MATLAB_神经网络做数据拟合预测
目录
- 简介
- 各种网络模型分析及matlab实现
-
- BP
- RBF
- GRNN
- 分析比较
简介
1.本次我们将以25M晶振的温度频偏曲线数据为基础,进行神经网络的搭建学习,最后消除绝大部分频差。见下图,蓝色区域是有可能达到的偏差,我们通过学习来给一个相应的调整量使其尽量回到0频偏。本次仿真的输入有两个特征:温度和频偏;输出的为调整量。

以下为采集到的大样本数据:%输入训练向量p,注意必须使p,t矩正列相等其中每列表示一个样本,行数表示总样本数p=[-20 -19.5 -19 -18.5 -18 -17.5 -17 -16.5 -16 -15.5 -15 -14.5 -14 -13.5 -13 -12.5 -12 -11.5 -11 -10.5 -10 -9.5 -9 -8.5 -8 -7.5 -7 -6.5 -6 -5.5 -5 -4.5 -4 -3.5 -3 -2.5 -2 -1.5 -1 -0.5 0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 5.5 6 6.5 7 7.5 8 8.5 9 9.5 10 10.5 11 11.5 12 12.5 13 13.5 14 14.5 15 15.5 16 16.5 17 17.5 18 18.5 19 19.5 20 20.5 21 21.5 22 22.5 23 23.5 24 24.5 25 25.5 26 26.5 27 27.5 28 28.5 29 29.5 30 30.5 31 31.5 32 32.5 33 33.5 34 34.5 35 35.5 36 36.5 37 37.5 38 38.5 39 39.5 40 40.5 41 41.5 42 42.5 43 43.5 44 44.5 45 45.5 46 46.5 47 47.5 48 48.5 49 49.5 50 50.5 51 51.5 52 52.5 53 53.5 54 54.5 55 55.5 56 56.5 57 57.5 58 58.5 59 59.5 60 60.5 61 61.5 62 62.5 63 63.5 64 64.5 65 65.5 66 66.5 67 67.5 68 68.5 69 69.5 70; -5 -4.9 -4.5 -4 -3.5 -3 -2.9 -3.5 -3 -2.9 -1 -1.5 -1.2 -1.2 -1.2 1 0 0.3 0.3 1 2 1.3 1.9 2 2.2 2.5 2.5 2.5 2.7 2.7 3 4 3.2 3.3 3.5 3.6 3 3.5 3.3 3.2 3.1 4 3 3.1 3.1 3 3 2.9 2.7 2.6 2.5 3 4 3.8 3.7 3.6 2.5 2.5 2.3 2.1 2 2 3 2.8 2.6 2 1 2.5 2.4 2.3 2.3 1.5 2.2 2.5 2.3 2 1 1 0.8 0.6 0.5 0.5 0.5 0.4 0.3 0.2 0.2 0.2 0.1 0.1 0.1 0 -0.2 -0.2 -0.3 -0.3 -0.3 -0.4 -0.5 -0.7 -0.8 -1 -1.1 -1.2 -1.3 -1.4 -1.5 -1.4 -1.5 -1.4 -1.4 -1.5 -1.6 -1.6 -1.7 -1.9 -2 -2 -2.1 -2.3 -2.5 -2.5 -2.6 -2.7 -2.8 -2.9 -3 -3 -3.1 -3.1 -3.2 -3.3 -3.3 -3.5 -3.6 -3.9 -4 -4.1 -4.2 -4.1 -4.2 -4.1 -4.3 -4.5 -4.5 -4.6 -4.7 -4.8 -4.8 -4.9 -5 -5 -4.9 -4.8 -4.8 -4.7 -4.3 -4 -3 -3.2 -3.4 -3.5 -3.4 -3.2 -3.5 -2.8 -2.6 -2.1 -1.5 -1 -0.5 0.1 0.5 0.9 1.2 1.3 1.5 1.8 2 2.3 3]; %训练目标向量t t = [5 4.9 4.5 4 3.5 3 2.9 3.5 3 2.9 1 1.5 1.2 1.2 1.2 -1 0 -0.3 -0.3 -1 -2 -1.3 -1.9 -2 -2.2 -2.5 -2.5 -2.5 -2.7 -2.7 -3 -4 -3.2 -3.3 -3.5 -3.6 -3 -3.5 -3.3 -3.2 -3.1 -4 -3 -3.1 -3.1 -3 -3 -2.9 -2.7 -2.6 -2.5 -3 -4 -3.8 -3.7 -3.6 -2.5 -2.5 -2.3 -2.1 -2 -2 -3 -2.8 -2.6 -2 1 -2.5 -2.4 -2.3 -2.3 -1.5 -2.2 -2.5 -2.3 -2 -1 -1 -0.8 -0.6 -0.5 -0.5 -0.5 -0.4 -0.3 -0.2 -0.2 -0.2 -0.1 -0.1 -0.1 0 0.2 0.2 0.3 0.3 0.3 0.4 0.5 0.7 0.8 1 1.1 1.2 1.3 1.4 1.5 1.4 1.5 1.4 1.4 1.5 1.6 1.6 1.7 1.9 2 2 2.1 2.3 2.5 2.5 2.6 2.7 2.8 2.9 3 3 3.1 3.1 3.2 3.3 3.3 3.5 3.6 3.9 4 4.1 4.2 4.1 4.2 4.1 4.3 4.5 4.5 4.6 4.7 4.8 4.8 4.9 5 5 4.9 4.8 4.8 4.7 4.3 4 3 3.2 3.4 3.5 3.4 3.2 3.5 2.8 2.6 2.1 1.5 1 0.5 -0.1 -0.5 -0.9 -1.2 -1.3 -1.5 -1.8 -2 -2.3 -3];
以下为采集到的小样本数据:%输入训练向量p,注意必须使p,t矩正列相等其中每列表示一个样本,行数表示总样本数 p=[-20 -17.5 -15 -12.5 -10 -7.5 -5 -2.5 0 2.5 5 7.5 10 12.5 15 17.5 20 22.5 25 27.5 30 32.5 35 37.5 40 42.5 45 47.5 50 ; -5 -3 -1 1 2 2.5 4 3 4 3 3 2.5 2 1 1.5 1 0.5 0.2 0 -0.3 -1 -1.5 -1.5 -2 -2.5 -3 -3.3 -4 -4.1]; %训练目标向量t t=[ 5 3 1 -1 -2 -2.5 -4 -3 -4 -3 -3 -2.5 -2 -1 -1.5 -1 -0.5 -0.2 0 0.3 1 1.5 1.5 2 2.5 3 3.3 4 4.1];
以下为测试样本数据:%测试样本P_test P_test=[-20 -17.5 -15 -12.5 -10 -7.5 -5 -2.5 0 2.5 5 7.5 10 12.5 15 17.5 20 22.5 25 27.5 30 32.5 35 37.5 40 42.5 45 47.5 50 ; -4 -2 -0.5 1 2 2.5 4 3 4 3 3 2.5 2 1 1.5 1 0.5 0.2 0 -0.3 -1 -1.5 -1.5 -2 -2.5 -3 -3.3 -4 -4.1]; %测试目标t1 t1=[4 2 0.5 -1 -2 -2.5 -4 -3 -4 -3 -3 -2.5 -2 -1 -1.5 -1 -0.5 -0.2 0 0.3 1 1.5 1.5 2 2.5 3 3.3 4 4.1];
各种网络模型分析及matlab实现
BP
在此之前,我们先看看什么是归一化?
——将数据映射到[0, 1]或[-1, 1]区间或其他的区间。
为什么要归一化?
-
输入数据的单位不一样,有些数据的范围可能特别大,导致的结果是神经网络收敛慢、训练时间长。
-
数据范围大的输入在模式分类中的作用可能会偏大,而数据范围小的输入作用就可能会偏小。(防止数据湮灭等现象)
-
由于神经网络输出层的激活函数的值域是有限制的,因此需要将网络训练的目标数据映射到激活函数的值域。例如神经网络的输出层若采用S形激活 函数,由于S形函数的值域限制在(0,1),也就是说神经网络的输出只能限制在(0,1),所以训练数据的输出就要归一化到[0,1]区间。
-
S形激活函数在(0,1)区间以外区域很平缓,区分度太小。例如S形函数f(X)在参数a=1时,f(100)与f(5)只相差0.0067。这样数据的差异就会失去意义!
-
归一化的算法:
y = ( x - min )/( max - min ) —— 【0,1】
y = 2 * ( x - min ) / ( max - min ) - 1 —— 【-1,1】
接下来我们介绍BP网络:
BP神经网络是一种多层的前馈神经网络,其主要的特点是:信号是前向传播的,而误差是反向传播的。下图为BP网络结构图:

具体来说,对于如下的只含一个隐层的神经网络模型:BP神经网络的过程主要分为两个阶段,
第一阶段是信号的前向传播,从输入层经过隐含层,最后到达输出层;
第二阶段是误差的反向传播,从输出层到隐含层,最后到输入层,依次调节隐含层到输出层的权重和偏置,输入层到隐含层的权重和偏置。
本实验的隐含层采用sigmod传输函数,输出层采用线性函数,初始权值一般为随机给定的。
训练一个BP神经网络的全流程:
1.初始化神经网络,对每个神经元的w和b赋予随机值;
2.输入训练样本集合,对于每个样本,将输入给到神经网络的输入层,进行一次正向传播得到输出层各个神经元的输出值;
3.求出输出层的误差,再通过反向传播算法,向后求出每一层(的每个神经元)的误差;
4.通过误差可以得出每个神经元的∂E/∂w、∂E/∂b,再乘上负的学习率(-η),就得到了Δw、Δb,将每个神经元的w和b更新为 w+Δw、b+Δb;
MATLAB实现代码如下:
%训练目标向量t
t = [5 4.9 4.5 4 3.5 3 2.9 3.5 3 2.9 1 1.5 1.2 1.2 1.2 -1 0 -0.3 -0.3 -1 -2 -1.3 -1.9 -2 -2.2 -2.5 -2.5 -2.5 -2.7 -2.7 -3 -4 -3.2 -3.3 -3.5 -3.6 -3 -3.5 -3.3 -3.2 -3.1 -4 -3 -3.1 -3.1 -3 -3 -2.9 -2.7 -2.6 -2.5 -3 -4 -3.8 -3.7 -3.6 -2.5 -2.5 -2.3 -2.1 -2 -2 -3 -2.8 -2.6 -2 1 -2.5 -2.4 -2.3 -2.3 -1.5 -2.2 -2.5 -2.3 -2 -1 -1 -0.8 -0.6 -0.5 -0.5 -0.5 -0.4 -0.3 -0.2 -0.2 -0.2 -0.1 -0.1 -0.1 0 0.2 0.2 0.3 0.3 0.3 0.4 0.5 0.7 0.8 1 1.1 1.2 1.3 1.4 1.5 1.4 1.5 1.4 1.4 1.5 1.6 1.6 1.7 1.9 2 2 2.1 2.3 2.5 2.5 2.6 2.7 2.8 2.9 3 3 3.1 3.1 3.2 3.3 3.3 3.5 3.6 3.9 4 4.1 4.2 4.1 4.2 4.1 4.3 4.5 4.5 4.6 4.7 4.8 4.8 4.9 5 5 4.9 4.8 4.8 4.7 4.3 4 3 3.2 3.4 3.5 3.4 3.2 3.5 2.8 2.6 2.1 1.5 1 0.5 -0.1 -0.5 -0.9 -1.2 -1.3 -1.5 -1.8 -2 -2.3 -3];
P_test=[-20 -17.5 -15 12.5 -10 -7.5 -5 -2.5 0 2.5 5 7.5 10 12.5 15 17.5 20 22.5 25 27.5 30 32.5 35 37.5 40 42.5 45 47.5 50 ;
-3 -2 -2 0 1 0 4 2 3 0 3 2.5 2 1 1.5 1 0.5 0.2 0 -0.3 -1 -1.5 -1.5 -2 -2.5 -3 -3.3 -4 -3];
%测试目标t1
t1=[ 3 2 2 0 -1 0 -4 -2 -3 0 -3 -2.5 -2 -1 -1.5 -1 -0.5 -0.2 0 0.3 1 1.5 1.5 2 2.5 3 3.3 4 3];
%训练集归一化
[pn,ps_input] = mapminmax(p,0,1);
[tn,ps_output] = mapminmax(t,0,1);
%测试集输入数据归一化
p2 = mapminmax('apply',P_test,ps_input); %将训练集的归一化的“标准”应用在测试集的归一化上
%创建网络参数,可以根据自己要求修改
net = newff(pn,tn);
net.trainparam.show=50;
net.trainparam.mc=0.9;
net.trainparam.lr=0.8;
net.trainparam.epochs=5000;
net.trainparam.goal=0.0000000000001;
%网络初始化
net=init(net);
%训练网络
[net,tr]=train(net,pn,tn);
%网络仿真
PN=sim(net,p2);
%反归一化
out = mapminmax('reverse',PN,ps_output);
%作图表示实测值和仿真值
figure(1);
X=-20:2.5:50;
plot(X,out,'r*',X,t1,'bo');
R2 = (29 * sum(out .* t1) - sum(out) * sum(t1))^2 / ((29 * sum((out).^2) - (sum(out))^2) * (29 * sum((t1).^2) - (sum(t1))^2));
title(sprintf('此仿真数据为大样本数据,*为预测值,o为预测值 相关系数为%f ',R2));
结果如下图

将大样本数据更换为小样本数据结果如下图:

总结:大样本下的学习效果和小样本学习效果相当。
RBF
RBF神将网络是一种三层神经网络,其包括输入层、隐层、输出层。从输入空间到隐层空间的变换是非线性的,而从隐层空间到输出层空间变换是线性的。其隐含层神经元的核函数取为高斯核函数.。输入层到隐含层采用非线性映射,隐含层到输出层采用线性映射。结构图如下:

RBF神经网络与BP神经网络之间的区别
1、局部逼近与全局逼近:
BP神经网络的隐节点采用输入模式与权向量的内积作为激活函数的自变量,而激活函数采用Sigmoid函数。各调参数对BP网络的输出具有同等地位的影响,因此BP神经网络是对非线性映射的全局逼近。
RBF神经网络的隐节点采用输入模式与中心向量的距离(如欧式距离)作为函数的自变量,并使用径向基函数(如Gaussian函数)作为激活函数。神经元的输入离径向基函数中心越远,神经元的激活程度就越低(高斯函数)。RBF网络的输出与部分调参数有关,譬如,一个wij值只影响一个yi的输出(参考上面第二章网络输出),RBF神经网络因此具有“局部映射”特性。所谓局部逼近是指目标函数的逼近仅仅根据查询点附近的数据。而事实上,对于径向基网络,通常使用的是高斯径向基函数,函数图象是两边衰减且径向对称的,当选取的中心与查询点(即输入数据)很接近的时候才对输入有真正的映射作用,若中心与查询点很远的时候,欧式距离太大的情况下,输出的结果趋于0,所以真正起作用的点还是与查询点很近的点,所以是局部逼近;而BP网络对目标函数的逼近跟所有数据都相关,而不仅仅来自查询点附近的数据。
2、中间层数的区别
BP神经网络可以有多个隐含层,但是RBF只有一个隐含层。
3、训练速度的区别
使用RBF的训练速度快,一方面是因为隐含层较少,另一方面,局部逼近可以简化计算量。对于一个输入x,只有部分神经元会有响应,其他的都近似为0,对应的w就不用调参了。
MATLAB实现代码如下:
%输入训练向量p,注意必须使p,t矩正列相等其中每列表示一个样本,行数表示总样本数
p=[-20 -19.5 -19 -18.5 -18 -17.5 -17 -16.5 -16 -15.5 -15 -14.5 -14 -13.5 -13 -12.5 -12 -11.5 -11 -10.5 -10 -9.5 -9 -8.5 -8 -7.5 -7 -6.5 -6 -5.5 -5 -4.5 -4 -3.5 -3 -2.5 -2 -1.5 -1 -0.5 0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 5.5 6 6.5 7 7.5 8 8.5 9 9.5 10 10.5 11 11.5 12 12.5 13 13.5 14 14.5 15 15.5 16 16.5 17 17.5 18 18.5 19 19.5 20 20.5 21 21.5 22 22.5 23 23.5 24 24.5 25 25.5 26 26.5 27 27.5 28 28.5 29 29.5 30 30.5 31 31.5 32 32.5 33 33.5 34 34.5 35 35.5 36 36.5 37 37.5 38 38.5 39 39.5 40 40.5 41 41.5 42 42.5 43 43.5 44 44.5 45 45.5 46 46.5 47 47.5 48 48.5 49 49.5 50 50.5 51 51.5 52 52.5 53 53.5 54 54.5 55 55.5 56 56.5 57 57.5 58 58.5 59 59.5 60 60.5 61 61.5 62 62.5 63 63.5 64 64.5 65 65.5 66 66.5 67 67.5 68 68.5 69 69.5 70;
-5 -4.9 -4.5 -4 -3.5 -3 -2.9 -3.5 -3 -2.9 -1 -1.5 -1.2 -1.2 -1.2 1 0 0.3 0.3 1 2 1.3 1.9 2 2.2 2.5 2.5 2.5 2.7 2.7 3 4 3.2 3.3 3.5 3.6 3 3.5 3.3 3.2 3.1 4 3 3.1 3.1 3 3 2.9 2.7 2.6 2.5 3 4 3.8 3.7 3.6 2.5 2.5 2.3 2.1 2 2 3 2.8 2.6 2 1 2.5 2.4 2.3 2.3 1.5 2.2 2.5 2.3 2 1 1 0.8 0.6 0.5 0.5 0.5 0.4 0.3 0.2 0.2 0.2 0.1 0.1 0.1 0 -0.2 -0.2 -0.3 -0.3 -0.3 -0.4 -0.5 -0.7 -0.8 -1 -1.1 -1.2 -1.3 -1.4 -1.5 -1.4 -1.5 -1.4 -1.4 -1.5 -1.6 -1.6 -1.7 -1.9 -2 -2 -2.1 -2.3 -2.5 -2.5 -2.6 -2.7 -2.8 -2.9 -3 -3 -3.1 -3.1 -3.2 -3.3 -3.3 -3.5 -3.6 -3.9 -4 -4.1 -4.2 -4.1 -4.2 -4.1 -4.3 -4.5 -4.5 -4.6 -4.7 -4.8 -4.8 -4.9 -5 -5 -4.9 -4.8 -4.8 -4.7 -4.3 -4 -3 -3.2 -3.4 -3.5 -3.4 -3.2 -3.5 -2.8 -2.6 -2.1 -1.5 -1 -0.5 0.1 0.5 0.9 1.2 1.3 1.5 1.8 2 2.3 3];
%训练目标向量t
t = [5 4.9 4.5 4 3.5 3 2.9 3.5 3 2.9 1 1.5 1.2 1.2 1.2 -1 0 -0.3 -0.3 -1 -2 -1.3 -1.9 -2 -2.2 -2.5 -2.5 -2.5 -2.7 -2.7 -3 -4 -3.2 -3.3 -3.5 -3.6 -3 -3.5 -3.3 -3.2 -3.1 -4 -3 -3.1 -3.1 -3 -3 -2.9 -2.7 -2.6 -2.5 -3 -4 -3.8 -3.7 -3.6 -2.5 -2.5 -2.3 -2.1 -2 -2 -3 -2.8 -2.6 -2 1 -2.5 -2.4 -2.3 -2.3 -1.5 -2.2 -2.5 -2.3 -2 -1 -1 -0.8 -0.6 -0.5 -0.5 -0.5 -0.4 -0.3 -0.2 -0.2 -0.2 -0.1 -0.1 -0.1 0 0.2 0.2 0.3 0.3 0.3 0.4 0.5 0.7 0.8 1 1.1 1.2 1.3 1.4 1.5 1.4 1.5 1.4 1.4 1.5 1.6 1.6 1.7 1.9 2 2 2.1 2.3 2.5 2.5 2.6 2.7 2.8 2.9 3 3 3.1 3.1 3.2 3.3 3.3 3.5 3.6 3.9 4 4.1 4.2 4.1 4.2 4.1 4.3 4.5 4.5 4.6 4.7 4.8 4.8 4.9 5 5 4.9 4.8 4.8 4.7 4.3 4 3 3.2 3.4 3.5 3.4 3.2 3.5 2.8 2.6 2.1 1.5 1 0.5 -0.1 -0.5 -0.9 -1.2 -1.3 -1.5 -1.8 -2 -2.3 -3];
%测试样本P_test
P_test=[-20 -17.5 -15 -10.5 -10 -7.5 -5 -2.5 0 2.5 5 7.5 10 12.5 15 17.5 20 22.5 25 27.5 30 32.5 35 37.5 40 42.5 45 47.5 50 ;
-2 0 -0.5 1 2 1.5 4 3 3 3 3 2.5 2 1 0.5 1 0.5 0.3 0 -0.3 -1 -1.5 -2 -1.5 -1 -3 -3.3 -4 -4.1];
%测试目标t1
t1=[ 2 0 0.5 -1 -2 -1.5 -4 -3 -3 -3 -3 -2.5 -2 -1 -0.5 -1 -0.5 -0.3 0 0.3 1 1.5 2 1.5 1 3 3.3 4 4.1];
net=newrbe(p,t,4000);%4000位spread参数,需要自己根据数据来调整
%网络仿真
out=sim(net,P_test)
%作图表示实测值和仿真值
figure(1);
X=-20:2.5:50;
plot(X,t1,'r*',X,out,'bo');
%plot(X,P_test(2,:),'r*',X,out,'bo');
R2 = (29 * sum(out .* t1) - sum(out) * sum(t1))^2 / ((29 * sum((out).^2) - (sum(out))^2) * (29 * sum((t1).^2) - (sum(t1))^2));
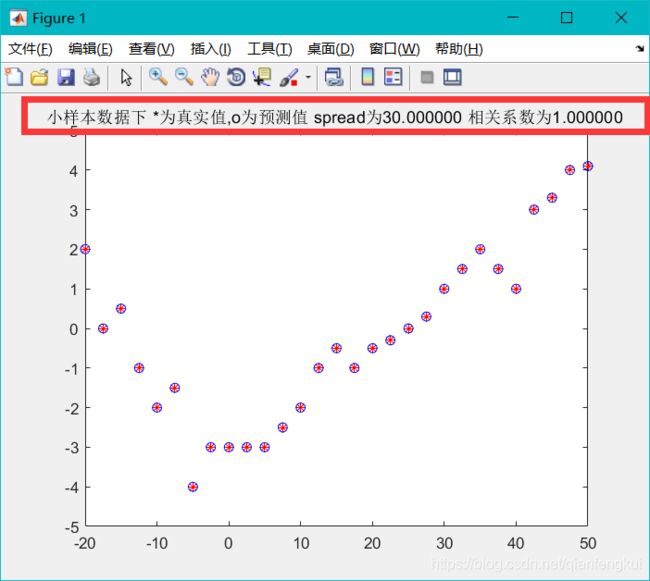
title(sprintf('大样本数据下 *为真实值,o为预测值 spread为%f 相关系数为%f ',spread,R2));

GRNN
广义回归神经网络是径向基神经网络的一种,GRNN具有很强的非线性映射能力和学习速度,比RBF具有更强的优势,网络最后普收敛于样本量集聚较多的优化回归,样本数据少时,预测效果很好,还可以处理不稳定数据。虽然GRNN看起来没有径向基精准,但实际在分类和拟合上,特别是数据精准度比较差的时候有着很大的优势。
关于RBF&GRNN
-
RBF网络是一个两层的网络,除了输入输出层之外仅有一个隐层。隐层中的转换函数是局部响应的高斯函数,而其他前向型网络,转换函数一般都是全局响应函数。由于这样的不同,要实现同样的功能,RBF需要更多的神经元,这就是RBF网络不能取代标准前向型网络的原因。但是RBF的训练时间更短。它对函数的逼近是最优的,可以以任意精度逼近任意连续函数。隐层中的神经元越多,逼近越较精确.
-
径向基神经元和线性神经元可以建立广义回归神经网络,它是径RBF网络的一种变化形式,经常用于函数逼近。在某些方面比RBF网络更具优势。GRNN隐藏层与输入层全连接,层内无连接,隐藏层神经元个数与样本个数相等,也就是n,传输函数为径向基函数。
GRNN结构图如下:



分析比较
GRNN效果并不好,故抛弃此方案,大样本数据下BP网络效果最好,小样本数据下RBF效果最好。