4 Flask mega-tutorial第4章 数据库 Database
如需转载请注明出处。
win10 64位、Python 3.6.3、Notepad++、Chrome 67.0.3396.99(正式版本)(64 位)
注:作者编写时间2017-12-27,linux、python 3.5.2
以下内容均是加入自己的理解与增删,以记录学习过程。不完全照搬作者Miguel Grinberg的博客,但版权属于作者,感谢他提供免费学习的资料。
| 传送门 | |||
|---|---|---|---|
| 00 开篇 | 01 Hello world | 02 模板 | 03 Web表单 |
| 04 数据库 | 05 用户登录 | 06 个人资料和头像 | 07 错误处理 |
| 08 关注 | 09 分页 | 10 支持QQ邮箱 | 11 美化页面 |
| 12 时间和日期 | 13 I18n和L10n 翻译成中文 zh-CN | 14 Ajax(百度翻译API | 15 更好的App结构(蓝图) |
| 16 全文搜索 | 17 部署到腾讯云Ubuntu | 18 部署到Heroku | 19 部署到Docker容器 |
| 20 JavaScript魔法 | 21 用户通知 | 22 后台工作(Redis) | 23 应用程序编程接口(API) |
Flask中的数据库
Flask本身并不支持 数据库。意味着可以自由选择适合应用程序的 数据库。在Python中对于数据库,有很多选择,并且很多带有Flask扩展,可很好地与Flask Web应用程序集成。数据库分为两大类:关系型、非关系型。后者称为NoSQL,即它们没有实现流行的关系查询语言SQL。关系型数据库适合具有结构化数据的应用程序,如用户列表、博客帖子等;而NoSQL数据库适合具有结构不太明确的。
在第3章中,展示了第一个Flask扩展 Flask-WTF。本章将再使用两个Flask扩展:Flask-SQLAlchemy、Flask-Migrate。
其中,Flask-SQLAlchemy为流行的SQLAlchemy包提供了一个Flask-friendly包装器,它是一个ORM。ORM允许应用程序使用高级实体(如类、对象、方法)而不是表和SQL来管理数据库,它的工作是将高级操作转换为数据库命令。
关于SQLAlchemy的好处是:它不是一个ORM,而是许多关系数据库。SQLAlchemy支持很多数据库引擎,包括流行的MySQL、PostgreSQL、SQLite。这非常强大,因为可以使用不需要服务器的简单SQLite数据库进行开发,然后在生产服务器上部署应用程序时,可以选择更强大的MySQL或PostgreSQL服务器,而无需改变应用程序。
PS:学到一个单词 alchemy 译为 炼金术、魔力,SQLAlchemy是个有魔力的东西。
在虚拟环境中安装Flask-SQLAlchemy:pip install flask-sqlalchemy,将会自动附带安装sqlalchemy包。
| 库名称 | 版本号 | 简要说明 |
|---|---|---|
| sqlalchemy | 1.2.10 | SQLAlchemy不是数据库,而是操作数据库的工具包、是对数据库进行操作的一种框架,简化了数据库管理的操作。也是一个强大的关系型数据库框架。 |
| flask-sqlalchemy | 2.3.2 | Flask-SQLAlchemy 也是一种数据库框架,是一个Flask扩展,它包装了SQLAlchemy,支持多种数据库后台。无须关心SQL处理细节,一个基本关系对应一个类,而一个实体对应类的实例对象,通过调用方法操作数据库。 |
(venv) D:\microblog>pip install flask-sqlalchemy
Collecting flask-sqlalchemy
Using cached https://files.pythonhosted.org/packages/a1/44/294fb7f6bf49cc7224417cd0637018db9fee0729b4fe166e43e2bbb1f1c8/Flask_SQLAlchemy-2.3.2-py2.py3-none-any.whl
Requirement already satisfied: Flask>=0.10 in d:\microblog\venv\lib\site-packages (from flask-sqlalchemy)
Collecting SQLAlchemy>=0.8.0 (from flask-sqlalchemy)
Downloading https://files.pythonhosted.org/packages/8a/c2/29491103fd971f3988e90ee3a77bb58bad2ae2acd6e8ea30a6d1432c33a3/SQLAlchemy-1.2.10.tar.gz (5.6MB)
100% |████████████████████████████████| 5.6MB 208kB/s
Requirement already satisfied: Werkzeug>=0.14 in d:\microblog\venv\lib\site-packages (from Flask>=0.10->flask-sqlalchemy)
Requirement already satisfied: click>=5.1 in d:\microblog\venv\lib\site-packages (from Flask>=0.10->flask-sqlalchemy)
Requirement already satisfied: Jinja2>=2.10 in d:\microblog\venv\lib\site-packages (from Flask>=0.10->flask-sqlalchemy)
Requirement already satisfied: itsdangerous>=0.24 in d:\microblog\venv\lib\site-packages (from Flask>=0.10->flask-sqlalchemy)
Requirement already satisfied: MarkupSafe>=0.23 in d:\microblog\venv\lib\site-packages (from Jinja2>=2.10->Flask>=0.10->flask-sqlalchemy)
Installing collected packages: SQLAlchemy, flask-sqlalchemy
Running setup.py install for SQLAlchemy ... done
Successfully installed SQLAlchemy-1.2.10 flask-sqlalchemy-2.3.2
更多关于Flask-SQLAlchemy、SQLAlchemy以及Flask使用数据库的操作可查看博文。
数据库迁移
大多数数据库教程都涵盖数据库的创建、使用,但没有充分解决在应用程序在需要 更改或增长时对现有数据库进行更新的问题。这是一个难点,因为关系数据库是以结构化数据为中心,在结构发生更改时,数据库中 已有的数据需要 迁移到 修改后的结构中。Flask-Migrate扩展是Alembic(PS:Alembic是SQLAlchemy作者编写的数据库迁移工具)的Flask包装器,是SQLAlchemy的数据库迁移框架。虽然使用数据库迁移为启动数据库添加了一些工作,但这是一个很小的代价,将为未来对数据库进行更改提供强大方法。
在虚拟环境中安装Flask-Migrate:pip install flask-migrate,将会自动附带安装Mako、alembic、python-dateutil、python-editor、six。
| 库名称 | 版本号 | 简要说明 |
|---|---|---|
| Flask-Migrate | 2.2.1 | Flask的数据库迁移扩展 |
| alembic | 1.0.0 | SQLAlchemy作者编写的数据库迁移工具 |
| Mako | 1.0.7 | 是一种嵌入式Python(即Python服务器页面)语言,提供一种熟悉的非XML语法 |
| python-dateutil | 2.7.3 | 对datetime模块的强大扩展 |
| python-editor | 1.0.3 | 以编程方式打开编辑器,捕获结果 |
| six | 1.11.0 | Python 2.x和3.x兼容库,目的是编写兼容两个Python版本的Python代码 |
C:\Users\Administrator>d:
D:\>cd D:\microblog\venv\Scripts
D:\microblog\venv\Scripts>activate
(venv) D:\microblog\venv\Scripts>cd D:\microblog
(venv) D:\microblog>pip install flask-migrate
Collecting flask-migrate
Using cached https://files.pythonhosted.org/packages/59/97/f681c9e43d2e2ace4881fa588d847cc25f47cc98f7400e237805d20d6f79/Flask_Migrate-2.2.1-py2.py3-none-any.whl
Requirement already satisfied: Flask-SQLAlchemy>=1.0 in d:\microblog\venv\lib\site-packages (from flask-migrate)
Collecting alembic>=0.7 (from flask-migrate)
Downloading https://files.pythonhosted.org/packages/96/c7/a4129db460c3e0ea8fea0c9eb5de6680d38ea6b6dcffcb88898ae42e170a/alembic-1.0.0-py2.py3-none-any.whl (158kB)
100% |████████████████████████████████| 163kB 246kB/s
Requirement already satisfied: Flask>=0.9 in d:\microblog\venv\lib\site-packages (from flask-migrate)
Requirement already satisfied: SQLAlchemy>=0.8.0 in d:\microblog\venv\lib\site-packages (from Flask-SQLAlchemy>=1.0->flask-migrate)
Collecting python-dateutil (from alembic>=0.7->flask-migrate)
Using cached https://files.pythonhosted.org/packages/cf/f5/af2b09c957ace60dcfac112b669c45c8c97e32f94aa8b56da4c6d1682825/python_dateutil-2.7.3-py2.py3-none-any.whl
Collecting Mako (from alembic>=0.7->flask-migrate)
Using cached https://files.pythonhosted.org/packages/eb/f3/67579bb486517c0d49547f9697e36582cd19dafb5df9e687ed8e22de57fa/Mako-1.0.7.tar.gz
Collecting python-editor>=0.3 (from alembic>=0.7->flask-migrate)
Using cached https://files.pythonhosted.org/packages/65/1e/adf6e000ea5dc909aa420352d6ba37f16434c8a3c2fa030445411a1ed545/python-editor-1.0.3.tar.gz
Requirement already satisfied: itsdangerous>=0.24 in d:\microblog\venv\lib\site-packages (from Flask>=0.9->flask-migrate)
Requirement already satisfied: click>=5.1 in d:\microblog\venv\lib\site-packages (from Flask>=0.9->flask-migrate)
Requirement already satisfied: Jinja2>=2.10 in d:\microblog\venv\lib\site-packages (from Flask>=0.9->flask-migrate)
Requirement already satisfied: Werkzeug>=0.14 in d:\microblog\venv\lib\site-packages (from Flask>=0.9->flask-migrate)
Collecting six>=1.5 (from python-dateutil->alembic>=0.7->flask-migrate)
Using cached https://files.pythonhosted.org/packages/67/4b/141a581104b1f6397bfa78ac9d43d8ad29a7ca43ea90a2d863fe3056e86a/six-1.11.0-py2.py3-none-any.whl
Requirement already satisfied: MarkupSafe>=0.9.2 in d:\microblog\venv\lib\site-packages (from Mako->alembic>=0.7->flask-migrate)
Installing collected packages: six, python-dateutil, Mako, python-editor, alembic, flask-migrate
Running setup.py install for Mako ... done
Running setup.py install for python-editor ... done
Successfully installed Mako-1.0.7 alembic-1.0.0 flask-migrate-2.2.1 python-dateutil-2.7.3 python-editor-1.0.3 six-1.11.0
Flask-SQLAlchemy配置
在 开发过程中,这将使用 SQLite数据库,它是开发小型应用程序的方便选择,有时甚至不是那么小,因为每个数据库都存储在磁盘上的单个文件中,并且不需要运行像MySQL、PostgreSQL的数据库服务器。添加两个配置项到config.py中:
microblog/config.py:Flask-SQLAlchemy配置
import os
basedir = os.path.abspath(os.path.dirname(__file__))#获取当前.py文件的绝对路径
class Config:
SECRET_KEY = os.environ.get('SECRET_KEY') or 'you will never guess'
SQLALCHEMY_DATABASE_URI = os.environ.get('DATABASE_URI') or 'sqlite:///' + os.path.join(basedir, 'app.db')
SQLALCHEMY_TRACK_MODIFICATIONS = False
Flask-SQLAlchemy扩展从SQLALCHEMY_DATABASE_URI变量中获取应用程序数据库的位置。在第3章中已学过,从环境变量中设置配置是一种很好的做法,并在环境中未定义变量时提供回退值。在这种情况下,将从DATABASE_URL环境变量中获取数据库URL;如果没有定义,将在应用程序主目录下配置一个名为app.db的数据库,该数据库存储在basedir变量中。
SQLALCHEMY_TRACK_MODIFICATIONS配置选项设置为False,意为禁用我不需要的Flask-SQLAlchemy的该特征,即追踪对象的修改并且发送信号。
更多的Flask-SQLAlchemy配置选项可参考 官网。
数据库将在应用程序中通过数据库实例表示。数据库迁移引擎也将有一个实例。这些是需要在应用程序之后需要创建的对象(即在app/__init__.py)。
app/__init__.py:初始化Flask-SQLAlchemy和Flask-Migrate,更新代码
from flask import Flask
from config import Config#从config模块导入Config类
from flask_sqlalchemy import SQLAlchemy#从包中导入类
from flask_migrate import Migrate
app = Flask(__name__)
app.config.from_object(Config)
db = SQLAlchemy(app)#数据库对象
migrate = Migrate(app, db)#迁移引擎对象
from app import routes,models#导入一个新模块models,它将定义数据库的结构,目前为止尚未编写
数据库模型
将存储在 数据库中的数据由一组 类来表示,通常称之为 数据库模型。 SQLAlchemy中的 ORM层将做 从这些类创建的对象 映射到 适当的数据库表的行所需的转换。创建代表用户的模型,下图表示在users表中使用的数据。
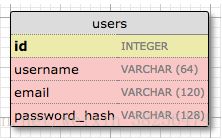
id字段通常在所有模型中,用作主键,将为数据库中的每个用户分配一个唯一的id值,该值存储在id字段中。大多情况下,主键由数据库自动分配,因此只需提供id字段并标记为主键。
username、email、password_hash字段都被定义为字符串(VARCHAR),并指定最大长度。其中,password_hash字段值得关注,我们要确保应用程序采用安全性最佳实践,因此不能将用户密码存储在数据库中。不直接写密码,而是密码哈希,大大提高安全性。
现在,已知道想要的用户表,将其转换为新模板models中的代码:
app/models.py:用户数据库模型
from app import db
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), index=True, unique=True)
email = db.Column(db.String(120), index=True, unique=True)
password_hash = db.Column(db.String(128))
def __repr__(self):
return ''.format(self.username)
上述创建的User类继承自db.Model,它是Flask-SQLAlchemy所有模型的基类。这个类定义了几个字段作为类变量,这些字段是db.Column类创建的实例,它将字段类型作为参数、及其他可选参数,例 指定哪些字段是唯一的、索引的,这些对数据库搜索是非常重要的、有效的。
__repr__ 方法用于告知Python如何打印此类的对象,这对调试很有用。在下面的Python解释会话中可看到__repr__()方法的实际应用:
>>> from app.models import User
>>> u = User(username='susan', email='[email protected]')
>>> u
创建迁移存储库
上一节中创建的 模型类定义了这个应用程序的 初始数据库结构(或模式schema)。但随着应用程序的不断发展,将可能需要更改结构、添加新内容,还看修改或删除项目。 Alembic(Flask-Migrate使用的迁移框架)将 以不需要从头开始重新创建数据库的方式做到这些模式变化。为了完成这个看似困难且麻烦的任务,Alembic维护了一个迁移存储库,它是一个存储其迁移脚本的目录。每次对数据库模式进行更改时,都会将迁移脚本添加到存储库,其中包含更改的详细信息。若要迁移运用于数据库,这些迁移脚本将按创建顺序执行。
Flask-Migrate通过flask命令公开其命令。运行程序时的flask run是Flask原生子命令。flask db 子命令由Flask-Migrate添加到管理有关数据库迁移的一切。因此,通过运行flask db init 命令为微博客创建迁移存储库:
(venv) D:\microblog>flask db init
Creating directory D:\microblog\migrations ... done
Creating directory D:\microblog\migrations\versions ... done
Generating D:\microblog\migrations\alembic.ini ... done
Generating D:\microblog\migrations\env.py ... done
Generating D:\microblog\migrations\README ... done
Generating D:\microblog\migrations\script.py.mako ... done
Please edit configuration/connection/logging settings in 'D:\\microblog\\migrations\\alembic.ini' before proceeding.
运行完该命令后,项目文件夹microblog下新增migrations目录,它就是迁移目录,其中包含一些文件、一个版本子目录。从此刻开始,所有这些文件都应视为项目的一部分,且应该添加到源代码管理中。
flask命令是依赖于FLASK_APP环境变量来知道Flask应用程序的位置。对于这个应用程序,正是在第1章设置的FLASK_APP = microblog.py。
第1次数据库迁移
有了 迁移存储库,就可创建第一个数据库迁移,其中包括映射到User数据库模型的 users表。有两种方法可创建数据库迁移:手动、自动。为了自动生成迁移, Alembic将数据库模型定义的数据库模式 与数据库中当前使用的实际数据库模式进行比较。然后,它会使迁移脚本填充必要的更改,以使数据库模式与应用程序模型匹配。在当前情况下,由于此前没有数据库,自动迁移会将整个`User模型`添加到迁移脚本中。`flask db migrate`子命令生成这些自动迁移:(venv) D:\microblog>flask db migrate -m "users table"
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'user'
INFO [alembic.autogenerate.compare] Detected added index 'ix_user_email' on '['email']'
INFO [alembic.autogenerate.compare] Detected added index 'ix_user_username' on '['username']'
Generating D:\microblog\migrations\versions\1f1d69541c8c_users_table.py ... done
flask db migrate -m "users table"将输出Alembic在迁移中包含的内容。前两行是信息性的,通常可忽略。接着,说检测到一个用户表、两个索引。最后,它告知编写的迁移脚本的位置。这个1f1d69541c8c_users_table.py文件(位于migrations\versions目录下)是用于迁移自动生成的唯一代码。使用-m选项提供注释的可选的,它可为迁移添加一个简短的描述性文本。
此时,microblog目录下将新增app.db文件(即SQLite数据库)、microblog\migrations\versions下1f1d69541c8c_users_table.py文件。生成的这个迁移脚本现已是项目的一部分,需要合并到源代码管理中。它里头有两个函数:upgrade()用于迁移;downgrade()用于删除。这允许Alembic使用降级路径将数据库迁移到历史记录的任何位置,甚至迁移到旧版本。
flask db migrate命令不对数据库进行任何更改,它只生成迁移脚本。要将更改运用于数据库,必须使用flask db upgrade命令。
因为这个应用程序使用SQLite,所以upgrade命令将检测数据库不存在,并将创建它。如果使用的是MySQL或PostgreSQL等数据库服务器,得在运行upgrade命令之前在数据库服务器创建数据库。
(venv) D:\microblog>flask db upgrade
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> 1f1d69541c8c, users table
此时,microblog目录下的app.db将更新。
PS:默认情况下,Flask-SQLAlchemy对数据库表使用“snake case”命名约定。对于上述User模型,在数据库中相应的表将被命名为`user`。对于AddressAndPhone模型类,将会被命名为address_and_phone。如果想选择自己的表名,可在模型类中添加一个名为__tablename__的属性,并将其设置为一个字符串。
数据库升级和降级工作流程
现在这个Flask应用程序还处于起步阶段,但讨论未来的数据库迁移策略并无坏处。如应用程序在开发机器上,而且还有一个副本部署到线上和正在使用的生产服务器上。假设应用程序的下个版本需对模型进行更改,例如添加新表。如果没有迁移,则需要弄清楚如何在开发机器和再次在服务器上去改变数据库模式,这可能需要做很多的工作。
但是,通过数据库迁移的支持,在修改了应用程序的模型后,将会生成一个新的迁移脚本(flask db migrate),我们可能会检查它以确保自动生成做正确的事,然后将改变运用于开发数据库(flask db upgrade)。我们将迁移脚本添加到源代码管理、并提交它。
当准备将新版本的应用程序发布到生产服务器时,需做的是获取应用程序的更新版本(包括新的迁移脚本)并运行flask db upgrade。Alembic将检测到生产数据库未更新到最新版本的模式,并运行在先前版本之后创建的所有新迁移脚本。
flask db downgrade命令,可撤销上次迁移。虽然我们不太可能在生产系统上需要它,但可能在开发过程非常有用。例:已生成迁移脚本并将其运用,但发现所做的更改并非所需要的。这种情况下,可降级数据库,删除迁移脚本,然后生成一个新的替换它。
数据库关系
关系数据库善于存储数据项之间的关系。考虑用户撰写博客文章的情况,用户将在`users表`中有一条记录,该帖子在`posts表`中也将有一条记录。 记录撰写特定帖子的人最有效的方法是链接两个相关记录。一旦建立了用户、帖子之间的链接,数据库就可以回答有关此链接的查询。最简单的一个查询:当有博客帖子并且知道需要知道用户写了什么。更复杂的查询与此相反:可能想知道某用户所写的所有帖子。Flask-SQLAlchemy将帮助处理这两种类型的查询。
扩展数据库以存储博客文章,并查看它们的关系。以下是新posts表的结构:

这个posts表有id、body、timestamp字段。还有一个额外的字段user_id,将帖子连接到作者。所有用户都有一个主键id,是唯一的。将博客帖子链接到所创作它的用户的方法是添加对用户的引用id,这正是user_id字段,称之为 外键。上述图中显示了作为外键的字段 user_id与id字段之间的链接,这种关系称之为一对多,即一个用户可写多篇帖子。
更新models模块,app/models.py:帖子的数据库表和关系
from app import db
from datetime import datetime
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), index=True, unique=True)
email = db.Column(db.String(120), index=True, unique=True)
password_hash = db.Column(db.String(128))
posts = db.relationship('Post', backref='author', lazy='danamic')
def __repr__(self):
return ''.format(self.username)
class Post(db.Model):
id = db.Column(db.Integer, primary_key=True)
body = db.Column(db.String(140))
timestamp = db.Column(db.DateTime, index=True, default=datetime.utcnow)
user_id = db.Column(db.Integer, db.ForeignKey('user.id'))
def __repr__(self):
return ' 新建的Post类表示用户撰写的博客文章。timestamp字段被 编入索引,比如按时间顺序检索帖子,这将非常有用;还添加了default参数,并传给它datetime.utcnow函数(得到的是格林威治时间 (GMT),即北京时间减8个时区的时间),在此,要注意一点,即将函数作为默认参数传递时,SQLAlchemy会将该字段设置为调用该函数的值(utcnow后没有括号()),传递的是函数本身,而不是调用它的结果。通常,在服务器应用程序中使用UTC日期和时间,这可确保使用统一的时间戳,无论用户立于何处,这些时间戳都可在显示时转换为用户的本地时间。
user_id字段已作为一个外键初始化了,这表明它引用了users表中的id值。在这个引用中user表示模型中数据库表的名称。这有一个不幸的不一致:在某些情况下,如db.relationship()调用中,模型由模型类引用,模型类通常以大写字符开头;而在其他情况下,如db.ForeignKey()中,模型由数据库表名称给出,SQLAlchemy自动使用小写字符,对于多字模型名称将使用“snake case”命名约定。
User类有一个新的posts字段,是用db.relationship初始化的。这不是一个真正的数据库字段,而是用户、帖子之间关系的高级视图,因此它不在数据库图中。对于一对多关系,db.relationship字段通常在“一”侧定义,并且用作访问“多”的便捷方式。因此,举例,如果有一个用户存储 u,表达式u.posts将运行一个数据库查询,返回该用户的所有帖子。db.relationship的第一个参数 表示关系“多”的模型类。如果模型稍后在模块中定义,则此参数可作为带有类名的字符串提供。第二个参数backref定义将添加到“多”类的对象的字段的名称,该类指向“一”对象。这将添加一个post.author表达式,它将返回给定帖子的用户。第三个参数lazy定义了如何发布对关系的数据库查询,这将在稍后讨论。
由于我们对应用程序的模型进行了更新,因此需要生成新的数据库迁移:
(venv) D:\microblog>flask db migrate -m "posts table"
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'post'
INFO [alembic.autogenerate.compare] Detected added index 'ix_post_timestamp' on '['timestamp']'
Generating D:\microblog\migrations\versions\c0139b2ef594_posts_table.py ... done
迁移需要应用于数据库:
(venv) D:\microblog>flask db upgrade
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running upgrade 1f1d69541c8c -> c0139b2ef594, posts table
Show Time
上述所有内容均是讲述 如何定义数据库,但还未告知如何运作的。由于应用程序还没有任何数据库逻辑,接下来将在 Python解释器中使用数据库来熟悉它。在激活虚拟环境的前提下,启动Python解释器,进入Python提示后,导入数据库实例、模型:(venv) D:\microblog>python
Python 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 18:11:49) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from app import db
>>> from app.models import User, Post
首先,创建一个新用户:
>>> u = User(username='john', email='[email protected]')
>>> db.session.add(u)
>>> db.session.commit()
对数据库的更改在会话session的上下文中完成,即作为db.session()访问。可以在会话session中累积多次更改,一旦所有的更改注册了,就可以用db.session.commit()发送一个信号,它以原子方式写入所有更改。
如果在会话session期间任何时间有一个错误,都可调用db.session.rollback()中止会话session并删除存储在其中的任何更改。
请注意的是:更改只会在db.session.commit()调用时写入数据库。会话session保证了数据库永远不会处于不一致状态。
添加另一个用户:
>>> u = User(username='susan', email='[email protected]')
>>> db.session.add(u)
>>> db.session.commit()
数据库可回答一个返回所有用户的查询:
>>> users = User.query.all()
>>> users
[, ]
>>> for u in users:
... print(u.id, u.username)
...
1 john
2 susan
所有模型都有一个query属性,它是运行数据库查询的入口点。最基本的查询是返回该类的所有元素,它被适当地命名为all()。上述例中:这两个用户被添加时,id字段会被自动地设置为1和2。
如果知道用户id,还可通过如下方式检索该用户:
>>> u = User.query.get(1)
>>> u
为id 为1的用户添加一篇博文:
>>> u = User.query.get(1)
>>> p = Post(body='my first post come!', author=u)
>>> db.session.add(p)
>>> db.session.commit()
不需要为timestamp字段设置值,因为它有默认值(模型中定义了)。对于user_id字段,User类向用户添加posts字段中db.relationship还把author属性给了帖子。这里使用author虚拟字段将作者分配给帖子,而不是必须处理用户ID。SQLAlchemy在这方面做的很好,它提供了对关系、外键的高级抽象。
再看几个数据库查询:
>>> #取得一个用户写的所有帖子
...
>>> u = User.query.get(1)
>>> u
>>> posts = u.posts.all()
>>> posts
[>> #同样,看看没有写帖子的用户
...
>>> u = User.query.get(2)
>>> u
>>> u.posts.all()
[]
>>> #对所有帖子打印其作者、内容
...
>>> posts = Post.query.all()
>>> for p in posts:
... print(p.id, p.author.username, p.body)
...
1 john my first post come!
>>> #以反字母顺序打印所有用户
...
>>> User.query.order_by(User.username.desc()).all()
[, ]
Flask_SQLAlchemy文档可学习到更多查询数据库的知识。
删除上述创建的测试用户、帖子,以便数据库干净,并为下一章做准备:
>>> users = User.query.all()
>>> for u in users:
... db.session.delete(u)
...
>>> posts = Post.query.all()
>>> for p in posts:
... db.session.delete(p)
...
>>> db.session.commit()
Shell上下文
在上一节开启Python解释器后,做的第一件事是运行一些导入:>>> from app import db
>>> from app.models import User, Post
在处理应用程序时,经常需要在Python shell中进行测试,如果每次都要重复上述导入,将变得极其乏味、麻烦。flask shell命令是flask命令伞中另一个非常有用的工具。shell命令是在run之后,Flask执行的第二个核心命令。这个命令的目的是在应用程序的上下文中启动Python解释器。以下示例助理解:
(venv) d:\microblog>python
Python 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 18:11:49) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> app
Traceback (most recent call last):
File "", line 1, in
NameError: name 'app' is not defined
>>>exit()
(venv) d:\microblog>flask shell
Python 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 18:11:49) [MSC v.1900 64 bit (AMD64)] on win32
App: app [production]
Instance: d:\microblog\instance
>>> app
使用常规解释器会话(python)时,app符号除非显示导入了,否则它是不可知的,会报错!但是使用flask shell命令,它预先导入应用程序实例。flask shell的好处是:不是它预先导入app,而是我们可配置一个“shell context”(即shell上下文,它是一个预先导入的其他符号的列表)。
在模块microblog.py添加给函数,它创建了一个shell 上下文,将数据库实例、模型添加到shell会话中:
from app import app, db
from app.models import User, Post
@app.shell_context_processor
def make_shell_context():
return {'db': db, 'User': User, 'Post': Post}
上述app.shell_context_processor装饰器注册了一个作为shell 上下文功能的函数。当运行flask shell命令时,它将调用此函数并在shell会话中注册它返回的项。函数返回字典而不是列表的原因是:对于每个项目,我们还须提供一个名称,在这个名称下,它将在shell中被引用,由字典的键给出。
由于上述更新了microblog.py文件,则必须重新设置FLASK_APP环境变量,否则会报错NameError。添加了shell 上下文处理器功能后,我们可以方便地使用数据库实体,而无需导入它们:
(venv) d:\microblog>set FLASK_APP=microblog.py
(venv) d:\microblog>flask shell
Python 3.6.3 (v3.6.3:2c5fed8, Oct 3 2017, 18:11:49) [MSC v.1900 64 bit (AMD64)] on win32
App: app [production]
Instance: d:\microblog\instance
>>> db
>>> User
>>> Post
目前为止,项目结构:
microblog/
app/
templates/
base.html
index.html
login.html
__init__.py
forms.py
models.py
routes.py
migrations/
venv/
app.db
config.py
microblog.py
参考:
作者博客
如需转载请注明出处。