目标检测FCOS网论文阅读、损失函数解读
文章:FCOS: Fully Convolutional One-Stage Object Detection
项目源码:https://github.com/tianzhi0549/FCOS
目录
- 1 基于全卷积的单阶段检测
-
- 损失函数
- 2 FCOS基于FPN进行多层次预测
- 3 Center-ness for FCOS
- 与RetinaNet的不同
1 基于全卷积的单阶段检测
![]() 表示backbone中第i层feature map,s代表该层之前的stride。对于输入图片ground truth boxes的定义为
表示backbone中第i层feature map,s代表该层之前的stride。对于输入图片ground truth boxes的定义为![]()
![]() ,(x0, y0)、(x1, y1)分别表示真值框左上角和右下角坐标。C(i)代表该边框所属于的类别。C代表类别总数。
,(x0, y0)、(x1, y1)分别表示真值框左上角和右下角坐标。C(i)代表该边框所属于的类别。C代表类别总数。
对于feature map Fi上的每个位置(x,y),将其映射回输入图片上为![]() ,大致为与(x,y)感受野中心的附近。基于anchor的方法是将输入图片的位置作为anchor的中心,并将边框进行回归,而FCOS直接对图片的每个位置进行目标边框的回归,换言之,本文将每个像素看作训练样本,而不是只将anchor boxes看作样本,这点与语义分割的全卷积相似。
,大致为与(x,y)感受野中心的附近。基于anchor的方法是将输入图片的位置作为anchor的中心,并将边框进行回归,而FCOS直接对图片的每个位置进行目标边框的回归,换言之,本文将每个像素看作训练样本,而不是只将anchor boxes看作样本,这点与语义分割的全卷积相似。

当某点(x,y)落入任意ground-truth 边框中,则可以将其看作是postitive 样本,其类别为ground truth边框的类别。否则,该样本为negative样本,其类别设置为c*=0。本文用一个4D的向量t*=(l*,t*,r*,b*)作为回归目标,l*,t*,r*,b*分别代表距离边框四条边的边界,如图figure 1。如果一个位置落入多个边框中,则该位置就为模糊样本。目前,本文选择区域最小的边框作为回归目标。下文会通过多层次预测大幅度减少模糊样本的数量。(x,y)位置与边框Bi相关,则该位置的回归目标可以按如下方式及计算,(x,y)为每个像素点坐标。FCOS在训练的回归时尽可能利用fore-ground样本,这也是性能优于基于anchor-based方法的可能原因。
网络输出:
网络输出一个C(类别数–coco80)D及4D的向量t=(l,t,r,b),本文的类别训练并不是基于多任务训练,而是训练C个binary 分类器。本文在backbone的feature map后分别增加了4层卷积层在分类分支及回归分支前。此外,通常回归目标是positive,本文应用exp(x)在回归分支的顶部将任意实数映射到(0,∞)。FCOS相比基于anchor-based的方法减少了9倍的网络输出。
损失函数
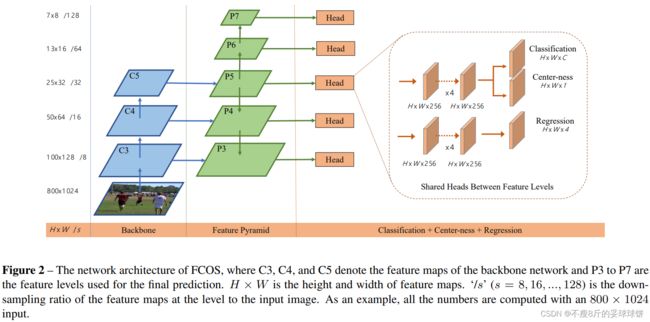
FCOS网络的输出依然包括分类和检测分支,三个分支中的centerness后面再说(centerness分支采用BCE loss)。分类分支通过卷积,输出是80维的向量,代表的是80个类别,并且80个类别接的是sigmoid,这点跟RetinaNet一致;检测分支输出的4维的向量,分别对应点到上下左右边的距离,模型结构如上图Figure 2所示。另外训练的时候,Classification采用的是focal loss,Regression采用的是IOU loss(IOU loss其实也很简单,详情可以参考论文:UnitBox),这里跟基于anchor的RetinaNet不太一样,RetinaNet回归使用的是smooth L1 loss。另外需要说明的是,网络中的头是共享的。
具体损失函数公式如下:

其中,Lcls是focal loss[15],Lreg是UnitBox[32]中的IOU loss。Npos表示正样本数,本文中λ为1是Lreg的平衡权重。在特征图Fi上的所有位置计算总和。1{c∗ i>0}是指示函数,如果是c*>0则为1,否则为0。
2 FCOS基于FPN进行多层次预测
FCOS上的存在的两个问题及解决:
- I.CNN中经过加大的stride得到的feature map可能会产生较低的最可能召回率(BPR)。对于基于anchor的方法,可以通过调整IoU的阈值来补偿较大stride导致的较低召回率,对于FCOS来说,由于较大stride后的feature map上没有位置编码信息,因此,FCOS得到的BPR可能会更低,然而,通过FCN仍可以得到较满意的BPR。因此,BPR对于FCOS来说并不是一个问题。此外,通过much-level FPN预测,BPR可以得到进一步的提高可以达到RetinaNet最好的高度。
- II.训练时,与ground truth boxes的重叠可能会产生难以理解的模糊情况,会拉低基于FCN检测器的检测能。本文通过多层次预测解决上述问题。
与FPN相似,本文在不同层次的feature map上进行不同尺寸的目标检测。利用feature map的五个层次{P3,P4,P5,P6,P7}。P3,P4,P5由backbone的C3,C4,C5后接1x1的卷积得到。 如figure 2所示,P6,P7在分别在P5,P6上设置stride 为2并增加卷积层得到。最终,P3,P4,P5,P6,P7的stride分别为8,16,32,64,128。
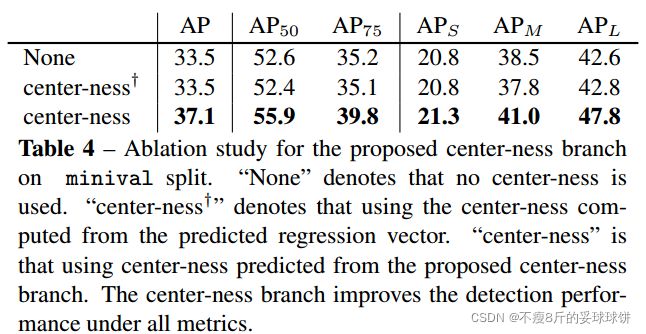
不同于基于anchor的检测器,在不同层的feature map上应用不同尺寸的anchor,本文直接限制边界框回归的范围。首先计算出所有层上每个位置对应的回归目标,l*,t*,r*,b*,若一个位置满足下列两个条件则将其认定为负样本,也没有进行回归的意义了。max(l*,t*,r*,b*)>mi或者max(l*,t*,r*,b*) 我们在不同的特征级别之间共享头部,不仅使检测器参数有效,而且提高了检测性能。然而,不同层的feature level需要回归指定大小的回归框。如P3的范围为[0,63],P4的为[64,128]。因此,对于不同的feature level使用相同的head这是不合理的。因此,本文并不使用标准的exp(x),而是增加了一个训练参数si,基于exp(si x)根据Pi进行自动调整。 另外为了进一步降低目标的误检,作者引入了Center-ness层。 在进行多层次预测后,FCOS仍与基于anchor的检测器的性能存在一定差距。这是由于距离目标中心较远的位置预测出大量低质量的边框造成的。本文在不引进参数的情况下来抑制低质量的边框。平行于分类分支增加了一个1维的分支, 用于预测位位置的"center-ness"如该位置到目标物中心位置的距离。如figure 2所示,给定一个回归目标t*,l*,r*,b*,center-ness的回归定义如下所示,从公式可见最中心的点的centerness为1,距离越远的点,centerness的值越小。 训练的时候,使用Binary CrossEntropy Loss。 在inference阶段,网络前向之后,将该Center-ness的值与classification的输出值相乘,这样距离中心远的预测框的score会变小,从而一批误检框在NMS阶段更有可能被过滤掉,提高识别准确度。 这里,作者也对比了使用center-ness的效果,结果如下表所示,其中center-ness+,代表的是在检测分支上直接进行中心点的预测,而不是在分类上增加一个分支。结果可以发现在检测分支进行直接预测的结果并没有原来的好,在分类分支增加了center-ness,mAP可以提高大约3个点左右。另外作者也进行了实验,如果center-ness预测的全部都对的情况下(理想情况),mAP可以达到42.1%的准确率,说明其实center-ness还是有提升空间的,所以作者进一步进行了实验,将center-ness加深,结果显示mAP从36.6%提高到了36.8%。 因为FCOS的模型结构和RetinaNet非常相似,作者在论文中也提到backbone阶段的超参数和后处理部分都和RetinaNet完全一样,因此这里列举一下FCOS和RetinaNet的不同来帮助理解。 1.模型结构的不同 2.Loss的不同 参考链接:3 Center-ness for FCOS

这里用开根的作用是降低center-ness的衰减速度。center-ness的取值范围为0至1,因此使用binary 交叉熵损失进行训练。当进行测试时,通过结合对应的分类分数及多个预测得到的center-ness计算得到分数用于对检测的边框进行排序。因此,center-ness可以降低距离目标中心较远预测框的权重。虽然其更高的概率值,但仍可能会被NMS干掉。对比基于anchor的检测器设置两个IoU的阈值用于对anchor进行标记,center-ness可以看作是soft threshold。在网络训练时进行学习,并不需要花费时间及经历进行微调。同时本文方法可以将任意落入ground box的位置看作为正样本,因此,可以尽可能的利用正样本用于回归。

与RetinaNet的不同
https://blog.csdn.net/Chunfengyanyulove/article/details/95091061
https://www.cnblogs.com/fourmi/p/10771436.html
https://blog.csdn.net/ooooocj/article/details/109364523