单目3D检测新SOTA!PersDet:透视BEV中进行3D目标检测
后台回复【ECCV2022】获取ECCV2022所有自动驾驶方向论文!
文章题目:PersDet: Monocular 3D Detection in Perspective Bird’s-Eye-View
论文链接:https://arxiv.org/pdf/2208.09394.pdf
作者单位:旷视科技
一、摘要
目前,在鸟瞰图 (BEV)中检测3D目标要优于其它用于自动驾驶和机器人领域的3D目标检测器。但要将图像特征转化为BEV需要特殊的操作进行特征采样。这些操作在很多边缘计算设备上并不支持,这给部署检测器带来了额外的障碍。为了解决这一问题,我们重新讨论了BEV表示的生成,并提出了在透视BEV上检测目标的方法:一种新的BEV表示,不需要特征采样。我们证明了透视BEV特性同样可以享受到BEV范式的好处。此外,透视BEV解决了特征采样带来的问题,提高了检测性能。基于此,我们提出PersDet,在透视BEV空间获取高性能目标检测效果。在实现简单和内存高效结构的同时,使用ResNet-50作为骨干网络,PersDet在nuScenes上优于现有的其它SOTA单目检测方法,达到34.6% mAP和40.8% NDS。
二、介绍
3D目标检测在自动驾驶系统中非常重要,如摄像头、LiDAR、RaDARs等都是常用的传感器,其中基于摄像头的3D目标检测方法由于成本较低,现在受到越来越多的关注。
从检测视角来看,基于摄像头的3D目标检测分为两种:一种是Camera-View(CV)的检测器,一种是鸟瞰图视角(BEV)检测器。CV检测器比如FCOS3D、PGD等,都是遵循了2D检测器的设计,扩展检测头适配3D任务。从nuScenes榜单上看,这些CV检测方法表现不如基于BEV的方法。但由于CV检测器可以保持类似2D检测器一样的全卷积结构,在部署的时候非常友好,所以在工业界很受欢迎。
在BEV场景下检测3D目标是一种新的范式,并且得到了较好的效果。为了在BEV空间进行检测,他们使用了一个视角转换阶段,将Camera-View特征转换为BEV特征。然后将扩展的2D检测head(Yin、Zhou和Krahenbuhl 2021)应用于变换后的BEV特征。在现有的转化方法中,基于Lift-Splat (Philion and Fidler 2020)的方法因其高效、有效而受到越来越多的关注。基于lift-splatt的方法转换视角分为三步:
-
利用深度估计将2D图像特征映射到3D空间。这一步生成一个3D表示,可以从BEV上查看特征。
-
将3D图像特征与预定义的BEV网格/anchors对齐。这些anchors通常在空间中有规律地(即均匀地)分布。由于3D表示存在透视图像产生的透视畸变,因此该步骤采用特征采样算子,将特征与BEV的anchors对齐,去除畸变。
-
将三维特征沿高度维度折叠,得到二维BEV特征。
Lift-Splat转换的其他步骤比较简单,而第二步采用的特征采样操作无法在许多设备上部署或加速,这是使BEV检测器应用到工业界的主要障碍。我们就思考:能否在保持简单流程的同时享受BEV范式的好处?
为了回答以上问题,我们深入研究了特征和anchors之间的对齐细节,就如下图所示。Camera-View中,是沿着高度和宽度在图像平面上放置anchors,这些anchors自然的就和下采样的图像特征对齐了。由于BEV特征的语义对应水平参考平面上的目标,因此BEV检测器的anchors分布在宽度轴和深度轴上。
由于Lift-Splat方法最初是为分割任务设计的,这些锚点通常均匀分布在参考平面上。这种分布引入了特征采样的需求,透视影响体现在投影特征中,但anchors中没有。在本文中,我们提出将透视影响引入到anchors中,而不是将透视影响从特征中移除。这种情况下,语义特征可以与真实的anchors对齐,而不用做特征采样。

此外,由于现有方法中的特征采样操作往往伴随着过采样和欠采样现象,会导致的信息丢失和结构失真,所以去除特征采样会带来额外的性能提升。
通过这种改进,我们构建了一个高性能的检测器PersDet,可以直接对透视BEV特征进行检测。具体地说,我们首先像Lift-Splat做的那样,将图像特征投影到透视BEV空间。然后,我们不用对特征进行采样,而是直接折叠这个3D表示,并将我们的PersHead用透视畸变的方式放在BEV特征上。PersHead在透视空间中部署了回归anchors,在偏远区域anchors是稀疏的,反之则是密集的。在这种情况下,外部产生的特征自然与anchors对齐。
我们的贡献如下:
-
我们指出了特征采样的缺点,并提出了透视BEV来避免这一过程。
-
我们提出了基于透视BEV特征的目标检测方法,验证了透视BEV特征的有效性。
-
提出的PersDet在nuScenes基准测试中实现了SOTA表现,同时显示了部署友好的优势。
三、方法
1、BEV 检测框架
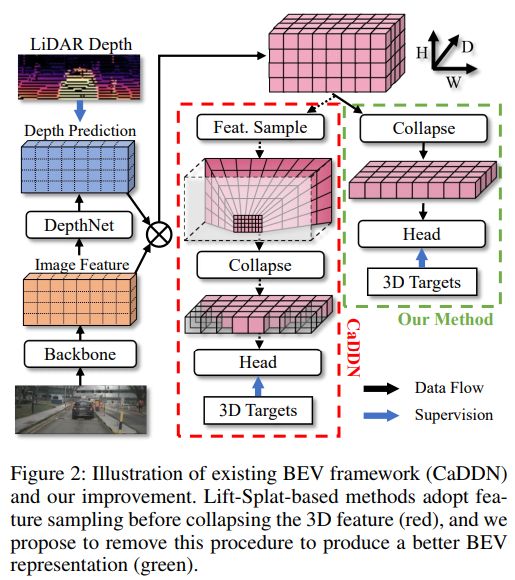
以CaDDN为代表的现有BEV检测器遵循Lift-splat模式,一个特征提取器提取特征和一个DepthNet来进行深度预测。深度预测采用LiDAR获取的真值深度进行单独监督。注意,激光雷达深度只在训练期间使用,最终的检测器在测试和验证阶段只需要图像。具体见下图的流程:
BEV检测框架使用3D目标框和深度监督信息进行统一训练,整体PersDet的损失函数定义如下:

有了图像特征,有了深度信息,那么3D特征就能得到,如上公式(2)。传统上,生成的3D特征会进行采样或池化来和固定的anchors对齐,消除透视影响。CollapseConv用来生成特征采样后的2D BEV表示。但特征采样操作存在一些缺点,无法达到最优。
2、特征采样的缺点
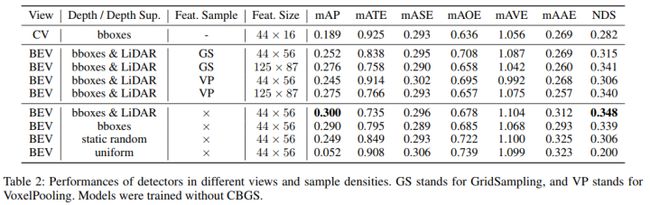
我们选择CaDDN作为单目BEV检测器的代表,其采用网格采样的方法对BEV特征进行对齐。
过采样和欠采样
网格采样(Reading et al. 2021)基于空间坐标信息和预定义的网格(anchors)来操作样本特征。anchors设置对该步骤的性能和效率有着决定性的影响。见下图,在给出密集anchors点分布时,过采样的问题会导致重复的特征表示。过采样现象会造成内存的浪费和结构完整性的恶化。相反,稀疏分布可能导致欠采样,其中一些源特征没有采样,导致信息丢失。更糟糕的是,过采样和欠采样问题不能完全解决,因为它们总是同时发生。由于透视相机的FOV在不同的深度下有不同的宽度(距离宽,距离窄),近场总是存在欠采样问题,远场总是存在过采样问题。通过调整超参数获得的最佳性能也只是一种折衷。因此,一旦对特征进行采样,特征的退化是不可避免的。

内存效率低
不规则的相机视野(FOV,上图中的绿色区域)导致常规BEV特性的内存效率低。由于计算设备以矩阵的形式存储和计算数据,而摄像机的视场是一个截锥体,因此有很大一部分存储区域不包含有效的信息。这种低效率导致3D tensor的大小急剧增加,并伴随着大量的内存浪费。在下图中,我们展示了CaDDN探测器在不同anchors((图像的水平轴))下的性能和内存消耗。结果表明,3D tensor的内存消耗随着anchors密度的增加呈二次增长,从而导致整体内存消耗的增加。当anchors的数量增加到176,下采样问题得到了缓解,从而获得了足够的性能。然而,3D tensor的扩展使检测器的总体内存消耗增加了一倍。也就是说,为了获得合适的性能,特征采样操作会显著增加检测器的内存消耗,导致模型应用成本增加。

如上节所述,特征采样使用自定义操作,如Grid采样或体素池化(Li等,2022)。这些操作可以通过在以CUDA为代表的平台上使用自定义算子来部署和加速。然而,在边缘设备上,这样复杂的操作无法执行或加速。
因此,由于特征采样的原因,很多低端场景无法享受到BEV检测器的优势。考虑到上述特征采样的缺点,我们探索直接对未去除透视影响的BEV特征上进行检测。PersHead是针对上述问题提出的一种简单高效的目标检测方法。
3、透视BEV空间中的目标检测
Anchors 和目标
我们设计了透视anchors来与透视BEV特征进行对齐。具体地,我们用逆透视变换将均匀分布的截椎体anchors转换到真实世界坐标系下。具体公式如下:
其中,I是相机内参矩阵。逆投影后,透视anchors在远距离上分布稀疏,反之分布密集。由于这些anchors包含透视影响,因此需要对heatmap目标(比如目标得分target)进行相应的改变。如下图所示,将透视影响引入目标,来与透视特征对齐。

PersHead
我们按照CenterPoint的Head(Yin, Zhou, and Krahenbuhl 2021)来设计PersHead,使用特定任务分支进行分类和回归。由Lift-Splat模块产生BEV特征,PersHead在BEV特征上共享卷积,使用特定任务子网络进行密集预测。对于每个BEV特征网格,PersHead 预测其目标得分以及目标框属性(包括中心偏置、中心高度、尺寸、局部偏航角、方向、速度等)。整体的检测Loss如下所示:
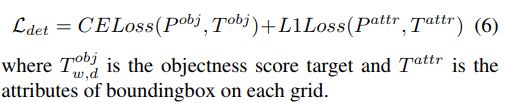
最后,根据预测的目标框属性,将目标框中心偏移量与相应ahchors的坐标相加,即可得到目标框中心的真实坐标。
四、实验
1、实验细节
数据集
我们在nuScenes上进行实验,只评估58m内的目标,且主要关注单目检测的mAP和NDS(NuScenes Detection Score)指标。mAP评估是地平面上的2D mAP。NDS是对其他指标的重新加权组合,表明整体检测能力。
训练设置
我们主干网络使用的ResNet-50,使用了一个SECOND FPN来融合多尺度图像特征。使用的分辨率为256704,batch_size=8(8×6,每个样本包好6张图像)。数据增强包括随机翻转,随机旋转,随机缩放,随机裁剪等。我们在nuScenes数据集上训练24个epoch,使用学习率=2e-4,深度权重=3、EMA策略。在与nuScenes上其他方法比较时,采用CBGS (Zhu et al. 2019)。
重建了CaDDN
为了保证公正,我们和CaDDN对齐主干、FPN、特定任务Head、图像特征大小和训练设置。对于新的nuScenes数据集,我们使用体素网格范围[2,58]×[−40,40]×[−40,40] (m)和体素网格大小[0.64,0.64,0.64] (m),因为我们的特征下采样率是16。
2、与其它SOTA比较
整体来看,我们比其它单目检测器都要好,比双目中的一些方法也有优势。
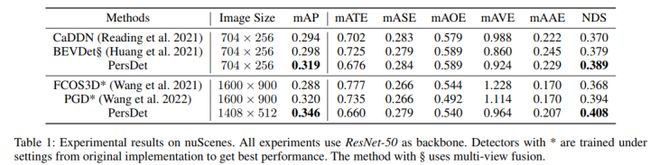
检测器在不同视角和样本密度上的表现:
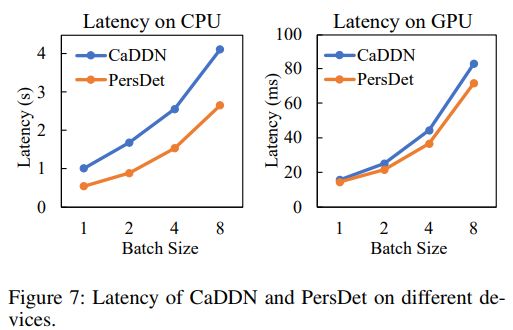
PersDet与CaDDN在不同设备上的延迟对比。
透视BEV可以获得更高的内存效率。如下图所示,常规的BEV特征留下了很大一部分“无效”空间。这些区域的存在限制了获取有价值信息的空间。


不同深度划分下的PersDet的性能。

总结
本文分析了用于3D目标检测的BEV范式,指出了两者的本质区别,BEV和Camera-View检测器是特征在深度维度上的分布。通过回顾生成BEV特征的视图转换过程,我们提出了PersDet,它在透视上执行目标检测,BEV特征不需要特征采样。我们证明,该PersDet解决了现有BEV检测器中特征采样带来的问题,并在单目3D检测器中取得了SOTA性能。根据详细的结果和消融研究,我们的方法比现有的方法性能更好,同时更简单和部署友好。