将ndarray对象的数据按索引矩阵进行选取的几种方法
将ndarray对象的数据按索引矩阵进行选取的几种方法
有很多时候,我们需要把ndarray对象的数据按索引矩阵进行选择,本文就写一写此操作的常用方法
目录
- 01-按维度和索引选择数据
- 02-以对象A中的值为索引挑选矩阵choices中的值形成新的矩阵
- 03-由索引矩阵生成新的矩阵
- 04-通过布尔值来对矩阵数据进行压缩处理
01-按维度和索引选择数据
可以用方法take()实现这个需求。
方法take()的原型如下:
take(a, indices[, axis, out, mode])
官方说明如下:
Return an array formed from the elements of a at the given indices.
示例代码如下:
import numpy as np
A = np.array([[1, 2, 3, 4, 5],
[6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20]], dtype='int8')
B = A.take([1, 3], 1)
C = A.take([1, 3], 0)
运行结果如下:
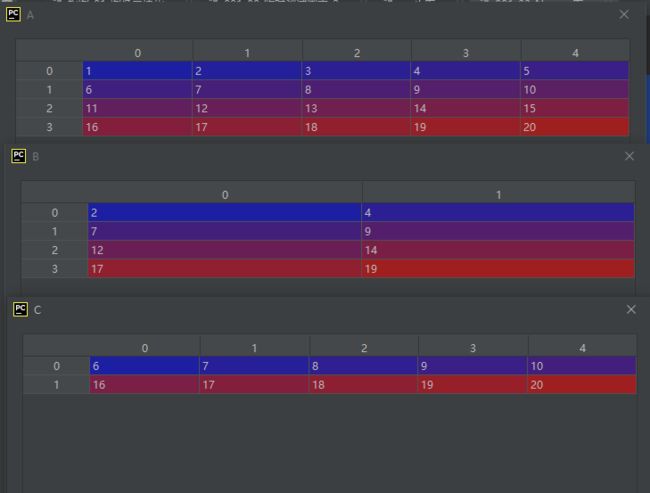
代码和结果说明:
由上面的运行可以看出:
当参数indices=1时,索引表示哪一列,即按列进行数据选择。
当参数indices=0时,索引表示哪一行,即按行进行数据选择。
02-以对象A中的值为索引挑选矩阵choices中的值形成新的矩阵
可以用方法choose()实现这个功能。
方法choose()的原型如下:
choose(choices[, out, mode])
Use an index array to construct a new array from a set of choices.
示例代码如下:
import numpy as np
A = np.array([[0, 0, 3], [1, 0, 2], [2, 1, 0]])
B = np.array([3, 7, 6, 2])
C = A.choose(B)
运行结果如下:
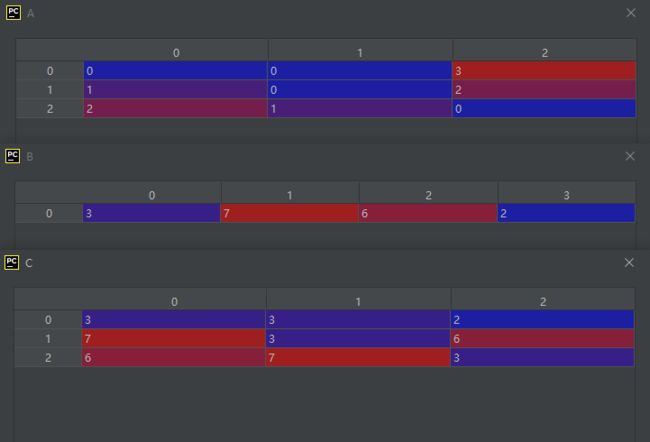
此时C形成的具体过程请大家参见博文 https://www.hhai.cc/thread-121-1-1.html
如果B是二维的,则A中各元素的值是对B中每列元素的索引:
示例如下:
A = np.array([[1, 0, 2], [0, 2, 0]])
B = np.array([[3, 7, 6],
[1, 8, 9],
[2, 5, 4]])
C = A.choose(B)
运行结果如下:

此时C形成的具体过程请大家参见博文 https://www.hhai.cc/thread-121-1-1.html
一个实际的应用场景为:
假设B为二维矩阵,每一列为一个样本,列中的元素依次为样本的某个特征值,则我们可以通过设定A取出每个样本的某个特征值形成一个新的矩阵。
当然上面介绍的方法take()也可实现这个需求,并且似乎更直观,更简单。
关于方法choose()的参数mode说两句,参数mode影响上述例子中A中各元素的取值范围,设B中的索引最大值为n-1,
则
mode=‘raise’,表示A中的数必须在[0,n-1]范围内
mode=‘wrap’,表示A中的数可以是任意的整数(signed),对n取余映射到[0,n-1]范围内
mode=‘clip’, 表示A中的数可以是任意的整数(signed),负数映射为0,大于n-1的数映射为n-1
03-由索引矩阵生成新的矩阵
可以用函数take_along_axis()实现这个功能,函数take_along_axis()的使用和理解比较难,为此,我专门写了一篇博文进行介绍,详情见链接 https://www.hhai.cc/thread-120-1-1.html
04-通过布尔值来对矩阵数据进行压缩处理
可以使用方法compress()实现这个功能。
原型如下:
compress(condition[, axis, out])
示例代码如下:
import numpy as np
A = np.array([[1, 2], [3, 4], [5, 6]])
B = A.compress([0, 1, 1], axis=0)
C = A.compress([False, True], axis=1)
运行结果如下:

分析:
语句 B = A.compress([0, 1, 1], axis=0) 代表在列方向上进行压缩,第1个数0代表某列的第0个元素被舍弃;第2个数1代表某列的第1个元素被保留;第3个数1代表某列的第2个元素被保留。
以A的第0列为例,元素1被舍弃,元素3、5被保留。
以此类推…
而语句 C = A.compress([False, True], axis=1)代表在行方向上进行压缩,第1个布尔值False代表某行的第0个元素被舍弃,第2个布尔值True代表某行的第1个元素被舍弃。
以A的第0行为例,元素1被舍弃,元素2被保留。
以此类推…