细粒度图像分类论文研读-2011
文章目录
- The Caltech-USCD Birds-200-2011 Dataset
-
- Abstract
- 数据集规范与收集
- 应用
- Novel Dataset for Fine-Grained Image Categorization:Stanford Dogs
-
- Introduction
-
- 与其他数据集的比较
- 训练与测试
- Combining Randomization and Discrimination for Fine-Grained Image Categorization
-
- Abstract
- Introduction
- Dense Sampling Space
- Random Forest with Discriminative Decision Trees
-
- The Random Forest Framework
- Sampling the Dense Feature Space
- Learning the Splits
The Caltech-USCD Birds-200-2011 Dataset
Abstract
是CUB-200的扩充版本(扩充了图片数量、增加了位置标注【bounding boxes、part locations、attribute labels】)。
数据集规范与收集
| 内容 | 描述 |
|---|---|
| Bird Species | 包含了11788张图像,共200个鸟的品种 |
| Bounding Boxes | - |
| Attributes | 包含了28个属性组,共计312个二进制属性(一个颜色就有多种选项) |
| Part Locations | 包含15个局部部位(像素位置与可见性) |
应用
| 属性 | 描述 |
|---|---|
| 次级类别识别 | 由于类别在视觉上的高度相似性,分类往往不成功。研究次级类别分类有助于提高判断能力与定位能力 |
| 多类别目标检测和基于局部的方法 | 为基于局部的方法提供了局部信息,同时为目标检测任务提供了更丰富的类别 |
| 基于属性的方法 | 为基于属性的方法提供了属性信息,更提供了相关的局部位置信息 |
| 众包和用户研究 | 因为是大众标注所以可能存在一定的误差 |
可以看出,该数据集服务于细粒度图像分析任务,主要特色有丰富的种类、同时提供了属性与局部特征。
论文中进行的实验有:
- 给定局部位置,对图像进行分类;
- 给定原始图像,对图像进行分类;
- 给定原始图像,预测位置与部位的可见性。
Novel Dataset for Fine-Grained Image Categorization:Stanford Dogs
Introduction
包含了超过22000张带有标注的图像,共包含120个类别。
每个图像用一个bounding box和object class label。
除了图像之间本身的类内方差大、类间方差小的问题,相比于其他的数据集,该数据集中包含了更多的人类与人造环境,这使得背景的差异性更大。
与其他数据集的比较

种类丰富,每一类别的样本也充足。
训练与测试
每类中,取100张作为训练集,剩下作为测试集。
Combining Randomization and Discrimination for Fine-Grained Image Categorization
Abstract
本文的方法的目的是为了探索细粒度图像的统计数据与检测有区分度的图像块来进行识别。
为了达到这一目的,应用了区分度特征挖掘和随机化两种手段。
区分度特征挖掘可以建模有区分度的细节信息,而随机化可以解决大的特征空间和阻止过拟合。
本文提出了基于判别树算法的随机森林,其中每一节点是一个分类器。值得一提的是,这一分类器的训练是和上层的节点一起进行的。
Introduction
本文通过找到一些有区分度的图像块来进行分类(类似于找不同),但是没有特征选择的支持,势必会带来数量庞大的图像块。本文提出使用随机化来解决这一问题。
本文提出了 random forest with discriminative decision trees 算法来发现有区分度的图像块和图像块对。本文的算法在每一个节点位置都适用强大的分类器并且在树的不同深度上结合信息来有效挖掘非常密集的采样空间。
本文提出的方法显著提升了决策树在随机森林中的能力同时树与树之间保持较低的相关性。这一特性使得我们的方法达到了很低的泛化误差。
本文提出的方法的实验效果有:
- 在两个数据集上达到了SOTA;
- 检测到的图像块在语义上是有意义的;
- 生成的图像区域结构是由粗到细的,与人类的视觉系统相当。
Dense Sampling Space
本文的算法的目的在于识别有助于分类的细粒度图像统计数据。
关键在于找到一些特别的图像块。本文的算法可以通过搜索一些随机的矩形框来实现这一目的。可以看到采样点和采样的长宽组合是很丰富的。

本文参考了广泛的图像区域作为密集采样空间。更进一步来说,为了捕捉更有区分度的特征,我们考虑了图像块对之间的交互。这一种成对的交互是应用级联、绝对差分或交集来实现的。
然而,密集的采样空间是很大的。不仅仅是因为采样的位置和长宽,更是考虑到图像块之间的成对交互而加剧了空间大小。
此外,特征集合中还有很多的噪声和冗余。一方面,许多的图像块不具有区分度;另一方面,采样的图像块高度重叠。
Random Forest with Discriminative Decision Trees
提出两个目标:
- 通过有判别性的训练从图像块中有效地提取信息;
- 通过随机化来有效探索密集特征空间。
具体而言,本文采用了随机森林结构,其中每一个节点是一个有判别性的分类器,用一个或一对图像块进行训练。
在我们的设置中discriminative training 和randomization能够从彼此身上获益。我们的方法的优势有:
- 随机森林结构允许我们考虑图像区域的子集,允许我们有效探索密集采样空间;
- 随机森林在每个节点中选择最好的图像块,因此它能够消除噪声图像块并减少特征集合中的冗余;
- 通过使用有区分度的分类器来训练树节点,我们的随机森林有强大的判别树。这允许我们的方法有更小的泛化误差。
The Random Forest Framework
每个树返回样本在给定类的一个后验概率。我们定义在树t的叶子l上对类别c的后验概率为 c ∗ = arg max c 1 T P t , l t ( c ) c^*=\argmax_c\frac{1}{T}P_{t,l_t}(c) c∗=argmaxcT1Pt,lt(c)。 l t l_t lt表示图像落入的叶节点。
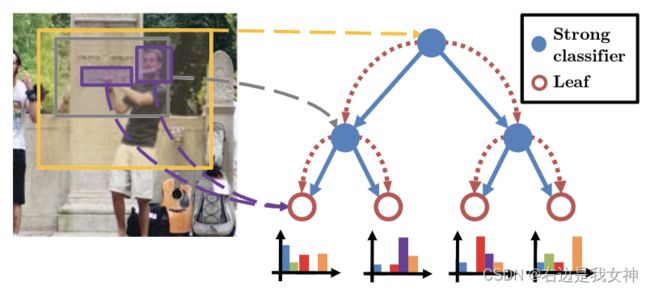
Sampling the Dense Feature Space
决策树中的每个内部节点对应于一个或一对从密集采样空间中采样的矩形图像区域。为了对候选图像区域进行采样,先将所有图像归一化到单位宽度和高度,然后从0-1均匀分布中采样对角位置。
每个采样的图像区域由视觉描述的直方图表示。对于一对区域,通过从两个区域获得的直方图进行直方图操作,形成特征表示。
此外,还会使用该图像的父节点的决策值对图像进行增强。因此,我们的特征表示结合了对应图像的所有上游节点的信息。
Learning the Splits
使用SVM进行二元分割包含两步,分别为:
- 从每个类中随机分配所有的样本到一个二元标签;
- 使用SVM来学习一个数据的二元分割。
假设在一个给定的节点上有C类图像。
每个节点都执行一个对数据的二元分裂,这允许我们在每个节点上学习一个简单的二元SVM。
使用图像区域的特征表示f,我们得到相应的二元分裂方法:

其中w是从线性SVM中学到的权重。分割的基准依然是信息增益的大小。