Linux_文件系统(内存角度)
文章目录
- 文件描述符
-
- 什么是文件描述符
- 文件描述符的使用
-
- open()
-
- 参数—flags
- 参数—mode
- 返回值
- close()
- write()
-
- 参数—fd
- 参数—buf、count
- 返回值
- read()
-
- 参数fd
- 参数buf&&count
- 返回值
- C库函数和系统调用的联系
- 自动打开的文件
- 文件描述符的底层原理
- 如何理解一切皆文件
- 关于重定向
-
- 文件描述符的分配规则
- 重定向的本质
- 重定向接口—dup2
- 命令行中的重定向
-
- 回顾
- shell的实现方式
- 标准错误流
-
- 拆分
- 合并
- perror
- 缓冲区的理解
-
- 什么是缓冲区
- 为什么要有缓冲区
-
- 1. 解放进程的IO时间
- 2. 集中处理数据的刷新
- 缓冲区在哪
-
- 语言级缓冲区
- 文件系统缓冲区
- 缓冲区刷新策略
- FILE的总结
- 案例解析
文件描述符
什么是文件描述符
在C语言中,有一些对文件操作的函数,如:
- 打开一个文件–>
fopen() - 关闭一个文件–>
fclose() - 对文件进行写入–>
fwrite() - 对文件进行读取–>
fread() - ……
具体这些函数的使用,可以通过这篇文章回顾一下–>C语言文件操作函数
总体看,这套文件操作的使用逻辑就是:打开一个文件,对文件进行操作,关闭这个文件;
为了让操作的时候能找到这个文件,C语言提供了一个FILE*的结构体指针,里面存着可以找到文件的成员变量,打开文件的同时返回这样一个指针,之后的对FILE* 的操作即使对文件的操作。
int main()
{
FILE* fp = fopen("test.txt", ...);
fwrite(fp, ...);
fread(fp, ...);
fclose(fp);
}
我们知道,当调用C语言函数对文件进行写入的时候,最终一定是向磁盘中写入
然而只有操作系统有资格向硬件进行写入
也就是说,C语言函数底层一定调用了操作系统提供的系统调用接口(函数)
这套系统接口对文件的操作方法无非也只是打开、访问、关闭
那就一定也要有一个可以代表这个文件、找到这个文件的变量
我们就称这个变量为文件描述符
文件描述符的使用
要了解文件描述符,我们就先看看它怎么用,
那就不可避免的要看一些文件操作的系统调用:
open()
相当于C语言的fopen(),open()这个系统调用也用于打开一个文件
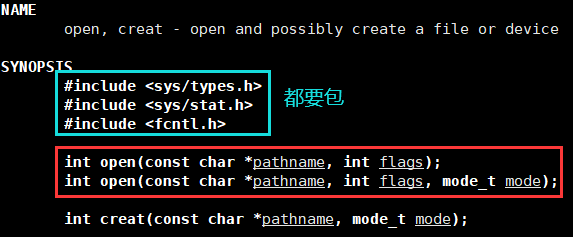
可以看到上面有两个两个同名的open()函数,我们可以把它看作是C语言的一种函数重载
两者唯一的区别就是传或不传mode
其中第一个参数filename就是文件的路径,与fopen()一致,我们重点分析后两个和它的返回值——文件描述符
参数—flags
通过这个参数传入文件的打开方式

如下三个必选一个
| 宏 | 含义 |
|---|---|
O_RDONLY |
只读 |
O_WRONLY |
只写 |
O_RDWR |
读/写 |
下面这些可以添加0个或多个
| 宏 | 含义 |
|---|---|
| O_CREAT | 如果文件不存在就创建之 |
| O_TRUNC | 打开一个文件时,先将其已有内容清空 |
| O_APPEND | 对文件追加 (如果不是追加模式,默认的读写指针会指向头,也就是会从头进行覆盖式写入 如果使用了追加模式,文件的读写指针会指向文件的末尾,就会追加写入) |
这些宏以位图的模式传入,
我们知道,一个int有32位,其中每一位都可以作为一个bool值表示有或无
所以,我们将这些某些位定义为宏,如:把O_WRONLY 设置为0001(2)
当函数内通过位操作检测到flag的这一位为1,则进行只读的处理
所以,我们就可以把多个宏按位或到一起,如:O_WRONLY | O_CREAT,表示用只读的方式创建一个文件。
参数—mode
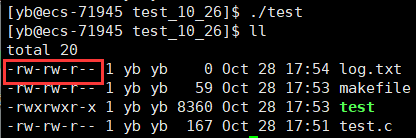
我们尝试用O_WRONLY | O_CREAT创建一个文件:
#include 
可以看到,创建好的文件的权限是杂乱无章的(其实就是一串乱码)
这是因为函数open在创建文件的时候,一定要设置文件的权限属性
这里的属性就是通过第三个参数mode传入的,传入一个三位的八进制数,具体原则可以看Linux_文件权限–>修改文件权限–>方法二
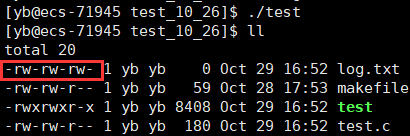
#include (这里0666 的第一个0仅表示这是一个C语言的8进制数字,实际有意义的仅仅是后三位666)
此时创建的文件正常了许多,但是依然不能与666完全对应,上面的是664
这其实是因为这里创建的文件也会收掩码——umask的影响
因为我们当前系统的掩码是0002,所以其他用户的w权限被去掉了
(具体掩码的知识可以看 Linux_文件权限–>权限掩码—umask)
所以我们需要暂时把掩码设置为0

umask(0)即可将掩码设置为0;
#include 此时新建文件的权限就是我们所期望的666了
返回值
这里的返回值是一个整型,我们称之为文件描述符,它是对打开文件的一个标识;
后面可以通过这个整数对当前open打开的文件进行读写访问或者关闭
close()
关闭一个文件

传入open返回的整型即可关闭那个文件
write()
对文件进行写入
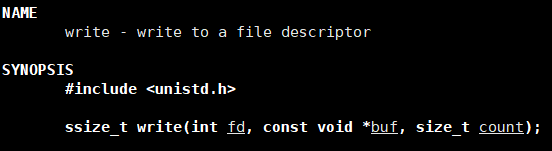
参数—fd
第一个参数传入代表文件的文件描述符,即之前open的返回值,且必须是用写入方式打开的文件(O_WRONLY或O_RDWR)
参数—buf、count
要写入空间的首地址(可以是任何类型:char*,int*,自定义类型指针……)和要写入的大小(以字节为单位)
#include 
返回值
返回写入的字节数,这里的ssize_t类型相当于signed int
read()
从文件中读取内容

参数fd
用于读取的文件的文件描述符
这个文件打开的时候一定要有读取权限(O_RDONLY或O_RDWR)
参数buf&&count
从文件中读count个字节读到buf中,如果count大于文件的大小,仅读完文件
返回值
返回读到的字节数;没有读到返回0;发生错误返回-1
C库函数和系统调用的联系
-
毋庸置疑,C库函数底层调用了系统调用
-
函数接口是对应的:
fopen–>openfwrite–>write- ……
-
数据类型对应:
FILE* fp–>int fd
实际上FILE结构体中用来标定文件的成员变量就是文件描述符,
int main()
{
int fd1 = open("file1.txt", O_WRONLY | O_CREAT, 0666);
int fd2 = open("file2.txt", O_WRONLY | O_CREAT, 0666);
int fd3 = open("file3.txt", O_WRONLY | O_CREAT, 0666);
int fd4 = open("file4.txt", O_WRONLY | O_CREAT, 0666);
int fd5 = open("file5.txt", O_WRONLY | O_CREAT, 0666);
printf("%d-%d-%d-%d-%d\n", fd1, fd2, fd3, fd4, fd5);
return 0;
}
int main(int argc, char const *argv[])
{
FILE *fp1 = fopen("file1.txt", "w");
FILE *fp2 = fopen("file2.txt", "w");
FILE *fp3 = fopen("file3.txt", "w");
FILE *fp4 = fopen("file4.txt", "w");
FILE *fp5 = fopen("file5.txt", "w");
printf("%d-%d-%d-%d-%d\n", fp1->_fileno, fp2->_fileno, fp3->_fileno, fp4->_fileno, fp5->_fileno);
return 0;
}
运行这两段代码,可以发现结果相同,
所以可以证明,FILE中的_fileno成员变量存的就是系统调用的fd
自动打开的文件
从上面的案例,我们还发现两个现象:
- 这里的文件描述符是非常有规律的2,3,4……像极了数组的下标
- 如果是数组的下标,那0、1、2三个值去哪了
实际上0,1,2描述符对应的文件确实存在,它们分别是:
- 0–>输入流(键盘设备)
- 1–>输出流(屏幕设备)
- 2–>错误流(屏幕设备)
(由于Linux一切皆文件的理念,我们先把这些设备看作是文件,至于它是如何实现让设备和磁盘中的文件能同等看待的,后面会讲到)
C程序会默认打开这三个文件,我们编写代码打开的文件,自然也就会排在在这三个文件之后了。
文件描述符的底层原理
我们知道,一个进程可以打开多个文件
那么我们就要对这些文件进行管理
管理就是先描述,再组织
-
描述–>定义一个结构体
struct file { //包含了我们想看到的大部分文件内容 struct file* next;//指向后一个结构体 } -
组织–>将这些结构体用某种数据结构串联起来

(虽然内核中实际用的不是链表,我们就先用一张链表代表它被组织起来了)
对被打开文件的管理,就转化成了对链表的增删查改
所有的进程打开的文件都会串联到如上这张链表中,那么每个进程又如何与自己的文件结构体建立映射关系呢?
实际上,每个进程的进程控制块上都有一个数组指针,数组里存了struct file*,指向打开文件对应结构体的首地址
然后返回数组的下标给用户,用户即可通过数组下标找到对应的文件对象,找到对应的文件
实际上这个数组的下标就是open()打开文件后,返回的文件描述符

如下是linux-2.6.32.26的源代码
如下是进程控制块结构体——task_struct中的成员变量

如下是files_struct结构体

其中
fd_array就是存储file指针的数组,它的默认大小NR_OPEN_DEFAULT,这个值一般是32或64,但最多可以打开的文件不只这么多,通过扩展表,做多可以扩展到10万个文件;我们可以通过
ulimit -a,看到自己主机当前的进程文件默认最大打开数
我们再打开file结构体
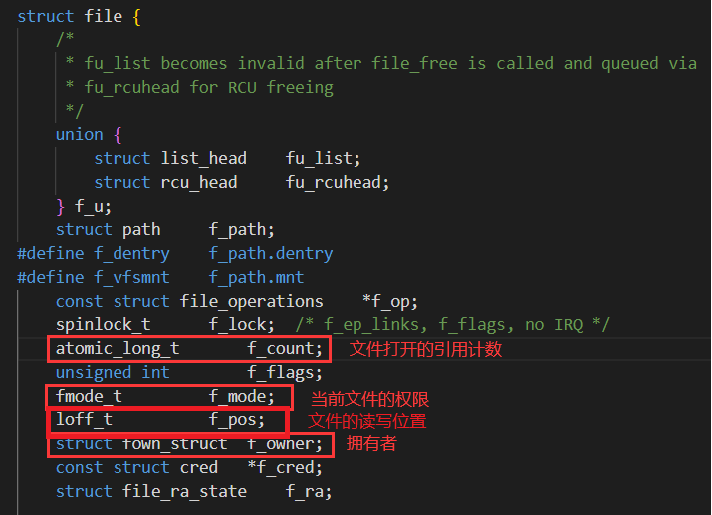
如何理解一切皆文件
前面提到,程序默认打开的三个文件其实是三个外设,那操作系统是如何做到把外设和文件一视同仁的呢?
首先,所有的外设都要让驱动进行操作,驱动也要为上层提供相应的读写接口
从上面我们知道,操作系统会用一个file结构体描述一个文件
那么就可以在结构体中设置一些函数指针,指向对应打开设备的操作函数
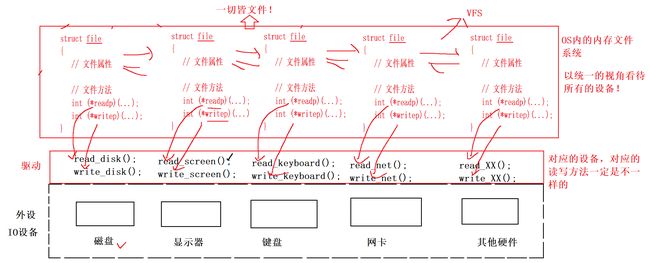
当构造一个file对象的时候,让readp和writep指向对应设备的操作函数
当write()函数底层对文件进行写入的时候,只会调用readp这个函数,至于到底是在对什么设备操作,它并不关心;
这其实就是C++中多态概念的原始体现。
如上这种文件管理方式我们称为虚拟文件系统 Virtual File Systems(VFS)
我们看一下内核代码块中的file:
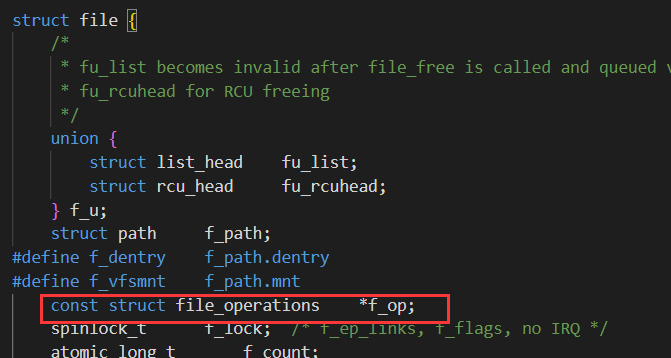
这里file_operations结构体中就是对应的一些函数指针:

在file结构体构造的时候,就会把f_op成员中的这些函数指针指向对应文件或设备的接口·
关于重定向
文件描述符的分配规则
如果直接打开一个文件:
int main(int argc, char const *argv[])
{
int fd = open("file.txt", O_CREAT | O_WRONLY, 0666);
printf("fd->%d\n", fd);
close(fd);
return 0;
}
fd->3
默认分配的文件操作符是3;
如果先把输入文件(0)关掉:
int main(int argc, char const *argv[])
{
close(0);
int fd = open("file.txt", O_CREAT | O_WRONLY, 0666);
printf("fd->%d\n", fd);
close(fd);
return 0;
}
fd->0
新创建的文件的文件操作符就是0,顶替了原本的输出文件
所以,我们可以得出:
文件操作符的分配规则就是:从0位置开始找到第一个未使用的进行分配
重定向的本质
那么,我们我们如果打开一个新文件之前,先将用于标准输出的文件描述符—1中的文件关掉,
那么这个位置就为空,新打开的文件就会放到这个位置,
原本1号文件描述符所对应的标准输出文件就变成了我们新打开的文件,
标准输出流—stdout中存的也是文件描述符1,它所代表的文件也变成了我们新打开的这个。
我们知道,所有对文件的读写操作(write,read,printf……)只认文件描述符
所以此时的所有标准输出都会写到文件中,我们测试一下:
int main(int argc, char const *argv[])
{
close(1);//关掉标准输出
int fd = open("file.txt", O_CREAT | O_WRONLY, 0666);//打开新文件
printf("fd->%d\n", fd);//向stdout输出
fflush(stdout);//刷新缓存区
close(fd);//关闭新打开的文件
return 0;
}
由于缓存区的存在,要想完成写入,必须对缓存区进行刷新,具体缓存区内容见后
此时运行这个程序,可以看到屏幕上并没有任何输出,打开file.txt文件可以看到相应的输出
fd->1

当我们调用printf进行打印的时候,它并不会关心是不是打印到了屏幕上,只会按部就班的到stdout的FILE结构体中找到_fileno,向文件描述符所指向的文件中写入。
但是如果想我们上面先关闭一个2文件,再打开一个文件的操作,进行重定向实在是有点挫,下面看看用于重定向的函数
重定向接口—dup2
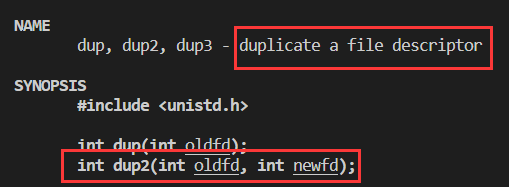
duplicate本意是复制,这个函数的作用也是复制一个文件描述符
dup2(): makes newfd be the copy of oldfd, closing newfd first if necessary
文档中的解释可能有点晦涩
我们知道,文件描述符就是file* fd_array[]这个数组的下标,
这个函数的作用就是把oldfd下标中的file*指针拷贝一份到newfd下标中,
如果newfd的位置不为空,就先将它指向的文件close()再拷贝
此时newfd和oldfd指向同一个文件
int main(int argc, char const *argv[])
{
int fd = open("file.txt", O_CREAT | O_WRONLY, 0666);
dup2(fd, 1); //把fd位置的文件拷贝一份到1位置
printf("fd->%d\n", fd);
fflush(stdout);
close(fd);
close(1);
return 0;
}
file.txt
fd->3
如果我们指向进行重定向,原位置3的文件不再需要,也可dup2(fd, 1);之后直接close(3);
我们也不需要担心这里的重复close()会造成资源重复释放,因为指向的file对象中会有一个引用计数,每当有新的文件描述符对其指向或进行close(),其内部的计数器会自动++/–,所以close()函数仅仅就是将file* fd_array[]数组的对应下标置空、再对file中的计数器进行–;至于file资源什么时候释放,完全由操作系统监管。
命令行中的重定向
回顾
我们回顾一下,命令行中重定向的使用:
int main()
{
string s;
getline(cin, s);
cout << s << endl;
return 0;
}
如果直接运行这个程序,输入一行,复制输出一行

当使用>out.txt,表示将原本要输出到屏幕的字符串输出到out.txt文件
使用
于是./test 即可把in.txt文件的一行拷贝到out.txt中

>表示先清空文件内容,然后覆盖式写入
如果想追加写入,可以使用追加重定向:>>

shell的实现方式
我们在命令行进行>:输出重定向、>>:追加重定向、<:输入重定向实际就是shell进程检测到了命令行中的>/>>/<符号,就将进程test的0/1号文件描述符指向后面的这个文件
假如我们要自己实现一个shell,就可以在fork之后,让子进程进行重定向到后面的out.txt,然后再进程替换为前面的./test
(至于如何实现一个shell,进程创建,进程替换等知识,可以看进程控制一文)
具体重定向:
当我们检测到>,在fork之后就可以
pid_t id = fork();
if(id==0)
{
int fd = open("out.txt", O_CREAT | O_WRONLY | O_TRUNC, 0666);
dup2(fd, stdout->_fileno);
execlp(...);
}
当检测到>>:
pid_t id = fork();
if(id==0)
{
int fd = open("out.txt", O_CREAT | O_WRONLY | O_APPEND, 0666);
dup2(fd, stdout->_fileno);
execlp(...);
}
当检测到<:
pid_t id = fork();
if(id==0)
{
int fd = open("in.txt", O_RDONLY);
dup2(fd, stdout->_fileno);
execlp(...);
}
(注意:execlp进程替换不会影响PCB中的file_struct表,不然我们前面的重定向就无效了)
标准错误流
拆分
前面我们一个C程序会默认产生三个FILE:标准输入流、标准输出流、标准错误流
第一个默认对应键盘,后两个都是屏幕
当我们程序出现错误的时候,一般使用如下的方式,调用标准错误流进行错误的打印
int main()
{
string s1 = "stderr";
string s2 = "stdout";
fprintf(stderr, "%s\n", s1.c_str());//C语言
cerr << s1 << endl;//c++
printf("%s\n", s2.c_str());//C语言
cout << s2 << endl;//c++
}
前两条会向3号文件描述符的文件输出
如果在执行程序的时候,仅仅使用>重定向到out.txt,”stdout”会在out.txt进行写入”stderr”依然会打印到屏幕上

因为>仅仅会改1号文件描述符,2号文件描述符对应的还是屏幕
如果我们想在命令行对stderr进行重定向,可以使用如下方法
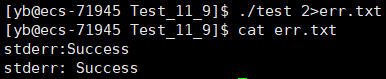
./test 2>err.txt >out.txt
表示把./test的2号描述符指向err.txt,1号描述符指向out.txt

(>等同于1>,当然如果已知程序中还有3,4,5号描述符,也可用3>,4>,5>对它们重定向)
那标准错误流的意义何在呢?
如此就可以把不同等级的错误和正常输出进行区分,让他们出现在不同的文件,这些文件的等级也称为日志等级
合并
前面的是将默认都输出到屏幕的改为输出到多个文件
那可以把原本输出到多个文件的改为输出到一个文件或屏幕吗?
如果仅
./test >all.txt
标准输出会到all.txt中去,但标准错误还会到屏幕上
./test >all.txt 2>&1
后面的2>&1表示把原本输出到2号文件描述符的内容输出到1号中去
此时,标准输出和标准错误就都会输出到all.txt中去
shell的实现也很好理解,只需dup2(1,2);即可
perror
C语言还有一个专门用于输出错误的函数perror
void perror ( const char * str );
它可以向stderr流输出str字符串和此时的错误(strerror(errno)):
int main()
{
string s1 = "stderr";
string s2 = "stdout";
fprintf(stderr, "%s:%s\n", s1.c_str(), strerror(errno));
perror(s1.c_str());
}
当一些C库函数调用的过程中如果发生了错误,可能会设置errno为特定数值,通过strerror函数可以把数值转为错误字符串
缓冲区的理解
在前面重定向的本质所给的代码案例中,有个小细节:最后要加一个fflush,用来刷新缓冲区
之前大家应该也或多或少听过缓冲区这个词
那什么是缓冲区呢?
什么是缓冲区
从本质上看,缓冲区就是一段物理
为什么要有缓冲区
1. 解放进程的IO时间
从计算机的冯诺依曼体系我们知道,CPU访问外设的时间相对于访问内存来说是很长的
那当我们打开一个文件进行写入的时候,需要经过漫长的路,完成数据的写入,然后才能会回来继续执行后续操作
在写入的这段时间,进程相当于一直在阻塞等待,也就是卡住了
为了增加效率,让进程运行起来更丝滑,我们可以先将数据写入内存中,然后迅速的回来执行后续的进程操作,从内存到文件的存储可以后面单独再做,这部分内存就是缓冲区
2. 集中处理数据的刷新
当进程要多次对文件等外设输入时,如果直接跟外设进行交互,读写十次,也就要10次漫长的IO时间
如果十次都先把数据加载到内存的缓冲区中,那么最终也只要一次IO时间,大大提高了IO效率
缓冲区在哪
前面说缓冲区是内存上的一段空间,那这段空间是谁开出来的?由谁管理?
这里的“谁”可以由很多答案,甚至用户在栈区开一个数组进行临时存储,如果符合上面的概念,也叫缓冲区
语言级缓冲区
当我们执行如下代码:
int main(int argc, char const *argv[])
{
printf("hello printf");
write(stdout->_fileno, "hello write", 20);
sleep(3);
return 0;
}
按照代码的执行顺序,屏幕上应该先输出hello printf,然后输出hello write,等待3秒后进程退出
但实际的打印情况是:屏幕上先输出hello write,三秒后,也就是进程退出的时候才输出hello printf
也很好理解,在C语言学习时我们就知道,如果printf输出的时候没有\n进行换号,默认不会刷新缓冲区,如果中间一直不出现刷新,会等到缓冲区满或者进程退出的时候再刷新,所以我们这里的hello printf一直等到进程退出的时候才刷新到屏幕
从进程已启动立刻就打印了hello write可以看出,这个系统级接口的缓冲区刷新策略是实时的
但是这个C语言提供的printf一定会调用系统接口write,如果它们用的是同一个缓冲区,当printf调用了write,一定会立即刷新
所以,可以得出,这里C语言的缓冲区和系统调用的一定不重合
事实上,C语言的缓冲区就在FILE结构体中
typedef _IO_FILE FILE;
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
//缓冲区相关
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
int _fileno;
#if 0
int _blksize;
#else
int _flags2;
#endif
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
};
也就是说,当我们使用fopen()每打开一个文件:
fopen会创建一个FILE结构体,并为FILE开一个缓冲区,然后返回这个FILE的地址
我们在调用fopen处就用一个FILE*接收
文件系统缓冲区
前面我们介绍了C语言的缓存区,但是系统调用write的缓冲区我们一直没细谈
这部分需要很多的知识铺垫,大家可以到Linux_文件系统一文再看
缓冲区刷新策略
从前面我们看到,缓冲区系统调用:write和语言级函数printf的刷新实际不同
单C语言的缓冲区,对stdout的输入时遇到换行就会刷新到屏幕,但对一个打开的磁盘文件输入时即使有换行也不会刷新
所以,不同地方的缓冲区刷新策略是不同的
我们总览一下缓冲区的刷新策略有哪些:
常规:
- 无缓冲(立即刷新)
- 行缓冲(遇到换号符刷新)——显示器文件(stdout)
- 全缓冲(缓冲区满才刷新)——块设备文件(磁盘文件)
特殊:
- 进程退出刷新
- 用户强制刷新——
fflush()
FILE的总结
此时我们了解到的,FILE中有三个东西:
文件描述符:int _fileno;
缓冲区的各种指针
不同打开文件对应的刷新策略:int _flags;
案例解析
观察如下代码:
int main()
{
const char *str1 = "hello printf\n";
const char *str2 = "hello fprintf\n";
const char *str3 = "hello fputs\n";
const char *str4 = "hello write\n";
printf(str1);
fprintf(stdout, str2);
fputs(str3, stdout);
write(stdout->_fileno, str4, strlen(str4));
fork();
return 0;
}
我们使用三个C库函数和一个系统调用接口分别打印四个字符串
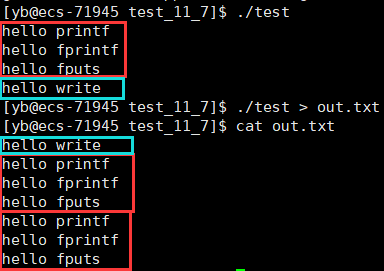
如果直接运行程序,结果确实与我们预期所一致
但是如果输出重定向到另一个文件,可以看到,打印的内容多了三条
发生了什么?
当我们对其重定向,stdout原本对应得显示器文件就变成了对应得磁盘文件,
同时刷新策略也从行缓冲变为了全缓冲,即三个C语言函数只有进程退出的时候才会刷新
其中write是系统调用,不会受C语言刷新策略的影响,一直都是即时刷新,也就只打印了一次
由于fork之后,进程所有的的数据都进行了写时拷贝,
也就相当于父进程和子进程各有一个未刷新的FILE类型的stdout
当父子都退出,都会触发进程退出时的流刷新,文件中也就有两份输出