深入理解 MyBatis
1、什么是 MyBatis ?
MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
官方解释:mybatis.org/mybatis-3/z…
Mybaits 整体结构

整体上可以把 Mybatis 分为三层
API 接口层:对开发提供的业务层,使用本地 API 调用来操作业务数据库
数据处理层:负责具体的 SQL 查找,语句解析(参数映射),SQL 执行,以及结果映射,主要用来完成一次数据库请求操作。
基础支撑层:负责基础的功能组件支撑,包括有连接管理,事务管理,配置加载以及缓存处理等。将这些公用的组件提取出来,负责为上游业务提供基础支撑。
2、入门案例
也可参考官方:mybatis.org/mybatis-3/z…
代码示列:
使用上面的例子,就可以完成 Mybatis 操纵数据库得到业务数据。
总结下分为四个步骤:
- 获取配置文件(也可以是配置建造器),从配置中得到 SqlSessionFactory
- 从 SqlSessionFactory 获取 SqlSession
- 通过 SqlSession.getMapper 进行 CRUD 和事务操作
- 关闭 session
思考:Mybatis 在上面四步操作中做了什么?MyBatissql 语句的执行解析过程?
3、执行过程分析
3.1 构建 SqlSessionFactory
我们一步一步来,根据代码进行查看
String resource = "mybatis-config.xml";
//将 XML 配置文件构建为 Configuration 配置类
Reader reader = Resources.getResourceAsReader(resource);
// 通过加载配置文件流构建一个 SqlSessionFactory DefaultSqlSessionFactory
SqlSessionFactory sqlMapper = new SqlSessionFactoryBuilder().build(reader);
复制代码首先上面两行代码是从配置文件中进行构建 SqlSessionFactory,进入到 build... 中看看是如何构建出的
public SqlSessionFactory build(Reader reader, String environment, Properties properties) {
try {
XMLConfigBuilder parser = new XMLConfigBuilder(reader, environment, properties);
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
reader.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
复制代码这里看出 SqlSessionFactoryBuilder 会加载配置并解析 xml 配置文件,先看下 Mybatis 的一个完整的配置:
复制代码接下来可以看解析配置的核心方法
org.apache.ibatis.builder.xml.XMLConfigBuilder#parse
public Configuration parse() {
/**
* 若已经解析过了 就抛出异常
*/
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
/**
* 设置解析标志位
*/
parsed = true;
/**
* 解析 mybatis-config.xml 的节点
*
*/
parseConfiguration(parser.evalNode("/configuration"));
return configuration;
}
复制代码 org.apache.ibatis.builder.xml.XMLConfigBuilder#parseConfiguration
private void parseConfiguration(XNode root) {
try {
/**
* 解析 properties 节点
*
*/
environmentsElement(root.evalNode("environments"));
/**
* 解析数据库厂商
*/
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
/**
* 解析我们的类型处理器节点*/
typeHandlerElement(root.evalNode("typeHandlers"));
/**
* 最重要的就是解析我们的 mapper
* resource/url/class/package;
*/
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
复制代码 以上过程执行完成后会得到一个包含 Configuration 对象,其中 Configuration 包含所有的配置信息。
总结
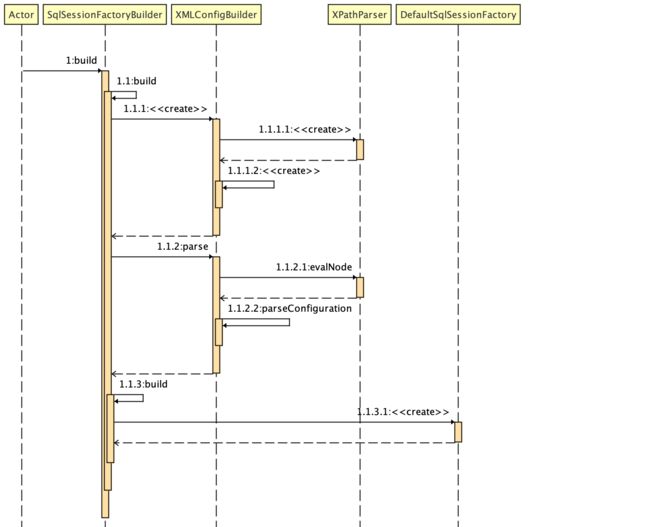
获取 SqlSessionFactory 的流程:
- 通过 SqlSessionFactoryBuilder 解析 Mybatis 所有的属性配置,生成一个包含所有的配置信息的 Configuration 对象。
- 然后用 Configuration 生成一个 DefaultSqlSessionFactory,整个过程的时序图如下
3.2 获取 SqlSession
拿到 DefaultSqlSessionFactory 后就可以开启 session,获取 SqlSession 后可以执行 CURD 操作,接下来看看 SqlSession session = sqlMapper.openSession() 的过程;
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
//获取环境变量
final Environment environment = configuration.getEnvironment();
//获取事务工厂
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
/**
* 创建一个 sql 执行器对象
* 一般情况下 若我们的 mybaits 的全局配置文件的 cacheEnabled 默认为 ture 就返回
* 一个 cacheExecutor,若关闭的话返回的就是一个 SimpleExecutor
*/
final Executor executor = configuration.newExecutor(tx, execType);
// 建返回一个 DeaultSqlSessoin 对象返回
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
复制代码这里会根据 SQL 执行器类型 execType,获取一个 sql 执行器,用来进行 SQL 语句操作
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
/**
* 判断执行器的类型
* 批量的执行器
*/
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
//可重复使用的执行器
executor = new ReuseExecutor(this, transaction);
} else {
//简单的 sql 执行器对象
executor = new SimpleExecutor(this, transaction);
}
//判断 mybatis 的全局配置文件是否开启缓存
if (cacheEnabled) {
//把当前的简单的执行器包装成一个 CachingExecutor
executor = new CachingExecutor(executor);
}
/**
* TODO:调用所有的拦截器对象 plugin 方法
*/
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
复制代码SQL 执行器 Executor 分为 CachingExecutor 和 BaseExecutor;

public static void main(String[] args) {
String resource = "mybatis-config.xml";
Reader reader;
try {
//将 XML 配置文件构建为 Configuration 配置类
reader = Resources.getResourceAsReader(resource);
// 通过加载配置文件流构建一个 SqlSessionFactory DefaultSqlSessionFactory
SqlSessionFactory sqlMapper = new SqlSessionFactoryBuilder().build(reader);
// 数据源 执行器 DefaultSqlSession
SqlSession session = sqlMapper.openSession();
try {
// 执行查询 底层执行 jdbc
// User user = (User)session.selectOne("com.zcy.mapper.UserMapper.selectById", 1);
UserMapper mapper = session.getMapper(UserMapper.class);
System.out.println(mapper.getClass());
User user = mapper.selectById(1L);
session.commit();
System.out.println(user.getUserName());
} catch (Exception e) {
e.printStackTrace();
}finally {
session.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
复制代码其中 BaseExecutor 可以分为 SimpleExecutor、ReuseExecutor、 BatchExecutor,他封装了 Transction 组件。
-
SimpleExecutor:简单执行 sql,每次执行一个 select 或者 update,就会开启一个 Statement,用完就关闭 Statement。
-
ReuseExecutor:会重用 statement 执行 sql 操作,其定义了一个 Map
-
BatchExecutor:专门用于执行批量 sql 操作,将所有的 SQL 都添加到批量处理中,等待统一执行 executeBatch(),它缓存了多个 Statement 对象。
-
CachingExecutor:其实就是封装了普调的 Executor,区别在于每次查询会先从缓存中查一下如果缓存中存在就用缓存中的结果,如果不存在,就使用普通的 Executor 查,再将结果放入缓存。
最后,根据 SQL 执行器对象 executor,配置对象configuration创建 DefaultSqlSession 拿到 SqlSession 后,我们就可以开心的进行 CURD 了。
总结
- 获取 SqlSessionFactory 后,会调用 SqlSessionFactory#openSession 方法,在这个方法里面会创建一个你的 SQL 执行器,Sql 执行器会代理你配置的拦截器方法。
- 根据执行器对象 executor 和configuration创建 SqlSession。
其中一些重要的类需要注意:
org.apache.ibatis.session.SqlSessionFactory
org.apache.ibatis.session.SqlSessionFactoryBuilder
org.apache.ibatis.session.SqlSession(默认使用 DefaultSqlSession)
org.apache.ibatis.executor.Executor
org.apache.ibatis.plugin.Plugin
org.apache.ibatis.plugin.InterceptorChain#pluginAll 方法
复制代码
3.3 获取 Mapper
拿到 SqlSession 后,通过 session.getMapper(UserMapper.class)获取到 UserMapper 的代理对象,怎么样获取到代理对象的,跟进去看一下;
org.apache.ibatis.session.defaults.DefaultSqlSession#getMapper
@Override
public T getMapper(Class type) {
return configuration.getMapper(type, this);
}
复制代码 org.apache.ibatis.session.Configuration#getMapper
//mapperRegistry 的 key 是接口的 Class 类型
//mapperRegistry 的 Value 是 MapperProxyFactory,用于生成对应的 MapperProxy(动态代理类)
protected final MapperRegistry mapperRegistry = new MapperRegistry(this);
public T getMapper(Class type, SqlSession sqlSession) {
return mapperRegistry.getMapper(type, sqlSession);
}
复制代码 可以看到最终会通过 org.apache.ibatis.session.Configuration#mapperRegistry 来获取 Mapper,mapperRegistry 实际上是一个 Map,在开始加载 config 配置的时候,会把所有的 Mapper 加载到这个 map 中.
下面看看 getMapper
public T getMapper(Class type, SqlSession sqlSession) {
/**
* 直接去缓存 knownMappers 中通过 Mapper 的 class 类型去找我们的 mapperProxyFactory
*/
final MapperProxyFactory mapperProxyFactory = (MapperProxyFactory) knownMappers.get(type);
/**
* 缓存中没有获取到 直接抛出异常
*/
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
/**
* 通过 MapperProxyFactory 来创建我们的实例
*/
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
复制代码 查看 org.apache.ibatis.binding.MapperProxyFactory#newInstance(org.apache.ibatis.session.SqlSession)方法
public class MapperProxyFactory {
private final Class mapperInterface;
private final Map methodCache = new ConcurrentHashMap<>();
public MapperProxyFactory(Class mapperInterface) {
this.mapperInterface = mapperInterface;
}
public Class getMapperInterface() {
return mapperInterface;
}
public Map getMethodCache() {
return methodCache;
}
@SuppressWarnings("unchecked")
protected T newInstance(MapperProxy mapperProxy) {
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
public T newInstance(SqlSession sqlSession) {
/**
* 创建我们的代理对象
*/
final MapperProxy mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
/**
* 创建我们的 Mapper 代理对象返回
*/
return newInstance(mapperProxy);
}
}
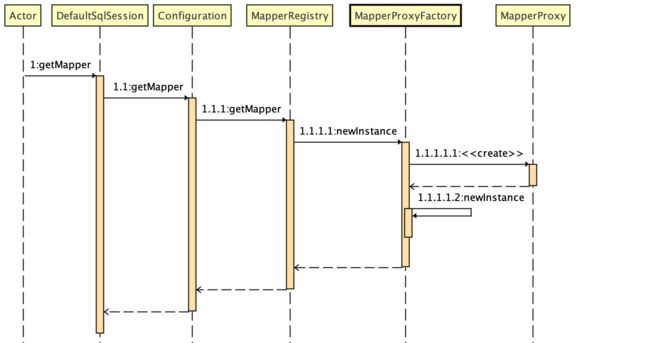
复制代码 总结
获取 Mapper 最终会调用 MapperProxyFactory#newInstance(MapperProxy 方法。通过 Proxy 动态代理得到我们需要的 Mapper,所以最后我们生成的 Mapper 实际上是一个代理对象,流程如下:
3.4 执行代理 Mapper 方法
上面看完 Mapper 的代理,具体是怎样代理的,我们到 MapperProxy 类中一探究竟
public class MapperProxy implements InvocationHandler, Serializable {
private static final long serialVersionUID = -6424540398559729838L;
private static final int ALLOWED_MODES = MethodHandles.Lookup.PRIVATE | MethodHandles.Lookup.PROTECTED
| MethodHandles.Lookup.PACKAGE | MethodHandles.Lookup.PUBLIC;
private static Constructor lookupConstructor;
private final SqlSession sqlSession;
private final Class mapperInterface;
/**
* 用于缓存我们的 MapperMethod 方法
*/
private final Map methodCache;
public MapperProxy(SqlSession sqlSession, Class mapperInterface, Map methodCache) {
this.sqlSession = sqlSession;
this.mapperInterface = mapperInterface;
this.methodCache = methodCache;
}
static {
try {
lookupConstructor = MethodHandles.Lookup.class.getDeclaredConstructor(Class.class, int.class);
} catch (NoSuchMethodException e) {
try {
// Since Java 14+8
lookupConstructor = MethodHandles.Lookup.class.getDeclaredConstructor(Class.class, Class.class, int.class);
} catch (NoSuchMethodException e2) {
throw new IllegalStateException("No known constructor found in java.lang.invoke.MethodHandles.Lookup.", e2);
}
}
lookupConstructor.setAccessible(true);
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
// 判断我们的方法是不是我们的 Object 类定义的方法,若是直接通过反射调用
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else if (method.isDefault()) { //是否接口的默认方法
//调用我们的接口中的默认方法
return invokeDefaultMethod(proxy, method, args);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
// 主要流程从这里开始,创建或者从缓存中获取 MapperMethod
final MapperMethod mapperMethod = cachedMapperMethod(method);
return mapperMethod.execute(sqlSession, args);
}
private MapperMethod cachedMapperMethod(Method method) {
/**
* 相当于这句代码.
* if(methodCache.get(method)==null){
* methodCache.put(new MapperMethod(mapperInterface, method, sqlSession.getConfiguration()))
* }
*/
return methodCache.computeIfAbsent(method, k -> new MapperMethod(mapperInterface, method, sqlSession.getConfiguration()));
}
private Object invokeDefaultMethod(Object proxy, Method method, Object[] args)
throws Throwable {
final Class declaringClass = method.getDeclaringClass();
final Lookup lookup;
if (lookupConstructor.getParameterCount() == 2) {
lookup = lookupConstructor.newInstance(declaringClass, ALLOWED_MODES);
} else {
// SInce JDK 14+8
lookup = lookupConstructor.newInstance(declaringClass, null, ALLOWED_MODES);
}
return lookup.unreflectSpecial(method, declaringClass).bindTo(proxy).invokeWithArguments(args);
}
}
复制代码 这个类中主要关注 invoke 方法,方法中主要是创建 MapperMethod 对象或者是从缓存中获取 MapperMethod 对象。MapperMethod 中主要是对 Mapper 中的方法进行描叙,包含 Mapper 中定义的方法参数 ParamMap,方法签名 MethodSignature 以及方法的 SQL 类型 SqlCommand(CURD),类结构如下图

获取到 MapperMethod 这个对象后执行 execute 方法,这里进入 MapperMethod 的 execute 方法:
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
//判断我们执行 sql 命令的类型
switch (command.getType()) {
//insert 操作
case INSERT: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
//update 操作
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
//delete 操作
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
//select 操作
case SELECT:
//返回值为空
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
//返回值是一个 List
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
//返回值是一个 map
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
//返回游标
result = executeForCursor(sqlSession, args);
} else {
//查询返回单个
//解析参数
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
复制代码在 execute 中,无非就是拿到你当前执行的 SQL,判断当前要执行的是增删改查的哪一种类型,然后做出不同的反应。我们要执行 User user = mapper.selectById(1L),这里拿出 sqlSession.selectOne 来分析。
public T selectOne(String statement, Object parameter) {
// Popular vote was to return null on 0 results and throw exception on too many.
//这里 selectOne 调用也是调用 selectList 方法
List list = this.selectList(statement, parameter);
//若查询出来有且有一个一个对象,直接返回要给
if (list.size() == 1) {
return list.get(0);
} else if (list.size() > 1) {
//查询的有多个,抛出异常
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}
复制代码 可以看到 selectOne 还是调用 selectList 来执行,然后取出一个,若获取到多个结果,则抛出很常见的异常:Expected one result (or null) to be returned by selectOne(), but found: " + list.size()
具体看下 selectList 方法:
public List selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
//第一步:通过我们的 statement 去我们的全局配置类中获取 MappedStatement
MappedStatement ms = configuration.getMappedStatement(statement);
/**
* 通过执行器去执行我们的 sql 对象
* 第一步:包装我们的集合类参数
* 第二步:一般情况下是 executor 为 cacheExetory 对象
*/
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
复制代码 在这里会调用执行器去执行 executor.query,看下方法实现:
org.apache.ibatis.executor.Executor#query
public List query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
//创建缓存 key
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
//最终调用
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
复制代码 这里会获取 BoundSql,这个对象 包含从 SqlSource 处理后的动态实际 SQL 字符串,SQL 字符串可能有 SQL 占位符“?”和一个参数映射列表(有序)以及每个参数的附加信息(至少是要从中读取值的输入对象的属性名称)。 也可以有由动态语言创建的附加参数(for 循环、绑定...)

最终经过了缓存处理(一级缓存,二级缓存调用若没有获取到),会来到 queryFromDatabase,看名次就知道要去查数据库:
private List queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
复制代码 这里选择 SimpleExecutor.doQuery
public List doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
//这里会封装为一个 StatementHandler, ParameterHandler 和 ResultSetHandler ,
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
//StatementHandler 封装了 Statement, 让 StatementHandler 去处理
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
复制代码 StatementHandler 是个接口,包含一个抽象类及其三个实现,抽象类中还封装了 ParameterHandler 和 ResultSetHandler ,这里 RoutingStatementHandler 貌似用到了策略模式...

我们比较熟悉的是 PreparedStatementHandler,我们就抽出来看看他的 query 方法实现:
public List query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
return resultSetHandler.handleResultSets(ps);
}
复制代码 这里的方法大家都熟悉了吧,PreparedStatement 调用 execute,然后 resultSetHandlerl 来处理响应查询结果并返回。
总结
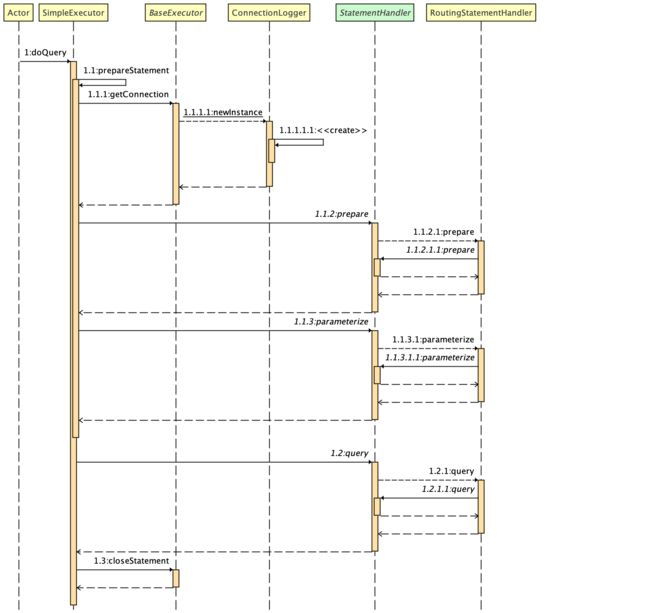
1、 MapperProxy 会执行 invoke,在 invoke 中会得到一个 MapperMethod 对象,调用其 execute 方法,将 sqlSession 作为参数代入。
2、接下来会调用 Executor 组件的 query 方法,在这里会封装 StatementHandler 对象,其中 StatementHandler 会包含 ParameterHandler 和 ResultSetHandler,最终调用 StatementHandler 来预编译 SQL 语句,使用 ParameterHandler 来给 SQL 语句预设值。
3、最后 StatementHandler 会调用其增删改查的方法,使用 ResultSetHandler 对结果进行转换,请求结束。
这个过程中 Executor、StatementHandler 、ParameterHandler、ResultSetHandler,Mybatis 的插件会对上面的四个组件进行动态代理。
Mapper.invoke--> selectOne--> doQuery 的流程图


一些重要的属性类:
- MapperRegistry:其实是一个 Map,对应的 key 是接口的全限定名,value 是对应的 MapperProxyFactory,保存在 MapperRegistry 对象的 knownMappers 属性中。
- MapperProxyFactory:是 MapperRegistry 的 value,当调用 session.getMapper 时,首先会获取到这个代理工厂,然后通过代理工厂获取到 Mapper 的动态代理类。
- MapperProxy:实现 InvocationHandler 接口,是 Mapper 的代理类,当调用 Mapper 的方法时,都会执行到 MapperProxy 的 invoke 方法。
- MapperMethod:用来判断当前执行的是增删改查的哪一类操作。
- SqlSession:Mybatis 主要 API ,负责与数据库会话交互,完成增删改查。
- Executor:Mybatis 执行器,作为 Mybatis 的 SQL 调度中心,负责 SQL 语句的生成和维护。
- StatementHandler:封装了 JDBC Statement。
- ParameterHandler:封装 JDBC Statement 所需要的参数。
- ResultSetHandler:封装 JDBC 返回的 ResultSet 结果集对象转换成 List 类型的集合。
- TypeHandler:负责 Java 对象与 JDBC 对象的互转。
- MappedStatement:维护 mapper 的信息,包含 mapper 的全路径,对应语句结果类型,SQL 语句类型,以及 SQL 语句等信息。
- SqlSource:负责将用户传递的参数封装到 BoundSql 中,可以动态的生成 SQL 语句。
- BoundSql:动态的 SQL 语句信息,包含参数。
- Configuration:MyBatis 的全局配置类。
4、Mybatis 插件
在上面的分析中有两个类值得注意,分别是 org.apache.ibatis.plugin.Plugin、org.apache.ibatis.plugin.InterceptorChain 方法,这两个类就是 Mybatis 的插件支持,在 Mybatis 官方文档中这么解释:
MyBatis 允许你在映射语句执行过程中的某一点进行拦截调用。默认情况下,MyBatis 允许使用插件来拦截的方法调用包括:
- Executor (update, query, flushStatements, commit, rollback, getTransaction, close, isClosed)
- ParameterHandler (getParameterObject, setParameters)
- ResultSetHandler (handleResultSets, handleOutputParameters)
- StatementHandler (prepare, parameterize, batch, update, query)
写的比较明确,可以总结一下,就是 Mybatis 插件可以进行拦截以下执行过程:
Executor 执行的方法
ParameterHandler 的处理方法
ResultSetHandler 的处理方法
StatementHandler 的处理方法
4.1 插件的定义
具体的插件如何使用,可以参考下官方(参考mybatis.org/mybatis-3/z…)这里不展开描叙,我们这讨论下插件是如何执行,在何时进行调用的。
首先需要使用一个插件,需要在配置中打开配置
复制代码在上面分析中有讲过配置是如何加载的,我们找到 org.apache.ibatis.builder.xml.XMLConfigBuilder#parseConfiguration.pluginElement
private void parseConfiguration(XNode root) {
//省略...
//解析我们的插件(比如分页插件)
pluginElement(root.evalNode("plugins"));
//省略...
}
private void pluginElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
String interceptor = child.getStringAttribute("interceptor");
Properties properties = child.getChildrenAsProperties();
Interceptor interceptorInstance = (Interceptor) resolveClass(interceptor).getDeclaredConstructor().newInstance();
interceptorInstance.setProperties(properties);
configuration.addInterceptor(interceptorInstance);
}
}
}
public void addInterceptor(Interceptor interceptor) {
interceptorChain.addInterceptor(interceptor);
}
复制代码比较简单,拿到配置中的 plugin,通过反射,将 plugin 添加到 configuration 的一个类部属性interceptorChain。
interceptorChain 是一个连接器链,看下他的定义
public class InterceptorChain {
private final List interceptors = new ArrayList<>();
public Object pluginAll(Object target) {
for (Interceptor interceptor : interceptors) {
target = interceptor.plugin(target);
}
return target;
}
public void addInterceptor(Interceptor interceptor) {
interceptors.add(interceptor);
}
public List getInterceptors() {
return Collections.unmodifiableList(interceptors);
}
}
复制代码 看到这里,我们知道了拦截器配置的解析以及拦截器的归属,那接下来看看为什么我们定义插件,会在 Executor,ParameterHandler,ResultSetHandler,StatementHandler 的一些方法中执行。
4.2 插件的执行
首先找到这四个对象在哪里被创建出来,在 configuration 中有这些对象的实例化实例
public ParameterHandler newParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) {
ParameterHandler parameterHandler = mappedStatement.getLang().createParameterHandler(mappedStatement, parameterObject, boundSql);
parameterHandler = (ParameterHandler) interceptorChain.pluginAll(parameterHandler);
return parameterHandler;
}
public ResultSetHandler newResultSetHandler(Executor executor, MappedStatement mappedStatement, RowBounds rowBounds, ParameterHandler parameterHandler,
ResultHandler resultHandler, BoundSql boundSql) {
ResultSetHandler resultSetHandler = new DefaultResultSetHandler(executor, mappedStatement, parameterHandler, resultHandler, boundSql, rowBounds);
resultSetHandler = (ResultSetHandler) interceptorChain.pluginAll(resultSetHandler);
return resultSetHandler;
}
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
public Executor newExecutor(Transaction transaction) {
return newExecutor(transaction, defaultExecutorType);
}
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
//判断执行器的类型 批量的执行器
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
//可重复使用的执行器
executor = new ReuseExecutor(this, transaction);
} else {
//简单的 sql 执行器对象
executor = new SimpleExecutor(this, transaction);
}
//判断 mybatis 的全局配置文件是否开启缓存
if (cacheEnabled) {
//把当前的简单的执行器包装成一个 CachingExecutor
executor = new CachingExecutor(executor);
}
//调用所有的拦截器对象 plugin 方法
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
复制代码上面四个方法,都是在 Configuration 类中定义,在分析执行过程中,我们知道 Mybatis 在执行方法过程中,必然会依次执行 Executor,ParameterHandler,ResultSetHandler,StatementHandler,所以在这四个类实例化对应的对象后依旧必然会执行 interceptorChain.pluginAll 方法,InterceptorChain 的 pluginAll 就会遍历所有定义的拦截器,去执行 plugin 方法。
比如分页插件,需要在查询的 SQL 语句上拼接分页,那么就需要拦截 StatementHandler(其主要处理 sql 语法的构建),在 StatementHandler 接口实现类中的拼接我们自己的 sql 即可。
MyBatis 还提供了 @Intercepts 和 @Signature 关于拦截器的注解,还包括了 Plugin 类的使用,这里不做多介绍。
5、缓存
MyBatis 自带强大的事务性查询缓存,它非常的方便开发定制和易于使用,在 MyBatis 中,默认情况下是只启用了本地缓存,即一级缓存,他是一个存在于 session 级别的缓存,仅仅对当前 session 有效,若要启用全局缓存(二级缓存),只需要通过简单的配置,便可使用。
具体使用先可以参考权威官方:mybatis.org/mybatis-3/z…
5.1 一级缓存
先看下一级缓存,一级缓存是 MyBatis 默认开启的,我们通过代码验证
public static void main(String[] args) {
String resource = "mybatis-config.xml";
Reader reader;
try {
reader = Resources.getResourceAsReader(resource);
SqlSessionFactory sqlMapper = new SqlSessionFactoryBuilder().build(reader);
SqlSession session = sqlMapper.openSession();
try {
UserMapper mapper = session.getMapper(UserMapper.class);
User user = mapper.selectById(1L);
System.out.println("j 结果===>"+user.getUserName());
//=============
UserMapper mapper1 = session.getMapper(UserMapper.class);
User user1 = mapper1.selectById(1L);
System.out.println("j 结果===>"+user1.getUserName());
} catch (Exception e) {
e.printStackTrace();
}finally {
session.close();
session1.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
复制代码上面代码是从一个 session 会话中进行数据查询,执行上面代码会发现最终只打印一条 SQL 语句,说明只查了一次数据库。
对代码稍加修改:
public static void main(String[] args) {
String resource = "mybatis-config.xml";
Reader reader;
try {
reader = Resources.getResourceAsReader(resource);
SqlSessionFactory sqlMapper = new SqlSessionFactoryBuilder().build(reader);
SqlSession session = sqlMapper.openSession();
SqlSession session1 = sqlMapper.openSession();
try {
UserMapper mapper = session.getMapper(UserMapper.class);
User user = mapper.selectById(1L);
System.out.println("j 结果===>"+user.getUserName());
//=============
UserMapper mapper1 = session1.getMapper(UserMapper.class);
User user1 = mapper1.selectById(1L);
System.out.println("j 结果===>"+user1.getUserName());
} catch (Exception e) {
e.printStackTrace();
}finally {
session.close();
session1.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
复制代码开启两个 session,执行上面代码发现打印 2 次 SQL,说明两次走数据库查询。
对于一级缓存,这里给出结论,可以自行验证
缓存开启
- 默认就开启了,也可以关闭一级缓存 localCacheScope=STATEMENT
- 作用域:是基于 sqlSession(默认),一次数据库操作会话。
- 缓存默认实现类 PerpetualCache ,使用 map 进行存储的
- 查询完就会进行存储
- 先从二级缓存中获取,再从一级缓存中获取
- cacheKey :保存 sqlid+sql
失效情况:
- 不同的 sqlSession 会使一级缓存失效
- 同一个 SqlSession,但是查询语句不一样
- 同一个 SqlSession,查询语句一样,期间执行增删改操作
- 同一个 SqlSession,查询语句一样,执行手动清除缓存
5.2 二级缓存
还是参考官方:mybatis.org/mybatis-3/z…
这里我们讨论下二级缓存底层如何实现,先给出列子:
public static void main(String[] args) {
String resource = "mybatis-config.xml";
Reader reader;
try {
reader = Resources.getResourceAsReader(resource);
SqlSessionFactory sqlMapper = new SqlSessionFactoryBuilder().build(reader);
SqlSession session = sqlMapper.openSession();
SqlSession session1 = sqlMapper.openSession();
try {
UserMapper mapper = session.getMapper(UserMapper.class);
User user = mapper.selectById(1L);
System.out.println("j 结果===>"+user.getUserName());
session.close();
//=============
UserMapper mapper1 = session1.getMapper(UserMapper.class);
User user1 = mapper1.selectById(1L);
System.out.println("j 结果===>"+user1.getUserName());
session1.close();
} catch (Exception e) {
e.printStackTrace();
}
} catch (IOException e) {
e.printStackTrace();
}
}
复制代码开启二级缓存之后,代码按照上面写法,开启两个 session,在第一个 session 关闭之后,MyBatis 便会将结果进行缓存,在第二次开启一个会话查询,重新查询。执行上面代码发现,会发现只打印一条 SQL,说明走了缓存。
这也给直接出结论,自行验证
特性
- 作用域:基于全局范围,应用级别。
- 缓存默认实现类 PerpetualCache ,使用 map 进行存储的但是二级缓存根据不同的 mapper 命名空间多包了一层
- 事务提交的时候(sqlSession 关闭)
- 先从二级缓存中获取,再从一级缓存中获取
实现
- 开启二级缓存
- 在需要使用到二级缓存的映射文件中加入
,基于 Mapper 映射文件来实现缓存的,基于 Mapper 映射文件的命名空间来存储的 - 在需要使用到二级缓存的 javaBean 中实现序列化接口 implements Serializable
失效
- 同一个命名空间进行了增删改的操作,会导致二级缓存失效,如果不想失效:可以将 SQL 的 flushCache 设置为 false,但是要慎重设置,因为会造成数据脏读问题,除非你能保证查询的数据永远不会执行增删改
- 查询不想缓存的数据设置到二级缓存中 useCache="false"
- 如果希望其他 mapper 映射文件的命名空间执行了增删改清空另外的命名空间就可以设置:
5.3 二级缓存原理实现
具体如何走缓存,怎么根据我们添加的配置走缓存,看下是如何代码实现根据不同的配置缓存属性,实现缓存的。在上面分析的全局配置文件中会配置 mapper,在 mapper 中有开启二级缓存,那就进入代码到解析 mapper 中去;
我们配置扫描 mapper 的方式是通过 package 扫描,跟踪到org.apache.ibatis.builder.xml.XMLConfigBuilder#parseConfiguration.mapperElement,看到 package...
if ("package".equals(child.getName())) {
String mapperPackage = child.getStringAttribute("name");
configuration.addMappers(mapperPackage);
}
复制代码这里层层调用,会把指定 package 下的 mapper 文件扫描到一个knownMappers集合中去,最终进行解析,关注 parser.parse()。
public void addMapper(Class type) {
if (type.isInterface()) {
if (hasMapper(type)) {
throw new BindingException("Type " + type + " is already known to the MapperRegistry.");
}
boolean loadCompleted = false;
try {
//把我们的 Mapper 接口保存到 knownMappers
knownMappers.put(type, new MapperProxyFactory<>(type));
// mapper parser. If the type is already known, it won't try.
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
// 进行解析
parser.parse();
loadCompleted = true;
} finally {
if (!loadCompleted) {
knownMappers.remove(type);
}
}
}
}
复制代码 public void parse() {
String resource = type.toString();
// 是否已经解析 mapper 接口对应的 xml
if (!configuration.isResourceLoaded(resource)) {
// 根据 mapper 接口名获取 xml 文件并解析解析里面所有东西放到 configuration
loadXmlResource();
// 添加已解析的标记
configuration.addLoadedResource(resource);
assistant.setCurrentNamespace(type.getName());
// 解析缓存
parseCache();
parseCacheRef();
Method[] methods = type.getMethods();
for (Method method : methods) {
try {
// issue #237
if (!method.isBridge()) {
// 是不是用了注解 用了注解会将注解解析成 MappedStatement
parseStatement(method);
}
} catch (IncompleteElementException e) {
configuration.addIncompleteMethod(new MethodResolver(this, method));
}
}
}
parsePendingMethods();
}
复制代码 在 parseCache()中会调用 org.apache.ibatis.builder.MapperBuilderAssistant#useNewCache 方法,直接进去吧
在这里可以看到,构建了一个 CacheBuilder,将我们在配置属性里面的 flushInterval,eviction,size,readOnly 等属性构建出来,用一个 Cache 接口接受。看下结构,这个类有许多子类

每个类有不同的功能,其中默认实现类是永久缓存 PerpetualCache,ScheduledCache 是周期清除缓存,LoggingCache 是打印日志功能,LruCache 缓存过期策略,SynchronizedCache 同步缓存等。
看下 build 的过程
public Cache build() {
setDefaultImplementations();
Cache cache = newBaseCacheInstance(implementation, id);
//设置缓存属性
setCacheProperties(cache);
// issue #352, do not apply decorators to custom caches
if (PerpetualCache.class.equals(cache.getClass())) {
for (Class decorator : decorators) {
cache = newCacheDecoratorInstance(decorator, cache);
setCacheProperties(cache);
}
//设置标准装饰器
cache = setStandardDecorators(cache);
} else if (!LoggingCache.class.isAssignableFrom(cache.getClass())) {
cache = new LoggingCache(cache);
}
return cache;
}
复制代码在 build 过程中,有个 setStandardDecorators,字面意思设置标准装饰器,看看怎么设置
private Cache setStandardDecorators(Cache cache) {
try {
MetaObject metaCache = SystemMetaObject.forObject(cache);
if (size != null && metaCache.hasSetter("size")) {
metaCache.setValue("size", size);
}
if (clearInterval != null) {
cache = new ScheduledCache(cache);//ScheduledCache:调度缓存,负责定时清空缓存
((ScheduledCache) cache).setClearInterval(clearInterval);
}
if (readWrite) { // 将 LRU 装饰到 Serialized
cache = new SerializedCache(cache); //SerializedCache:缓存序列化和反序列化存储
}
cache = new LoggingCache(cache);
cache = new SynchronizedCache(cache);
if (blocking) {
cache = new BlockingCache(cache);
}
return cache;
} catch (Exception e) {
throw new CacheException("Error building standard cache decorators. Cause: " + e, e);
}
}
复制代码就是拿到原始的 PerpetualCache 对象,将他包装一下,包装类就是上面 Cache 的实现子类,至于为什么这样包装(装饰器),还需要下面分析吧。
以上是缓存的设计实现,使用建造者模式+装饰器模式构建出一个缓存。
具体如何使用缓存?在上面代码中,可以看到在查询的时候,肯定走了缓存,进去代码中去,会发现最终在 org.apache.ibatis.session.defaults.DefaultSqlSession#selectList(java.lang.String, java.lang.Object, org.apache.ibatis.session.RowBounds)方法调用查询
public List selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
//全局配置类中获取 MappedStatement,这个对象包含了 cache 对象
MappedStatement ms = configuration.getMappedStatement(statement);
//执行器去执行 sql 对象
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
复制代码 public List query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
//解析 SQL 对象
BoundSql boundSql = ms.getBoundSql(parameterObject);
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
复制代码 在 executor.query 中创建了 CacheKey,可以看到 CacheKey 的结构,最后在 query 方法中执行查询
public List query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
//判断是否开启了二级缓存
Cache cache = ms.getCache();
if (cache != null) {
//判断是否需要刷新缓存
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
//先去二级缓存中获取
@SuppressWarnings("unchecked")
List list = (List) tcm.getObject(cache, key);
//没有获取到
if (list == null) {
//通过查询数据库去查询
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
//加入到二级缓存中
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
//没有开启二级缓存,直接去查询
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
复制代码 到这里,比较清晰了,先去二级缓存查,没有查到就去数据库查询,看下tcm.getObject(cache, key)的逻辑,这个方法会把缓存包装一下,然后在获取结构。他先包装成一个事务缓存,二级缓存是事务性的。这意味着,当 SqlSession 完成并提交时,或是完成并回滚,但没有执行 flushCache=true 的 insert/delete/update 语句时,缓存会获得更新。
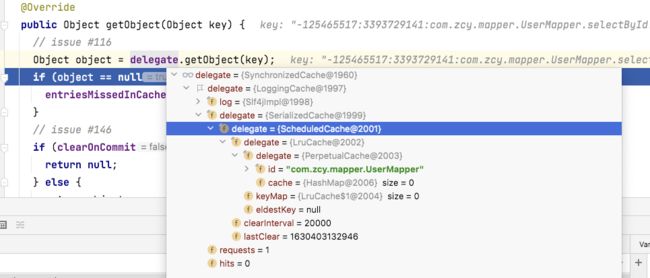
public Object getObject(Cache cache, CacheKey key) {
//先包装成一个事务缓存
return getTransactionalCache(cache).getObject(key);
}
复制代码public Object getObject(Object key) {
// issue #116
Object object = delegate.getObject(key);
if (object == null) {
entriesMissedInCache.add(key);
}
// issue #146
if (clearOnCommit) {
return null;
} else {
return object;
}
}
复制代码获取缓存的逻辑很简单,直接从 delegate 中 get,这个 delegate 就是个包装,在上面介绍过,Cache 是一个接口,有许多实现类,delegate 就是上面这些类的包装器,在获取缓存对象的时候,会层层获取,看下调用结构,最外层是 SynchronizedCache,包装着 LoggingCache,然后 LoggingCache 包装 SerializedCache.....发现好像是个责任链?是的!
再回到 org.apache.ibatis.mapping.CacheBuilder#build,应该明白为甚这样包装了吧
总结
缓存功能由接口 org.apache.ibatis.cache.Cache 来定义,整个体系采用装饰器模设计模式,数据缓存和基本的缓存功能由永久缓存 org.apache.ibatis.cache.impl.PerpetualCache 实现,在调用的时候,通过装饰器+责任链模式依次链式调用,整个过程方便控制,代码耦合度低易于拓展。
6、Spring 如何管理 MyBatis
在知道 MyBatis 怎么使用后,我们经常在 Spring 中结合 MyBatis 一起使用,那么 Spring 又是怎么管理到 MyBatis 的 Mapper 的呢?这个问题在面试中,也经常被问到:Spring 是怎么管理 MyBatis 中的 Mapper 动态代理的?这里详细介绍下。
首先,肯定是下载 Mybatis 集成 Spring 的适配器,将 MyBatis-Spring 模块相关 jar 引入到工程里面去,具体结合的过程这里也不做多描叙,详细可以参考官方:mybatis.org/spring/,这里主要说下,结合过程中的理论支撑。
6.1 示列代码
引入 spring-mybatis 示列代码:
@Data
public class User implements Serializable {
private Long id;
private String userName;
private Date createTime;
@Override
public String toString() {
return "User{" +
"id=" + id +
", userName='" + userName + '\'' +
", createTime=" + createTime +
'}';
}
}
@Mapper
public interface UserMapper {
User selectById(Long id);
}
复制代码UserMapper.xml
复制代码在 web 项目中,我们通常这样使用:
@RestController
public class TestController {
@Autowired
private UserMapper userMapper;
@GetMapping("test")
public User getUser(){
User user = userMapper.selectById(1L);
return user;
}
}
复制代码回到我们上面的问题,Spring 是怎么管理到 MyBatis 的 Mapper 的,代码中是将 Mapper 直接注入到 Spring 容器中去,但是 Spring 管理的对象必定是一个 bean,而 Mapper 是一个接口,这时我们肯定会想到,这里的 Mapper 一定是一个代理对象,所以,Spring 管理的就是被我们注入的 Mapper 的代理对象,断点验证一下,证实
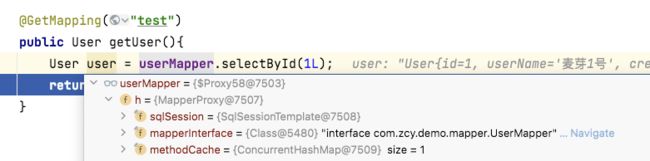
那 Spring 是怎么管理 MyBatis 中的 Mapper 动态代理的呢,Spring 需要管理 Mapper,那就是管理 bean,首先看下 Spring 的 bean 是怎么产生的。
在 Spring 中,是通过 getBean 得到一个 bean 对象,在这个过程中会先得到一个 bean 定义 BeanDefinition,通过 BeanDefinition,构建 bean 的不同参数,最终生成一个 bean。
如果我们要生成一个 bean 对象,就需要构建一个自己 BeanDefinition,然后在 BeanDefinition 中对我们自己的 bean 进行描叙,把 BeanDefinition 添加到 Spring,这样 Spring 就会帮我们生成一个自己的 bean。
可以这样实现:
package com.zcy.demo.bean;
@Component
public class Mapper1 {
}
public class Mapper2 {
//没有交给 Spring 管理的 bean
}
@Configurable
@ComponentScan("com.zcy.demo.bean")
public class MyConfig {
}
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext((MyConfig.class));
System.out.println(context.getBean("mapper1"));
context.start();
// SpringApplication.run(MybatisWebApplication.class, args);
}
复制代码执行完发现输出: com.zcy.demo.bean.Mapper1@7f77e91b,得到自己的类,可是 BeanDefinition 是可以被修改的!比如我们增加一个 bean 后置处理器
@Component
public class MyBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory configurableListableBeanFactory) throws BeansException {
BeanDefinition bf = configurableListableBeanFactory.getBeanDefinition("mapper1");
bf.setBeanClassName(Mapper2.class.getName());
}
}
复制代码这时候,执行发现输出 com.zcy.demo.bean.Mapper2@7f77e91b,这个骚操作应该都理解吧,这个说明在 Spring 中,对象跟 class 并没有关系,而是跟 BeanDefinition 有关系。
6.2 Mybatis 的代理对象的类型是什么
现在回到之前的问题,我们要生成一个自己的 mapper,就需要解决两个问题:
1,生成一个自己的 BeanDefinition
2,把 BeanDefinition 交给 Spring 容器
那现在需要把 UserMapper 接口代理注入到 Spring 容器,如果其代理对象为 UserMapperProxy,那大致代码应该如下
BeanDefinitoin bd = new BeanDefinitoin();
bd.setBeanClassName(UserMapperProxy.class.getName());
SpringContainer.addBd(bd);
复制代码但是有个问题,UserMapperProxy 是变化的,是 jdk 代理对象动态生成的,所以新增根本不能确定代理对象类型是什么,那现在问题变成了,Mybatis 的代理对象的类型是什么东东?答案无非如下:
- 代理对象对应的代理类
- 代理对象对应的接口
但是 1 被我们排除了,那就剩下 代理对象对应的接口,那代码应该如下
BeanDefinitoin bd = new BeanDefinitoin();
bd.setBeanClassName(UserMapper.class.getName()); //mapper 接口
SpringContainer.addBd(bd);
复制代码可是接口是不能实例化对象的,所以这肯定也行不通,代理对象对应的接口也不对。
总结上面的推理:我们想通过设置 BeanDefinition 的 class 类型,然后由 Spring 自动的帮助我们去生成对应的 bean,但是这条路是行不通的。
那,还有其他办法生成 Bean 吗?
在 Spring 中,有个 FactoryBean,可以通过 FactoryBean. getObject()生成需要的对象
@Component
public class MyFactoryBean implements FactoryBean {
@Override
public Object getObject() throws Exception {
Object proxyInstance = Proxy.newProxyInstance(MyFactoryBean.class.getClassLoader(), new Class[]{UserMapper.class}, new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else {
// 执行代理逻辑
return null;
}
}
});
return proxyInstance;
}
@Override
public Class getObjectType() {
return UserMapper.class;
}
}
复制代码定义一个 MyFactoryBean,实现了 FactoryBean,其中 getObject 方法就是用来自定义生成 bean 对象逻辑的。
测试一下结果:
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext((MyConfig.class));
//System.out.println(context.getBean("mapper1"));
//System.out.println(context.getBean("mapper2"));
System.out.println("myFactoryBean: " + context.getBean("myFactoryBean"));
System.out.println("&myFactoryBean: " + context.getBean("&myFactoryBean"));
System.out.println("myFactoryBean-class: " + context.getBean("myFactoryBean").getClass());
context.start();
}
复制代码打印结果如下:
myFactoryBean: com.zcy.demo.bean.MyFactoryBean$1@55040f2f
&myFactoryBean: com.zcy.demo.bean.MyFactoryBean@64c87930
myFactoryBean-class: class com.sun.proxy.$Proxy12
从结果可以看到,获取到的 myFactoryBean-class 的对象就是 jdk 动态代理的结果。所以,我们可以通过 FactoryBean 来向 Spring 容器中添加一个自定义的 bean 对象。上面所定义的 MyFactoryBean 对应的就是 UserMapper,表示我们定义了一个 MyFactoryBean,相当于把 UserMapper 对应的代理对象作为一个 bean 放入到了容器中。
但是我们不可能每次都写一个 MyFactoryBean(UserMapper),上面代码需要调整一下,让他动态传入,变成
@Component
public class MyFactoryBean implements FactoryBean {
// 动态传入
private Class mapperInterface;
public MyFactoryBean(Class mapperInterface) {
this.mapperInterface = mapperInterface;
}
@Override
public Object getObject() throws Exception {
Object proxyInstance = Proxy.newProxyInstance(MyFactoryBean.class.getClassLoader(), new Class[]{mapperInterface}, new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else {
// 执行代理
return null;
}
}
});
return proxyInstance;
}
@Override
public Class getObjectType() {
return mapperInterface;
}
}
复制代码这样改造 MyFactoryBean 之后,我们在构造 MyFactoryBean 时,通过构造传入不同的 Mapper 接口
BeanDefinition bd = new BeanDefinitoin();
// 设置的是 MyFactoryBean
bd.setBeanClassName(MyFactoryBean.class.getName());
// 表示当前 BeanDefinition 在生成 bean 对象时,会通过调用 MyFactoryBean 的构造方法来生成,并传入 UserMapper
bd.getConstructorArgumentValues().addGenericArgumentValue(UserMapper.class.getName())
SpringContainer.addBd(bd);
复制代码上面这样写法表示 BeanDefinition 在构建 bean 对象时,会通过调用 MyFactoryBean 的构造方法来生成,并传入 mapperInterface 为 UserMapper 的 Class 对象,最终在生成 MyFactoryBean 时就会生成一个 UserMapper 接口对应的代理对象作为 bean 了。
到这里,代理对象有了,我们还有一件事需要做,就是怎么定义一个 BeanDefinition,并把它添加到 Spring 中,Spring 中有一个类 ImportBeanDefinitionRegistrar 可以做到
public class MyImportBeanDefinitionRegistrar implements ImportBeanDefinitionRegistrar {
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
BeanDefinitionBuilder builder = BeanDefinitionBuilder.genericBeanDefinition();
AbstractBeanDefinition beanDefinition = builder.getBeanDefinition();
beanDefinition.setBeanClass(MyFactoryBean.class);
beanDefinition.getConstructorArgumentValues().addGenericArgumentValue(UserMapper.class);
// 添加 beanDefinition
registry.registerBeanDefinition("my"+UserMapper.class.getSimpleName(), beanDefinition);
}
}
复制代码然后在配置类上使用@import 注解导入该类
@Configurable
@ComponentScan("com.zcy.demo.bean")
@Import(MyImportBeanDefinitionRegistrar.class)
public class MyConfig {
}
复制代码这样在 Spring 启动后,会生成一个 BeanDefinition,这个 BeanDefinition 会生成一个 MyFactoryBean,并生成一个对应的 UserMapper 的代理对象。
最后总结一下,要在 Spring 中使用 Mybatis,需要做如下事情:
1、定义一个 MyFactoryBean
2、定义一个 MyImportBeanDefinitionRegistrar
3、在 AppConfig 上添加一个注解@Import(MyImportBeanDefinitionRegistrar.class)
总结
代码可以优化一下
单独再定义一个@MyScan 注解,可以直接标注到 MyConfig 上
@Retention(RetentionPolicy.RUNTIME)
@Import(MyImportBeanDefinitionRegistrar.class)
public @interface MyScan {
}
复制代码然后在 MyImportBeanDefinitionRegistrar 中,可以再去扫描 Mapper,在 MyImportBeanDefinitionRegistrar 可以通过 AnnotationMetadata 获取到对应的@MyScan 注解,所以可以在 @MyScan 上设置一个 value,表示指定待扫描的包路径。然后在 MyImportBeanDefinitionRegistrar 中获取所设置的包路径,扫描该路径下的所有 Mapper,生成 BeanDefinition,放入 Spring 容器中。
到这里,有没有觉得 Spring 如何管理 Mapper 就如此透彻,最后在总结一下:
- 定义一个 MyFactoryBean,用来将 Mybatis 的代理对象生成一个 bean 对象
- 定义一个 MyImportBeanDefinitionRegistrar,用来生成不同 Mapper 对象的 MyFactoryBean
- 定义一个@MyScan,用来在启动 Spring 时执行 MyImportBeanDefinitionRegistrar 的逻辑,并指定包路径
以上这个三个要素分别对象 org.mybatis.spring 中的:
- MapperFactoryBean
- MapperScannerRegistrar
- @MapperScan
最近面试的小伙伴很多,对此我整理了一份Java面试题手册:基础知识、JavaOOP、Java集合/泛型面试题、
Java异常面试题、Java中的IO与NIO面试题、Java反射、Java序列化、Java注解、多线程&并发、JVM、Mysql、Redis、
Memcached、MongoDB、Spring、SpringBoot、SpringCloud、RabbitMQ、Dubbo、MyBatis、ZooKeeper、数据结构、算法、
Elasticsearch、Kafka、微服务、Linux等等。可以分享给大家学习。【持续更新中】领取方式【999】就可以领取资料了