机器学习面试必考面试题汇总—附解析
问题:xgboost对特征缺失敏感吗,对缺失值做了什么操作,存在什么问题
不敏感,可以自动处理,处理方式是将missing值分别加入左节点 右节点取分裂增益最大的节点将missing样本分裂进这个节点 。这种处理方式的问题在xgboost仅仅在特征的非缺失的值上进行分裂然后missing值直接放入其中一个节点,显然当缺失值很多的情况下,比如缺失80%,那么xgb分裂的时候仅仅在20%的特征值上分裂,这是非常容易过拟合的。
问题:简要说一下Lightgbm相对于xgboost的优缺点
优点:直方图算法—更高(效率)更快(速度)更低(内存占用)更泛化(分箱与之后的不精确分割也起到了一定防止过拟合的作用);
缺点:直方图较为粗糙,会损失一定精度,但是在gbm的框架下,基学习器的精度损失可以通过引入更多的tree来弥补。
问题:对比一下XGB和lightGBM在节点分裂时候的区别
xgb是level-wise,lgb是leaf-wise,level-wise指在树分裂的过程中,同一层的非叶子节点,只要继续分裂能够产生正的增益就继续分裂下去,而leaf-wise更苛刻一点,同一层的非叶子节点,仅仅选择分裂增益最大的叶子节点进行分裂。
篇幅有限,仅展示部分题目,本篇文章面试题来源于七月在线 - 智能时代在线职教平台,免费题库,近4000道名企AI笔试⾯试题等着⼤家,刷题愉快。
问题:xgb何时停止分裂?
人工设定的参数,max_depth,min_data_in_leaf等等,这类通过超参数形式限制树的复杂度的方法都会引发xgb的分裂的停止,也就是常说的预剪枝;人工不限制,自由生长的情况下,当分裂增益小于0则基学习器停止分裂
问题:RF和xgboost哪个对异常点更敏感
xgb明显敏感的多,当然对rf也是有一定影响的,rf的每棵数的生成是独立的,异常点数量不多的情况下异常点常常和正常样本中的某些样本合并在一个分支里。但是xgb不一样,异常样本的t-1轮的预测值和真实标签计算出来的负梯度会一直很大。
假设当到达某一轮的时候,所有正常样本的计算得到的负梯度都很小而异常样本的负梯度很大例如【0.0000001,0.0000001,0.0000001,0.0000001,0.0000001,10】,这个时候新树会可能会继续进行不正常的分裂为[0.0000001,0.0000001,0.0000001,0.0000001,0.0000001],[10],而这样的分裂是不合理的,因为异常值本身可能是因为某些人为失误导致的数据记录错误,或者异常样本完全是属于另外一种分布,此时强制要进行模型训练会导致模型的结果有偏从而发生过拟合。当然异常样本数量很少比如10个以内的时候而正常样本有100000000个其实基本没什么影响,但是如果占比较高的话是会产生影响的。
问题:xgb的预排序算法是怎么做的呢?
将原始特征进行排序之后以块的形式保存到内存中,在块里面保存排序后的特征值及对应样本的引用,以便于获取样本的一阶、二阶导数值,但意味着除了保存原始特征之外还要保存原始特征的排序结果,耗内存。
问题:XGB特征重要性程度是怎么判断的?
![]()
官网上给出的方案,total_gain就是特征带来的总的分裂增益,也就是我们常规意义上的分裂总增益,weight,被用来作为分裂节点的次数,也就是我们常规意义上的分裂总次数,gain=total_gain/weight,计算的是每一次分裂带来的平均增益,total_cover表示特征分裂的样本数,举个例子,假设初始样本有10000个,第一次分裂的时候使用了特征A,也就是特征A在这10000个样本上分裂,则此时的cover值为10000,假设根据特征A分裂出左枝的样本有1000个,右边有9000个,而在左枝特征B是最优特征根据这1000个样本进行分裂,则B当前的cover是1000,依次类推最后求和。而cover显然就是total_cover/weight,也就是平均每次分裂所“负责”的样本数。
问题:XGBoost和GBDT的区别有哪些?
1、算法层面:
(1)损失函数的二阶泰勒展开;
(2)树的正则化概念的引入,对叶节点数量和叶子节点输出进行了约束,方式是将二者形成的约束项加入损失函数中;
(3)二阶泰勒展开与树正则化推出了新的叶子节点输出的计算公式而不是原始gbdt那样的简单平均;
(4)a、对于基础学习器的改进,

分裂的时候自动根据是否产生正增益指导是否进行分裂,因为引入了正则项的概念,分裂的时候这个预剪枝更加严苛;
b、对于缺失值的处理,xgboost根据左右子节点的增益大小将缺失值分到增益大的节点中,而sklearn中的gbdt是无法处理缺失值的,因为sklearn中的gbdt是以sklearn中的cart为基学习器的,而sklearn中的cart也并没有实现对缺失值的处理功能。
(5)XGBoost 新增回归树的学习率设置在 (0,1)范围内,有利于学习数量更多的树,防止过拟合;而 GBDT 拟合负梯度,默认学习率为 1。
(6)引入了随机森林使用的列采样功能,便于降低过拟合;
(7)引入了许多近似直方图之类的优化算法来进一步提高树的训练速度与抗过拟合的能力,这个比较复杂,因为实现了很多种算法,后面单独写一篇来总结;
2、工程层面
(1)对每个特征进行分块(block)并排序(pre_sort),将排序后的结构保存在内存中,这样后续分裂的时候就不需要重复对特征进行排序然后计算最佳分裂点了,并且能够进行并行化计算.这个结构加速了split finding的过程,只需要在建树前排序一次,后面节点分裂时直接根据索引得到梯度信息。
(2)其它更复杂的工程优化处理:
https://zhuanlan.zhihu.com/p/75217528
问题:你有自己用过别的模型然后调参之类的吗?能说一下基本的调参流程吗?XGBoost知道吗,以XGBoost为例子说一下调参流程吧。
一般来说采用贝叶斯优化或者遗传算法等启发式的优化算法确定相对最佳参数(如果不熟悉的话用随机搜索也是可以的,或者网格搜索但是参数得到步长设置的很大,一步一步确定相对最优参数的区间),然后再根据实际的模型在验证集上的表现做一些微调,对于过拟合优先调整max_depth和树的数量,在实际使用过程中这两个参数对于模型的整体效果影响很大很明显。对于欠拟合,反着来就行了。
问题:为什么在 xgboost 可以在不选定损失函数具体形式的情况下, 仅仅依靠输入数据的值,一阶导数信息和二阶导数信息就可以进行叶子分裂优化计算?
首先需要说明的是,题目中所描述的仅仅是不选定损失函数的具体形式,而并不是说不需要损失函数,从 xgboost 节点分裂的计算公式,也就是下图中,可以看出g和h都是和损失函数有关的,所以不可能完全不考虑损失函数,损失函数的具体形式可以根据业务需求进行修改,可参见面试题:
https://www.julyedu.com/question/big/kp_id/41/ques_id/3097。
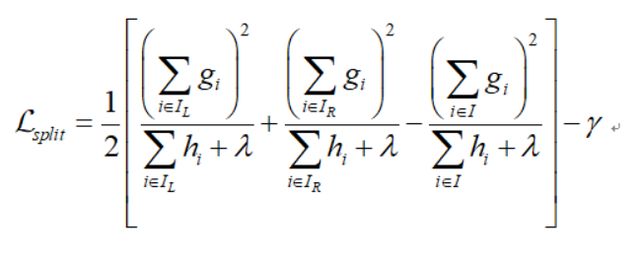
点击此处添加图片说明文字
↓↓↓免费送!福利!福利!福利↓↓↓
了解七月在线的的小伙伴应该知道2019年七月在线出了两本书《名企AI面试100题》和《名企AI面经100篇》,反响很好,助力数千人拿到dream offer。今年我们又整理出了两本书《2021年最新大厂AI面试题 Q2版》、《机器学习十大算法系列》、《2021年最新大厂AI面试题 Q3版》,七月在线学员拿到书后反响不错。为了让更多AI人受益,七仔现把电子版免费送给大家。
↓ ↓ ↓以下5本书,电子版免费送 ↓ ↓ ↓

刚出的《2021年最新大厂AI面试题 Q3版》还没来得及拍照:

《2021年最新大厂AI面试题 Q2版》、《2021年最新大厂AI面试题 Q3版》《机器学习十大算法系列》、《名企AI面试100题》及《名企AI面经100篇》无套路,免费取!
需要的小伙伴评论区发书名,看到后发你。
喜欢这样的福利请三连,三连,你的鼓励是七仔继续放福利,持续输出的不竭动力!