OpenCV人脸识别之LBPH算法(局部二值模式方法)
人脸识别LBPH算法
人脸识别是指将一个需要识别的人脸和人脸库中的某个人脸对应起来(类似于指纹识别),目的是完成识别功能,该术语需要和人脸检测进行区分,人脸检测是在一张图片中把人脸定位出来,完成的是搜寻的功能。
1.LBPH算法介绍原理图
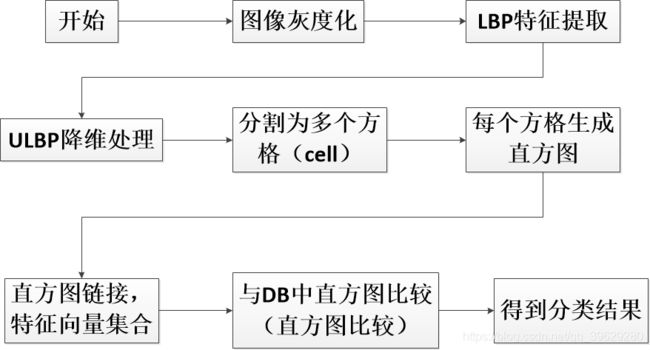
2.LBP算子
原始的LBP算子定义为在3*3的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于或等于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数即LBP码,共256种),即得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理特征。如下图所示:
| 1 |
2 |
4 |
| 5 |
5 |
10 |
| 8 |
2 |
4 |
| 0 |
0 |
0 |
| 1 |
|
1 |
| 1 |
0 |
0 |
Binary:00010011 Decimal:19
基本的 LBP算子的最大缺陷在于它只覆盖了一个固定半径范围内的小区域,这显然不能满足不同尺寸和频率纹理的需要。为了适应不同尺度的纹理特征,Ojala等对LBP算子进行了改进,将3×3邻域扩展到任意邻域,并用圆形邻域代替了正方形邻域,改进后的LBP算子允许在半径为R的圆形邻域内有任意多个像素点,从而得到了诸如半径为R的圆形区域内含有P个采样点的LBP算子,OpenCV中正是使用圆形LBP算子,下图示意了圆形LBP算子:
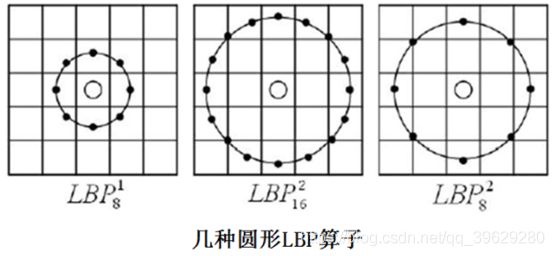
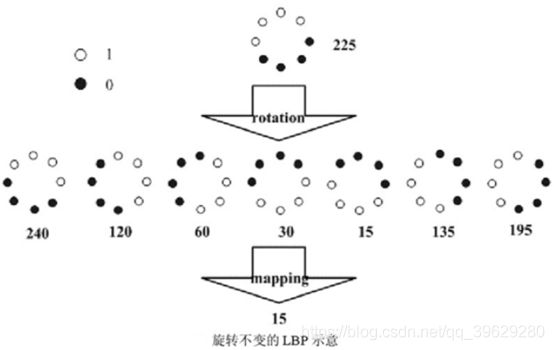
3.旋转不变性
从LBP的定义可以看出,LBP算子是灰度不变的,但却不是旋转不变的,图像的旋转就会得到不同的LBP值。Maenpaa等人又将LBP算子进行了扩展,提出了具有旋转不变性的LBP算子,即不断旋转圆形邻域得到一系列初始定义的LBP值,取其最小值作为该邻域的LBP值。下图给出了求取旋转不变LBP的过程示意图,图中算子下方的数字表示该算子对应的LBP值,图中所示的8种LBP模式,经过旋转不变的处理,最终得到的具有旋转不变性的LBP值为15。也就是说,图中的8种LBP模式对应的旋转不变的LBP码值都是00001111。
4. 等价模式
考察LBP算子的定义可知,一个LBP算子可以产生多种二进制模式(p个采样点)如:3x3邻域有p=8个采样点,则可得到2^8=256种二进制模式;5x5邻域有p=24个采样点,则可得到2^24=16777216种二进制模式,以此类推......。显然,过多的二进制模式无论对于纹理的提取还是纹理的识别、分类及信息存取都是不利的,在实际应用中不仅要求采用的算子尽量简单,同时也要考虑到计算速度、存储量大小等问题。因此需要对原始的LBP模式进行降维。
Ojala提出一种“等价模式”(Uniform Pattern)来对LBP算子进行降维,Ojala等认为图像中,某个局部二进制模式所对应的循环二进制数从0—>1或从1—>0,最多有两次跳变,该局部二进制模式所对应的二进制就成为一个等价模式。
如00000000,00111000,10001111,11111111等都是等价模式类。判断一个二进制模式是否为等价模式最简单的办法就是将LBP值与其循环移动一位后的值进行按位相与,计算得到的二进制数中1的个数,若个数小于或等于2,则是等价模式;否则,不是。除了等价模式以外的模式都归一一类,称为混合模式类,例如10010111(共四次跳变)。跳变的计算方法:如10010111,首先第一二位10,由1—>0跳变一次;第二、三位00,没有跳变;第三、四位01,由0—>1跳变一次,第四、五位10,由1—>0跳变一次;第五六位01,由0—>1跳变一次;第六七位11,没有跳变;第七八位11,没有跳变;第八位和第一位11,没有跳变;故总共跳变4次。
通过这种改进,二进制模式的种类大大减少,而不会丢失任何信息,模式种类由原来的2^p减少为p*(p-1)+2种。但等价模式代表了图像的边缘、斑点、角点等关键模式,等价模式占了总模式中的绝大多数,所以极大的降低了特征维度。利用这些等价模式和混合模式类直方图,能够更好地提取图像的本质特征。
5. LBP特征用于检测的原理
显而易见的是,上述提取的LBP算子在每个像素点都可以得到一个LBP“编码”,那么,对一幅图像(记录的是每个像素点的灰度值)提取其原始的LBP算子之后,得到的原始LBP特征依然是“一幅图片”(记录的是每个像素点的LBP值)。
如果将以上得到的LBP图直接用于人脸识别,其实和不提取LBP特征没什么区别,在实际的LBP应用中一般采用LBP特征谱的统计直方图作为特征向量进行分类识别,并且可以将一幅图片划分为若干的子区域,对每个子区域内的每个像素点都提取LBP特征,然后,在每个子区域内建立LBP特征的统计直方图。如此一来,每个子区域,就可以用一个统计直方图来进行描述,整个图片就由若干个统计直方图组成,这样做的好处是在一定范围内减小图像没完全对准而产生的误差,分区的另外一个意义在于我们可以根据不同的子区域给予不同的权重,比如说我们认为中心部分分区的权重大于边缘部分分区的权重,意思就是说中心部分在进行图片匹配识别时的意义更为重大。 例如:一幅100*100像素大小的图片,划分为10*10=100个子区域(可以通过多种方式来划分区域),每个子区域的大小为10*10像素;在每个子区域内的每个像素点,提取其LBP特征,然后,建立统计直方图;这样,这幅图片就有10*10个子区域,也就有了10*10个统计直方图,利用这10*10个统计直方图,就可以描述这幅图片了。之后,我们利用各种相似性度量函数,就可以判断两幅图像之间的相似性了,OpenCV在LBP人脸识别中使用的是如下相似度公式:
6.OpenCV自带的LBPH人脸识别算法流程如下:
1. 加载数据
用vector
注:如果图像对应标签相同证明是同一个人;
2. 训练模型
2.1 初始化参数
(1) 初始化采样半径(radius=1),邻域大小(neighbors=8),宽度方向和高度方向格子数(gridx=8, gridy=8,),直方图距离阈值(threshold = DBL_MAX)。
(2) 利用 labels初始化模型标签数组 _labels。
2.2 LBP编码
计算各图像LBP编码图像LBPi ,大小为(w-2*radius,h-2*radius),各像素值计算方法如下:
(1) 依次计算所有像素坐标第n邻域对应像素偏移坐标(dx,dy)n![]()
![]()
![]()
(2) 双线性差值计算所有像素坐标(x,y)第n邻域的灰度值 gray(x,y)n![]() 以及编码值:lbp(x,y)n
以及编码值:lbp(x,y)n![]() :
:
lbp(x,y)n=1,(grayx,yn≤gray(x,y)n)
lbp(x,y)n=0,(grayx,yn>gray(x,y)n)
(3) 计算所有像素的LBP编码值:
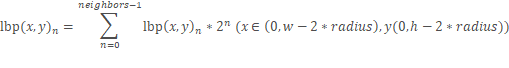
2.3 计算直方图
各LBPi图像对应直方图矩阵HISTi宽度为2neighbors=256![]() ,高度为gradx*grady
,高度为gradx*grady
- 计算每个格子的宽度和高度:
w_grad=LBP.cols/gridx
h_grad=LBP.rows/gridy
(2) 按照行序统计每个格子内直方图各值的高度,并依次将结果存储在HISTi的每一行;并对直方图高度归一化,即所有直方图高度除以w_grad*h_grad。以行为主序将HISTi转换为为1行列的向量矩阵。
(3) 将所有人脸训练图像直方图矩阵HISTi插入到成员变量_histograms,其中_histograms的行数为gradx*grady*2neighbors![]() ,列数为N。
,列数为N。
3. 更新模型
首先设置更新模型图像数据和图像对应标签数据;更新模型算法和训练模型算法一致,唯一的区别是在训练模型之前不需要将_labels和_histograms清零。
4. 预测
按照3中方法计算待识别人脸图片直方图矩阵HISTq,计算HISTq和训练模型中各图像_histogramsi直方图之间的距离,记录距离最dis_min 的直方图图像对应标签label_min,如果dis_min
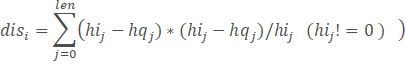
其中,分别为训练模型第i个直方图值为j的直方图高度和待匹配图像值为j的直方图高度;len为直方图最大值。