AI量化与机器学习流程:从数据到模型
原创文章第99篇,专注“个人成长与财富自由、世界运作的逻辑, AI量化投资”。
第99篇了,第一个100篇原创小目标就要完成,非常好。
坚持1000天做一件事情,会是什么效果?拭目以待吧。
这几天的文章讲了数据(hdf5:兼容pandas的dataframe合适量化的存储格式)、特征工程(因子特征工程:基于pandas和talib(代码))、单因子评估(【每周研报复现】AI量化特征工程之alphalens:一套用于分析 alpha 因子的通用工具),今天要说说模型。
先要把金融建模与机器学习流程结合起来:
01 数据准备、特征工程及标注
def feature_engineer(df):
features = []
for p in [1, 5, 20, 60]:
features.append('mom_{}'.format(p))
df['mom_{}'.format(p)] = df['close'].pct_change(p)
df['f_return_1'] = np.sign(df['close'].shift(-1) / df['close'] - 1)
features.append('code')
features.append('f_return_1')
print(features)
df = df[features]
return df
import pandas as pd
symbols = ['SPX', '000300.SH']
dfs = []
with pd.HDFStore('data/index.h5') as store:
for symbol in symbols:
df = store[symbol]
df['close'] = df['close'] / df['close'].iloc[0]
df = feature_engineer(df)
dfs.append(df)
all = pd.concat(dfs)
# all.set_index([all.index,'code'],inplace=True)
all.sort_index(ascending=True, level=0, inplace=True)
all.dropna(inplace=True)
all
这里得到特征工程及标注后的数据集,
这个过程是通用的:
02 划分数据集
import numpy as np
import datetime
def get_date_by_percent(start_date,end_date,percent):
days = (end_date - start_date).days
target_days = np.trunc(days * percent)
target_date = start_date + datetime.timedelta(days=target_days)
#print days, target_days,target_date
return target_date
def split_dataset(df,input_column_array,label,split_ratio):
split_date = get_date_by_percent(df.index[0],df.index[df.shape[0]-1],split_ratio)
input_data = df[input_column_array]
output_data = df[label]
# Create training and test sets
X_train = input_data[input_data.index < split_date]
X_test = input_data[input_data.index >= split_date]
Y_train = output_data[output_data.index < split_date]
Y_test = output_data[output_data.index >= split_date]
return X_train,X_test,Y_train,Y_test
03 基准模型
实现三个基准模型,分别为logistic回归、随机森森和SVM。
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC, SVC
def do_logistic_regression(x_train,y_train):
classifier = LogisticRegression()
classifier.fit(x_train, y_train)
return classifier
def do_random_forest(x_train,y_train):
classifier = RandomForestClassifier()
classifier.fit(x_train, y_train)
return classifier
def do_svm(x_train,y_train):
classifier = SVC()
classifier.fit(x_train, y_train)
return classifier
04 测试
def test_predictor(classifier, x_test, y_test):
pred = classifier.predict(x_test)
hit_count = 0
total_count = len(y_test)
for index in range(total_count):
if (pred[index]) == (y_test[index]):
hit_count = hit_count + 1
hit_ratio = hit_count / total_count
score = classifier.score(x_test, y_test)
print("hit_count=%s, total=%s, hit_ratio = %s" % (hit_count, total_count, hit_ratio))
return hit_ratio, score
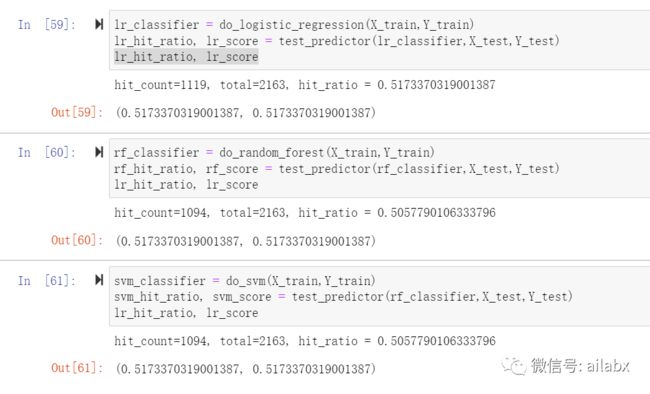
金融量化注入到机器学习全流程中,主要就是数据预处理,因子计算,数据自动化标注,然后模型训练,模型预测等等。
这个过程几乎是标准的,后来主要是添加更多、更好的因子,不同的标注方法,可以是分类也可以是连续的。同时,因子也可以做一些预处理,滤波之类的。
然后就是更好的,能力更强的模型。