【李宏毅】深度学习——作业1-Covid-19(Regression)
任务描述
目标:预测COVID-19
给出过去三天在美国的一些州的统计的一些人的资料和阳性的比例(无第三天的),预测第三天阳性的比例

这些统计信息包括40个州,每个州都用一个one-hot向量编码,并且给出了这些人的一些基本状况,比如是否生病(
4个),行为上(8个),精神健康上(5个),texted_positive(1个,这个也是我们要预测的值),所以每个样例有18个特征值。
Data–Training
train.csv(2700samples, 每个州68个,40个州)

Data–Testing
test.csv(893samples,最后一天是没有阳性比例的,需要预测)

数据集
分析数据
- 训练集一共2700行,95列,每一行是一个one-hot向量和三天的特征,one-hot向量维度40,每天十八个特征值,所以是
18*3+40 = 94,还有一列是id- 测试集一共894行,94列,每一行是一个one-hot向量和三天的特征,one-hot向量维度40,前两天十八个特征值,第三天17个特征值,所以是
18*2+17+40 = 93,还有一列是id- 每一行都是一个sample
特征提取
对于原始数据,我们应该删除第一行第一列,所以训练集剩下93列,测试集92列,训练集的最后一列是我们要预测的属性,作为target,将训练集拿出1/10作为验证集。对于one-hot向量做一个正则化处理。
定义自己的数据集
- 从train.csv读取训练数据到内存
- 提取特征
- 将数据集分为训练和验证集
- 将特征正则化
class COVID19Dataset(Dataset):
'''处理下载下来的数据集'''
def __init__(self, path, mode='train', target_only=False):
self.mode = mode
# 读数据到内存
with open(path, 'r') as fp:
data = list(csv.reader(fp))
data = np.array(data[1:])[:, 1:].astype(float)
if not target_only:
feats = list(range(93))
else:
pass
if mode == 'test':
data = data[:, feats]
self.data = torch.FloatTensor(data)
else:
target = data[:, -1]
data = data[:, feats]
# 划分训练和验证集
if mode == 'train':
indices = [i for i in range(len(data)) if i % 10 != 0]
elif mode =='dev':
indices = [i for i in range(len(data)) if i % 10 == 0]
self.data = torch.FloatTensor(data[indices])
self.target = torch.FloatTensor(target[indices])
# 正则化 每
self.data[:, 40:] = \
(self.data[:, 40:] - self.data[:, 40:].mean(dim=0, keepdim=True)) \
/ self.data[:, 40:].std(dim=0, keepdim=True)
self.dim = self.data.shape[1]
print('Finished reading the {} set of COVID19 Dataset ({} samples found, each dim = {})'
.format(mode, len(self.data), self.dim))
def __getitem__(self, index):
if self.mode in ['train', 'dev']:
return self.data[index], self.target[index]
else:
return self.data[index]
def __len__(self):
return len(self.data)
定义DataLoader
# DataLoader
def prep_dataloader(path, mode, batch_size, n_jobs=0, target_only=False):
dataset = COVID19Dataset(path, mode=mode, target_only=target_only)
dataLoader = DataLoader(dataset, batch_size, shuffle=(mode == 'train'), drop_last=False, num_workers=n_jobs, pin_memory=True)
return dataLoader
定义我们的model
这里只用一个简单的两次全连接网络来实现模型,用MSELoss作为损失进行训练
# DNN
class NeuralNet(nn.Module):
def __init__(self, input_dim):
super(NeuralNet, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 64),
nn.ReLU(),
nn.Linear(64, 1)
)
self.criterion = nn.MSELoss(reduction='mean')
def forward(self, x):
return self.net(x).squeeze(1)
def cal_loss(self, pred, target):
return self.criterion(pred, target)
定义一些训练时需要的参数
# 定义相关参数
device = get_device()
os.makedirs('models', exist_ok=True) # 保存训练模型
target_only = False
config = {
'n_epochs' : 3000, # 训练次数
'batch_size' : 270, # 批量大小
'optimizer' : 'SGD', # 优化器
'optim_hparas' : { # 优化器的参数
'lr' : 0.001, # 学习率
'momentum' : 0.9
},
'early_stop' : 200, #用来提前终止 如果200轮训练都模型都没有进步
'save_path' : 'models/model.pth' # 模型保存路径
}
验证
验证集可以用来评估模型在训练期间的好坏,也可以用来提前终止无用的训练
# 定义验证函数 在训练期间使用
def dev(dv_set, model, device):
model.eval()
total_loss = 0
for x, y in dv_set:
x, y = x.to(device), y.to(device)
with torch.no_grad():
pred = model(x)
mse_loss = model.cal_loss(pred, y)
# detach() 返回一个新的tensor cpu()取出tensor放到cpu上面 numpy只能放在cpu上面
# 跟.data差不多 但是detach更安全 都不会计算梯度
total_loss += mse_loss.detach().cpu().item() * len(x)
return total_loss
训练
# tarin
def train(tr_set, dv_set, model, config, device):
n_epochs = config['n_epochs']
# getattr(object, name[, default]) 函数用于返回一个对象属性值 object是对象
optimizer = getattr(torch.optim, config['optimizer'])(model.parameters(), **config['optim_hparas'])
min_mse = 1000 # 最小的损失
loss_record = {'train':[], 'dev':[]} # 训练和验证的损失
early_stop_cnt = 0
epoch = 0
while epoch < n_epochs:
model.train()
for x, y in tr_set:
optimizer.zero_grad()
x, y = x.to(device), y.to(device)
pred = model(x)
mse_loss = model.cal_loss(pred, y)
mse_loss.backward()
optimizer.step()
loss_record['train'].append(mse_loss.detach().cpu().item())
# 每一轮训练结束,在验证集上验证模型
dev_mse = dev(dv_set, model, device)
if dev_mse < min_mse:
# 如果模型提升了 保存模型
min_mse = dev_mse
print('Saving model (epoch = {:4d}, loss = {:.4f})'
.format(epoch + 1, min_mse))
torch.save(model.state_dict(), config['save_path'])
early_stop_cnt = 0
else :
# 没有更新 参数加一 用来最后判断多少次没有更新
early_stop_cnt += 1
epoch += 1
loss_record['dev'].append(dev_mse)
if early_stop_cnt > config['early_stop']:
# 如果模型损失经过了early_syop次都不再更新 停止训练
break
print('Finished training after {} epochs'.format(epoch))
return min_mse, loss_record
加载数据集和定义模型
tr_path = 'train.csv'
tt_path = 'test.csv'
# 加载数据集和构造模型
tr_set = prep_dataloader(tr_path, 'train', batch_size=config['batch_size'], target_only=target_only)
dv_set = prep_dataloader(tr_path, 'dev', config['batch_size'], target_only)
tt_set = prep_dataloader(tt_path, 'test', config['batch_size'], target_only)
model = NeuralNet(tr_set.dataset.dim).to(device)
开始训练
# 开始训练
model_loss, model_loss_record = train(tr_set, dv_set, model, config, device)
plot_learning_curve(model_loss_record, title="deep model")
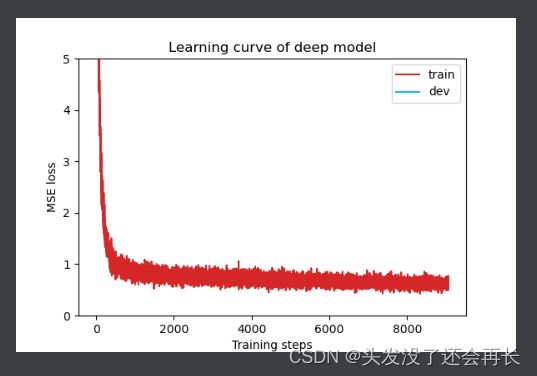
测试
# test
def test(tt_set, model, device):
model.eval()
preds = []
for x in tt_set:
x = x.to(device)
with torch.no_grad():
pred = model(x)
preds.append(pred.detach().cpu())
preds = torch.cat(preds, dim=0).numpy() # 将所有预测转换成一个numpy数组
return preds
开始预测并保存预测结果
def save_pred(preds, file):
''' Save predictions to specified file '''
print('Saving results to {}'.format(file))
with open(file, 'w') as fp:
writer = csv.writer(fp)
writer.writerow(['id', 'tested_positive'])
for i, p in enumerate(preds):
writer.writerow([i, p])
preds = test(tt_set, model, device) # predict COVID-19 cases with your model
save_pred(preds, 'pred.csv') # save prediction file to pred.csv
参考文献
李宏毅老师的代码地址(GitHub)
Homework 1: COVID-19 Cases Prediction (Regression)