vue 在线访问word,excel,pdf 文件以及打印
git 项目代码
一.pdf
1. vue-pdf
安装
npm i --save vue-pdf
语法
在组件种使用
import pdf from 'vue-pdf'
pdf.createLoadingTask(url,httpHeaders);
参数: url(所请求的接口),headers(请求头信息)
或者url 是pdf 的链接地址案例
(1)简单使用
(3)请求接口 或者 是外部链接的pdf
(4)分页
上一页
{{ currentPage }} / {{ numPages }}
下一页
(5)vue-pdf 打印

4. HTML网页生成PDF格式
大概思路 => 就是将页面转换成图片格式 .然后通过图片的base64码 生成PDF格式 保存到本地。
需要两个插件:
npm install --save html2canvas
npm install jspdf --save
使用
(1).封装组件
// 导出页面为PDF格式
import html2Canvas from 'html2canvas'
import JsPDF from 'jspdf'
export default {
install(Vue, options) {
Vue.prototype.getPdf = function (id, title) {
html2Canvas(document.querySelector(`#${id}`), {
allowTaint: true
}).then(function (canvas) {
let contentWidth = canvas.width
let contentHeight = canvas.height
let pageHeight = contentWidth / 592.28 * 841.89
let leftHeight = contentHeight
let position = 0
let imgWidth = 595.28
let imgHeight = 592.28 / contentWidth * contentHeight
let pageData = canvas.toDataURL('image/jpeg', 1.0)
let PDF = new JsPDF('', 'pt', 'a4')
if (leftHeight < pageHeight) {
PDF.addImage(pageData, 'JPEG', 0, 0, imgWidth, imgHeight)
} else {
while (leftHeight > 0) {
PDF.addImage(pageData, 'JPEG', 0, position, imgWidth, imgHeight)
leftHeight -= pageHeight
position -= 841.89
if (leftHeight > 0) {
PDF.addPage()
}
}
}
PDF.save(title + '.pdf')
}
)
}
}
}(2).注册
main.js
import htmlToPdf from '@/utils/htmlToPdf'
Vue.use(htmlToPdf)(3).组件
vue HTML网页生成PDF格式
大概思路 => 就是将页面转换成图片格式 .然后通过图片的base64码
生成PDF格式 保存到本地。
二.word
Mammoth 旨在将 word文档 将其转换为 HTML。Mammoth 的目标是通过使用文档中的语义信息并忽略其他细节来生成简单干净的 HTML。
Mammoth.js 这个库同时支持 Node.js 和浏览器两个平台。
安装
npm install --save mammoth
常用的 API
1. mammoth.convertToHtml(input, options:把源文档转换为 HTML 文档
mammoth.convertToHtml(input, options) 将源文档转换为 HTML input: 描述源文档的对象。 在
node.js 上,支持以下输入: {path: path},其中 path 是. docx 文件的路径。 {buffer:
buffer},其中 buffer 是包含. docx 文件的node.js 缓冲区。 在浏览器中,支持以下输入:
{arrayBuffer: arrayBuffer},其中 arrayBuffer 是包含. docx 文件的array 缓冲区。
options ( 可选): 转换的选项。 浏览器表示支持arrayBuffer 转换也仅仅支持docx
只能预览.docx文件不能预览doc文件
2. mammoth.convertToMarkdown(input, options):把源文档转换为 Markdown 文档。这个方法与 convertToHtml 方法类似,区别就是返回的 result 对象的 value 属性是 Markdown 而不是 HTML。
3. mammoth.extractRawText(input):提取文档的原始文本。这将忽略文档中的所有格式。每个段落后跟两个换行符。注意
1.docx可以解析,doc 不行
2.只能适应于 结构简单word文件
docx使用的结构和HTML的结构之间存在很大的不匹配,这意味着转换不太可能适合更复杂的文档。如果只使用样式对文档进行语义标记,那么Mammoth的效果最好。
eg:标题,图片,粗体、斜体、下划线、删除线、上标和下。。。。
3. 直接访问本地的文件地址,或是线上的地址,如下操作,会报错”Could not find file in options “,不懂是为啥,有待研究
mammoth.convertToHtml({path: "E:\gitProgram\gitee\vue-pdf-word\public\words.docx"})
.then(function (resultObject) {
vm.vHtml =resultObject.value;
});
.done();4. 服务端请求接口下载文件,在放到mammoth.convertToHtml({arrayBuffer: new Uint8Array(xhr.response)})转换得到值
案例
(1)开发方式:服务端请求接口下载文件,在放到mammoth.convertToHtml({arrayBuffer: new Uint8Array(xhr.response)})转换得到值

(2).官网提供的操作
input【type=“file”】

三.excel
(一) 理解
由SheetJS出品的js-xlsx是一款非常方便的只需要纯JS即可读取和导出excel的工具库,功能强大,支持格式众多,支持xls、xlsx、ods(一种OpenOffice专有表格文件格式)等十几种格式。
官网
(二) 安装
npm install -S xlsx //导出excel
npm install -S xlsx-style // 设置excel的样式
npm install -S file-saver //用来生成文件的web应用程序
(三) 使用
import FileSaver from 'file-saver';
import * as XLSX from 'xlsx';
import XLSXStyle from 'xlsx-style';
(四) 兼容
支持 ES5 的浏览器,如果是比较老的浏览器,需要引入 polyfill
(五) 常用api
(1)读取excel XLSX.read(data, {type: type})
读取excel主要是通过XLSX.read(data, {type: type});方法来实现,返回一个叫WorkBook的对象,type主要取值如下:
base64: 以base64方式读取;
binary: BinaryString格式(byte n is data.charCodeAt(n))
string: UTF8编码的字符串;
buffer: nodejs Buffer;
array: Uint8Array,8位无符号数组;
file: 文件的路径(仅nodejs下支持);(2)详解 workbook
可以理解为XLSX对excel文件描述的一个对象,可通过 XLSX.utils.book()来创建,该方法返回workbook对象
构建workbook对象
let elt = document.getElementById('exportTable');
let wb = XLSX.utils.table_to_book(elt, {
sheet: 'Sheet JS',
raw: true
});
1. Workbook Object
workbook里面有什么东西呢,我们打印出来看一下:
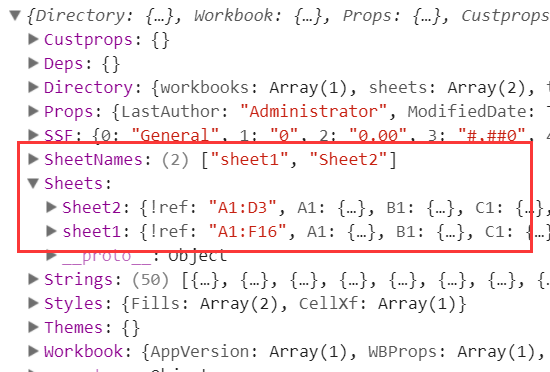
可以看到,SheetNames里面保存了所有的sheet名字,然后Sheets则保存了每个sheet的具体内容(我们称之为Sheet Object)。每一个sheet是通过类似A1这样的键值保存每个单元格的内容,我们称之为单元格对象(Cell Object):

2. Worksheet对象(Sheet Object)
每一个Sheet Object表示一张表格,只要不是!开头的都表示普通cell,否则,表示一些特殊含义,具体如下:
sheet['!ref']:表示excel的渲染区域 (所有单元格的范围),例如从A1到E3则记录为A1:E3;

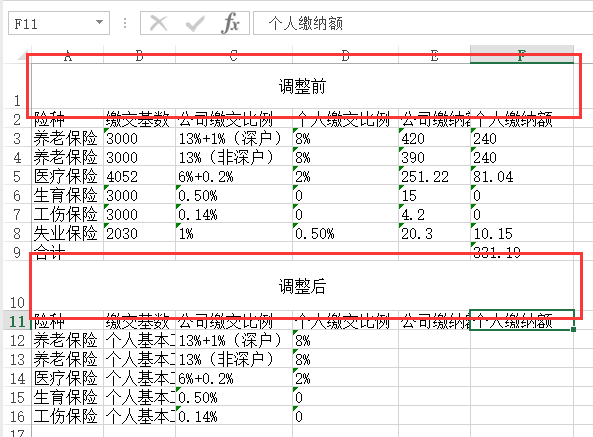
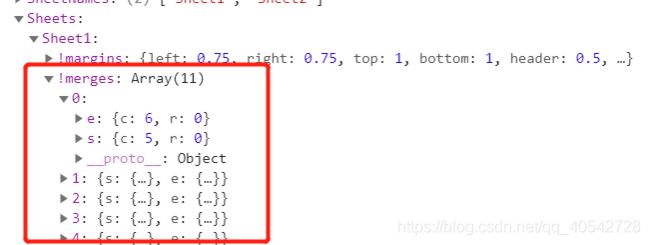
sheet[!merges]:合并单元格 : 存放一些单元格合并信息,是一个数组,每个数组由包含s和e构成的对象组成,s表示开始,e表示结束,r表示行,c表示列;
关于单元格合并,看懂下面这张图基本上就没问题了:

结果如下:
分析::{c:0,r:0} 表示第一行 e:{c:5:r:0} 第6列
- sheet['!cols]: 设置列宽(列属性对象的数组)列宽实际上是以规范化的方式存储在文件中的,以“最大位数宽度”(呈示的数字0-9的最大宽度,以像素为单位)衡量
// 1. 获取数据(引用 HTML 表格)
let elt = document.getElementById('exportTable');
// 2. 提取数据(从表中创建一个工作簿对象)
let wb = XLSX.utils.table_to_book(elt, {
sheet: 'Sheet JS',
raw: true
});let range = XLSX.utils.decode_range(wb.Sheets['Sheet JS']['!ref']);
for (let C = range.s.c; C <= range.e.c; ++C) {
for (let R = range.s.r; R <= range.e.r; ++R) {
//每个单元格的样式 固定 宽度
wb.Sheets['Sheet JS']['!cols'].push({
wpx: 150
});
}
}
- sheet['!rows]: 设置行高:[{hpx:40}]
- !printHeader:打印的时候要重复的行,比如 table 的表头信息 [1:1] // 重复第一行
3. 单元格对象
可以使用单元格对象来实现对单元格样式对修改,最终导出是一定要使用xlsx-style的方法导出
单元格样式
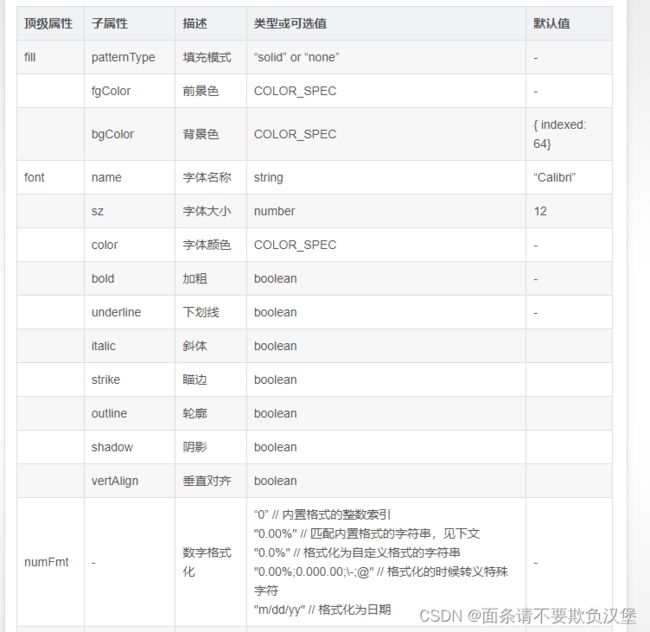
在 xlsx-style 中,单元格样式共有五个顶级的属性,分别是:fill, font, numFmt, alignment 和 border

let range = XLSX.utils.decode_range(wb.Sheets['Sheet JS']['!ref']);
for (let C = range.s.c; C <= range.e.c; ++C) {
for (let R = range.s.r; R <= range.e.r; ++R) {
// 7. 每个单元格的样式
if (wb.Sheets['Sheet JS'][cell_ref]) {
// 每个单元格的样式
wb.Sheets['Sheet JS'][cell_ref].s = {
font: {
// 字体设置
sz: 12,
bold: false,
color: {
rgb: '000000' // 十六进制,不带#
}
},
alignment: {
// 文字居中
horizontal: 'center',
vertical: 'center',
wrapText: true // 换行
},
border: {
// 设置边框
top: {
style: 'thin'
},
bottom: {
style: 'thin'
},
left: {
style: 'thin'
},
right: {
style: 'thin'
}
}
};
}
}
}4. 读取workbook
普通方法:
// 读取 excel文件
function outputWorkbook(workbook) {
var sheetNames = workbook.SheetNames; // 工作表名称集合
sheetNames.forEach(name => {
var worksheet = workbook.Sheets[name]; // 只能通过工作表名称来获取指定工作表
for(var key in worksheet) {
// v是读取单元格的原始值
console.log(key, key[0] === '!' ? worksheet[key] : worksheet[key].v);
}
});
}
根据!ref确定excel的范围,再根据!merges确定单元格合并(如果有),最后输出整个table,比较麻烦,幸运的是,插件自身已经写好工具类XLSX.utils给我们直接使用,无需我们自己遍历,工具类输出主要包括如下:

有些不常用,常用的主要是:
XLSX.utils.sheet_to_csv:生成CSV格式
XLSX.utils.sheet_to_txt:生成纯文本格式
XLSX.utils.sheet_to_html:生成HTML格式
XLSX.utils.sheet_to_json:输出JSON格式常用的主要是sheet_to_csv或者sheet_to_html,转csv的话会忽略格式、单元格合并等信息,所以复杂表格可能不适用。转html的话会保留单元格合并,但是生成的是代码,而不是
这里写一个采用转csv方式输出结果的简单示例,可点击这里查看在线DEMO:
function readWorkbook(workbook)
{
var sheetNames = workbook.SheetNames; // 工作表名称集合
var worksheet = workbook.Sheets[sheetNames[0]]; // 这里我们只读取第一张sheet
var csv = XLSX.utils.sheet_to_csv(worksheet);
document.getElementById('result').innerHTML = csv2table(csv);
}
// 将csv转换成简单的表格,会忽略单元格合并,在第一行和第一列追加类似excel的索引
function csv2table(csv)
{
var html = '';
var rows = csv.split('\n');
rows.pop(); // 最后一行没用的
rows.forEach(function(row, idx) {
var columns = row.split(',');
columns.unshift(idx+1); // 添加行索引
if(idx == 0) { // 添加列索引
html += '';
for(var i=0; i';
}
html += ' ';
}
html += '';
columns.forEach(function(column) {
html += ''+column+' ';
});
html += ' ';
});
html += '
';
return html;
}(六)某小点
(1)大多数涉及表格和数据的场景
//1. 获取数据:引用 HTML 表格
var table_elt = document.getElementById("my-table-id");// 2.提取数据(从表中创建一个工作簿对象)
var workbook = XLSX.utils.table_to_book(table_elt);// 3.处理数据:从生成汇总统计数据到清理数据记录,这一步是问题的核心。
var ws = workbook.Sheets["Sheet1"];
XLSX.utils.sheet_add_aoa(ws, [["Created "+new Date().toISOString()]], {origin:-1});// 4. 发布数据:电子表格文件可以上传到服务器或本地写入。数据可以在 HTML TABLE 或数据网格中呈现给用户
XLSX.writeFile(workbook, "Report.xlsx");注意:使用XLSXStyle时
// 文件存在本地
var wopts = {
bookType: 'xlsx', // 要生成的文件类型
bookSST: false,
type: 'binary'
};
var wbout = XLSX.write(wb, wopts);
(2)单元格转化方法(由A1转化成{c:C, r:R},c为列,r为行)
excel中 列以 A开始,行以1开始,在XLSX中转化为数值后行与列都是0开始
- encode_cell / decode_cell 转化单元格号
由于解析的单元格是A1形式,无法直接获取行列,需要转化为XLSX中的数值(如:{c:0,r:0})
XLSX.utils.encode_cell({c:0,r:0}) // A1 XLSX.utils.decode_cell('A2') //{c: 0, r: 1}
-
encode_row / decode_row转化行号 =>r的值
XLSX.utils.encode_row(1) // 2 XLSX.utils.decode_row('1') // 0
-
encode_col / decode_col转化列号 =>c的值
console.log(XLSX.utils.encode_col(1)) // B console.log(XLSX.utils.decode_col('A')) // 0
(3)单元格合并(范围)
encode_range / decode_range 转化表格范围 (如A1:B2 互相转化 {s: {c: 0, r: 0},e: {c: 1, r: 1}})
在解析出来的数据中,单元格合并由属性 !merges 表示(s:start,e:end)
遍历单元格范围(range={s:{c:C, r:R}, e:{c:C, r:R}} )
for(var R = range.s.r; R <= range.e.r; ++R) {
for(var C = range.s.c; C <= range.e.c; ++C) {
var cell_address = {c:C, r:R};
/* if an A1-style address is needed, encode the address */
var cell_ref = XLSX.utils.encode_cell(cell_address);
}
}
table中 合并行和列
let range = XLSX.utils.decode_range(wb.Sheets['Sheet JS']['!ref']);
for (let C = range.s.c; C <= range.e.c; ++C) {
for (let R = range.s.r; R <= range.e.r; ++R) {
let cell = { c: C, r: R };
let cell_ref = XLSX.utils.encode_cell(cell);
if (wb.Sheets['Sheet JS']['!merges']) {
// 合并单元格判断
wb.Sheets['Sheet JS']['!merges'].forEach(item => {
if (item.e.r == item.s.r && item.e.c != item.s.c) {
// 列合并
let R = item.s.r;
for (let i = item.s.c; i <= item.e.c; i++) {
let cell_1 = { c: i, r: R };
let cell_ref1 =
XLSX.utils.encode_cell(cell_1);
if (!wb.Sheets['Sheet JS'][cell_ref1]) {
wb.Sheets['Sheet JS'][cell_ref1] = {
t: 's',
v: ''
};
}
}
} else if (
item.e.c == item.s.c &&
item.e.r != item.s.r
) {
// 行合并
let C = item.s.c;
for (let i = item.s.r; i <= item.e.r; i++) {
let cell2 = { c: C, r: i };
let cell_ref2 =
XLSX.utils.encode_cell(cell2);
if (!wb.Sheets['Sheet JS'][cell_ref2]) {
wb.Sheets['Sheet JS'][cell_ref2] = {
t: 's',
v: ''
};
}
}
}
});
}
}
}(4)拆分单元格
拆分单元格:根据已知要拆分位置,转为坐标然后遍历"!merges"数组,删除匹配的项目就完成已合并表格的删除(如:合计占了多行, 判断excle里的坐标 行数 是不是大于 实际行数,如果大于的话,就拆了)

// 1. 获取数据(引用 HTML 表格)
let elt = document.getElementById('exportTable');
// 2. 提取数据(从表中创建一个工作簿对象)
let wb = XLSX.utils.table_to_book(elt, {
sheet: 'Sheet JS',
raw: true
});var row_count = 0;
let ref = wb.Sheets['Sheet JS']['!ref'];
let s_e = ref.split(':');
row_count = this.getRowFromId(s_e[1]) + 1;
// 对特殊数据的拆分(如:合计 总数量)
let merges = wb.Sheets['Sheet JS']['!merges'];
if (merges) {
for (var j = 0; j < merges.length; j++) {
var srcmerge = merges[j];
// 获取最后一行的r的值
var row = XLSX.utils.encode_row(row_count - 2);
if (srcmerge.s.r == row && srcmerge.e.r > row) {
//结束的行数 = 开始的行数
srcmerge.e.r = Number(row);
}
}
}
// 获取excel行的行数
getRowFromId(str) {
var reg = /(\d+)/g;
var result = reg.exec(str);
return parseInt(result[0]) - 1;
},

(5)插入/删除行和列
首先扩展行和列,直接操作"!ref"字段,然后把所选中行列之后的数据全部后移。
简单的列子,删除最后一列
// 1. 获取数据(引用 HTML 表格)
let elt = document.getElementById('exportTable');
// 2. 提取数据(从表中创建一个工作簿对象)
let wb = XLSX.utils.table_to_book(elt, {
sheet: 'Sheet JS',
raw: true
});
// 3. 删除最后一列
var row_count = 0;
var colums_count = 0;
let ref = wb.Sheets['Sheet JS']['!ref'];
let s_e = ref.split(':');
row_count = this.getRowFromId(s_e[1]) + 1;
colums_count = this.getIndexFromId(s_e[1]) + 1;
wb.Sheets['Sheet JS']['!ref'] =
'A1:' + this.letters[colums_count - 2] + String(row_count);
// 获取excel列的坐标
getIndexFromId(str) {
var reg = /([A-Z]+)/g;
var result = reg.exec(str);
return this.letters.indexOf(result[0]);
},
// 获取excel行的行数
getRowFromId(str) {
var reg = /(\d+)/g;
var result = reg.exec(str);
return parseInt(result[0]) - 1;
},
注意:如要看插入/删除行和列 请看:sheetjs前段操作excel,点击合并拆分表格增删行列功能实现
(七)案例
(1)把html中的table 导出excel
index.vue
导出
import { tableExcel } from '@/mixins/tableExcel.js';
export default {
mixins: [tableExcel],
data() {
return {
// 遮罩层
loading: true,
total: 0,
tableList: [],//table的数据
tableHead: [],//表头的字段
queryParams: {
pageNum: 1,
pageSize: 50,
starTime: undefined,
endTime: undefined
},
};
},
}mixins/tableExcel.js
import FileSaver from 'file-saver';
import { Loading } from 'element-ui';
import * as XLSX from 'xlsx';
import XLSXStyle from 'xlsx-style';
let downloadLoadingInstance;
export const tableExcel = {
data() {
return {
pageLoading: false,
// EXCEL 列的坐标
letters: [
'A',
'B',
'C',
'D',
'E',
'F',
'G',
'H',
'I',
'J',
'K',
'L',
'M',
'N',
'O',
'P',
'Q',
'R',
'S',
'T',
'U',
'V',
'W',
'X',
'Y',
'Z',
'AA',
'AB',
'AC',
'AD',
'AE',
'AF',
'AG',
'AH',
'AI',
'AJ',
'AK',
'AL',
'AM',
'AN',
'AO',
'AP',
'AQ',
'AR',
'AS',
'AT',
'AU',
'AV',
'AW',
'AX',
'AY',
'AZ',
'BA',
'BB',
'BC',
'BD',
'BE',
'BF',
'BG',
'BH',
'BI',
'BJ',
'BK',
'BL',
'BM',
'BN',
'BO',
'BP',
'BQ',
'BR',
'BS',
'BT',
'BU',
'BV',
'BW',
'BX',
'BY',
'BZ',
'CA',
'CB',
'CC',
'CD',
'CE',
'CF',
'CG',
'CH',
'CI',
'CJ',
'CK',
'CL',
'CM',
'CN',
'CO',
'CP',
'CQ',
'CR',
'CS',
'CT',
'CU',
'CV',
'CW',
'CX',
'CY',
'CZ'
]
};
},
methods: {
// 获取excel列的坐标
getIndexFromId(str) {
var reg = /([A-Z]+)/g;
var result = reg.exec(str);
return this.letters.indexOf(result[0]);
},
// 获取excel行的行数
getRowFromId(str) {
var reg = /(\d+)/g;
var result = reg.exec(str);
return parseInt(result[0]) - 1;
},
// 对数据的处理 导出excel
excelFn(fileName) {
// 1. 获取数据(引用 HTML 表格)
let elt = document.getElementById('exportTable');
// 2. 提取数据(从表中创建一个工作簿对象)
let wb = XLSX.utils.table_to_book(elt, {
sheet: 'Sheet JS',
raw: true
});
// 3. 删除多出来的最后一列
var row_count = 0;
var colums_count = 0;
let ref = wb.Sheets['Sheet JS']['!ref'];
let s_e = ref.split(':');
row_count = this.getRowFromId(s_e[1]) + 1;
colums_count = this.getIndexFromId(s_e[1]) + 1;
wb.Sheets['Sheet JS']['!ref'] =
'A1:' + this.letters[colums_count - 2] + String(row_count);
// 4. 对特殊数据的 拆分合计
let merges = wb.Sheets['Sheet JS']['!merges'];
if (merges) {
for (var j = 0; j < merges.length; j++) {
var srcmerge = merges[j];
// 最后一行
var row = XLSX.utils.encode_row(row_count - 2);
if (srcmerge.s.r == row && srcmerge.e.r > row) {
srcmerge.e.r = Number(row);
}
}
}
console.log(wb);
// 5. 合并单元格
let range = XLSX.utils.decode_range(wb.Sheets['Sheet JS']['!ref']);
for (let C = range.s.c; C <= range.e.c; ++C) {
for (let R = range.s.r; R <= range.e.r; ++R) {
let cell = { c: C, r: R };
let cell_ref = XLSX.utils.encode_cell(cell);
if (wb.Sheets['Sheet JS']['!merges']) {
// 合并单元格判断
wb.Sheets['Sheet JS']['!merges'].forEach(item => {
if (item.e.r == item.s.r && item.e.c != item.s.c) {
// 列合并
let R = item.s.r;
for (let i = item.s.c; i <= item.e.c; i++) {
let cell_1 = { c: i, r: R };
let cell_ref1 =
XLSX.utils.encode_cell(cell_1);
if (!wb.Sheets['Sheet JS'][cell_ref1]) {
wb.Sheets['Sheet JS'][cell_ref1] = {
t: 's',
v: ''
};
}
}
} else if (
item.e.c == item.s.c &&
item.e.r != item.s.r
) {
// 行合并
let C = item.s.c;
for (let i = item.s.r; i <= item.e.r; i++) {
let cell2 = { c: C, r: i };
let cell_ref2 =
XLSX.utils.encode_cell(cell2);
if (!wb.Sheets['Sheet JS'][cell_ref2]) {
wb.Sheets['Sheet JS'][cell_ref2] = {
t: 's',
v: ''
};
}
}
}
});
}
// 6. 每个单元格的样式 固定 宽度
wb.Sheets['Sheet JS']['!cols'].push({
wpx: 150
});
// 7. 每个单元格的样式
if (wb.Sheets['Sheet JS'][cell_ref]) {
// 每个单元格的样式
wb.Sheets['Sheet JS'][cell_ref].s = {
font: {
// 字体设置
sz: 12,
bold: false,
color: {
rgb: '000000' // 十六进制,不带#
}
},
alignment: {
// 文字居中
horizontal: 'center',
vertical: 'center',
wrapText: true // 换行
},
border: {
// 设置边框
top: {
style: 'thin'
},
bottom: {
style: 'thin'
},
left: {
style: 'thin'
},
right: {
style: 'thin'
}
}
};
}
}
}
// 8. 文件存在本地
var wopts = {
bookType: 'xlsx', // 要生成的文件类型
bookSST: false, // 是否生成Shared String Table,官方解释是,如果开启生成速度会下降,但在低版本IOS设备上有更好的兼容性
type: 'binary'
};
var wbout = XLSXStyle.write(wb, wopts); // 一定要用XLSXStyle不要用XLSX,XLSX是没有格式的!
// 9. 文件存在本地
FileSaver.saveAs(
new Blob([this.s2ab(wbout)], {
type: 'application/octet-stream'
}),
`${fileName}_${new Date().getTime()}.xlsx`
);
setTimeout(() => {
downloadLoadingInstance.close();
}, 1000);
},
// 对数据的处理
s2ab(s) {
var buf = new ArrayBuffer(s.length);
var view = new Uint8Array(buf);
for (var i = 0; i != s.length; ++i) {
view[i] = s.charCodeAt(i) & 0xff;
}
return buf;
},
// 合计
getSummaries(param) {
const { columns, data } = param;
const sums = [];
columns.forEach((column, index) => {
if (index === 0) {
sums[index] = '合计';
return;
}
const values = data.map(item => item[column.property]);
if (
!values.every(
value => isNaN(value) || this.$lodash.isNull(value)
)
) {
sums[index] = values.reduce((prev, curr) => {
const value = Number(curr);
if (!isNaN(value)) {
return Number(prev) + Number(curr);
} else {
return prev;
}
}, 0);
} else {
sums[index] = '--';
}
});
return sums;
},
/** 导出按钮操作 */
handleExport(fileName) {
if (this.tableList.length == 0) {
this.$message({
message: '列表暂无数据,不能执行导出',
type: 'error'
});
return false;
}
downloadLoadingInstance = Loading.service({
text: '正在下载数据,请稍候',
spinner: 'el-icon-loading',
background: 'rgba(0, 0, 0, 0.7)'
});
this.$nextTick(async () => {
await this.excelFn(fileName);
});
}
}
};
点击导出 得到的效果

(2)获取接口中的excel
excel

遇到问题
1. 报错 TypeError: Cannot read properties of undefined (reading ‘utils‘)
解决:把import XLSX from 'xlsx'变成import * as XLSX from 'xlsx'
2. npm i xlsx-style安装完在使用的时候会报错
解决:在vue.config.js
chainWebpack(config) {
config.externals({ './cptable': 'var cptable' });
}参考材料
如何使用JavaScript实现纯前端读取和导出excel文件
sheetjs前段操作excel,点击合并拆分表格增删行列功能实现
四 打印
监听打印预览对话框
//定义打印前事件
var beforePrint = function () {
console.log("打印前");
};
//定义打印后事件
var afterPrint = () => {
console.log("打印后");
};
//监听window状态
if (window.matchMedia) {
var mediaQueryList = window.matchMedia("print");
//为印添加事件
mediaQueryList.addListener(function (mql) {
if (mql.matches) {
beforePrint();
} else {
afterPrint();
}
});
}批量打印
(1) 打开新窗口的形式window.open("black.html")
批量打印
//批量打印功能
async gprint() {
let _this = this;
await this.createDIV("pdfdJS", "pdfdImg");
const loadingBatchPrint = this.$loading({
lock: true,
text: "正在打印中...",
spinner: "el-icon-loading",
background: "rgba(0, 0, 0, 0.7)",
});
await _this.printEventList();
await _this.handleQuery();
loadingBatchPrint.close();
},
// 批量打印
async printEventList() {
let _this = this;
try {
//1. 获取nextID
const base64 = await nextPrint();
if (base64.code == 402) {
this.$message({
showClose: true,
message: "批量打印完成",
type: "success",
});
return false
} else if (base64.code !== 200) {
throw new Error(base64.msg);
}
//2 获取图片 base64 地址
const printRes = await fp_imgPrint(base64.img);
if (printRes.code !== 200) {
throw new Error(printRes.msg);
}
// 3. 调浏览器打印
await this.plPrint(printRes);
} catch (err) {
let { message } = err;
if (!message.includes("timeout")) {
this.$message({
showClose: true,
message: err,
type: "error",
});
}
return;
}
},
//批量打印,没有安装httpserver的情况
plPrint(printRes) {
let box = document.getElementById("pdfdImg");
box.src = "data:image/jpg;base64," + printRes.msg;
this.$nextTick(() => {
box.onload = () => {
this.doPrint();
};
});
},
// 浏览器打印
doPrint() {
//根据div标签ID拿到div中的局部内容
var jubuData = document.getElementById("pdfdJS").innerHTML;
// 将打印的区域赋值给新窗口body,进行打印
const newWindow = window.open("black.html");
newWindow.document.write(jubuData);
newWindow.window.print();
newWindow.window.close(); // 打印完成后关闭后新窗口
this.gprint();
return false;
},
/** 消除dom */
/**
* @param father 父
* @param ownId 删除的div id
*/
createDIV(father, ownId) {
let box = document.getElementById(father);
document.getElementById("pdfdImg").remove();
let ple = document.createElement("img");
ple.setAttribute("id", "pdfdImg");
ple.setAttribute("ref", "pdfdImg");
ple.style.width = "100%";
box.appendChild(ple);
},(2)采用print-js
onPrintDialogClose 监听浏览器对话框关闭事件
打印
let loadingBatchPrint = "";
//批量打印操作
async batchPrintHandle() {
pageLoading = this.setLoading("打印数据加载中...");
let result = await this.getDqrList();
if (result.data.length > 0) {
// 获取批量打印图片数据
let data = filterArr.map((item) => {
return "data:image/jpg;base64," + item;
});
//打印
await this.printHandle(data);
}
},
// 设置通用loading提示
setLoading(text) {
return this.$loading({
lock: true,
text: text,
spinner: "el-icon-loading",
background: "rgba(0, 0, 0, 0.7)",
});
},
// 打印所有
async printHandle(imgArr) {
document.getElementById("pdfdJS").innerHTML = "";
await this.batchCreateDIV("pdfdJS", imgArr);
await this.prinkFn();
},
/**
* @param father 父
* @param ownId 删除的div id
*/
batchCreateDIV(father, imgArr) {
let box = document.getElementById(father);
if (imgArr.length > 0) {
imgArr.map((item, index) => {
let img = item.hasOwnProperty("imgBase64")
? item.imgBase64
: item;
let ple = document.createElement("img");
ple.setAttribute("id", "pdfdImg" + index);
ple.setAttribute("src", img);
ple.style.width = "100%";
box.appendChild(ple);
});
}
},
// 打印方法
async prinkFn(flag) {
// 解决Vue+Print.js配置 忠onPrintDialogClose监听不到的问题
let focuser = setInterval(
() => window.dispatchEvent(new Event("focus")),
500
);
const style =
"@page { size: auto; margin: 0mm; } " +
"@media print { .img {width: 100%; }";
print({
printable: "pdfdJS",
type: "html",
style: style, // 亦可使用引入的外部css;
scanStyles: false,
onPrintDialogClose: async () => {
clearInterval(focuser);
console.log('打印预览对话框关闭,这个不能区分是取消还是打印')
//调查询接口
},
});
}