1 英文数据演示
1.4.2 中文特征提取演示
1.4.3 jieba分词:中文特征提取
1.4.4 Tf-idf文本特征提取
在实际应用中,数据的类型多种多样,比如文本、音频、图像、视频等。而很多机器学习算法要求输入的样本特征是数学上可计算的,因此在机器学习之前需要将不同类型的数据转换为向量表示即数据的特征表示。
特征分类:
对特征进行分类,对于不同的特征应该有不同的处理方法。
根据不同的分类方法,可以将特征分为
(1)Low level特征和High level特征。
- Low level特征——较低级别的特征,主要是原始特征,不需要或者需要非常少的人工处理和干预。例如文本特征中的词向量特征,图像特征中的像素点,用户id,商品id等。Low level特征一般维度比较高,不能用过于复杂的模型。
- High level特征——经过较复杂的处理,结合部分业务逻辑或者规则、模型得到的特征。例如人工打分,模型打分等特征,可以用于较复杂的非线性模型。
- Low level 比较针对性,覆盖面小。长尾样本的预测值主要受high level特征影响。 高频样本的预测值主要受low level特征影响。
(2)稳定特征与动态特征。
-
稳定特征——变化频率(更新频率)较少的特征
例如评价平均分,团购单价格等,在较长的时间段内都不会发生变化。 -
动态特征——更新变化比较频繁的特征,有些甚至是实时计算得到的特征
例如距离特征,2小时销量等特征。或者叫做实时特征和非实时特征。 -
针对两类特征的不同可以针对性地设计特征存储和更新方式,例如:
对于稳定特征,可以建入索引,较长时间更新一次,如果做缓存的话,缓存的时间可以较长。
对于动态特征,需要实时计算或者准实时地更新数据,如果做缓存的话,缓存过期时间需要设置的较短。
(3)二值特征、连续型特征、离散型特征、枚举特征。
-
二值特征——主要是0/1特征,即特征只取两种值:0或者1
例如用户id特征:目前的id是否是某个特定的id,词向量特征:某个特定的词是否在文章中出现等等。 -
连续型特征——取值为连续实数的特征。比如,身高175.4cm。特征取值为是0~正无穷。
-
离散性特征——取值为离散实数的特征。离散型特征又可以分为类别型和序列型
- 类别型特征:取离散值,表示没有比较关系的类型。比如,血型有 A 型、B 型、AB 型和 O 型 4 种,它们各自为一个独立类型。
- 序列型特征:取离散值,表示有比较关系的类型。比如,收入划分为为 “高”、“中”、“低”3 种类型,有比较关系。
-
枚举值特征——主要是特征有固定个数个可能值,例如今天周几,只有7个可能值:周1,周2,…,周日。
模型输入的特征通常需要数值型的,所以需要将非数值型特征转换为数值特征。 如性别、职业、收入水平、国家、汽车使用品牌等。
机器学习模型需要的数据是数字型的,因为只有数字类型才能进行计算,而我么你平时处理到的一些数据是很多是符号的,或者是中文的。所以编码是必要的,对于各种各样的特征值去编码实际上就是一个量化的过程。
1、类别型特征的处理—特征编码
类别特征,见名思义,就是用来表达一种类别或标签。
分类变量的类别通常不是数字,需要使用编码方法将这些非数字类别变为数字。即特征编码
1.1 处理少量特征
1、One-hot 编码
又称独热编码。每个特征取值对应一维特征,从而得到稀疏的特征矩阵。
一个绝对的具有k个可能类别的变量被编码为长度为k的特征向量。
如表1即为对三种水果进行编码:
| e1 | e2 | e3 | |
| apple | 1 | 0 | 0 |
| banna | 0 | 1 | 0 |
| grape | 0 | 0 | 1 |
独热编码e1,e2,e3限制条件: e1 + e2 + e3 = 1
df = pd.DataFrame({
'fruit':
['apple', 'apple', 'banna', 'banna', 'grape'],
'Rent': [10, 10, 15, 15, 20]
})
one_hot_df = pd.get_dummies(df, prefix=['fruit'])
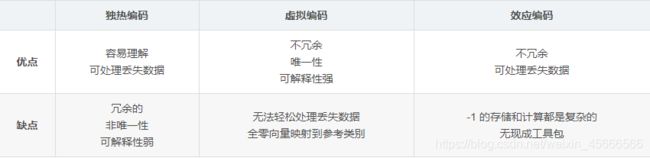
优点:
- 能够处理非数值属性。比如血型、性别等
- 一定程度上扩充了特征。
- 编码后的向量是稀疏向量,只有一位是 1,其他都是 0,可以利用向量的稀疏来节省存储空间。
- 能够处理缺失值。当所有位都是 0,表示发生了缺失。此时可以采用处理缺失值提到的高维映射方法,用第 N+1 位来表示缺失值。
缺点:
1.高维度特征会带来以下几个方面问题:
- KNN 算法中,高维空间下两点之间的距离很难得到有效的衡量;
- 逻辑回归模型中,参数的数量会随着维度的增高而增加,导致模型复杂,出现过拟合问题;
- 通常只有部分维度是对分类、预测有帮助,需要借助特征选择来降低维度。
2.决策树模型不推荐对离散特征进行独热编码,有以下两个主要原因:
- 产生样本切分不平衡问题,此时切分增益会非常小。
比如对血型做独热编码操作,那么对每个特征是否 A 型、是否 B 型、是否 AB 型、是否 O 型,会有少量样本是 1 ,大量样本是 0。
这种划分的增益非常小,因为拆分之后:
-
较小的那个拆分样本集,它占总样本的比例太小。无论增益多大,乘以该比例之后几乎可以忽略。
-
较大的那个拆分样本集,它几乎就是原始的样本集,增益几乎为零。
-
影响决策树的学习。
决策树依赖的是数据的统计信息。而独热码编码会把数据切分到零散的小空间上。在这些零散的小空间上,统计信息是不准确的,学习效果变差。
本质是因为独热编码之后的特征的表达能力较差。该特征的预测能力被人为的拆分成多份,每一份与其他特征竞争最优划分点都失败。最终该特征得到的重要性会比实际值低。
2、dummy 编码
又称虚拟编码,一个绝对的具有k个可能类别的变量被编码为长度为k-1的特征向量。
由全零向量表示参考类别.
| e1 | e2 | |
|---|---|---|
| apple | 1 | 0 |
| banna | 0 | 1 |
| grape | 0 | 0 |
dummy_df = pd.get_dummies(df, prefix=['city'], drop_first=True)3、Effect 编码
一个绝对的具有k个可能类别的变量被编码为长度为k-1的特征向量。
由全负一向量表示参考类别
| e1 | e2 | |
|---|---|---|
| apple | 1 | 0 |
| banna | 0 | 1 |
| grape | -1 | -1 |
Effect编码与虚拟编码非常相似,但是在线性回归中更容易被拟合。
独热,虚拟和效果编码非常相似。他们每个人都有优点和缺点。独热编码是多余的,它允许多个有效模型一样的问题。非唯一性有时候对解释有问题。该优点是每个特征都明显对应于一个类别。此外,失踪数据可以编码为全零矢量,输出应该是整体目标变量的平均值。
4、序号编码
序号编码一般用于处理类别间具有大小关系的数据即序列型特征。
比如成绩,可以分为高、中、低三个档次,并且存在“高>中>低”的大小关系,那么序号编码可以对这三个档次进行如下编码:高表示为 3,中表示为 2,低表示为 1,这样转换后依然保留了大小关系。
1.2 处理大量的类别特征
1.对编码不做任何事情。使用便宜的训练简单模型。在许多机器上将独热编码引入线性模型(逻辑回归或线性支持向量机)。
2.压缩编码,有两种方式
- 对特征进行哈希–在线性回归中特别常见
- bin-counting–在线性回归中与树模型都常见
特征哈希
特征哈希
bin-counting
相关介绍
1.3 字典特征提取(特征离散化) ⭐
(1) 什么是特征提取呢?
将任意数据(如文本或图像)转化为可用于机器学习的数字特征
- 将英文、字母转化成数字
- 将类别转化为数字,如男女、first,second等转化为010,001
注:特征值化是为了计算机更好的去理解数据
- 特征值的分类:
- 字典特征提取(特征离散化)
- 文本特征提取
- 图像特征提取(后边深度学习将介绍)基于rgb
特征提取API:sklearn.feature_extraction
- 对类别型数据进行转化
作用:对字典数据进行特征值化,将类别数据转化为010,001,…
API:
sklearn.feature_extraction.DictVectorizer( sparse=True, …)
- 首先实例化,再通过fit_transform进行转换
- DictVectorizer.fit_transform(X)
- X: 字典胡总和包含字典的迭代器返回值
- 返回sparse矩阵
- sparse=True:节省内存,提高读取效率,
DictVectorizer.get_feature_names() 返回类别名称 ,有时用.get_feature_names_out()
流程分析
- 实例化类DictVectorizer
- 调用fit_transform方法输入数据并转换(注意返回格式)
演示:我们对以下数据做特征提取
[{'city': '北京','temperature':100},
{'city': '上海','temperature':60},
{'city': '深圳','temperature':30}] #城市是一个类别,对其进行数字特征提取
from sklearn.feature_extraction import DictVectorizer
'''
字典特征提取
Return: feature_name , trans_data
'''
def dict_demo():
data = [{'city': '北京','temperature':100},
{'city': '上海','temperature':60},
{'city': '深圳','temperature':30}]
#字典特征提取
#1.实例化
transfer = DictVectorizer(sparse=False)#数据量小时:sparse=False直接给出矩阵,sparse=True给出非零的坐标
#2.调用fit_transform
trans_data = transfer.fit_transform(data)
print('特征名字是:\n',transfer.get_feature_names_out()) #.get_feature_names() 也可以
print(trans_data)
if __name__ == '__main__':
dict_demo()
输出结果:
特征名字是:
['city=上海' 'city=北京' 'city=深圳' 'temperature']
[[ 0. 1. 0. 100.]
[ 1. 0. 0. 60.]
[ 0. 0. 1. 30.]]总结:对于特征中存在类别信息的我们都会做one-hot编码处理
男女、肤色、头发长短等等
1.4 文本特征提取(英文+中文)⭐
作用:对文本数据进行特征值化
注意:
- 在中文文本特征提取之前,需要对中文句子(文章)进行分词(jieba)
- 中文、英文里面依旧可以使用停用词,进行词语的限制
API:
- sklearn.feature_extraction.text.CountVectorizer(stop_words=[])
- stop_words=[]:不需要统计的词
- 返回词频矩阵
- CountVectorizer.fit_transform(X)
- X: 文本或者包含文本字符串的可迭代对象
- 返回值:返回sparse矩阵,但是没有sparse参数
- CountVectorizer.get_feature_names() 返回值:单词列表
注意:单个字母和标点符号不做统计
流程分析
- 实例化类CountVectorizer
- 调用fit_transform方法输入数据并转换(注意返回格式,利用toarray()进行sparse矩阵转换array数组)
1.4.1 英文数据演示:
对以下数据进行特征提取
['life is short,i like python',
'life is too long,i dislike python'] #统计一下所有值的数目
'''
对文本进行特征提取—英文
return:None
'''
from sklearn.feature_extraction.text import CountVectorizer
def english_count_text_demo():
data = ['life is is short,i like python',
'life is too long,i dislike python']
#1.实例化
transfer = CountVectorizer(stop_words=['is'])#不统计is次数
#transfer = CountVectorizer(sparse=False) #报错,没有sparse参数
#2.调用fit_transform
transfer_data = transfer.fit_transform(data)
print('类别名称:\n',transfer.get_feature_names_out())
print('直接输出数据:\n', transfer_data)
#不想要看sparse矩阵,怎么办? 没有sparse参数
print('文本特征抽取结果',transfer_data.toarray())
if __name__ == '__main__':
english_count_text_demo()
输出结果:
类别名称:
['dislike' 'life' 'like' 'long' 'python' 'short' 'too']
直接输出数据:
(0, 1) 1
(0, 5) 1
(0, 2) 1
(0, 4) 1
(1, 1) 1
(1, 4) 1
(1, 6) 1
(1, 3) 1
(1, 0) 1
[[0 1 1 0 1 1 0]
[1 1 0 1 1 0 1]]1.4.2 中文特征提取演示:
对以下数据进行特征提取
'人生 苦短,我 喜欢 python','生活 太长久,我不 喜欢 python'
'''
对文本进行特征提取—中文
return:None
'''
from sklearn.feature_extraction.text import CountVectorizer
def chinese_count_text_demo():
data = ['人生 苦短,我 喜欢 python','生活 太长久,我不 喜欢 python']
#1.实例化
transfer = CountVectorizer(stop_words=[])
#2.调用fit_transform
transfer_data = transfer.fit_transform(data)
print('类别名称:\n',transfer.get_feature_names_out())
print('直接输出数据:\n', transfer_data)
print('文本特征抽取结果',transfer_data.toarray())
if __name__ == '__main__':
#english_count_text_demo()
chinese_count_text_demo()
输出结果:
类别名称:
['python' '人生' '喜欢' '太长久' '我不' '生活' '苦短']
直接输出数据:
(0, 1) 1
(0, 6) 1
(0, 2) 1
(0, 0) 1
(1, 2) 1
(1, 0) 1
(1, 5) 1
(1, 3) 1
(1, 4) 1
文本特征抽取结果 [[1 1 1 0 0 0 1]
[1 0 1 1 1 1 0]]
但是中文数据处理时,是按照空格进行划分的,但是在中文的习惯中词之间不加空格,怎么解决呢?如何自动划分词?
1.4.3 jieba分词:中文特征提取
- jieba.cut()
- 返回词语组成的生成器
- 需要安装下jieba库
如何用jieba对中文字符串进行分词
import jieba
'''
中文分词
'''
def cut_word(sen):
# print(list(jieba.cut(sen))) #将对象强制转换为列表,但是应该一句话用空格分开
text = ' '.join ( list(jieba.cut(sen)))
return text
if __name__ == '__main__':
cut_word('我喜欢中国,你喜欢什么国家?')
中文特征提取:使用jieba分词
from sklearn.extraction import CountVectorizer
def text_chinese_count_demo2():
data = [
'世上没有白费的努力,也没有碰巧的成功',
'一切无心插柳,其实都是水到渠成',
'人生没有白走的路,也没有白吃的苦',
'跨出去的每一步,都是未来的基石与铺垫'
]
list = []
for temp in data:#循环数据中的每一句话
#print(temp)
list.append(cut_word(temp))
print(list)
#1.实例化
transfer = CountVectorizer(stop_words=['回复','奶粉'])
#2.调用fit_transform
transfer_data = transfer.fit_transform(list)
print(transfer.fit_feature_names_out())
print(transfer_data.toarray())
if __name__ == '__main__':
text_chinese_count_demo2()
1.4.4 Tf-idf文本特征提取
主要思想:如果某个词或短语在一篇文章中出现的概率高,在其他文章中出现概率少,则认为这个词或者短语具有很好的分类能力,适合用来分类。
TF-IDF的作用:用以评估一字词对于某一个文件集或者一个语料库的其中一份文件的重要程度。
公式:
- TF ---- 词频(term frequency):指某一个给定词语在该文件中出现的频率
- IDF ---- 逆向文档频率(inverse document frequency):是一个词语普遍重要性的度量,某一个特征词语的idf,可以由总文件数除以包含该词语之文件的数目,再将得到的熵取以10为低的对数得到
![]()
举例:
假如某一篇文章中总词语数是100个,“非常”出现了5词,那么词频就是0.05;
而计算文件频率(IDF)的方法是以文件集的总数,除以出现“非常”一词的文件数,所以,如果“非常”在10000份文件中出现过,而文件总数是10,000,000的话,其逆向文件频率就是lg(10,000,000/ 10000) = 3。
最后“非常”对于这篇文档的tf-idf的分数就是0.05 * 3 = 0.15
Tf-idf 重要性
分类机器学习算法进行文章分类中前期数据处理方法
API
- sklearn.feature_extraction.text.TfidfVectorizer
- 在CountVectorizer中能使用的,在TfidfVectorizer中同样适用
4.1 案例
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba
def cut_word(text):
text = ' '.join(list(jieba.cut(text)))
return text
def text_chinese_tfidf_demo():
'''对中文进行特征提取'''
data = [
'世上没有白费的努力,也没有碰巧的成功',
'一切无心插柳,其实都是水到渠成',
'人生没有白走的路,也没有白吃的苦',
'跨出去的每一步,都是未来的基石与铺垫'
]
#将原始数据转化为分好词的形式
text_list = []
for sent in data:
text_list.append(cut_word(sent))
print(text_list)
#1.实例化一个转换器类
transfer = TfidfVectorizer(stop_words=['是的'])
#2.调用fit_transform
data = transfer.fit_transform(text_list)
print('文本特征提取的结果:\n', data.toarray())
print('返回特征名字:\n', transfer.get_feature_names_out())
if __name__ == '__main__':
text_chinese_tfidf_demo()