2021机器学习面试必考面试题汇总(附答案详解)
问题:Xgboost、lightGBM和Catboost之间的异同?
树的特征
三种算法基学习器都是决策树,但是树的特征以及生成的过程仍然有很多不同。
CatBoost使用对称树,其节点可以是镜像的。CatBoost基于的树模型其实都是完全二叉树。
XGBoost的决策树是Level-wise增长。Level-wise可以同时分裂同一层的叶子,容易进行多线程优化,过拟合风险较小,但是这种分裂方式也有缺陷,Level-wise对待同一层的叶子不加以区分,带来了很多没必要的开销。
实际上很多叶子的分裂增益较低,没有搜索和分裂的必要。 LightGBM的决策树是Leaf-wise增长。每次从当前所有叶子中找到分裂增益最大的一个叶子(通常来说是数据最多的一个),其缺陷是容易生长出比较深的决策树,产生过拟合,为了解决这个问题,LightGBM在Leaf-wise之上增加了一个最大深度的限制。
对于类别型变量
调用boost模型时,当遇到类别型变量,xgboost需要先处理好,再输入到模型,而lightgbm可以指定类别型变量的名称,训练过程中自动处理。
具体来讲,CatBoost 可赋予分类变量指标,进而通过独热最大量得到独热编码形式的结果(独热最大量:在所有特征上,对小于等于某个给定参数值的不同的数使用独热编码;同时,在 CatBoost 语句中设置“跳过”,CatBoost 就会将所有列当作数值变量处理)。
LighGBM 也可以通过使用特征名称的输入来处理属性数据;它没有对数据进行独热编码,因此速度比独热编码快得多。LGBM 使用了一个特殊的算法来确定属性特征的分割值。(注:需要将分类变量转化为整型变量;此算法不允许将字符串数据传给分类变量参数)
和 CatBoost 以及 LGBM 算法不同,XGBoost 本身无法处理分类变量,只接受数值数据,这点和RF很相似。实际使用中,在将分类数据传入 XGBoost 之前,必须通过标记编码、均值编码或独热编码等各种编码方式对数据进行处理。
文末免费送电子书:七月在线干货组最新 升级的《名企AI面试100题》免费送!
篇幅有限,仅展示部分题目,本篇文章面试题来源于七月在线官网,免费题库,近4000道名企AI笔试⾯试题等着⼤家,刷题愉快。
问题:SVM 和 Logistic 回归分别在什么情况下使用?
SVM 和 LR的选择实际上是模型预测能力和运行效率的权衡,从样本和特征数量的角度分析如下:
1. 若特征数量较大,样本数量较小(例如:1万个特征,1000个样本),则使用 LR。因为使用线性模型就能取得不错的效果,无需使用过于复杂的模型;
2. 若特征数量较小,样本数量中等(例如:10个特征,1万个样本),则使用高斯核函数的SVM。因为特征数较小,使用复杂核函数的SVM可以得到较好的预测性能,这一点胜过 LR,且样本数量中等,运算速度不会太慢;
3. 若特征数量中等,样本数量非常大(例如100个特征,50万个样本),则应该先构造更多的特征,然后使用LR。因为样本数量太大会导致SVM运算很慢,此时 LR 更有优势,应该引入更多的特征,来保证 LR 的预测性能。
结论:
(1)在工业界的实际使用中,SVM 用的不多,速度慢并且效果也很难保证。LR使用好的特征,加上正则化项可以取得不错的效果,上线后响应速度也快;
(2)LR 适合大规模特征和数据量级的场景,百万以上的特征或训练数据,一般都建议使用 LR;
(3)LR 可以得到一个概率值,在排序的场景下(如广告系统中的CTR预估)比较常用。
问题:为什么GBDT中叶子结点的分数是通过最小化损失函数得到的,而不是直接取平均或者多数表决?
GBDT的基模型为回归决策树。
(1)当损失函数为平方损失时,经验损失最小值对应的预测值为训练样本标记值的平均值,举例如下:
假设特征空间的划分已确定,如图所示:
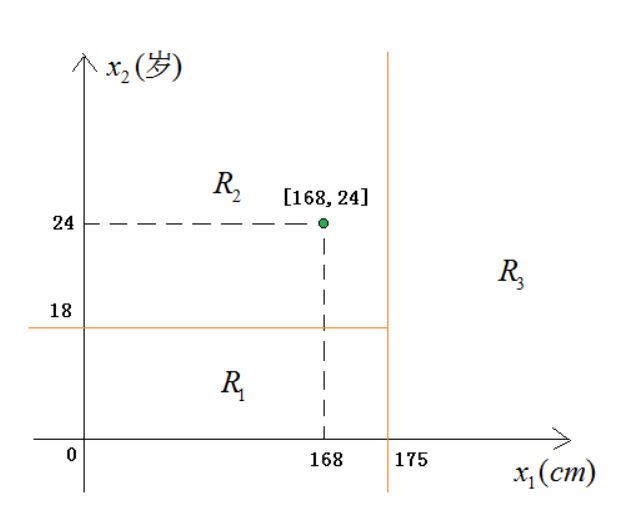
R2 单元对应的预测值 c2 应该尽量使其中的训练样本的预测损失最小。使用平方误差作为损失函数,假设 R2 中有三个训练样本 ,则预测值为 c2 产生的损失为:

令损失函数的导数为零,可以求出损失函数取最小值时对应的预测输出值:
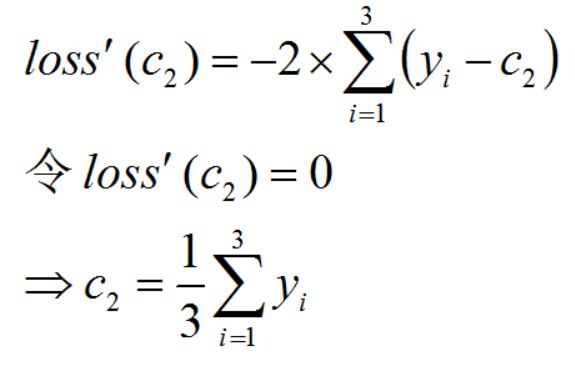
(2)当回归损失函数为更一般的情况时,也是类似的道理:求解损失函数最小时对应的预测值。
多数表决是分类问题预测值的求解方法,和GBDT没有关系。
问题:为什么xgboost不用后剪枝?
后剪枝计算代价太高了,合并一次叶节点就要计算一次测试集的表现,数据量大的情况下非常消耗时间,而且也并不是特别必要,因为这样很容易过拟合测试集。
问题:xgb和lgb在特征、数据并行上存在什么差异?
1)特征并行
lgbm特征并行的前提是每个worker留有一份完整的数据集,但是每个worker仅在特征子集上进行最佳切分点的寻找;worker之间需要相互通信,通过比对损失来确定最佳切分点;然后将这个最佳切分点的位置进行全局广播,每个worker进行切分即可。xgb的特征并行与lgbm的最大不同在于xgb每个worker节点中仅有部分的列数据,也就是垂直切分,每个worker寻找局部最佳切分点,worker之间相互通信,然后在具有最佳切分点的worker上进行节点分裂,再由这个节点广播一下被切分到左右节点的样本索引号,其他worker才能开始分裂。二者的区别就导致了lgbm中worker间通信成本明显降低,只需通信一个特征分裂点即可,而xgb中要广播样本索引。
2)数据并行
当数据量很大,特征相对较少时,可采用数据并行策略。lgbm中先对数据水平切分,每个worker上的数据先建立起局部的直方图,然后合并成全局的直方图,采用直方图相减的方式,先计算样本量少的节点的样本索引,然后直接相减得到另一子节点的样本索引,这个直方图算法使得worker间的通信成本降低一倍,因为只用通信以此样本量少的节点。xgb中的数据并行也是水平切分,然后单个worker建立局部直方图,再合并为全局,不同在于根据全局直方图进行各个worker上的节点分裂时会单独计算子节点的样本索引,因此效率贼慢,每个worker间的通信量也就变得很大。
3)投票并行(lgbm)
当数据量和维度都很大时,选用投票并行,该方法是数据并行的一个改进。数据并行中的合并直方图的代价相对较大,尤其是当特征维度很大时。大致思想是:每个worker首先会找到本地的一些优秀的特征,然后进行全局投票,根据投票结果,选择top的特征进行直方图的合并,再寻求全局的最优分割点。这个方法我没有找到很好的解释,因此,面试过程中答出前面两种我觉得就ok了吧。
帮助数千人成功上岸的《名企AI面试100题》书,电子版,限时免费送,评论区回复“100题”领取!
本书涵盖计算机语⾔基础、算法和⼤数据、机器学习、深度学习、应⽤⽅向 (CV、NLP、推荐 、⾦融风控)等五⼤章节,每⼀段代码、每⼀道题⽬的解析都经过了反复审查或review,但不排除可能仍有部分题⽬存在问题,如您发现,敬请通过官⽹/APP七月在线 - 国内领先的AI职业教育平台 (julyedu.com)对应的题⽬页⾯留⾔指出。
为了照顾⼤家去官⽹对应的题⽬页⾯参与讨论,故本⼿册各个章节的题⽬顺序和官⽹/APP题库内的题⽬展⽰顺序 保持⼀致。 只有100题,但实际笔试⾯试不⼀定局限于本100题,故更多烦请⼤家移步七⽉在线官⽹或 七⽉在线APP,上⾯还有近4000道名企AI笔试⾯试题等着⼤家,刷题愉快。
