背景
线程池是为了避免线程频繁的创建和销毁带来的性能消耗,而建立的一种池化技术,它是把已创建的线程放入“池”中,当有任务来临时就可以重用已有的线程,无需等待创建的过程,这样就可以有效提高程序的响应速度。但如果要说线程池的话一定离不开 ThreadPoolExecutor ,在阿里巴巴的《Java 开发手册》中是这样规定线程池的:
线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的读者更加明确线程池的运行规则,规避资源耗尽的风险。
说明:Executors 返回的线程池对象的弊端如下:
FixedThreadPool 和 SingleThreadPool:允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。CachedThreadPool 和 ScheduledThreadPool:允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
其实当我们去看 Executors 的源码会发现,Executors.newFixedThreadPool()、Executors.newSingleThreadExecutor() 和 Executors.newCachedThreadPool() 等方法的底层都是通过 ThreadPoolExecutor 实现的,所以本课时我们就重点来了解一下 ThreadPoolExecutor 的相关知识,比如它有哪些核心的参数?它是如何工作的?
典型回答
ThreadPoolExecutor 的核心参数指的是它在构建时需要传递的参数,其构造方法如下所示:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
// maximumPoolSize 必须大于 0,且必须大于 corePoolSize
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
第 1 个参数:corePoolSize 表示线程池的常驻核心线程数。如果设置为 0,则表示在没有任何任务时,销毁线程池;如果大于 0,即使没有任务时也会保证线程池的线程数量等于此值。但需要注意,此值如果设置的比较小,则会频繁的创建和销毁线程(创建和销毁的原因会在本课时的下半部分讲到);如果设置的比较大,则会浪费系统资源,所以开发者需要根据自己的实际业务来调整此值。
第 2 个参数:maximumPoolSize 表示线程池在任务最多时,最大可以创建的线程数。官方规定此值必须大于 0,也必须大于等于 corePoolSize,此值只有在任务比较多,且不能存放在任务队列时,才会用到。
第 3 个参数:keepAliveTime 表示线程的存活时间,当线程池空闲时并且超过了此时间,多余的线程就会销毁,直到线程池中的线程数量销毁的等于 corePoolSize 为止,如果 maximumPoolSize 等于 corePoolSize,那么线程池在空闲的时候也不会销毁任何线程。
第 4 个参数:unit 表示存活时间的单位,它是配合 keepAliveTime 参数共同使用的。
第 5 个参数:workQueue 表示线程池执行的任务队列,当线程池的所有线程都在处理任务时,如果来了新任务就会缓存到此任务队列中排队等待执行。
第 6 个参数:threadFactory 表示线程的创建工厂,此参数一般用的比较少,我们通常在创建线程池时不指定此参数,它会使用默认的线程创建工厂的方法来创建线程,源代码如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue) {
// Executors.defaultThreadFactory() 为默认的线程创建工厂
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
public static ThreadFactory defaultThreadFactory() {
return new DefaultThreadFactory();
}
// 默认的线程创建工厂,需要实现 ThreadFactory 接口
static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
// 创建线程
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false); // 创建一个非守护线程
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY); // 线程优先级设置为默认值
return t;
}
}
我们也可以自定义一个线程工厂,通过实现 ThreadFactory 接口来完成,这样就可以自定义线程的名称或线程执行的优先级了。
第 7 个参数:RejectedExecutionHandler 表示指定线程池的拒绝策略,当线程池的任务已经在缓存队列 workQueue 中存储满了之后,并且不能创建新的线程来执行此任务时,就会用到此拒绝策略,它属于一种限流保护的机制。
线程池的工作流程要从它的执行方法 execute() 说起,源码如下:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
// 当前工作的线程数小于核心线程数
if (workerCountOf(c) < corePoolSize) {
// 创建新的线程执行此任务
if (addWorker(command, true))
return;
c = ctl.get();
}
// 检查线程池是否处于运行状态,如果是则把任务添加到队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 再出检查线程池是否处于运行状态,防止在第一次校验通过后线程池关闭
// 如果是非运行状态,则将刚加入队列的任务移除
if (! isRunning(recheck) && remove(command))
reject(command);
// 如果线程池的线程数为 0 时(当 corePoolSize 设置为 0 时会发生)
else if (workerCountOf(recheck) == 0)
addWorker(null, false); // 新建线程执行任务
}
// 核心线程都在忙且队列都已爆满,尝试新启动一个线程执行失败
else if (!addWorker(command, false))
// 执行拒绝策略
reject(command);
}
其中 addWorker(Runnable firstTask, boolean core) 方法的参数说明如下:
- firstTask,线程应首先运行的任务,如果没有则可以设置为 null;
- core,判断是否可以创建线程的阀值(最大值),如果等于 true 则表示使用 corePoolSize 作为阀值,false 则表示使用maximumPoolSize 作为阀值。
考点分析
线程池任务执行的主要流程,可以参考以下流程图:
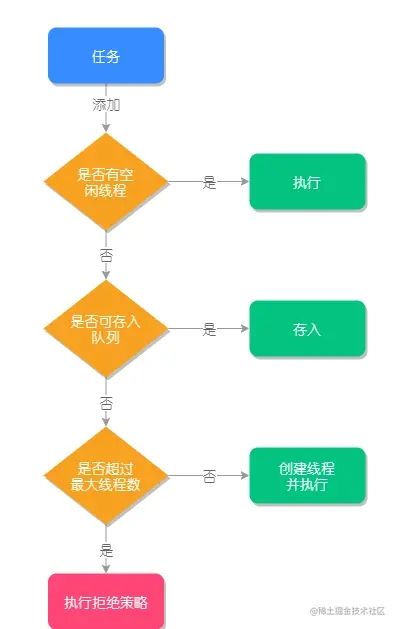
与 ThreadPoolExecutor 相关的面试题还有以下几个:
- ThreadPoolExecutor 的执行方法有几种?它们有什么区别?
- 什么是线程的拒绝策略?
- 拒绝策略的分类有哪些?
- 如何自定义拒绝策略?
- ThreadPoolExecutor 能不能实现扩展?如何实现扩展?
知识拓展
execute() VS submit()
execute() 和 submit() 都是用来执行线程池任务的,它们最主要的区别是,submit() 方法可以接收线程池执行的返回值,而 execute() 不能接收返回值。
来看两个方法的具体使用:
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 10, 10L,
TimeUnit.SECONDS, new LinkedBlockingQueue(20));
// execute 使用
executor.execute(new Runnable() {
@Override
public void run() {
System.out.println("Hello, execute.");
}
});
// submit 使用
Future future = executor.submit(new Callable() {
@Override
public String call() throws Exception {
System.out.println("Hello, submit.");
return "Success";
}
});
System.out.println(future.get());
以上程序执行结果如下:
Hello, submit.
Hello, execute.
Success
从以上结果可以看出 submit() 方法可以配合 Futrue 来接收线程执行的返回值。它们的另一个区别是 execute() 方法属于 Executor 接口的方法,而 submit() 方法则是属于 ExecutorService 接口的方法,它们的继承关系如下图所示:

线程池的拒绝策略
当线程池中的任务队列已经被存满,再有任务添加时会先判断当前线程池中的线程数是否大于等于线程池的最大值,如果是,则会触发线程池的拒绝策略。
Java 自带的拒绝策略有 4 种:
- AbortPolicy,终止策略,线程池会抛出异常并终止执行,它是默认的拒绝策略;
- CallerRunsPolicy,把任务交给当前线程来执行;
- DiscardPolicy,忽略此任务(最新的任务);
- DiscardOldestPolicy,忽略最早的任务(最先加入队列的任务)。
例如,我们来演示一个 AbortPolicy 的拒绝策略,代码如下:
ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 3, 10,
TimeUnit.SECONDS, new LinkedBlockingQueue<>(2),
new ThreadPoolExecutor.AbortPolicy()); // 添加 AbortPolicy 拒绝策略
for (int i = 0; i < 6; i++) {
executor.execute(() -> {
System.out.println(Thread.currentThread().getName());
});
}
以上程序的执行结果:
pool-1-thread-1
pool-1-thread-1
pool-1-thread-1
pool-1-thread-3
pool-1-thread-2
Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task com.lagou.interview.ThreadPoolExample$$Lambda$1/1096979270@448139f0 rejected from java.util.concurrent.ThreadPoolExecutor@7cca494b[Running, pool size = 3, active threads = 3, queued tasks = 2, completed tasks = 0]
at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063)
at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379)
at com.lagou.interview.ThreadPoolExample.rejected(ThreadPoolExample.java:35)
at com.lagou.interview.ThreadPoolExample.main(ThreadPoolExample.java:26)
可以看出当第 6 个任务来的时候,线程池则执行了AbortPolicy 拒绝策略,抛出了异常。因为队列最多存储 2 个任务,最大可以创建 3 个线程来执行任务(2+3=5),所以当第 6 个任务来的时候,此线程池就“忙”不过来了。
自定义拒绝策略
自定义拒绝策略只需要新建一个 RejectedExecutionHandler 对象,然后重写它的 rejectedExecution() 方法即可,如下代码所示:
ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 3, 10,
TimeUnit.SECONDS, new LinkedBlockingQueue<>(2),
new RejectedExecutionHandler() { // 添加自定义拒绝策略
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 业务处理方法
System.out.println("执行自定义拒绝策略");
}
});
for (int i = 0; i < 6; i++) {
executor.execute(() -> {
System.out.println(Thread.currentThread().getName());
});
}
以上代码执行的结果如下:
执行自定义拒绝策略
pool-1-thread-2
pool-1-thread-3
pool-1-thread-1
pool-1-thread-1
pool-1-thread-2
可以看出线程池执行了自定义的拒绝策略,我们可以在 rejectedExecution 中添加自己业务处理的代码。
ThreadPoolExecutor 扩展
ThreadPoolExecutor 的扩展主要是通过重写它的 beforeExecute() 和 afterExecute() 方法实现的,我们可以在扩展方法中添加日志或者实现数据统计,比如统计线程的执行时间,如下代码所示:
public class ThreadPoolExtend {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 线程池扩展调用
MyThreadPoolExecutor executor = new MyThreadPoolExecutor(2, 4, 10,
TimeUnit.SECONDS, new LinkedBlockingQueue());
for (int i = 0; i < 3; i++) {
executor.execute(() -> {
Thread.currentThread().getName();
});
}
}
/**
* 线程池扩展
*/
static class MyThreadPoolExecutor extends ThreadPoolExecutor {
// 保存线程执行开始时间
private final ThreadLocal localTime = new ThreadLocal<>();
public MyThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime,
TimeUnit unit, BlockingQueue workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
/**
* 开始执行之前
* @param t 线程
* @param r 任务
*/
@Override
protected void beforeExecute(Thread t, Runnable r) {
Long sTime = System.nanoTime(); // 开始时间 (单位:纳秒)
localTime.set(sTime);
System.out.println(String.format("%s | before | time=%s",
t.getName(), sTime));
super.beforeExecute(t, r);
}
/**
* 执行完成之后
* @param r 任务
* @param t 抛出的异常
*/
@Override
protected void afterExecute(Runnable r, Throwable t) {
Long eTime = System.nanoTime(); // 结束时间 (单位:纳秒)
Long totalTime = eTime - localTime.get(); // 执行总时间
System.out.println(String.format("%s | after | time=%s | 耗时:%s 毫秒",
Thread.currentThread().getName(), eTime, (totalTime / 1000000.0)));
super.afterExecute(r, t);
}
}
}
以上程序的执行结果如下所示:
pool-1-thread-1 | before | time=4570298843700
pool-1-thread-2 | before | time=4570298840000
pool-1-thread-1 | after | time=4570327059500 | 耗时:28.2158 毫秒
pool-1-thread-2 | after | time=4570327138100 | 耗时:28.2981 毫秒
pool-1-thread-1 | before | time=4570328467800
pool-1-thread-1 | after | time=4570328636800 | 耗时:0.169 毫秒
小结
最后我们总结一下:线程池的使用必须要通过 ThreadPoolExecutor 的方式来创建,这样才可以更加明确线程池的运行规则,规避资源耗尽的风险。同时,也介绍了 ThreadPoolExecutor 的七大核心参数,包括核心线程数和最大线程数之间的区别,当线程池的任务队列没有可用空间且线程池的线程数量已经达到了最大线程数时,则会执行拒绝策略,Java 自动的拒绝策略有 4 种,用户也可以通过重写 rejectedExecution() 来自定义拒绝策略,我们还可以通过重写 beforeExecute() 和 afterExecute() 来实现 ThreadPoolExecutor 的扩展功能。
以上就是ThreadPoolExecutor参数含义及源码执行流程详解的详细内容,更多关于ThreadPoolExecutor执行流程的资料请关注脚本之家其它相关文章!