Kubernetes部署(六):k8s项目交付----(3)集群监控
一、介绍Prometheus
Prometheus(普罗米修斯)是一个最初在SoundCloud上构建的监控系统。自2012年成为社区开源项目,拥有非常活跃的开发人员和用户社区。为强调开源及独立维护,Prometheus于2016年加入CNCF,成为继kubernetes之后的第二个托管项目。
官网:Prometheus - Monitoring system & time series database
源码托管:https://github.com/prometheus
Prometheus的特点:
多维数据模型:由度量名称和键值对标识的时间序列数据。
内置时间序列数据库:TSDB
promQL:一种灵活的查询语言,可以利用多维数据完成复杂查询
基于HTTP的pull(拉取)方式采集时间序列数据(exporter)
同时支持PushGateway组件收集数据
通过服务发现或静态配置发现目标收集数据
多种图形模式及仪表盘支持
支持做为数据源接入Grafana
多维数据模型:普罗米修斯它承载了数据持久化用的中间件。内置时间序列数据库:基于时间序列存储的,内置时间序列数据库:TSDB,并非关系型数据库(mysql)形式的二维表,类似于非关系型数据(mongodb)json格式,所以没有行跟列的说法。但是多维数据模型大致可以理解为关系型数据库中列很多,一维代表一列,可以用不同的维度(列),对存储的数据查询跟索引。不同的查询检索,跟不同的过滤条件去查到我想要的监控的信息。注:查询到的不是真正的监控的指标,而是度量名,也就是查询到的不是一个数值,而是一个函数。为什么使用TSDB:因为对于监控而言,不需要强制要求数据一致性,监控软件针对数据严谨性并不是高要求,丢一条两条无所谓,所以传统的zabbix选择数据库(mysql)已经过时,应该使用非关系型数据库。而且监控软件针对时间很重要,所以选择时间序列数据库:TSDB,可以选择其他的时间序列数据库。 promQL:普罗米修斯提供一种标准的查询语言,名字叫 promQL,类似如sql(结构化查询语言),不同的是promQL语言拥有复杂的一堆的聚合、模型等。普罗米修斯跟zabbix区别:普罗米修斯跟zabbix采集方式略有不同。zabbix分主动跟被动方式,分为服务端和代理节点,代理节点中可以通过脚本获取任何想要的信息,在通过zabbix客户端推送给服务端即可。但普罗米修斯默认只能跟被监软件件基于HTTP或者HTTPS拉取的方式通讯。普罗米修斯采集:有些服务不使用http/https接口如何通信,需要从官网下载指定的exporter,由exporter跟你的内部指定的被监控软件进行通讯,比如MySQL的exporter,MySQL的exporter安装并配置mysql的连接串,进而通过TCP sock跟mysql通信,然后由exporter暴露HTTP或者HTTPS接口,普罗米修斯就可以抓了。支持PushGateway:默认普罗米修斯基于http/https协议去向exporter拉取数据,但也支持PushGateway(推),exporter携带监控数据主动推给普罗米修斯。什么时候用推,有一个特定的使用场景(假如监控的目标是一个转瞬即逝的任务,比如一个jobs,在某天执行一次,0.1s执行完,由于时间间隔太短,普罗米修斯拉取不到。这种情况需要用PushGateway主动推)。通过服务发现或静态配置发现代理端exporter进行目标收集数据:两种发现目标的方式,一种叫服务发现一种叫静态配置,静态配置容易一些,但是用的少。支持做为数据源接入Grafana:Grafana仪表盘
Prometheus架构:
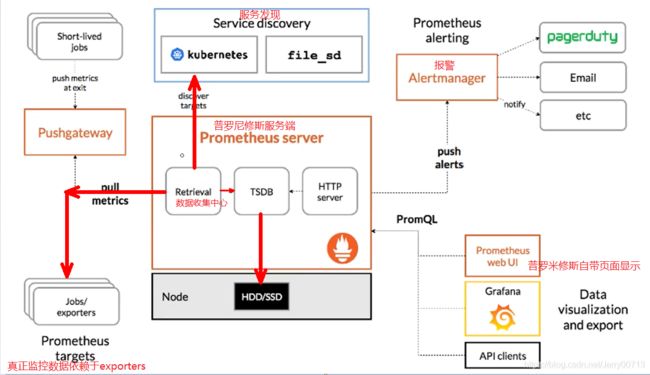
服务发现:(重点)两种发现目标的方式,一种是基于kuberntes本身元数据的自动发现,叫kuberntes_sd(kuberntes_service discovery)。专门用来服务基于k8s编排的容器云监控的自动发现,重中之重。另一种叫做file_sd。专门应用于不在k8s中服务,也可以实现自动发现,但是此方法需要写自动发现规则。是你把自动发现规则写到文件 ,基于文件自动发现。
Retrieval:数据收集中心,一要收集自动发现的规则,二还要收集exporters收集的监控指标。都由Retrieval帮助汇总跟收集,然后传到TSDB。
TSDB:时间序列数据库,可以落盘到HDD/SSD
HTTP server:普罗米修斯本身还提供可http server , 主要用于上图右侧服务,一要服务于报警push alerts推报警信息,二是通过PromQL给Prometheus web ui 或者grafana提供数据查询的接口。

思考:为什么zabbix不能监控k8s容器
比如最简单的让zabbix监控是不是已经启动的nginx服务的pod,都不用检测状态是不是RUNING,只要有nginx的pod就行。首先zabbix是非k8s内部,无法像kubectl这种查看pod,所以只能通过查看docker,比如nginx启动一个pod,名字是nginx-6s6z6adas-cas2,可以用docker ps -a |grep nginx-6s6z6adas-cas2查看并监控它,这时需要进行版本发布,kubectl会删除nginx-6s6z6adas-cas2,重新拉起新的容器,而新的容器的名字一定不是nginx-6s6z6adas-cas2,所以这个时候zabbix就会报警,提示nginx服务宕机了,但我们只是做了版本升级。
二、搭建Prometheus
架构流程
先搭建4个Prometheus targets(Jobs exporters),在搭建Prometheus server,讲解配置Service discovery(规则),在搭建Grafana,讲解Alertmanager(报警)
1、交付Exporters
各种Exporters下载地址:https://prometheus.io/download/
目前要监控k8s集群内部资源需要4个exporters(kube-state-metrics、node-exporters、cadvisor、blackbox-exporter),之前讲解过,Prometheus跟zabbix不同,Prometheus是主动获取客户端的监控项,所以每监控一个事件,就需要交付一个exporters规则
1.1、部署kube-state-metrics
kube-state-metrics用来收集k8s状态信息,或者收集基本状态信息的一个监控代理。比如k8s中有多少个节点,每个节点有多少个deployment,deployment更新过多少版等等,具体的如下
Pod
有多少Pod部署在集群中?
有多少Pod处于挂起状态?
是否有足够的资源来满足Pod的请求?
Deployment
有多少Pod处于运行状态或者预期的状态?
有多少副本可用?
哪些Deployment已更新过?
Node
工作节点处于什么状态?
集群中分配了多少CPU?
是否存在不可调度的节点?
Job
Job是何时启动的?
Job是何时结束的?
多少Job失败了?
1.1.1、准备镜像
网站:Quay
[root@hdss7-200 ~]# docker pull quay.io/coreos/kube-state-metrics:v1.5.0
# 如果上述 quay.io无法访问可采用以下方式
[root@hdss7-200 ~]# docker pull quay.mirrors.ustc.edu.cn/coreos/kube-state-metrics:v1.5.0
[root@hdss7-200 ~]# docker images |grep kube-state
quay.io/coreos/kube-state-metrics v1.5.0 91599517197a 2 years ago 31.8MB
[root@hdss7-200 ~]# docker tag 91599517197a harbor.od.com:180/public/kube-state-metrics:v1.5.0
[root@hdss7-200 ~]# docker login harbor.od.com:180
[root@hdss7-200 ~]# docker image push harbor.od.com:180/public/kube-state-metrics:v1.5.01.1.2、准备资源配置清单
[root@hdss7-200 ~]# mkdir -p /data/k8s-yaml/kube-state-metrics;cd /data/k8s-yaml/kube-state-metrics
[root@hdss7-200 kube-state-metrics]# vi rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: kube-state-metrics
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: kube-state-metrics
rules:
- apiGroups:
- ""
resources:
- configmaps
- secrets
- nodes
- pods
- services
- resourcequotas
- replicationcontrollers
- limitranges
- persistentvolumeclaims
- persistentvolumes
- namespaces
- endpoints
verbs:
- list
- watch
- apiGroups:
- policy
resources:
- poddisruptionbudgets
verbs:
- list
- watch
- apiGroups:
- extensions
resources:
- daemonsets
- deployments
- replicasets
verbs:
- list
- watch
- apiGroups:
- apps
resources:
- statefulsets
verbs:
- list
- watch
- apiGroups:
- batch
resources:
- cronjobs
- jobs
verbs:
- list
- watch
- apiGroups:
- autoscaling
resources:
- horizontalpodautoscalers
verbs:
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system解释:
kind: ServiceAccount 创建一个服务账号
name: kube-state-metrics 在kube-system命名空间下创建一个kube-state-metrics服务账号
namespace: kube-system kube-system命名空间kind: ClusterRole 声明一个集群角色ClusterRole
kubernetes.io/cluster-service: "true"
name: kube-state-metrics 集群角色叫kube-state-metrics ,让kube-state-metrics获得以下资源
rules:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding 集群角色绑定
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: kube-state-metrics 定义的集群角色绑定的名字kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics 集群角色叫kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics 跟ServiceAccount的kube-state-metrics服务账号做关联绑定
namespace: kube-system
[root@hdss7-200 kube-state-metrics]# vi dp.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "2"
labels:
grafanak8sapp: "true"
app: kube-state-metrics
name: kube-state-metrics
namespace: kube-system
spec:
selector:
matchLabels:
grafanak8sapp: "true"
app: kube-state-metrics
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
labels:
grafanak8sapp: "true"
app: kube-state-metrics
spec:
containers:
- name: kube-state-metrics
image: harbor.od.com:180/public/kube-state-metrics:v1.5.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
name: http-metrics
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 8080
scheme: HTTP
initialDelaySeconds: 5
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
serviceAccountName: kube-state-metricsreadinessProbe(就绪性探针):
容器启动后,执行存活性探针为success后,代表容器起来了,pod的状态RUNING,如果没有配置,默认启动容器后success。执行就绪性探针,如果满足配置条件为success,Ready 状态从为 false变成success,并才会把此pod加入到能被调度的资源的中(Endpoint),kube-proxy才会把流量引入到此节点。此yaml中没有配置存活性探针,默认启动容器后success,如果没有配置就绪性探针,容器启动默认为success,kube-proxy才会把流量引入到此节点。但是这个服务启动的很慢,导致报错,504 not Gateway,或者404,所以配置存活性探针后,能让网站更平滑。
就绪型探针满足条件配置:
failureThreshold: 3
httpGet:
path: /healthz
port: 8080
scheme: HTTP
1.1.3、应用资源配置清单
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/kube-state-metrics/rbac.yaml
serviceaccount/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/kube-state-metrics/dp.yaml
deployment.extensions/kube-state-metrics created
1.1.4、检测正否正常
1 main.go:208] Starting metrics server: 0.0.0.0:8080 内部启动8080
1 main.go:182] Starting kube-state-metrics self metrics server: 0.0.0.0:8081 自己检测自己跑的是8081
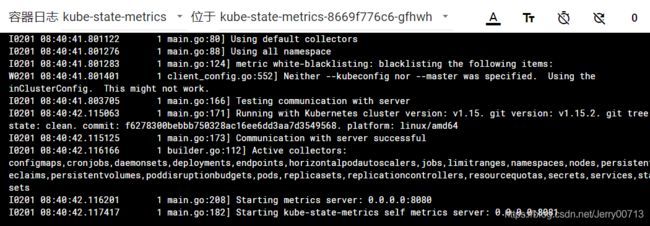
[root@hdss7-21 ~]# kubectl get pods -o wide -n kube-system |grep kube-state-metrics
kube-state-metrics-8669f776c6-gfhwh 1/1 Running 0 8m9s 172.7.21.7 hdss7-21.host.com
[root@hdss7-21 ~]# curl 172.7.21.7:8080/healthz
ok[root@hdss7-21 ~]# ok代表正常 真正取监控数据接口:http://172.7.21.7:8080/metrics,kube-state-metrics把数据汇总到(http://172.7.21.7:8080/metrics),Prometheus在从这个接口取pull数据
1.2、部署node-exporters
node-exporters用来收集k8s运算节点上基础设施信息。比如运算节点还有多少内存、cpu内存使用量、网络IO等等,具体如下。要在所有运算节点上部署。
Prometheus Node_exporter 详解
Basic CPU / Mem / Disk Info 基本CPU/Mem/磁盘信息
Basic CPU / Mem / Disk Gauge 基本CPU/Mem/磁盘规格
Basic CPU / Mem Graph 基本CPU/Mem图
Basic Net / Disk Info 基本网络/磁盘信息
CPU Memory Net Disk CPU内存网络磁盘
Memory Detail Meminfo 内存详细信息
Memory Detail Vmstat 内存细节Vmstat
Memory Detail Vmstat Counters 内存详细信息Vmstat计数器
System Detail 系统细节
Disk Datail 磁盘数据报
FileSystem Detail 文件系统详细信息
Network Traffic Detail 网络流量详细信息
Network Sockstat 网络套接字
Network Netstat 网络服务器
Network Netstat TCP 网络Netstat TCP
Network Netstat TCP Linux MIPs 网络Netstat TCP Linux MIPs
Network Netstat UDP 网络Netstat UDP
Network Netstat ICMP 网络Netstat ICMP
Node Exporter Node节点1.2.1、准备镜像
网站:Docker Hub
[root@hdss7-200 ~]# docker pull prom/node-exporter:v0.15.0
[root@hdss7-200 ~]# docker images |grep node-exporter
prom/node-exporter v0.15.0 12d51ffa2b22 3 years ago 22.8MB
[root@hdss7-200 ~]# docker image tag 12d51ffa2b22 harbor.od.com:180/public/node-exporter:v0.15.0
[root@hdss7-200 ~]# docker login harbor.od.com:180
[root@hdss7-200 ~]# docker image push harbor.od.com:180/public/node-exporter:v0.15.01.2.2、准备资源配置清单
[root@hdss7-200 k8s-yaml]# mkdir -p /data/k8s-yaml/node-exporter;cd /data/k8s-yaml/node-exporter
[root@hdss7-200 node-exporter]# vi ds.yaml
# node-exporter采用daemonset类型控制器,部署在所有Node节点,且共享了宿主机网络名称空间
# 通过挂载宿主机的/proc和/sys目录采集宿主机的系统信息
kind: DaemonSet
apiVersion: extensions/v1beta1
metadata:
name: node-exporter
namespace: kube-system
labels:
daemon: "node-exporter"
grafanak8sapp: "true"
spec:
selector:
matchLabels:
daemon: "node-exporter"
grafanak8sapp: "true"
template:
metadata:
name: node-exporter
labels:
daemon: "node-exporter"
grafanak8sapp: "true"
spec:
volumes:
- name: proc
hostPath:
path: /proc
type: ""
- name: sys
hostPath:
path: /sys
type: ""
containers:
- name: node-exporter
image: harbor.od.com:180/public/node-exporter:v0.15.0
args:
- --path.procfs=/host_proc
- --path.sysfs=/host_sys
ports:
- name: node-exporter
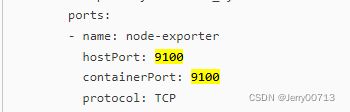
hostPort: 9100
containerPort: 9100
protocol: TCP
volumeMounts:
- name: sys
readOnly: true
mountPath: /host_sys
- name: proc
readOnly: true
mountPath: /host_proc
hostNetwork: true理解:我们只创建一个DaemonSet,因为我们每一个运算节点都要运行
volumes:
- name: proc 一个是挂在了宿主机的proc目录,为了取宿主机的状态,proc内存等等信息都在这里
hostPath:
path: /proc
type: ""
- name: sys 一个是挂在了宿主机的sys目录,为了取宿主机的状态,
hostPath:
path: /sys
type: ""
args:定义两个参数
- --path.procfs=/host_proc
- --path.sysfs=/host_sys
volumeMounts:
- name: sys 把sys挂在了/host_sys
readOnly: true
mountPath: /host_sys
- name: proc 把proc挂在了/host_proc
readOnly: true
mountPath: /host_prochostNetwork: true 使用了宿主机的网络名称空间(docker中有4中网络模型,分别是none、nat(默认)、宿主机共享网络名称空间、容器共享网络名称空间docker的4种网络模型_Jerry00713的博客-CSDN博客)。node-exporters本身容器里面监听9100端口,设置共享宿主机的网络名称空间后,容器启动的9100端口,其实就是宿主机启动的9100端口。(毕竟容器用的就是宿主机的IP,curl 容器的9100等同于curl 宿主机的9100)。所以在一个node节点执行netstat -tulpn |grep 9100 发现有没有监听,等启动node-exporter后查看
1.2.3、应用资源配置清单
在一个node节点执行
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/node-exporter/ds.yaml
daemonset.extensions/node-exporter created1.2.4、检测正否正常
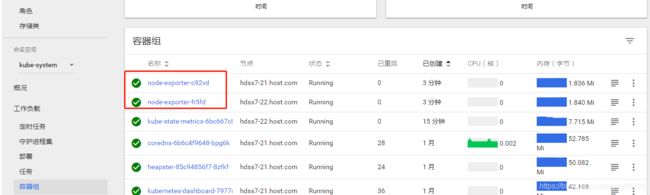
查看9100端口:
[root@hdss7-21 ~]# netstat -tulpn |grep 9100
tcp6 0 0 :::9100 :::* LISTEN 27069/node_exporter
[root@hdss7-21 ~]# kubectl get pods -o wide -n kube-system |grep node-exporter
node-exporter-c92vd 1/1 Running 0 10m 10.4.7.21 hdss7-21.host.com
node-exporter-fr5fd 1/1 Running 0 10m 10.4.7.22 hdss7-22.host.com
由于我们跟宿主机共享网络,所以docker没有IP了,IP就是宿主机
[root@hdss7-21 ~]# curl localhost:9100
Node Exporter
Node Exporter
真正取监控数据接口:http://10.4.7.21:9100/metrics,node-exporters把数据汇总到(http://10.4.7.21:9100/metrics),Prometheus在从这个接口取pull数据
1.3、部署cadvisor
cadvisor用来监控容器内部的使用资源的重要工具。容器本身到底耗费多少资源,应该怎么监控。他是通过容器外部来监控内部的资源(docker stats container_id(比如docker stats hb-weber 或者 docker stats 788) 可以查看运行的 Docker 镜像的运行状态),但这种方式无法通过 http 的方式来获取数据,而且没有界面,数据可视化还需要做大量的工作。由于 dokcer stats 有这些问题,所以 cadvisor 诞生了。 cadvisor 不仅可以搜集一台机器上所有运行的容器信息还提供基础查询界面和 http 接口,方便 Prometheus 进行数据抓取。部署cadvisor后,cadvisor通过跟kubectl要数据,kubectl跟docker引擎要数据,才能实现采集数据。所以容器本身消耗资源的监控是依赖于cadvisor,而不是kube-state-metrics
注:cadvisor在k8s1.9以前跟kubectl集成在一起,启动kubectl,cadvisor启动。从1.9以后分开。
注:(容器内部通过top、free -h查看发现总内存跟宿主机一致,但有可能可使用内存率,比宿主机还要低,这就不可靠了,毕竟整个docker是寄托在宿主机,怎么可能比宿主机低,具体是何原理,还未深入研究)
注:kube-state-metrics用来收集k8s状态信息,非监控容器资源
使用 cAdvisor 查看主机监控
访问 http://localhost:8080/containers/ 地址,在首页可以看到主机的资源使用情况,包含 CPU、内存、文件系统、网络等资源。使用 cAdvisor 查看容器监控
http://localhost:8080/docker/
总体来说,使用 cAdvisor 监控容器具有以下特点:
可以同时采集物理机和容器的状态;
可以展示监控历史数据。监控原理
我们知道 Docker 是基于 Namespace、Cgroups 和联合文件系统实现的。其中 Cgroups 不仅可以用于容器资源的限制,还可以提供容器的资源使用率。无论何种监控方案的实现,底层数据都来源于 Cgroups。
Cgroups 的工作目录为/sys/fs/cgroup,/sys/fs/cgroup目录下包含了 Cgroups 的所有内容。Cgroups包含很多子系统,可以用来对不同的资源进行限制。例如对CPU、内存、PID、磁盘 IO等资源进行限制和监控。
为了更详细的了解 Cgroups 的子系统,我们通过 ls -l 命令查看/sys/fs/cgroup文件夹,可以看到很多目录:
总结一下,容器的监控原理其实就是定时读取 Linux 主机上相关的文件并展示给用户。
1.3.1、准备镜像
[root@hdss7-200 ~]# docker pull google/cadvisor:v0.28.3
[root@hdss7-200 node-exporter]# docker images |grep cadvisor
google/cadvisor v0.28.3 75f88e3ec333 3 years ago 62.2MB
[root@hdss7-200 node-exporter]# docker image tag 75f88e3ec333 harbor.od.com:180/public/cadvisor:v0.28.3
[root@hdss7-200 node-exporter]# docker login harbor.od.com:180
[root@hdss7-200 node-exporter]# docker push harbor.od.com:180/public/cadvisor:v0.28.31.3.2、讲解容忍度(不在配置中)
在准备资源配置清单前,需要了解 tolerations参数
什么是tolerations: 英文本意叫容忍,实现人为影响k8s调度的方法。k8s能自动把容器调度到不同的节点,靠的是scheduler(主控检测组件,有预选策略和优选策略)。但是生产中,往往通过策略自动调度的节点,不是我预期的,那该怎么设置。两种方案,第一种如果你想指定调到到特定的一个节点,可以在pod控制器资源种声明需要调度到的节点名称。第二种,如果你所有的节点都可以调度,唯独某一个节点不被调度,给这个节点打一个污点,让所有的pod不能容忍这个污点,导致不能被调度,除非你在pod控制器资源种声明我可以容忍这个污点,就是可以忽略此污点,才能被调度此节点
解释如下配置:在node节点上打上污点,这个污点的名字是node-role.kubernetes.io/master,所影响的效果为NoSchedule不允许调度,所以此节点不会被任何资源调度。但当pod控制器资源,恰巧声明定义(key: node-role.kubernetes.io/master,effect: NoSchedule)说明,这个资源可以继续部署在这个污点名字是node-role.kubernetes.io/master,污点的影响的效果是NoSchedule的节点上。其中key要跟node污点节点的名字一致,effect:要跟node污点节点的影响的效果一致
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule人为影响k8s调度策略的五种方法:
· nodeName · ndoeSelector · nodeAffinity · podAffinity · Taints以及Tolerations:污点、容忍度方法实现现象:污点、容忍度方法可以人为的规定一个容器或者pod(k8s最小的单位),不能在那些节点上运行。 · 污点:如果想要实现污点、容忍度方法,需要现在运算节点node上进行打污点。 · 容忍度:pod谁是否能够容忍污点Kubernetes K8S节点选择(nodeName、nodeSelector、nodeAffinity、podAffinity、Taints以及Tolerations用法):https://blog.csdn.net/Jerry00713/article/details/124003264
实际操作例子:
1、注意:kubectl get node 中的roles不是污点,是label标签root@hdss7-21 ~]# kubectl get node NAME STATUS ROLES AGE VERSION hdss7-21.host.com Ready master,node 63d v1.15.2 hdss7-22.host.com Ready40d v1.15.2 2、给hdss7-21打污点
[root@hdss7-21 ~]# kubectl taint node hdss7-21.host.com node-role.kubernetes.io/master=master:NoSchedule node/hdss7-21.host.com tainted tainted意思是被污染了3、如何查看是否被污染
[root@hdss7-21 ~]# kubectl describe node hdss7-21.host.com |grep -i taints Taints: node-role.kubernetes.io/master=master:NoSchedule4、通过dashboard
5、编写脚本列出目前所有的node节点有哪些打了污点
[root@hdss7-21 ~]# vi nodes-taints.tmpl {{printf "%-50s %-12s\n" "Node" "Taint"}} {{- range .items}} {{- if $taint := (index .spec "taints") }} {{- .metadata.name }}{{ "\t" }} {{- range $taint }} {{- .key }}={{ .value }}:{{ .effect }}{{ "\t" }} {{- end }} {{- "\n" }} {{- end}} {{- end}} [root@hdss7-21 ~]# kubectl get nodes -o go-template-file="./nodes-taints.tmpl" Node Taint hdss7-21.host.com node-role.kubernetes.io/master=master:NoSchedule

1.3.3、准备资源配置清单
[root@hdss7-200 k8s-yaml]# mkdir -p /data/k8s-yaml/cadvisor;cd /data/k8s-yaml/cadvisor
[root@hdss7-200 cadvisor]# vi ds.yaml
# cadvisor采用daemonset方式运行在node节点上,通过污点的方式排除master
# 同时将部分宿主机目录挂载到本地,如docker的数据目录
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: cadvisor
namespace: kube-system
labels:
app: cadvisor
spec:
selector:
matchLabels:
name: cadvisor
template:
metadata:
labels:
name: cadvisor
spec:
hostNetwork: true
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: cadvisor
image: harbor.od.com:180/public/cadvisor:v0.28.3
imagePullPolicy: IfNotPresent
volumeMounts:
- name: rootfs
mountPath: /rootfs
readOnly: true
- name: var-run
mountPath: /var/run
- name: sys
mountPath: /sys
readOnly: true
- name: docker
mountPath: /var/lib/docker
readOnly: true
ports:
- name: http
containerPort: 4194
protocol: TCP
readinessProbe:
tcpSocket:
port: 4194
initialDelaySeconds: 5
periodSeconds: 10
args:
- --housekeeping_interval=10s
- --port=4194
terminationGracePeriodSeconds: 30
volumes:
- name: rootfs
hostPath:
path: /
- name: var-run
hostPath:
path: /var/run
- name: sys
hostPath:
path: /sys
- name: docker
hostPath:
path: /data/docker解释:
1、每一个节点都要监控自身容器到底耗费多少资源,所以必须使用DaemonSet,让每一个节点都都运行cadvisor
2、讲解为什么需要配tolerations
k8s从逻辑上,分为主控节点和逻辑节点(master,node),由于此文章部署k8s的时候,为了充分利用资源,所以把主控节点和逻辑节点放在一个架构种。比如,如果是通过kubeadm部署的k8s集群,集群规划是,默认找三台高性能的设备,安装apiserver、scheduler、controller-manager,当作是master的节点。而其他的节点部署kubectl、kube-proxy等组件,也就是node节点。这么做的好处是,随着业务的增加,节点扛不住了,必然增加物理设备,这时候就可以再找一些机器,安装kubectl,通过kubectl创建pod就行了。没别要把apiserver、scheduler、controller-manager都装一遍。而随着业务的变化,慢慢发现master的节点也安装kubectl,通过kubectl get node 可是实现查看master节点在集群中的状态,所以一般情况matser也会安装kubectl,但这回导致调度器会把资源调度到此master节点,所以会同时给加一个taint(污点)。而我们cadvisor要监控所有的资源,包括master节点,所以必须让pod控制器容忍此污点。

1.3.4、修改运算节点的软连接
在所有的运算节点修改软连接,因为版本原因,不修改软连接,会导致cadvisor取不到容器的资源
配置/sys/fs/cgroup/重新挂载
[root@hdss7-21 ~]# mount -o remount,rw /sys/fs/cgroup/
[root@hdss7-21 ~]# ll /sys/fs/cgroup/
drwxr-xr-x. 7 root root 0 2月 1 15:51 blkio
lrwxrwxrwx. 1 root root 11 2月 1 15:45 cpu -> cpu,cpuacct
lrwxrwxrwx. 1 root root 11 2月 1 15:45 cpuacct -> cpu,cpuacct
drwxr-xr-x. 7 root root 0 2月 1 15:51 cpu,cpuacct
容器会使用cpuacct,cpu,需要软连接出来
[root@hdss7-21 ~]# ln -s /sys/fs/cgroup/cpu,cpuacct/ /sys/fs/cgroup/cpuacct,cpu
[root@hdss7-21 ~]# ll /sys/fs/cgroup/
lrwxrwxrwx. 1 root root 11 2月 1 15:45 cpu -> cpu,cpuacct
lrwxrwxrwx. 1 root root 11 2月 1 15:45 cpuacct -> cpu,cpuacct
lrwxrwxrwx. 1 root root 27 2月 2 10:35 cpuacct,cpu -> /sys/fs/cgroup/cpu,cpuacct/
drwxr-xr-x. 7 root root 0 2月 1 15:51 cpu,cpuacct1.3.5、应用资源配置清单
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/cadvisor/ds.yaml
daemonset.extensions/cadvisor created1.4、blackbox-exporter
用来帮助探明业务容器是否存活
注:zabbix有一个重要监控场所,tomcat起来占用8080端口,要监控8080端口是否存活,如果8080意外的情况下宕了,要触发报警。 在这里面专门检测容器是否宕机的工具(由于blackbox-exporter的设计理念,发版更新代码不算宕机)
1.4.1、准备镜像
[root@hdss7-200 cadvisor]# docker pull prom/blackbox-exporter:v0.15.1
[root@hdss7-200 cadvisor]# docker images |grep blackbox-exporter
prom/blackbox-exporter v0.15.1 81b70b6158be 16 months ago 19.7MB
[root@hdss7-200 cadvisor]# docker image tag 81b70b6158be harbor.od.com:180/public/blackbox-exporter:v0.15.1
[root@hdss7-200 cadvisor]# docker login harbor.od.com:180
[root@hdss7-200 cadvisor]# docker image push harbor.od.com:180/public/blackbox-exporter:v0.15.1
1.4.2、准备资源配置清单
[root@hdss7-200 cadvisor]# mkdir -p /data/k8s-yaml/blackbox-exporter;cd /data/k8s-yaml/blackbox-exporter
[root@hdss7-200 blackbox-exporter]# vi cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
labels:
app: blackbox-exporter
name: blackbox-exporter
namespace: kube-system
data:
blackbox.yml: |-
modules:
http_2xx:
prober: http
timeout: 2s
http:
valid_http_versions: ["HTTP/1.1", "HTTP/2"]
valid_status_codes: [200,301,302]
method: GET
preferred_ip_protocol: "ip4"
tcp_connect:
prober: tcp
timeout: 2s[root@hdss7-200 blackbox-exporter]# vi dp.yaml
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: blackbox-exporter
namespace: kube-system
labels:
app: blackbox-exporter
annotations:
deployment.kubernetes.io/revision: 1
spec:
replicas: 1
selector:
matchLabels:
app: blackbox-exporter
template:
metadata:
labels:
app: blackbox-exporter
spec:
volumes:
- name: config
configMap:
name: blackbox-exporter
defaultMode: 420
containers:
- name: blackbox-exporter
image: harbor.od.com:180/public/blackbox-exporter:v0.15.1
imagePullPolicy: IfNotPresent
args:
- --config.file=/etc/blackbox_exporter/blackbox.yml
- --log.level=info
- --web.listen-address=:9115
ports:
- name: blackbox-port
containerPort: 9115
protocol: TCP
resources:
limits:
cpu: 200m
memory: 256Mi
requests:
cpu: 100m
memory: 50Mi
volumeMounts:
- name: config
mountPath: /etc/blackbox_exporter
readinessProbe:
tcpSocket:
port: 9115
initialDelaySeconds: 5
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 3[root@hdss7-200 blackbox-exporter]# vi svc.yaml
# 没有指定targetPort是因为Pod中暴露端口名称为 blackbox-port
kind: Service
apiVersion: v1
metadata:
name: blackbox-exporter
namespace: kube-system
spec:
selector:
app: blackbox-exporter
ports:
- name: blackbox-port
protocol: TCP
port: 9115正常定义ports格式如下,targetPort代表把容器的9115端口暴露出来,port代表访问cluster_ip: 9115,kube-proxy反代给容器的9115端口
ports:
- name: blackbox-port
protocol: TCP
port: 9115
targetPort:9115但其中targetPort 可以不写, 如果不写,访问cluster_ip: 9115,kube-proxy反代给容器那个端口呢?可以注意到,如果不写targetPort,就会出现name: blackbox-port。这是声明targetPort的另一种形式,使用name: blackbox-port形式,service资源就去找对应她连接的pod资源下,名字是blackbox-port声明的端口。所以cluster_ip: 9115反代pod资源声明的名字是blackbox-port下的端口。所以name后名字要跟容器定义的port端口名称一致
ports:
- name: blackbox-port
protocol: TCP
port: 9115
[root@hdss7-200 blackbox-exporter]# vi ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: blackbox-exporter
namespace: kube-system
spec:
rules:
- host: blackbox.od.com
http:
paths:
- path: /
backend:
serviceName: blackbox-exporter
servicePort: blackbox-port对比上述service资源,正常定义backend格式如下,
serviceName: blackbox-exporter
servicePort: 9115
之所以会写成blackbox-exporter,是因为ingress可以使用pod资源下,名字是blackbox-port声明的端口
配置blackbox.od.com域名解析:
[root@hdss7-11 ~]# vi /var/named/od.com.zone
$ORIGIN od.com.
$TTL 600 ; 10 minutes
@ IN SOA dns.od.com. dnsadmin.od.com. (
2020010516 ; serial
10800 ; refresh (3 hours)
900 ; retry (15 minutes)
604800 ; expire (1 week)
86400 ; minimum (1 day)
)
NS dns.od.com.
$TTL 60 ; 1 minute
dns A 10.4.7.11
harbor A 10.4.7.200
k8s-yaml A 10.4.7.200
traefik A 10.4.7.10
dashboard A 10.4.7.10
zk1 A 10.4.7.11
zk2 A 10.4.7.12
zk3 A 10.4.7.21
jenkins A 10.4.7.10
dubbo-monitor A 10.4.7.10
demo A 10.4.7.10
config A 10.4.7.10
mysql A 10.4.7.11
portal A 10.4.7.10
zk-test A 10.4.7.11
zk-prod A 10.4.7.12
config-test A 10.4.7.10
config-prod A 10.4.7.10
demo-test A 10.4.7.10
demo-prod A 10.4.7.10
blackbox A 10.4.7.10
[root@hdss7-11 ~]systemctl restart named
[root@hdss7-21 ~]# dig -t A blackbox.od.com @192.168.0.2 +short
10.4.7.10
1.4.3、应用资源配置清单
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/blackbox-exporter/cm.yaml
configmap/blackbox-exporter created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/blackbox-exporter/dp.yaml
deployment.extensions/blackbox-exporter created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/blackbox-exporter/svc.yaml
service/blackbox-exporter created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/blackbox-exporter/ingress.yaml
ingress.extensions/blackbox-exporter created
1.4.4、查看状态

2、交付Prometheus Server
2.1、准备镜像
[root@hdss7-200 ~]# docker pull prom/prometheus:v2.14.0
[root@hdss7-200 ~]# docker image tag prom/prometheus:v2.14.0 harbor.od.com:180/infra/prometheus:v2.14.0
[root@hdss7-200 ~]# docker login harbor.od.com:180
[root@hdss7-200 ~]# docker image push harbor.od.com:180/infra/prometheus:v2.14.02.2、准备资源配置清单
[root@hdss7-200 ~]# mkdir /data/k8s-yaml/prometheus;cd /data/k8s-yaml/prometheus
[root@hdss7-200 prometheus]# vi rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: prometheus
namespace: infra
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- nodes/metrics
- services
- endpoints
- pods
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: infra[root@hdss7-200 prometheus]# vi dp.yaml
# Prometheus在生产环境中,一般采用一个单独的大内存node部署,采用污点让其它pod不会调度上来
# --storage.tsdb.min-block-duration 内存中缓存最新多少分钟的TSDB数据,生产中会缓存更多的数据
# --storage.tsdb.retention TSDB数据保留的时间,生产中会保留更多的数据
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "5"
labels:
name: prometheus
name: prometheus
namespace: infra
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 7
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
nodeName: hdss7-21.host.com
containers:
- name: prometheus
image: harbor.od.com:180/infra/prometheus:v2.14.0
imagePullPolicy: IfNotPresent
command:
- /bin/prometheus
args:
- --config.file=/data/etc/prometheus.yml
- --storage.tsdb.path=/data/prom-db
- --web.enable-lifecycle
- --storage.tsdb.min-block-duration=5m
- --storage.tsdb.retention=24h
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: /data
name: data
resources:
requests:
cpu: "1000m"
memory: "1.5Gi"
limits:
cpu: "2000m"
memory: "3Gi"
imagePullSecrets:
- name: harbor
securityContext:
runAsUser: 0
serviceAccountName: prometheus
volumes:
- name: data
nfs:
server: hdss7-200
path: /data/nfs-volume/prometheus解释: spec: replicas: 1 启动份数1,因为普罗米修斯有持久化数据,下面有配置nfs,把data挂载出来 selector: 标签选择器 spec: nodeName: hdss7-22.host.com nodename参数,定义只能在hdss7-22上运行 --------------------------------------------- securityContext: command: 容器内执行什么命令,类似于sh -c 后接命令 - /bin/prometheus 容器启动后用sh -c /bin/prometheus启动普罗米修斯 args: 代表执行命令后接的参数 - --config.file=/data/etc/prometheus.yml 普罗米修斯配置文件 - --storage.tsdb.path=/data/prom-db 指定了tsdb的路径(时间数据库) - --web.enable-lifecycle 支持热更新,直接执行curl -X POST http://localhost:9090/-/reload,重启prometheus的配置立即生效 - --storage.tsdb.min-block-duration=10m 只加载普罗米修斯其中10min中内的数据(按照当 前配置,只加载普罗米修斯其中10min中内的数据, 普罗米修斯pod运行半个小时,轻轻松松普吃掉2G内 存,生产给建议2h) - --storage.tsdb.retention=72h 你的tsdb数据库到底存储多久的数据,跟硬盘有关,生产要比 72h多一些,毕竟磁盘倒是无所谓 所以上述意思是,容器启动后执行的是:sh -c /bin/prometheus --config.file=/data/etc/prometheus.yml --storage.tsdb.path=/data/prom-db --storage.tsdb.min-block-duration=10m -storage.tsdb.retention=72h --------------------------------------------- ports: - containerPort: 9090 暴露容器9090 protocol: TCP --------------------------------------------- volumeMounts: - mountPath: /data 读取名字是 data 的volumes的内容,把内容(/data/nfs- volume/prometheus) 目录挂载到容器的/data目录 name: data 调用名字是 data 的volumes的内容 --------------------------------------------- resources: 限制k8s容器资源配置方法 requests: 容器只要起来申请多大资源 cpu: "1000m" 1000m=1000毫核=1核,所以如果是半核就是500m memory: "1.5Gi" 内存1.5G limits: 当你的容器资源达到limits的限制,杀死容器,不能让你一个容器把宿主机资源耗尽 cpu: "2000m" memory: "3Gi" 注:如果你给到的内存太小就会触发limits后(比如 limits: cpu: "1000m" memory: "1Gi") ,容器 启动后过阵子会报错,status OOMKilled,代表内存不够,导致k8s的对应容器启动失败。思考:报错 oomkilled如何自动重启pod --------------------------------------------- serviceAccountName: prometheus --------------------------------------------- volumes: 定义挂载,定义那个目录要进行挂载,然后volumeMounts会获取volumes的内容 - name: data nfs: server: hdss7-200 path: /data/nfs-volume/prometheus 把宿主机的/data/nfs-volume/prometheus挂载到容器的/data
[root@hdss7-200 prometheus]# vi svc.yaml 暴露9090端口
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: infra
spec:
ports:
- port: 9090
protocol: TCP
targetPort: 9090
selector:
app: prometheus[root@hdss7-200 prometheus]# vi ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: traefik
name: prometheus
namespace: infra
spec:
rules:
- host: prometheus.od.com
http:
paths:
- path: /
backend:
serviceName: prometheus
servicePort: 9090配置nds解析
[root@hdss7-11 ~]# vi /var/named/od.com.zone
$ORIGIN od.com.
$TTL 600 ; 10 minutes
@ IN SOA dns.od.com. dnsadmin.od.com. (
2020010517 ; serial
10800 ; refresh (3 hours)
900 ; retry (15 minutes)
604800 ; expire (1 week)
86400 ; minimum (1 day)
)
NS dns.od.com.
$TTL 60 ; 1 minute
dns A 10.4.7.11
harbor A 10.4.7.200
k8s-yaml A 10.4.7.200
traefik A 10.4.7.10
dashboard A 10.4.7.10
zk1 A 10.4.7.11
zk2 A 10.4.7.12
zk3 A 10.4.7.21
jenkins A 10.4.7.10
dubbo-monitor A 10.4.7.10
demo A 10.4.7.10
config A 10.4.7.10
mysql A 10.4.7.11
portal A 10.4.7.10
zk-test A 10.4.7.11
zk-prod A 10.4.7.12
config-test A 10.4.7.10
config-prod A 10.4.7.10
demo-test A 10.4.7.10
demo-prod A 10.4.7.10
blackbox A 10.4.7.10
prometheus A 10.4.7.10
[root@hdss7-11 ~]# systemctl restart named
[root@hdss7-11 ~]# dig -t A prometheus.od.com @10.4.7.11 +short
10.4.7.10
2.3、准备Prometheus配置
拷贝证书
[root@hdss7-200 ~]# mkdir -p /data/nfs-volume/prometheus/{etc,prom-db} 创建etc配置、时间序列数据库
[root@hdss7-200 prometheus]# cd /data/nfs-volume/prometheus/etc/ 拷贝证书,因为要跟apiserver通讯。Prometheus为什么自动发现k8s的元数据,是因为跟apiserver通讯
[root@hdss7-200 etc]# cp /opt/certs/ca.pem .
[root@hdss7-200 etc]# cp -a /opt/certs/client.pem .
[root@hdss7-200 etc]# cp -a /opt/certs/client-key.pem .
[root@hdss7-200 etc]# ll
-rw-r--r--. 1 root root 1346 2月 5 16:12 ca.pem
-rw-------. 1 root root 1679 11月 30 12:22 client-key.pem
-rw-r--r--. 1 root root 1363 11月 30 12:22 client.pem
准备Prometheus的配置文件yml
[root@hdss7-200 etc]# vim /data/nfs-volume/prometheus/etc/prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'etcd'
tls_config:
ca_file: /data/etc/ca.pem
cert_file: /data/etc/client.pem
key_file: /data/etc/client-key.pem
scheme: https
static_configs:
- targets:
- '10.4.7.12:2379'
- '10.4.7.21:2379'
- '10.4.7.22:2379'
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'kubernetes-kubelet'
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __address__
replacement: ${1}:10255
- job_name: 'kubernetes-cadvisor'
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __address__
replacement: ${1}:4194
- job_name: 'kubernetes-kube-state'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- source_labels: [__meta_kubernetes_pod_label_grafanak8sapp]
regex: .*true.*
action: keep
- source_labels: ['__meta_kubernetes_pod_label_daemon', '__meta_kubernetes_pod_node_name']
regex: 'node-exporter;(.*)'
action: replace
target_label: nodename
- job_name: 'blackbox_http_pod_probe'
metrics_path: /probe
kubernetes_sd_configs:
- role: pod
params:
module: [http_2xx]
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_blackbox_scheme]
action: keep
regex: http
- source_labels: [__address__, __meta_kubernetes_pod_annotation_blackbox_port, __meta_kubernetes_pod_annotation_blackbox_path]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+);(.+)
replacement: $1:$2$3
target_label: __param_target
- action: replace
target_label: __address__
replacement: blackbox-exporter.kube-system:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'blackbox_tcp_pod_probe'
metrics_path: /probe
kubernetes_sd_configs:
- role: pod
params:
module: [tcp_connect]
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_blackbox_scheme]
action: keep
regex: tcp
- source_labels: [__address__, __meta_kubernetes_pod_annotation_blackbox_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __param_target
- action: replace
target_label: __address__
replacement: blackbox-exporter.kube-system:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'traefik'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme]
action: keep
regex: traefik
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
2.4、应用资源配置清单
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/prometheus/rbac.yaml
serviceaccount/prometheus created
clusterrole.rbac.authorization.k8s.io/prometheus created
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/prometheus/dp.yaml
deployment.extensions/prometheus created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/prometheus/svc.yaml
service/prometheus created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/prometheus/ingress.yaml
ingress.extensions/prometheus created
2.5、查看状态
访问http://prometheus.od.com/后跳转http://prometheus.od.com/graph
Alters 报警 graph 图表
注:如果容器启动失败报错,检查是否能ping hdss7-200,有可能/etc/resove.conf中没有search host.com
MountVolume.SetUp failed for volume "data" : mount failed: exit status 32 Mounting command: systemd-run Mounting arguments: --description=Kubernetes transient mount for /data/kubelet/pods/04e93582-f4f2-4a87-abac-ddcb151ec89f/volumes/kubernetes.io~nfs/data --scope -- mount -t nfs hdss7-200:/data/nfs-volume/prometheus /data/kubelet/pods/04e93582-f4f2-4a87-abac-ddcb151ec89f/volumes/kubernetes.io~nfs/data Output: Running scope as unit run-48291.scope. mount.nfs: Failed to resolve server hdss7-200: Name or service not known mount.nfs: Operation already in progress
3、 讲解配置文件
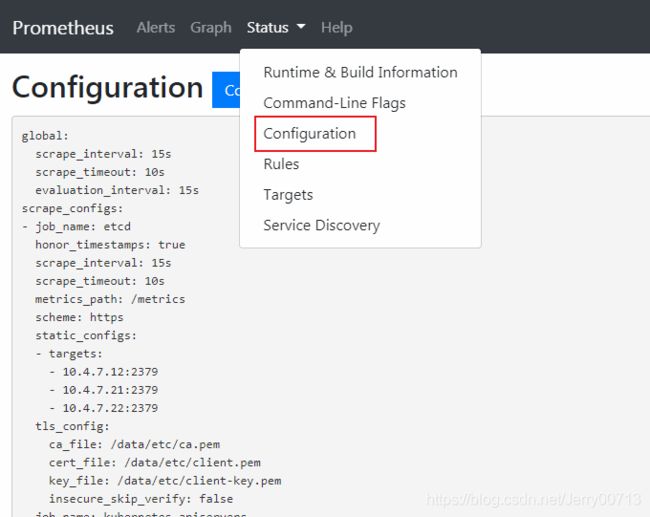
正常情况下,会看到如下这些,如果你只看到etcd,其他的都没有看到,而且还报错cannot list resource \"services\" in API group \"\" at the cluster scope",点击这个解决K8s 异常问题处理_Jerry00713的博客-CSDN博客
这些targets是怎么出来的,是通过读取之前配置的(/data/nfs-volume/prometheus/etc/prometheus.yml)的内容,从apiserver中获取的

点击Configuration,里面显示的内容就是(/data/nfs-volume/prometheus/etc/prometheus.yml)配置的内容。配置文件里面有多少个job.name(项目),就有多少个targets(模块)
讲解job_name: etcd中的配置
- job_name: etcd honor_timestamps: true scrape_interval: 15s 代表间隔多长时间取一次数据 scrape_timeout: 10s 如果10s内取不到数据,代表超时,将不获取数据,并提示失败 metrics_path: /metrics 这里代表取etcd中的哪个路径取数据,比如etc是10.4.7.12:2379,取10.4.7.12:2379/metrics数据 scheme: https 从什么协议拉取数据,因为普罗米修斯默认只能基于HTTP或者HTTPS拉取的方式跟(代理端exporter)通讯,exporter也只能提供http/https接口 static_configs: 静态配置,在这些job_name只有etcd是静态(etcd是写死),其他都是自动发现 - targets: 获取信息的列表 - 10.4.7.12:2379 从10.4.7.12的2379端口+metrics_pat,1379为etcd的端口,代表从10.4.7.12:2379/metrics 获取监控信息,其实metrics是从一开始规划时候,通过yaml等配置文件已经写死后续拉取信息从/metrics下。而exporter拉取此信息后给普罗米修斯 - 10.4.7.21:2379 - 10.4.7.22:2379 tls_config: 从etcd中取/存数据,使用ca认证 ca_file: /data/etc/ca.pem cert_file: /data/etc/client.pem key_file: /data/etc/client-key.pem insecure_skip_verify: falseEndpoint (接入点): 从那些接入点取数据,比如从https://10.4.12:2379/metrics中获取(使用_address_ 加上_metrics_path_参数拼接成https://10.4.12:2379/metrics)
lables : 通过lables中的参数过滤https://10.4.12:2379/metrics中内容,获取我需要的数据(什么样的维度标签去过滤相关的监控指标)

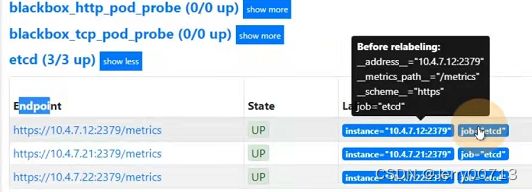
静态配置/服务发现
etcd是静态配置(etcd就三个,地址也是写死),所以除了etcd是静态的,其余的targets都是prometueus通过prometheus.yml中的参数去apiserver匹配,实现自动发现k8s元数据,并在这个页面中显示。Service Discovery 为服务自动发现详细情况
讲解job_name:kubernetes-kube-state中的配置
kubernetes-kube-state对应是部署node-exporters、部署kube-state-metrics的合集,用来收集k8s运算节点上基础设施信息、收集k8s状态信息
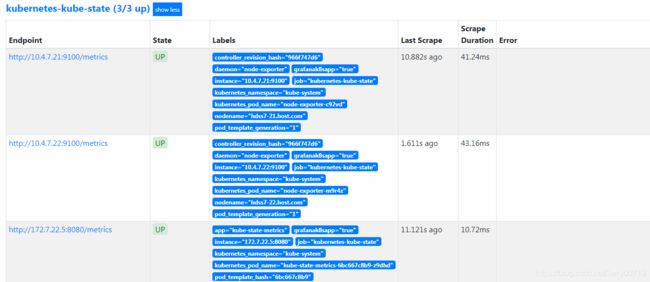
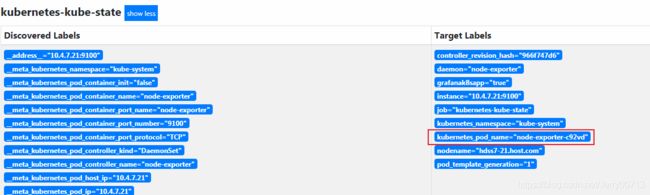
- job_name: kubernetes-kube-state 定义job_name: kubernetes-kube-state honor_timestamps: true scrape_interval: 15s 采集的时间 scrape_timeout: 10s 超时时间 metrics_path: /metrics 到底请求哪个url,地址 scheme: http kubernetes_sd_configs: kubernetes_service Discoveryd 自动发现k8s服务的配置,思考普罗米修斯 怎么获取k8s里面的元数据,通过(kubernetes_sd)自动发现。主要在于普罗米 修斯天生就跟k8s在一起,都是Goolge,所以只要声明kubernetes_sd后, Retrieval数据中心自动识别发现k8s的元数据. - role: pod 定义kubernetes_sd后,定义- role: pod,代表能够发现k8s中所有的pod relabel_configs: 我不能让所有的pod都进到我job这里来,通过一系列的标签选择规则,过滤我想要的 pod,在进入我的kubernetes-kube-state的jobEndpoint中的http://10.4.7.21:9100/metrices等,一样也是通过_address_ 加上_metrics_path_拼接而成的,只不过这些参数是Service Discovery 服务自动发现的,而不是像etcd在prometheus.yml中自定义的
通过上图可以查看,job_name:kubernetes-kube-state一共定义了三个Endpoint,说明自动发现通过跟apivserver,自动发现匹配上了三个容器,这三个pod有两个是 9100/metrices,一个是 8080/metrices。从一开始交付Exporters我们就知道,9100是部署node-exporters才会产生的端口,而 8080/metrices是部署kube-state-metrics产生的端口。其中node_exporter的DaemonSet资源中,声明了hostport:9100,说明了容器共享了宿主机的网络名称空间,所以查看9100端口是谁占用的。
[root@7-21 ~]# netstat -tulpn |grep 9100 tcp6 0 0 :::9100 :::* LISTEN 4235/node_exporter
relabel_configs配置讲解:
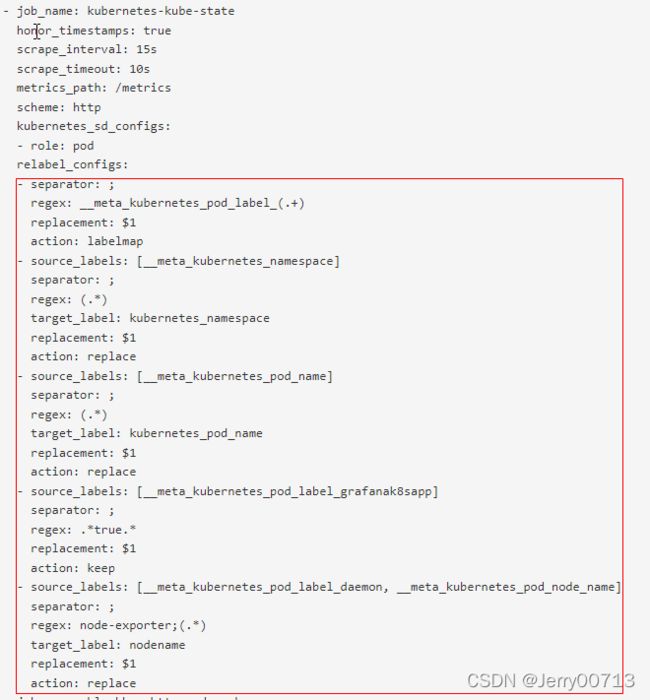
详细说明 prometheus.yml中的job_name:kubernetes-kube-state项目中的relabel_configs下的参数,如何过滤出node_exporter、kube-state-metrics
relabel_configs: 我不能让所有的pod都进到我job这里来,过滤 - separator: ; regex: __meta_kubernetes_pod_label_(.+) replacement: $1 action: labelmap - source_labels: [__meta_kubernetes_namespace] separator: ; regex: (.*) target_label: kubernetes_namespace replacement: $1 action: replace - source_labels: [__meta_kubernetes_pod_name] separator: ; regex: (.*) target_label: kubernetes_pod_name replacement: $1 action: replace - source_labels: [__meta_kubernetes_pod_label_grafanak8sapp] separator: ; regex: .*true.* replacement: $1 action: keep - source_labels: [__meta_kubernetes_pod_label_daemon, __meta_kubernetes_pod_node_name] separator: ; regex: node-exporter;(.*) target_label: nodename replacement: $1 action: replace如果遇到relabel_configs,最重要的是第一查看action,其中action: keep跟action: drop是重中之重先看。
action: 重新标签动作 replace: 默认,通过regex(正则表达式)匹配source_label的值,使用replacement来引用表达式匹配的分组 keep: 删除regex(正则表达式)与连接不匹配的目标source_label,意思是通过自动发现搜索我定义的source_label中内容,不符合我就抛弃 drop:删除regex(正则表达式)与连接匹配的目标source_label,意思是通过自动发现搜索我定义的source_label中内容,符合我就抛弃 hasdmod: 设置target_lable为modules连接的哈希值source_label labelmap: 匹配regex所有的标签名称,然后复制匹配标的签值进行分组,replacement分组引用($1,$2)代替prometheus.yml中看到了action: keep、并未看到action: drop,所以看action: keep
(- source_labels:[__meta_kubernetes_pod_label_grafanak8sapp] ) source_labels后定义的是标签,在k8s中所有的pod中自动发现,跟我 source_labels中内容相同标签的pod,怎么办呢?我就把他保留,没有这个标签的pod不保留。regex: .*true.* 如果正则表达式是true,才会执行keep动作。所以如下,自动发现取什么样子元数据?当你的k8s里面的pod有一个标签,这个标签的名字是grafanak8sapp,才会保留。- source_labels: [__meta_kubernetes_pod_label_grafanak8sapp] separator: ; regex: .*true.* replacement: $1 action: keep查看kube-state-metrics、node_exporter是否有labels:grafanak8sapp
[root@hdss7-22 ~]# kubectl get pods -o wide -n kube-system |grep kube-state-metrics kube-state-metrics-6bc667c8b9-z9dhd 1/1 Running 1 5d18h 172.7.22.5 hdss7-22.host.com[root@hdss7-22 ~]# kubectl get pod kube-state-metrics-6bc667c8b9-z9dhd -o yaml -n kube-system |grep -A 5 labels labels: app: kube-state-metrics grafanak8sapp: "true" pod-template-hash: 6bc667c8b9 name: kube-state-metrics-6bc667c8b9-z9dhd namespace: kube-system node_exporter也是有(labels:grafanak8sapp: "true"),就不演示了 总结:通过演示只有kube-state-metrics(2份容器)、node_exporter(1份容器)才会有(labels:grafanak8sapp: "true"),所以只匹配了他们。查看部署kube-state-metrics、node_exporter资源配置清单,从一开始就配置了labels:grafanak8sapp: "true",如下
[root@7-200 prometheus]# cat /data/k8s-yaml/node-exporter/ds.yaml kind: DaemonSet apiVersion: extensions/v1beta1 metadata: # 定义DaemonSet元数据 name: node-exporter namespace: kube-system ------------------------------------------- labels: # 这是DaemonSet类型的pod控制器的lables daemon: "node-exporter" grafanak8sapp: "true" ------------------------------------------- pod.spec.selector下的内容一般都是声明pod资源跟那个控制器所约束。看似都在一个ds.yaml中,但声明在集群中,DaemonSet资源、pod资源都是隔离的,都是需要进行绑定的,才能决定pod是被那种控制器所约束,DaemonSet资源去绑定,符合daemon: "node-exporter"跟grafanak8sapp: "true"标签的pod。 pod.spec.metadata下的内容一般都是声明pod的详细信息(调取那个镜像,挂载等),他需要连接 DaemonSet、deployment等资源,如果连接,通过此处找同命名空间下的符合我想找的lables。 ------------------------------------------- spec: selector: # 声明这是个标签选择器 matchLabels: # 用来进行匹配标签,pod资源跟那个DaemonSet资源进行匹配绑定 daemon: "node-exporter" grafanak8sapp: "true" ------------------------------------------- template: # 下面的内容为pod如何启动,按照这个模板,他也声明了一个 labels,给自己一个身份,毕竟在k8s中要有名字来继承他 metadata: name: node-exporter labels: # 定义pod容器的标签,这个才是通过自动发现,k8s获取pod的labels(元数据的 标签),然后Prometheus通过拿到k8s元数据的标签做匹配找到符合要求的元数据 daemon: "node-exporter" grafanak8sapp: "true" spec: volumes: - name: proc hostPath: path: /proc type: "" - name: sys hostPath: path: /sys总结下来(- source_labels:[__meta_kubernetes_pod_label_grafanak8sapp] ) :拿到了k8s的所有的pod的Labels的元数据,去匹配grafanak8sapp,如果正则的值是true,动作是keep,否则是drop
注: relabel_configs的配置规则,action:keep、action:drop不会同时存在,什么意思,通过(prometheus.yml下的job_name:kubernetes-kube-state下的 - role: pod 参数) 代表能够发现k8s中所有的pod,随后匹配到规则的会被(keep)成功保留,其余的默认被舍弃,而这个也就是drop的功能。下图Service Discovery → kubernetes-kube-state中查看到出现droped,但并没有定义action:drop,由于执行了action:keep,被舍弃labels的好似执行了action:drop

使用Prometheus 查询
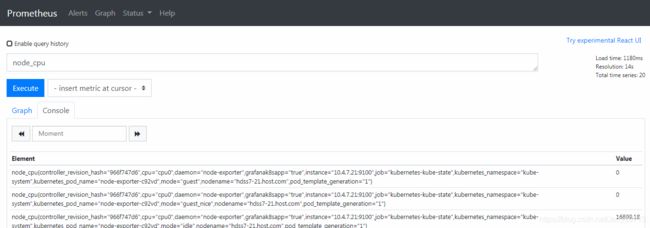
1、输入node_cpu (标签) ,点击Execute (查询)
1、node_cpu是一个函数。 2、通过输入“node_cpu”,进行查询后,显示node_cpu函数的所有信息。 3、{}里面是这个函数的详细信息,里面匹配的各种标签的元数据。 4、也就是说,你用一堆标签合成一个函数(数据维度),通过这个函数形成监控指标 5、后面的value代表的是查询到的数值node_cpu{controller_revision_hash="966f747d6",cpu="cpu0",daemon="node- exporter",grafanak8sapp="true",instance="10.4.7.21:9100",job="kubernetes-kube- state",kubernetes_namespace="kube-system",kubernetes_pod_name="node-exporter- 4824p",mode="guest",nodename="hdss7-21.host.com",pod_template_generation="1"} 搜索监控node_cpu函数后,输出都为监控指标。job="kubernetes-kube-state" 代表说明这个函数,是通过哪 一个target取出来的数值。kubernetes_pod_name="node-exporter-4824p" 代表具体从name是node- exporter的pod 取数据,也就是说我这里有一个node_cpu这么一个监控函数,你的node-exporter就可以返回 数值了。返回的数值是Value时间序列, 每隔15s取一次,0 代表未取到。2、假如要搜索hdss7-21.host.com的node_cpu,应该如何写 node_cpu{nodename="hdss7-21.host.com"}
点击Graph (图形界面),会对指标为node_cpu进行汇总绘画,然后显示,点击数据会发现里面有若干数据维度,然后通过时间序列,进行描点画图,从图形界面显示node_cpu监控指标是node-exporter提供的。
总结:从拉取到的所有的数据中(拉取的都是函数),存到普罗米修斯,通过Execute过滤这些函数。
3、如何知道都有那些函数
在target中kubernetes-kube-state (3/3 up) 中随便找一个Endpoint ,如http://10.4.7.21:9100/metrics ,访问它弹出的是监控数据源,而这个页面是node-exporter帮助收集k8s资源的元数据。也就是你输入函数。Prometheus通过配置文件中( - job_name: kubernetes-kube-state 下的 scrape_interval: 15s )定义了15s的间隔,curl一下http://10.4.7.21:9100/metrics收集最新数据
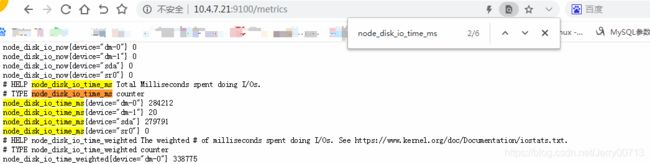
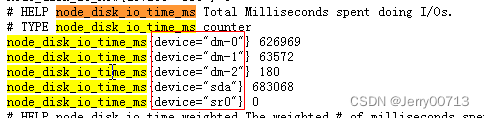
搜索node_disk_io_time_ms,他是从kubernetes_pod_name="node-exporter-c92vd"获取的
思考:通过输入函数node_disk_io_time_ms,执行Execute后搜索的一条数据数据很长
但是在http://10.4.7.21:9100/metrics中搜索node_disk_io_time_ms 只有{device="dm-0"} 、{device="dm-1"} 等等,
其他(daemon="node-exporter",grafanak8sapp="true",job="kubernetes-kube-state",kubernetes_pod_name="node-exporter-4824p",nodename="hdss7)等等的数据呢。
这个其他数据就是relabel_configs下决定的,他协助帮你拼接



relabel_configs配置中(replace)讲解:
图中的 kubernetes_pod_name="node-exporter-c92wd" 怎么来的,为什么能把容器名字等于kubernetes_pod_name,最后变成kubernetes_pod_name= "pod_name"
- job_name: kubernetes-kube-state ...... relabel_configs: ..... - source_labels: [__meta_kubernetes_pod_name] separator: ; regex: (.*) target_label: kubernetes_pod_name replacement: $1 action: replace ..... 我们通过定义relabel_configs的action为replace,告诉Prometheus,需要为当前实例采集的所有 metrics写入新的label。当需要过滤Target目标时,我们则将action定义为keep或者drop。 action:replace重新标签动作: 这里我们使用__meta_kubernetes_pod_name信息来标记当前Target所在的data center。并且通过regex来匹配source_label的值,使用replacement来选择regex表达式匹配到的mach group。通过action来告诉 Prometheus在采集数据之前,需要将replacement的内容写入到target_label: kubernetes_pod_name当中 replace通过定义source_label获取他们的某一种标签,比如__meta_kubernetes_namespace、比如__meta_kubernetes_pod_name获取的就是这些pod的pod_name。在通过replace下定义regex(正则表式) 进行匹配,比如regex: (.*)代表所有pod的名字,使用replacement参数给这些pod的(source_label内 容)做重新标签作。比如replacement:$1, $1为regex中正则匹配到的部分,就是所有的pod_name。最后就 是将所有的pod_name打一个标签,kubernetes_pod_name="pod的名字"。其中并不影响k8s中原pod的真实名 字。这样在Prometheus中统一。kubernetes_pod_name(监控指标名字)就能通过函数搜索符合匹配到的一 堆pod。详细解释+案例:
重写label,可以根据规则进行动态的修改label的各个属性。 target_label:修改的目的label source_labels:源label regex:正则表达式 replacement:替换结果 action:动作为replace,默认为replace separator:多个source_labels之间的分隔符修改端口
relabel_configs: - source_labels: [ __address__ ] target_label: __address__ regex: (.*):10250 replacement: $1:9101 action: replace __address__:为target的host:port的部分修改地址以及添加标签
relabel_configs: - source_labels: [__address__] target_label: __address__ regex: (.*) replacement: 127.0.0.1:9090 action: replace - source_labels: [__address__, __metrics_path__] target_label: test separator: '-' regex: (.*) replacement: $1 action: replace $1为regex中正则匹配到的部分对于直接保留标签的值时,也可以简化为:
- source_labels: [__meta_kubernetes_pod_name] target_label: kubernetes_pod_name
4、Prometheus的使用
4.1、监控自定义的组件--Traefik接入
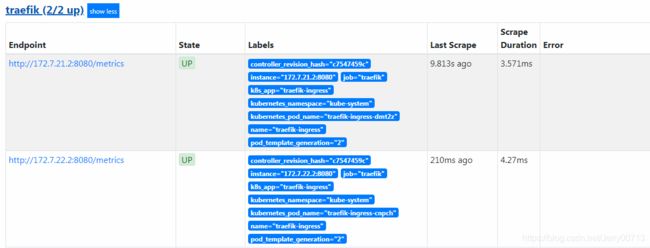
目前 traefik(0/0 up) traefik还是一个没有匹配上

需要注意的是,如果是自定义的业务,需要安装对应的exporters,Prometheus能获取数据的前提是,有个接口能让我获取到数据,在部署traefik的时候,我们已经特意暴露了8080/metrics接口,为了后续让Prometheus能获取数据,所以目前只要查看一下traefik配置,告诉Prometheus怎么拉
[root@hdss7-200 ~]# cat /data/k8s-yaml/traefik;cd /data/k8s-yaml/traefik/daemonset.yaml
............
- name: admin-web
containerPort: 8080
............
args:
- --metrics.prometheus- job_name: traefik
honor_timestamps: true
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme]
separator: ;
regex: traefik
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
separator: ;
regex: (.+)
target_label: __metrics_path__
replacement: $1
action: replace
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
separator: ;
regex: ([^:]+)(?::\d+)?;(\d+)
target_label: __address__
replacement: $1:$2
action: replace
- separator: ;
regex: __meta_kubernetes_pod_label_(.+)
replacement: $1
action: labelmap
- source_labels: [__meta_kubernetes_namespace]
separator: ;
regex: (.*)
target_label: kubernetes_namespace
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_pod_name]
separator: ;
regex: (.*)
target_label: kubernetes_pod_name
replacement: $1
action: replace
遇到relabel_configs,先看最重要的keep或者drop
- job_name: traefik
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme]
separator: ;
regex: traefik
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme]
pod_annotation 代表这里面是匹配了一个traefik注解,所以在traefik的pod资源上加一个annotations
注解,重启pod后,就会监控
修改traefik的pod控制器加上一个annotations注解,重启pod
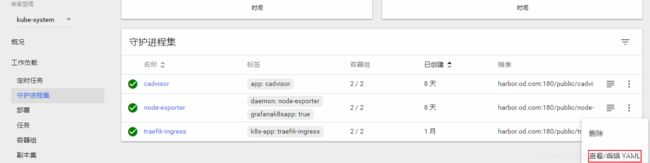
# 放在配置文件中,是定义pod资源的,跟lables同级别,加入注释,然后重启Pod。需要在pod资源声明(prometheus_io_path prometheus_io_port),Prometheus从哪获取数据。
"annotations": {
"prometheus_io_scheme": "traefik",
"prometheus_io_path": "/metrics",
"prometheus_io_port": "8080"
}为什么kubernetes-kube-state、node-exporters这种在pod资源种没有声明,他们就是专门作为收集信息exporters,所以pod启动的时候,默认会启动8080、9100,获取地址默认是http://pod_ip:端口/metrics。这些情况Prometheus知道,Prometheus就会按照默认地址去获取数据。如果exporters把端口或者接口地址修改,那对应的要在pod种也声明(prometheus_io_path prometheus_io_port)。在dashboard页面修改,可以不用对齐。
点击更新后,删除两个节点的traefik的pod,重启pod

如果容器发生了Terminating后,可以进行强制删除 (kubectl delete pods 容器名字 -n kube-system --force --grace-period=0)后,在看
启动后查看Prometheus下的Targets,Targets下的Treafik

4.2、监控服务是否存活--接入Blackbox
监控我们服务是否存活,我们先确定这个服务是什么类型的服务,是TCP还是http,按照协议类型Blackbox会不定时的检测端口,判断是不是存活。
# 在对应pod资源的注释中添加,以下分别是TCP探测和HTTP探测,Prometheus中没有定义其它协议的探测。
TCP:
"annotations": {
"blackbox_port": "3306",
"blackbox_scheme": "tcp"
}
如果你想监控这个服务是不是存活,首先需要知道服务启动后什么样子是正常的,比如mysql,3306端口起来
了说明正常,所以3306这种TCP协议的类型的,只要telnet 3306通代表正常。所以添加TCP的
annotations,意思是Prometheus按照固定间断时间telnet 3306,通这个服务正常
HTTP:
"annotations": {
"blackbox_port": "8080",
"blackbox_scheme": "http",
"blackbox_path": "/hello?name=health"
}
如果要监控服务是不是存活,网站能不能正常访问为依据,那就需要使用添加HTTP的annotations形式,
Prometheus按照固定间断时间(curl -I 网址),返回200~300之间,说明正常。如果404或者502页面无法访
问,代表失败。如上,只要这个服务curl -I IP:8080/hello?name=health 返回在200~300之间,说明正常.4.2.1 监控TCP业务
这里我们监控dubbo-demo-service为例子,dubbo-demo-service为生产者,默认启动TCP协议的20880端口,让消费者连接即可。首先先修改dp.yaml让dubbo-demo-service正常启动容器。(注:因为之前配置了dubbo-demo-service连接Apollo,如果dubbo-demo-service的image还是使用Apollo版本的,就需要启动Apollo,要不容器启动不起来,会报错login out failed。为了节省资源,建议使用非Apollo版本得image,然后不起启动Apollo)



继续修改dubbo-demo-service的yaml,把annotations加进去,还是依旧放在pod.spec.template.metadata下跟labels同级别下,然后删除容器,重启pod
"annotations": {
"blackbox_port": "20880",
"blackbox_scheme": "tcp"
}

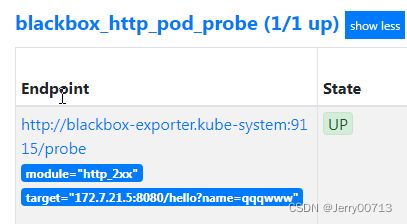
查看Targets查看状态
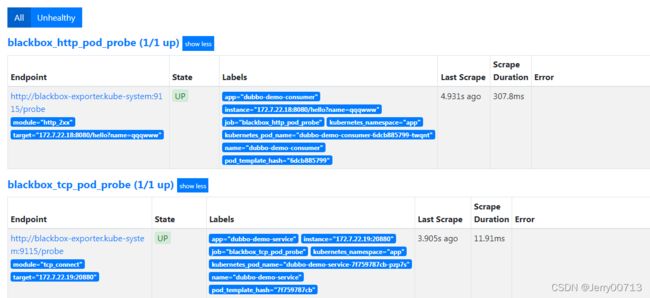
blackbox_http_pod_probe http监控结果项目
blackbox_tcp_pod_probe TCP监控结果项目
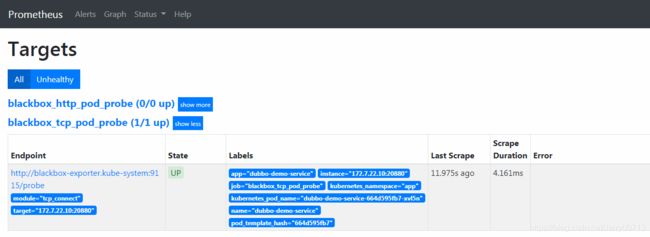
访问http://blackbox.od.com/,数据都在blackbox.od.com
检测机制:blackbox作为中间人,它去间断的访问172.7.22.10:20880,进而判断服务是不是正常,然后prometheus再去跟blackbox要信息
查看上图Logs日志
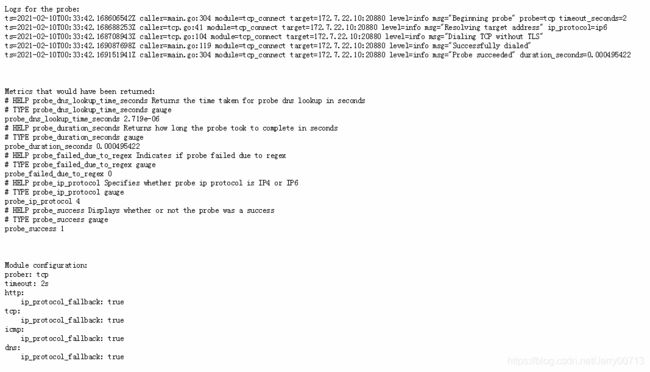
probe_duration_seconds 检测耗时多久
probe_failed_due_to_regex 正则表达式
probe_ip_protocol 4 IPv4
probe_success 1 1是success 0是Failure所以Prometheus检测业务容器是否存活,不能直接检测容器,Prometheus问blackbox,blackbox帮助检测
在Targets页面blackbox模块中,Endpoint地址是http://blackbox-exporter.kube-system:9115/probe,说明Prometheus是请求此地址拿数据的。
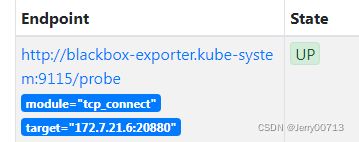
可以直接访问http://blackbox-exporter.kube-system:9115/probe是获取不到页面的,为什么?因为你没有给访问地址传参(module="tcp_connect 和 "target="172.7.22.10:20880" 是两个get 参数),如何传参也是在Prometheus.yml配置的。而且(http://blackbox-exporter.kube-system)一看这种形式,就知道他是使用了短域名service资源的name,全名是(blackbox-exporter.kube-system.svc.cluster.local.),这种service资源只有内部k8s集群内部才能被访问,宿主机curl不到。
# 查看blackbox-exporter的service资源,对应的clusterIP 192.168.243.210 ,port 9115
[root@hdss7-21 ~]# kubectl get svc -o wide -n kube-system |grep blackbox-exporter
blackbox-exporter ClusterIP 192.168.243.210 9115/TCP 7d20h app=blackbox-exporter
# 随便进入一个集群中的容器,然后curl blackbox-exporter.kube-system:9115,带着module=tcp_connect&target=172.7.22.10:20880参数。
# get请求带参数格式:IP:port/页面?参数1&参数2 ,通过?连接域名和参数 ,&不同参数的间隔符
[root@hdss7-21 ~]# kubectl exec -it nginx-ds-q5tmt /bin/bash
root@nginx-ds-q5tmt:/# curl 'http://blackbox-exporter.kube-system:9115/probe?module=tcp_connect&target=172.7.22.10:20880'
# HELP probe_dns_lookup_time_seconds Returns the time taken for probe dns lookup in seconds
# TYPE probe_dns_lookup_time_seconds gauge
probe_dns_lookup_time_seconds 0.357904555
# HELP probe_duration_seconds Returns how long the probe took to complete in seconds
# TYPE probe_duration_seconds gauge
probe_duration_seconds 0.35803019
# HELP probe_failed_due_to_regex Indicates if probe failed due to regex
# TYPE probe_failed_due_to_regex gauge
probe_failed_due_to_regex 0
# HELP probe_ip_protocol Specifies whether probe ip protocol is IP4 or IP6
# TYPE probe_ip_protocol gauge
probe_ip_protocol 0
# HELP probe_success Displays whether or not the probe was a success
# TYPE probe_success gauge
probe_success 0
root@nginx-ds-q5tmt:/#
总结:
有一个业务容器,通过添加注解后,被blackbox-exporter业务容器发现,每隔一段时间blackbox-exporter监听业务容器的服务是不是正常(通过检测容器内部的端口或者网页的返回值判断),所以由blackbox-exporter检测业务容器是不是一直存活,而不是Prometheus。
而这个业务容器通过添注解后,由Prometheus.yml中配置了自动发现(- job_name: 'blackbox_http_pod_probe、- job_name: 'blackbox_tcp_pod_probe')内容,Prometheus通过apiserver获得带有blackbox_por注解的pod信息,从pod中获取pod_IP:port 和生成module=tcp_connect,把这些信息放入到blackbox-exporter的Endpoint下的参数。然后继续由Prometheus.yml中配置了自动发现(- job_name: 'blackbox_http_pod_probe、- job_name: 'blackbox_tcp_pod_probe')内容,去找blackbox并获得service资源的域名http://blackbox-exporter.kube-system:9115/probe,带着get参数,去获取刚才的那个业务容器的监控指标
4.2.2 监控HTTP业务
这里我们监控dubbo-demo-consumer为例子,dubbo-demo-consumer是消费者,需要提供HTTP页面。首先先修改dp.yaml让dubbo-demo-consumer正常启动容器。(注:因为之前配置了dubbo-demo-consumer连接Apollo,如果dubbo-demo-consumer的image还是使用Apollo版本的,就需要启动Apollo,要不容器启动不起来,会报错login out failed。为了节省资源,建议使用非Apollo版本得image,然后不起启动Apollo)

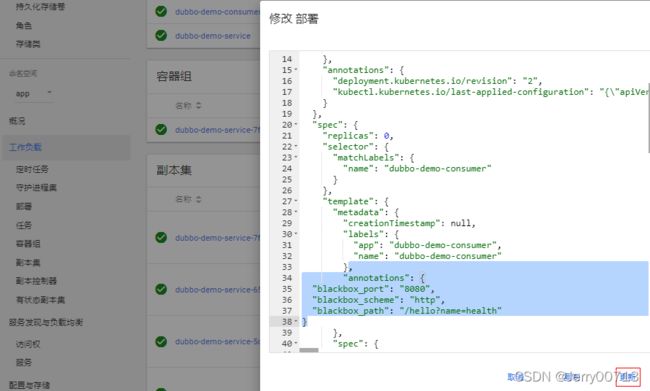
继续修改dubbo-demo-consumer的yaml,把annotations加进去,还是依旧放在pod.spec.template.metadata下跟labels同级别下,然后删除容器,重启pod。为什么是/hello?name=health,只要保证curl -I 网页是200~400之间的就可以,在上一篇文章说过,此代码的网站地址是http://demo.od.com/hello?name=随意参数,只要有返回值参数随意,所以这里你写成http://demo.od.com/hello?name=wewe都行。写成health只是为了规范(健康)
"annotations": {
"blackbox_port": "8080",
"blackbox_scheme": "http",
"blackbox_path": "/hello?name=health"
}
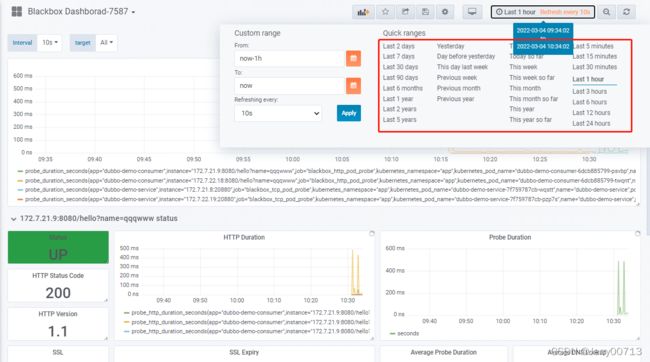
启动后查看Prometheus→Targets→blackbox_http_pod_probe
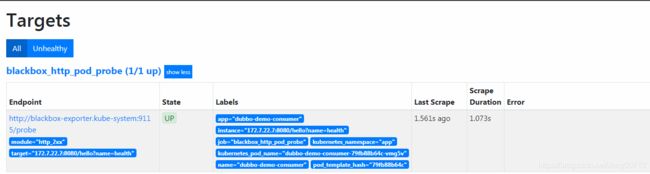
注:必须是(demo.od.com/hello?name=随意参数)参数可以随便写,比如写成qqqwww


5、部署Grafana
5.1、安装Grafana
[root@hdss7-200 ~]# docker pull grafana/grafana:5.4.2
[root@hdss7-200 ~]# docker image ls |grep grafana
grafana/grafana 5.4.2 6f18ddf9e552 2 years ago 243MB
[root@hdss7-200 ~]# docker image tag 6f18ddf9e552 harbor.od.com:180/infra/grafana:v5.4.2
[root@hdss7-200 ~]# docker login harbor.od.com:180
[root@hdss7-200 ~]# docker image push harbor.od.com:180/infra/grafana:v5.4.2
5.2、准备资源配置清单
[root@hdss7-200 ~]# mkdir /data/k8s-yaml/grafana;cd /data/k8s-yaml/grafana
[root@hdss7-200 grafana]# vi rbac.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: grafana
rules:
- apiGroups:
- "*"
resources:
- namespaces
- deployments
- pods
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/cluster-service: "true"
name: grafana
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: grafana
subjects:
- kind: User
name: k8s-node[root@hdss7-200 grafana]# vi dp.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
app: grafana
name: grafana
name: grafana
namespace: infra
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 7
selector:
matchLabels:
name: grafana
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
template:
metadata:
labels:
app: grafana
name: grafana
spec:
containers:
- name: grafana
image: harbor.od.com:180/infra/grafana:v5.4.2
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
protocol: TCP
volumeMounts:
- mountPath: /var/lib/grafana
name: data
imagePullSecrets:
- name: harbor
securityContext:
runAsUser: 0
volumes:
- nfs:
server: hdss7-200
path: /data/nfs-volume/grafana
name: data[root@hdss7-200 grafana]# mkdir /data/nfs-volume/grafana
[root@hdss7-200 grafana]# vi svc.yaml
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: infra
spec:
ports:
- port: 3000
protocol: TCP
targetPort: 3000
selector:
app: grafana[root@hdss7-200 grafana]# vi ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: grafana
namespace: infra
spec:
rules:
- host: grafana.od.com
http:
paths:
- path: /
backend:
serviceName: grafana
servicePort: 3000配置nds解析
[root@hdss7-11 ~]# vi /var/named/od.com.zone
$ORIGIN od.com.
$TTL 600 ; 10 minutes
@ IN SOA dns.od.com. dnsadmin.od.com. (
2020010518 ; serial
10800 ; refresh (3 hours)
900 ; retry (15 minutes)
604800 ; expire (1 week)
86400 ; minimum (1 day)
)
NS dns.od.com.
$TTL 60 ; 1 minute
dns A 10.4.7.11
harbor A 10.4.7.200
k8s-yaml A 10.4.7.200
traefik A 10.4.7.10
dashboard A 10.4.7.10
zk1 A 10.4.7.11
zk2 A 10.4.7.12
zk3 A 10.4.7.21
jenkins A 10.4.7.10
dubbo-monitor A 10.4.7.10
demo A 10.4.7.10
config A 10.4.7.10
mysql A 10.4.7.11
portal A 10.4.7.10
zk-test A 10.4.7.11
zk-prod A 10.4.7.12
config-test A 10.4.7.10
config-prod A 10.4.7.10
demo-test A 10.4.7.10
demo-prod A 10.4.7.10
blackbox A 10.4.7.10
prometheus A 10.4.7.10
grafana A 10.4.7.10[root@hdss7-11 ~]# systemctl restart named
[root@hdss7-11 ~]# dig -t A grafana.od.com @10.4.7.11 +short
10.4.7.10
5.3、应用资源配置清单
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/grafana/rbac.yaml
clusterrole.rbac.authorization.k8s.io/grafana created
clusterrolebinding.rbac.authorization.k8s.io/grafana created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/grafana/dp.yaml
deployment.extensions/grafana created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/grafana/svc.yaml
service/grafana created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/grafana/ingress.yaml
ingress.extensions/grafana created
访问http://grafana.od.com/
默认账户admin 密码 admin,第一次登录后让你输入新密码,改成admin123

配置(配置界面)--记得保存

5.4、安装插件
# 默认grafana少插件,需要后期安装插件
grafana-kubernetes-app
grafana-clock-panel 时钟插件
grafana-piechart-panel 饼图
briangann-gauge-panel D3 Gauge
natel-discrete-panel Discrete

# 以上插件安装有两种方式:
方式一: 进入docker容器中,执行各个安装命令 [root@hdss7-21 ~]# kubectl get pod -n infra -l name=grafana NAME READY STATUS RESTARTS AGE grafana-6d45bd5f75-x8pxr 1/1 Running 0 79m [root@hdss7-21 ~]# kubectl exec -it grafana-6d45bd5f75-x8pxr -n infra /bin/bashroot@grafana-596d8dbcd5-l2466:/usr/share/grafana# grafana-cli plugins install grafana-kubernetes-app root@grafana-596d8dbcd5-l2466:/usr/share/grafana# grafana-cli plugins install grafana-clock-panel root@grafana-596d8dbcd5-l2466:/usr/share/grafana# grafana-cli plugins install grafana-piechart-panel root@grafana-596d8dbcd5-l2466:/usr/share/grafana# grafana-cli plugins install briangann-gauge-panel root@grafana-596d8dbcd5-l2466:/usr/share/grafana# grafana-cli plugins install natel-discrete-panel 安装后有下面提示代表成功 √Installed $name sccessfully
方式二:手动下载插件zip包,访问 https://grafana.com/api/plugins/repo/$plugin_name 查询插件版本号 $version # 通过 https://grafana.com/api/plugins/$plugin_name/versions/$version/download 下载zip包 # 将zip包解压到 /data/nfs-volume/grafana/plugins 下 # 插件安装完毕后,重启Grafana的Pod [root@hdss7-200 plugins]# cd /data/nfs-volume/grafana/plugins [root@hdss7-200 plugins]# wget -O grafana-kubernetes-app.zip https://grafana.com/api/plugins/grafana-kubernetes-app/versions/1.0.1/download [root@hdss7-200 plugins]# wget -O grafana-clock-panel.zip https://grafana.com/api/plugins/grafana-clock-panel/versions/1.0.1/download [root@hdss7-200 plugins]# wget -O grafana-piechart-panel.zip https://grafana.com/api/plugins/grafana-piechart-panel/versions/1.0.1/download [root@hdss7-200 plugins]# wget -O briangann-gauge-panel.zip https://grafana.com/api/plugins/briangann-gauge-panel/versions/1.0.1/download [root@hdss7-200 plugins]# wget -O natel-discrete-panel.zip https://grafana.com/api/plugins/natel-discrete-panel/versions/1.0.1/download [root@hdss7-200 plugins]# ls *.zip | xargs -I {} unzip -q {}
不管方式一还是二都需要重启grafana,插件才能生效
[root@hdss7-21 ~]# kubectl delete pod grafana-6d45bd5f75-x8pxr -n infra
pod "grafana-6d45bd5f75-x8pxr" deleted
[root@hdss7-21 ~]# kubectl get pod -o wide -n infra
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
grafana-6d45bd5f75-wlm95 1/1 Running 0 42s 172.7.21.5 hdss7-21.host.com
5.5、添加数据源
选择 prometheus 作为数据源
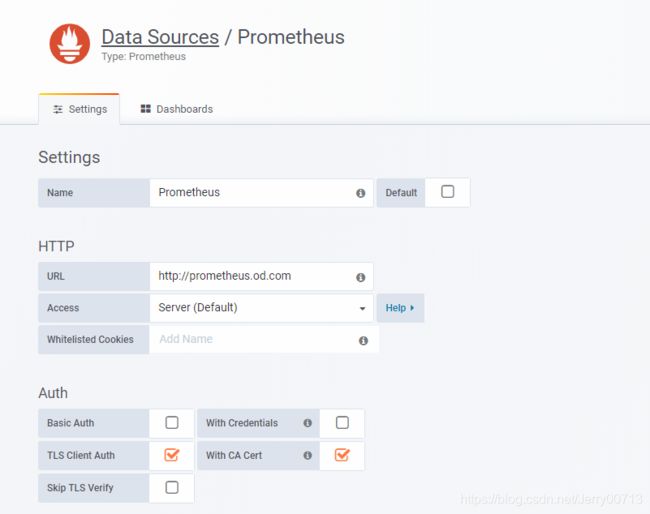
URL:http://prometheus.od.com
Access:Server 服务端
Whitelisted Cookies:白名单不用写
TLS Client Auth:tls 双向认
With CA Cert : CA证书,因为grafana需要有https权限访问k8s资源
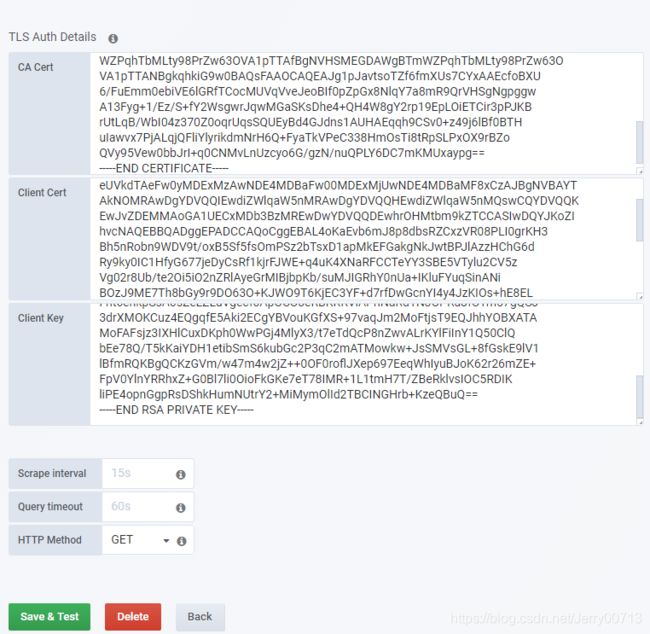
把hdss7-200的 /opt/certs/ca.pem 内容复制到CA.Cert
把hdss7-200的 /opt/certs/client.pem 复制到Clinet.Cert
把hdss7-200的 /opt/certs/client-key.pem 复制到Clinet.key
Scrape interval 采集的时间间隔
然后点击 Save & Test
配置kubernetes插件,点击kubernetes

点击enable

点击enable后,如下左边会出现一个kubernetes(Clusters) ,点击

点击kubernetes(Clusters) 后,点击new Clusters

name :填写名字随意
url :https://10.4.7.10:7443 (这里写apiserver中的地址,因为10.4.7.21、10.4.7.22 的kube-apiserver 启动6443端口,并且代理给10.4.7.10的7443端口)
Access:Server 服务端
TLS Client Auth:tls 双向认
With CA Cert : CA证书,因为grafana需要有https权限访问k8s资源
把hdss7-200的 /opt/certs/ca.pem 内容复制到CA.Cert
把hdss7-200的 /opt/certs/client.pem 复制到Clinet.Cert
把hdss7-200的 /opt/certs/client-key.pem 复制到Clinet.key
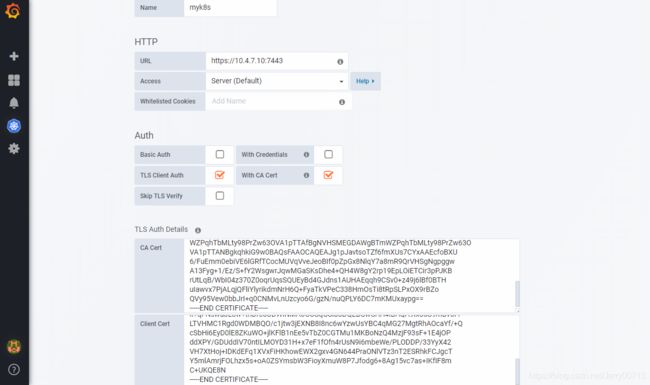
Datasource:Prometheus,然后save

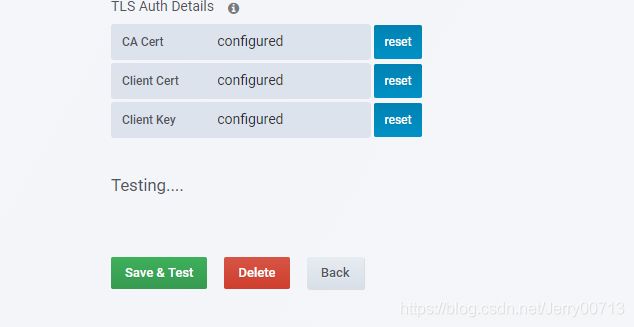
测试有无问题
点击如下
点击myk8s
点击save & test
报错没影响
5.6、查看监控选项
再次点击
点击如下
点击 Pod/Container Dashboard

发现数据
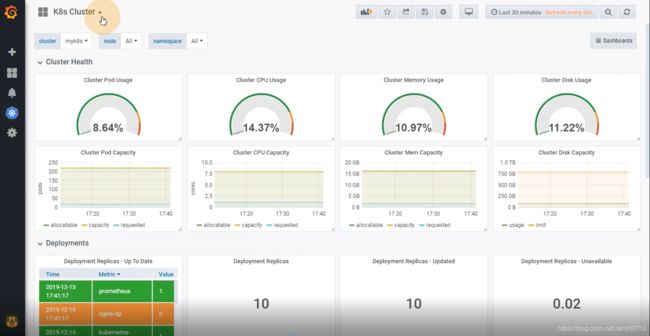
点击左上角的K8s Cluster ,这个插件会生成4个dashboard的概要。比如k8s Deployments 里面有多少个k8s 的Deployments、有多少个Deployments版本。k8s Container:内存/cpu使用率。
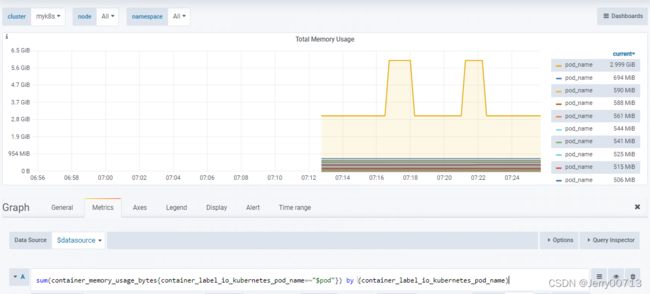
k8s Container有bug,默认取不到数据,点击上图的切换到k8s Container后,发现跟本数据,点击检测cpu或者memory内存的edit,需要修改两个pod_name为container_label_io_kubernetes_pod_name


5.7、导入监控模板
由于自带的有bug,监控的不准,所以全部删除,依次进入(
K8s Cluster、K8s Deployments、K8s Node、K8s Container)按照如下删除


 从
从
导入监控模板两种方式:
方式一:
去官网找新的dashboard监控模板
点击dashboards后,Dashboards | Grafana Labs,点击最多下载的
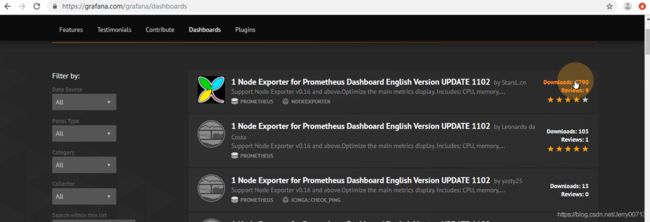
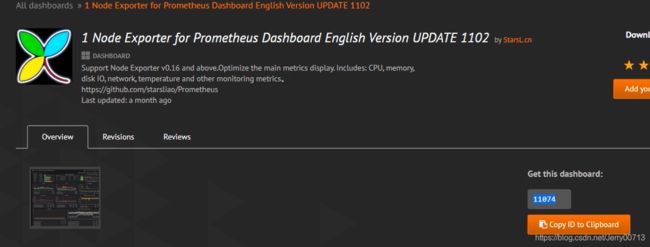
找到编号为11074
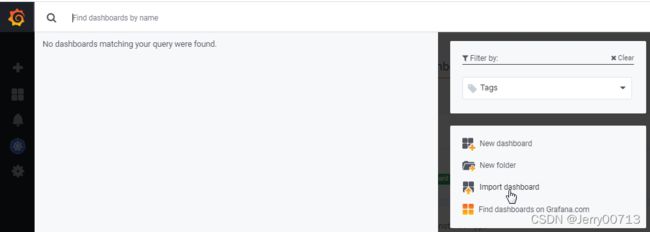
在自己的grafana中,点击import dashboard
输入编号,然后load
VictoriaMetrics: Prometheus后,点击import自动导入


方式二:load你本地的dashboard的模板
在自己的grafana中,点击import dashboard
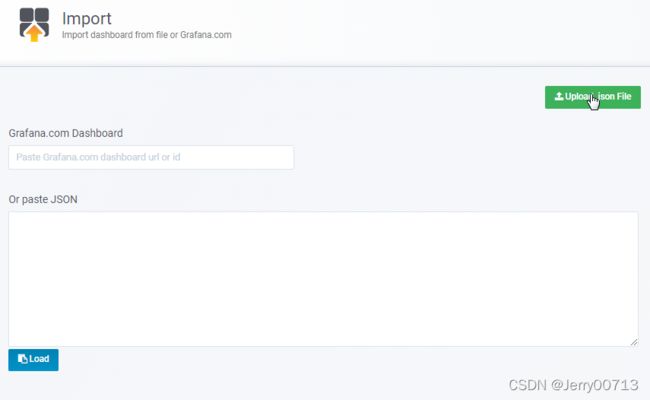
在导入的时候点击Upload .json File 是load你本地的dashboard的模板
模板下载:GrafanaDashboard.zip-kubernetes文档类资源-CSDN下载
需要导入(K8s Node Dashboard.json、K8S Cluster Dashboard.json、K8s Deployments Dashboard.json、K8s Container Dashboard.json等)
比如导入K8s Node Dashboard.json,选中后import

5.8、查看导入的新监控模板
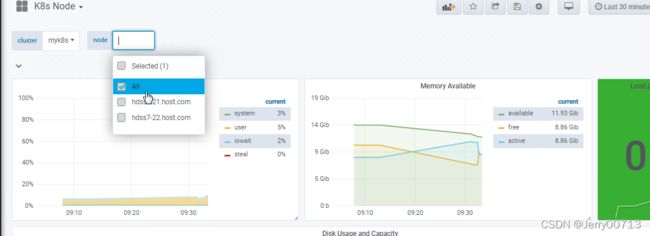
导入K8s Node Dashboard.json后查看k8s ndoe ,可以查看两个节点,对应的代表k8s两个节点
查看对应的负载(1.5)
k8s ndoe模板查看, 节点的磁盘、IO、网络
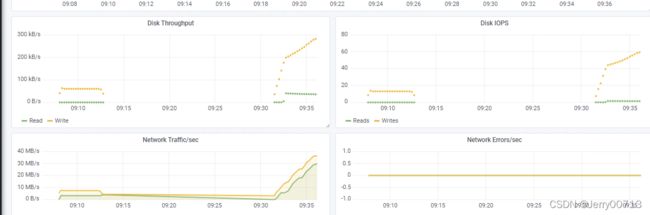
查看k8s Cluster 模板(集群的概况),Cluster Cpu Uasge ( cpu的百分比)、Cluster Memory Uasge (内存的百分比)
Deployment Replicas (多少个副本)


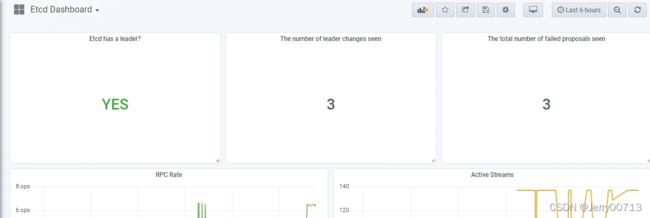
导入k8s ndoedaEtcd Dashboard.json后,查看Etcd Dashboard 模板,这些监控信息都是从prometheus的 Targets 的etcd 获取。自动匹配。

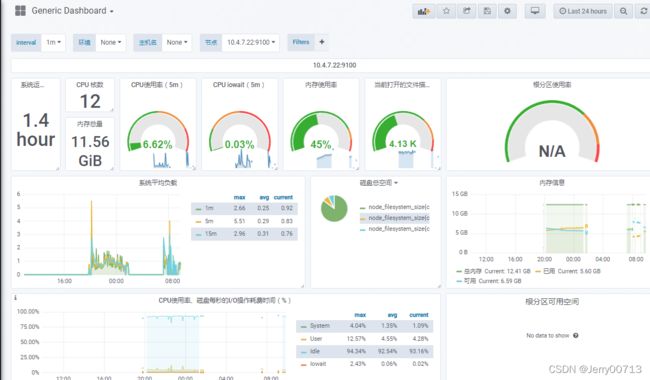
导入Generic Dashboard.json(通用模板),他是监控宿主机的,跟K8s Node模板差不多。打开Generic Dasghboard 显示一些根分区,磁盘空间、内存信息、磁盘容量、硬件温度等等。通过prometheus的node-exporter获取。
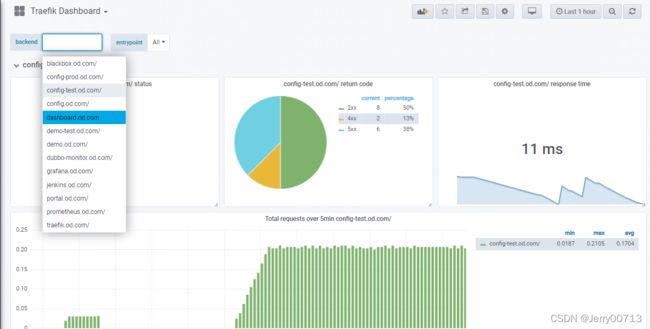
导入Traefik Dashboard.json,查看Traefik Dashboard ,我们知道traefik是ingress-controller ,也就是ingres的控制器,客户端流量通过ingres的控制器转发给service资源。所以可以选择所有的http协议的流量。通过prometheus的 Targets 的traefik 获取。所以不要忘记配置prometheus自动发现traefik
查看dashboard的流量,200ms,不到1s,3s以内是可以的,网站质量还可以

导入Blackbox Dashboard-9965.json,给重命名一下,因为有两个Blackbox模板区分一下
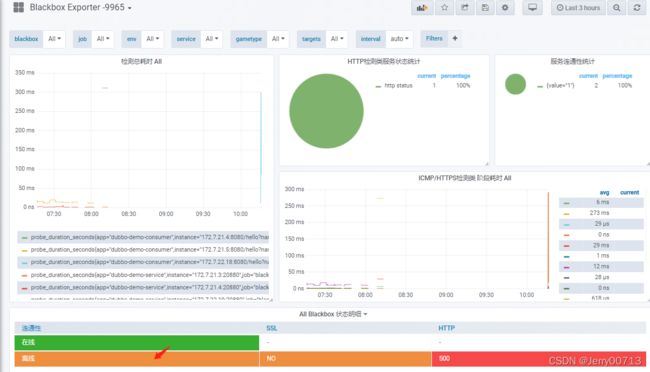
1、查看Blackbox Exporter -9965,其中有一个在线跟一个离线分别代表的是(blackbox_http_pod_probe、blackbox_tcp_pod_probe ),为什么有离线?
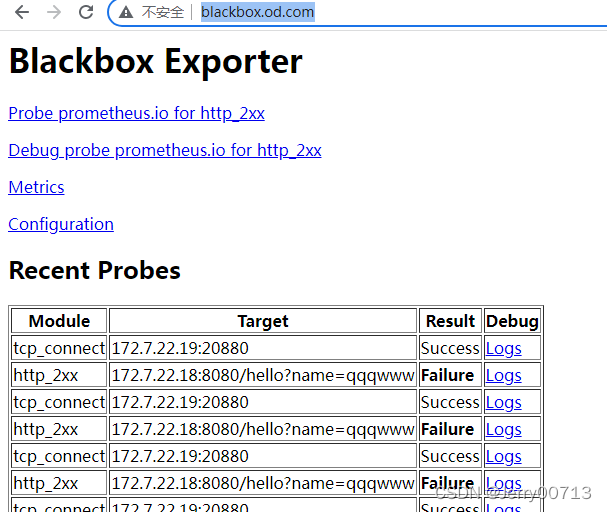
从Prometheus 看到的仅仅代表有数据源,就是Blackbox Exporter -9965模板的那两条,仅此而已
查看blackbox.od.com,是不是有失败的,如下提示失败了,这就得找为什么失败了,如果是TCP就telnet port,如果是HTTP就curl IP:port/网址?参数等等
找到问题之后,blackbox.od.com 是success
2、查看Blackbox Exporter -9965,SSL代表是不是tcp检测,HTTP代表是不是HTTP检测,检测curl -I的返回值是多少


导入Blackbox Dashboard-9965.json,给重命名一下,因为有两个Blackbox模板区分一下
Blackbox Dashboard用来监控blackbox-exporter,blackbox-exporter监控dubbo-demo-server等。可以修改时间周期
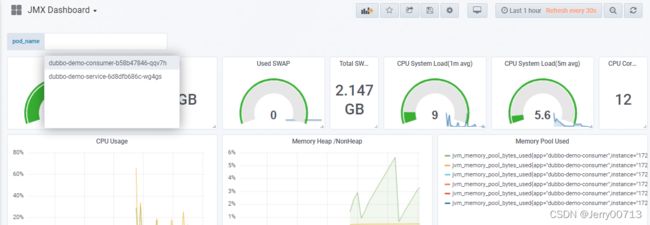
导入JMX Dashboard.json,查看JMX dashboard (用来监控业务容器的jvm)。当前数据为空,是因为没有配置prometheus的。所以需要加注解
在dubbo消费者、生产者的业务容器的yaml中加入注解
"annotations": { "prometheus_io_scrape": "true", "prometheus_io_port": "12346", "prometheus_io_path": "/" } 注意: "prometheus_io_scrape": "true" # 是不是要监控jvm,true "prometheus_io_port": "12346", # java启动的时候会生成jvm信息,需要用端口作为jvm远程端口,随时调取jvm信息,所以 安装Maven到Jenkins的时候,制作JRE镜像底 包,就配置了12346 "prometheus_io_path": "/" # 意思是访问jvm资源的路径是(http://IP:端口/),例如容器的IP是172.17.22.18,访问 的就是http://172.17.22.18:12346/,如 果"prometheus_io_path": "index", 访问的就 是http://172.17.22.18:12346/index/修改dubboe-demo-servic、dubboe-demo-consumer的yaml,因为之前配置过blackbox的注解,所以在这个注解下跟着写就行,随后kill 容器重启pod


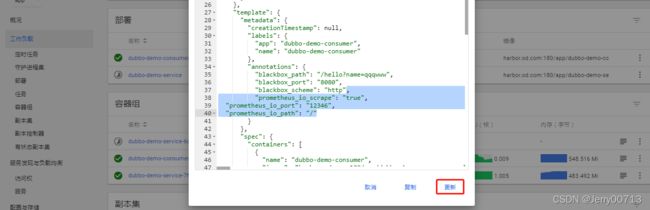
总结:
1、监控某服务的容器
方法:通过安装对应的exporter后,配置在prometheus.yaml,在声明annotations注解
注解如下:
"annotations": {
"prometheus_io_scheme": "traefik",
"prometheus_io_path": "/metrics",
"prometheus_io_port": "8080"
}
2、监控某服务的存活
方法:不用安装对应的exporter,配置annotations注解,在blackbox显示,prometheus去pull
注解如下:
(1)如果是tcp, 端口:port, telnet 端口通为存活
"annotations": {
"blackbox_port": "20880",
"blackbox_scheme": "tcp"
}
(2)如果是http, ip:端口/网址?参数 ,curl -I ip:端口/网址?参数,返回值在200~300为存活
"annotations": {
"blackbox_path": "/hello?name=health",
"blackbox_port": "8080",
"blackbox_scheme": "http"
}
3、监控jvm:跟监控某服务的容器一致
"annotations": {
"prometheus_io_scrape": "true",
"prometheus_io_port": "12346",
"prometheus_io_path": "/"
}6、部署alertmanager
配置alertmanager,使用你的qq邮箱发给告警
6.1、准备镜像
注:不建议使用高版本,比如v0.19.0,容器起不来,会报错Back-off restarting failed containe
容器logs(# couldn't deduce an advertise address: no private IP found, explicit advertise addr not provided)
[root@hdss7-200 ]# docker pull docker.io/prom/alertmanager:v0.14.0
[root@7-200 alertmanager]# docker images |grep alertmanager
prom/alertmanager v0.14.0 23744b2d645c 4 years ago 31.9MB
[root@hdss7-200 ]# docker image tag 23744b2d645c harbor.od.com:180/infra/alertmanager:v0.14.0
[root@hdss7-200 ]# docker login harbor.od.com:180
[root@hdss7-200 ]# docker push harbor.od.com:180/infra/alertmanager:v0.14.06.2、准备资源配置清单
[root@hdss7-200 ~]# mkdir /data/k8s-yaml/alertmanager;cd /data/k8s-yaml/alertmanager
[root@hdss7-200 alertmanager]# vi cm.yaml # 注意不能带注释,由于字符集问题
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: infra
data:
config.yml: |-
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: '×××××××'
smtp_require_tls: false
route:
group_by: ['alertname', 'cluster']
group_wait: 30s
group_interval: 5m
repeat_interval: 5m
receiver: default
receivers:
- name: 'default'
email_configs:
- to: '[email protected]'
send_resolved: true
解释:
global:
# 在没有报警的情况下声明为已解决的时间
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.qq.com:465' # 邮箱的smtp服务器
smtp_from: '[email protected]' # 从哪个邮箱发
smtp_auth_username: '[email protected]' # 邮箱的登录名
smtp_auth_password: '×××××××' # 自己邮箱的smtp验证密码,不是邮箱密码
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['alertname', 'cluster']
# 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。
group_interval: 5m
# 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们
repeat_interval: 5m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
receivers:
- name: 'default'
email_configs:
- to: '[email protected]' # 收件人
send_resolved: true注:配置alertmanager使用你的qq邮箱发给告警,需要取得qq邮箱的信任,就比如你需要密码才能登录,还需要配置(是哪个邮箱服务器),所以smtp_smarthost为你邮箱的SMTP服务器,如果是其他的邮箱服务器,自行百度(××邮箱的POP3与SMTP服务器是什么)
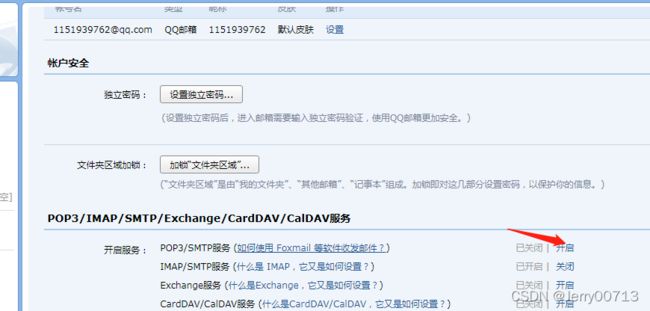
紧接着qq邮箱需要开启SMTP功能
smtp验证密码

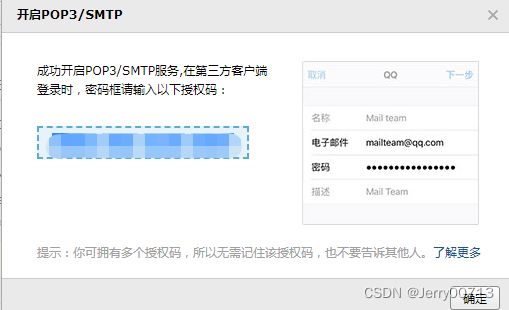
[root@hdss7-200 alertmanager]# vi dp.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: alertmanager
namespace: infra
spec:
replicas: 1
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
spec:
containers:
- name: alertmanager
image: harbor.od.com:180/infra/alertmanager:v0.14.0
args:
- "--config.file=/etc/alertmanager/config.yml"
- "--storage.path=/alertmanager"
ports:
- name: alertmanager
containerPort: 9093
volumeMounts:
- name: alertmanager-cm
mountPath: /etc/alertmanager
volumes:
- name: alertmanager-cm
configMap:
name: alertmanager-config
imagePullSecrets:
- name: harbor[root@hdss7-200 alertmanager]# vi svc.yaml
# Prometheus调用alert采用service name。不走ingress域名
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: infra
spec:
selector:
app: alertmanager
ports:
- port: 80
targetPort: 90936.3、应用资源配置清单
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/alertmanager/cm.yaml
configmap/alertmanager created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/alertmanager/dp.yaml
deployment.extensions/alertmanager created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/alertmanager/svc.yaml
service/alertmanager created
6.4、配置alert与prometheus联系
添加alert告警规则
[root@hdss7-200 ~]# vi /data/nfs-volume/prometheus/etc/rules.yml # alert告警规则配置在prometheus目录下,通过共享存储在容器中
groups:
- name: hostStatsAlert
rules:
- alert: hostCpuUsageAlert
expr: sum(avg without (cpu)(irate(node_cpu{mode!='idle'}[5m]))) by (instance) > 0.85
for: 5m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }}%)"
- alert: hostMemUsageAlert
expr: (node_memory_MemTotal - node_memory_MemAvailable)/node_memory_MemTotal > 0.85
for: 5m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }}%)"
- alert: OutOfInodes
expr: node_filesystem_free{fstype="overlay",mountpoint ="/"} / node_filesystem_size{fstype="overlay",mountpoint ="/"} * 100 < 10
for: 5m
labels:
severity: warning
annotations:
summary: "Out of inodes (instance {{ $labels.instance }})"
description: "Disk is almost running out of available inodes (< 10% left) (current value: {{ $value }})"
- alert: OutOfDiskSpace
expr: node_filesystem_free{fstype="overlay",mountpoint ="/rootfs"} / node_filesystem_size{fstype="overlay",mountpoint ="/rootfs"} * 100 < 10
for: 5m
labels:
severity: warning
annotations:
summary: "Out of disk space (instance {{ $labels.instance }})"
description: "Disk is almost full (< 10% left) (current value: {{ $value }})"
- alert: UnusualNetworkThroughputIn
expr: sum by (instance) (irate(node_network_receive_bytes[2m])) / 1024 / 1024 > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual network throughput in (instance {{ $labels.instance }})"
description: "Host network interfaces are probably receiving too much data (> 100 MB/s) (current value: {{ $value }})"
- alert: UnusualNetworkThroughputOut
expr: sum by (instance) (irate(node_network_transmit_bytes[2m])) / 1024 / 1024 > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual network throughput out (instance {{ $labels.instance }})"
description: "Host network interfaces are probably sending too much data (> 100 MB/s) (current value: {{ $value }})"
- alert: UnusualDiskReadRate
expr: sum by (instance) (irate(node_disk_bytes_read[2m])) / 1024 / 1024 > 50
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk read rate (instance {{ $labels.instance }})"
description: "Disk is probably reading too much data (> 50 MB/s) (current value: {{ $value }})"
- alert: UnusualDiskWriteRate
expr: sum by (instance) (irate(node_disk_bytes_written[2m])) / 1024 / 1024 > 50
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk write rate (instance {{ $labels.instance }})"
description: "Disk is probably writing too much data (> 50 MB/s) (current value: {{ $value }})"
- alert: UnusualDiskReadLatency
expr: rate(node_disk_read_time_ms[1m]) / rate(node_disk_reads_completed[1m]) > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk read latency (instance {{ $labels.instance }})"
description: "Disk latency is growing (read operations > 100ms) (current value: {{ $value }})"
- alert: UnusualDiskWriteLatency
expr: rate(node_disk_write_time_ms[1m]) / rate(node_disk_writes_completedl[1m]) > 100
for: 5m
labels:
severity: warning
annotations:
summary: "Unusual disk write latency (instance {{ $labels.instance }})"
description: "Disk latency is growing (write operations > 100ms) (current value: {{ $value }})"
- name: http_status
rules:
- alert: ProbeFailed
expr: probe_success == 0
for: 1m
labels:
severity: error
annotations:
summary: "Probe failed (instance {{ $labels.instance }})"
description: "Probe failed (current value: {{ $value }})"
- alert: StatusCode
expr: probe_http_status_code <= 199 OR probe_http_status_code >= 400
for: 1m
labels:
severity: error
annotations:
summary: "Status Code (instance {{ $labels.instance }})"
description: "HTTP status code is not 200-399 (current value: {{ $value }})"
- alert: SslCertificateWillExpireSoon
expr: probe_ssl_earliest_cert_expiry - time() < 86400 * 30
for: 5m
labels:
severity: warning
annotations:
summary: "SSL certificate will expire soon (instance {{ $labels.instance }})"
description: "SSL certificate expires in 30 days (current value: {{ $value }})"
- alert: SslCertificateHasExpired
expr: probe_ssl_earliest_cert_expiry - time() <= 0
for: 5m
labels:
severity: error
annotations:
summary: "SSL certificate has expired (instance {{ $labels.instance }})"
description: "SSL certificate has expired already (current value: {{ $value }})"
- alert: BlackboxSlowPing
expr: probe_icmp_duration_seconds > 2
for: 5m
labels:
severity: warning
annotations:
summary: "Blackbox slow ping (instance {{ $labels.instance }})"
description: "Blackbox ping took more than 2s (current value: {{ $value }})"
- alert: BlackboxSlowRequests
expr: probe_http_duration_seconds > 2
for: 5m
labels:
severity: warning
annotations:
summary: "Blackbox slow requests (instance {{ $labels.instance }})"
description: "Blackbox request took more than 2s (current value: {{ $value }})"
- alert: PodCpuUsagePercent
expr: sum(sum(label_replace(irate(container_cpu_usage_seconds_total[1m]),"pod","$1","container_label_io_kubernetes_pod_name", "(.*)"))by(pod) / on(pod) group_right kube_pod_container_resource_limits_cpu_cores *100 )by(container,namespace,node,pod,severity) > 80
for: 5m
labels:
severity: warning
annotations:
summary: "Pod cpu usage percent has exceeded 80% (current value: {{ $value }}%)"修改Prometheus配置,使其调用alter。如果alter跟Prometheus不在一个命名空间还需要带上命名空间
[root@hdss7-200 ~]# vim /data/nfs-volume/prometheus/etc/prometheus.yml # 在末尾追加,关联告警规则
......
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager"]
rule_files:
- "/data/etc/rules.yml"
然后重启promenteus,但是生产环境下不要删除promenteus的pod,因为太大,启动时间太长,还容易给集群拖垮。查看promenteus的pod部署在那个node,之前我们配置promenteus运行在hdss7-21上,所以找到promenteus的pid,由于promenteus支持配置文件修改后,平滑加载。然后kill -SIGHUP 就实现平滑加载。其中SIGHUP传递信号
[root@hdss7-21 ~]# ps aux |grep prometheus
root 3337 3.1 0.3 171828 38612 ? Ssl 08:29 7:21 traefik traefik --api --kubernetes --logLevel=INFO --insecureskipverify=true --kubernetes.endpoint=https://10.4.7.10:7443 --accesslog --accesslog.filepath=/var/log/traefik_access.log --traefiklog --traefiklog.filepath=/var/log/traefik.log --metrics.prometheus
root 30874 90.0 32.1 4287560 3899452 ? Ssl 09:28 159:53 /bin/prometheus --config.file=/data/etc/prometheus.yml --storage.tsdb.path=/data/prom-db --storage.tsdb.min-block-duration=5m --storage.tsdb.retention=24h
root 114768 0.0 0.0 112812 968 pts/0 S+ 12:25 0:00 grep --color=auto prometheus
[root@hdss7-21 ~]# kill -SIGHUP 30874
查看Alerts,查看报警规则
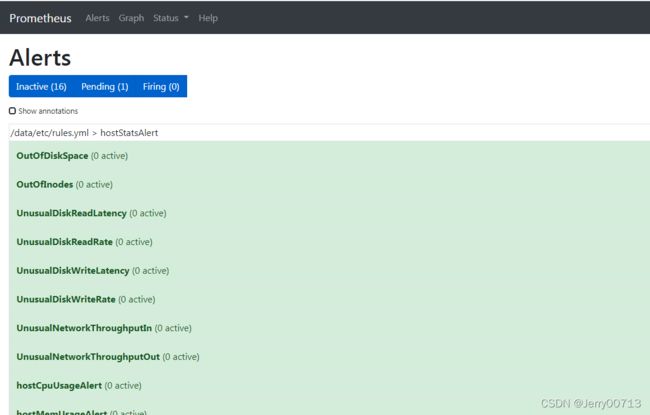
测试告警:
把dubbo-demo-service 停止,dubbo-demo-consumer一定是报错,然后触发报警
Blackbox首先已经报错
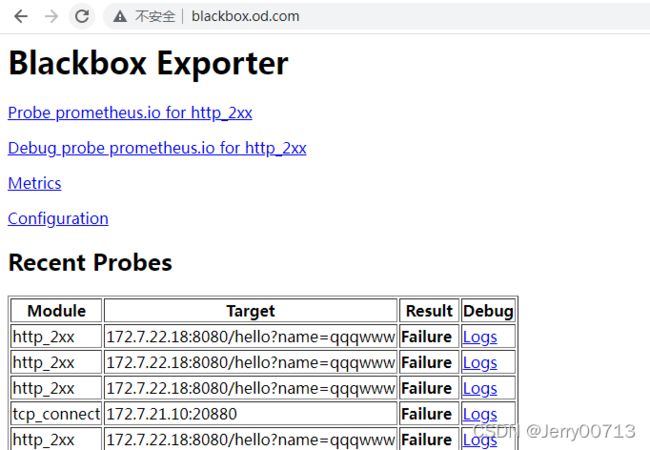
查看Alerts,提示报错变成黄色代表检测异常

等过一会后,变成红色后就会发邮件

查看邮件
