深入理解 WKWebView (渲染篇) —— DOM 树的构建
全文12003字,预计阅读时间24分钟
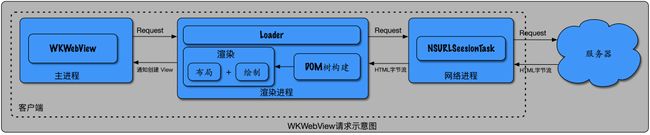
当客户端 App 主进程创建 WKWebView 对象时,会创建另外两个子进程:渲染进程与网络进程。主进程 WKWebView 发起请求时,先将请求转发给渲染进程,渲染进程再转发给网络进程,网络进程请求服务器。如果请求的是一个网页,网络进程会将服务器的响应数据 HTML 文件字符流吐给渲染进程。渲染进程拿到 HTML 文件字符流,首先要进行解析,将 HTML 文件字符流转换成 DOM 树,然后在 DOM 树的基础上,进行渲染操作,也就是布局、绘制。最后渲染进程通知主进程 WKWebView 创建对应的 View 展现视图。整个流程如下图所示:
一、什么是DOM树
渲染进程获取到 HTML 文件字符流,会将HTML文件字符流转换成 DOM 树。下图中左侧是一个 HTML 文件,右边就是转换而成的 DOM 树。
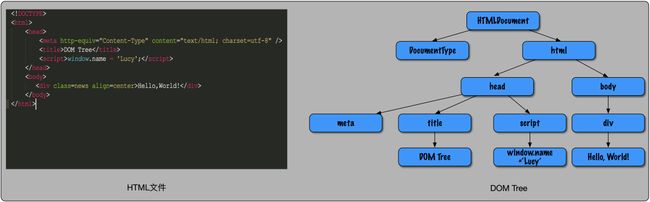
可以看到 DOM 树的根节点是 HTMLDocument,代表整个文档。根节点下面的子节点与 HTML 文件中的标签是一一对应的,比如 HTML 中的 标签就对应 DOM 树中的 head 节点。同时 HTML 文件中的文本,也成为 DOM 树中的一个节点,比如文本 ‘Hello, World!’,在 DOM 树中就成为div节点的子节点。
在 DOM 树中每一个节点都是具有一定方法与属性的对象,这些对象由对应的类创建出来。比如 HTMLDocument 节点,它对应的类是 class HTMLDocument,下面是 HTMLDocument 的部分源码:
class HTMLDocument : public Document { // 继承自 Document
...
WEBCORE_EXPORT int width();
WEBCORE_EXPORT int height();
...
}
从源码中可以看到,HTMLDocument 继承自类 Document,Document 类的部分源码如下:
class Document
: public ContainerNode // Document继承自 ContainerNode,ContainerNode继承自Node
, public TreeScope
, public ScriptExecutionContext
, public FontSelectorClient
, public FrameDestructionObserver
, public Supplementable
, public Logger::Observer
, public CanvasObserver {
WEBCORE_EXPORT ExceptionOr> createElementForBindings(const AtomString& tagName); // 创建Element的方法
WEBCORE_EXPORT Ref createTextNode(const String& data); // 创建文本节点的方法
WEBCORE_EXPORT Ref createComment(const String& data); // 创建注释的方法
WEBCORE_EXPORT Ref createElement(const QualifiedName&, bool createdByParser); // 创建Element方法
....
}
上面源码可以看到 Document 继承自 Node,而且还可以看到前端十分熟悉的 createElement、createTextNode 等方法,JavaScript 对这些方法的调用,最后都转换为对应 C++ 方法的调用。
类 Document 有这些方法,并不是没有原因的,而是 W3C 组织给出的标准规定的,这个标准就是 DOM(Document Object Model,文档对象模型)。DOM 定义了 DOM 树中每个节点需要实现的接口和属性,下面是 HTMLDocument、Document、HTMLDivElement 的部分 IDL(Interactive Data Language,接口描述语言,与具体平台和语言无关)描述,完整的 IDL 可以参看 W3C 。
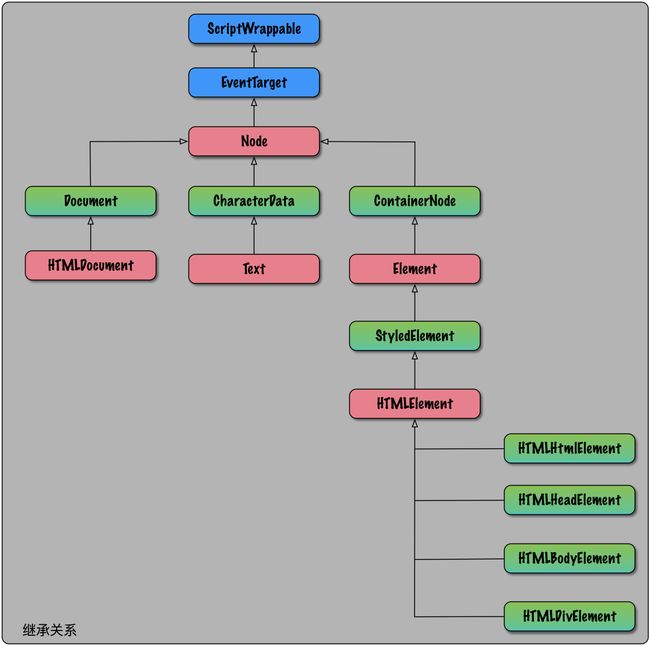
在 DOM 树中,每一个节点都继承自类 Node,同时 Node 还有一个子类 Element,有的节点直接继承自类 Node,比如文本节点,而有的节点继承自类 Element,比如 div 节点。因此针对上面图中的 DOM 树,执行下面的 JavaScript 语句返回的结果是不一样的:
document.childNodes; // 返回子Node集合,返回DocumentType与HTML节点,都继承自Node
document.children; // 返回子Element集合,只返回HTML节点,DocumentType不继承自Element
下图给出部分节点的继承关系图:
二、DOM树构建
DOM 树的构建流程可以分为4个步骤: 解码、分词、创建节点、添加节点。
2.1 解码
渲染进程从网络进程接收过来的是 HTML 字节流,而下一步分词是以字符为单位进行的。由于各种编码规范的存在,比如 ISO-8859-1、UTF-8 等,一个字符常常可能对应一个或者多个编码后的字节,解码的目的就是将 HTML 字节流转换成 HTML 字符流,或者换句话说,就是将原始的 HTML 字节流转换成字符串。

2.1.1 解码类图
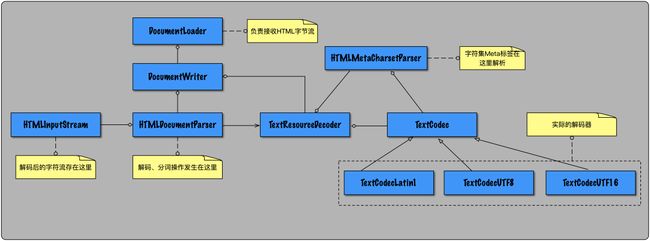
从类图上看,类 HTMLDocumentParser 处于解码的核心位置,由这个类调用解码器将 HTML 字节流解码成字符流,存储到类 HTMLInputStream 中。
2.1.2 解码流程
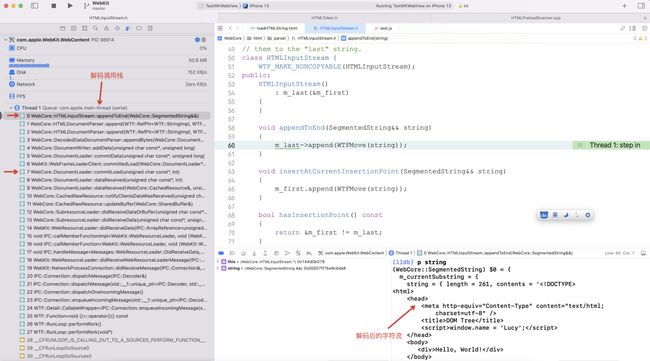
整个解码流程当中,最关健的是如何找到正确的编码方式。只有找到了正确的编码方式,才能使用对应的解码器进行解码。解码发生的地方如下面源代码所示,这个方法在上图第3个栈帧被调用:
// HTMLDocumentParser是DecodedDataDocumentParser的子类
void DecodedDataDocumentParser::appendBytes(DocumentWriter& writer, const uint8_t* data, size_t length)
{
if (!length)
return;
String decoded = writer.decoder().decode(data, length); // 真正解码发生在这里
if (decoded.isEmpty())
return;
writer.reportDataReceived();
append(decoded.releaseImpl());
}
上面代码第7行 writer.decoder() 返回一个 TextResourceDecoder 对象,解码操作由 TextResourceDecoder::decode 方法完成。下面逐步查看 TextResourceDecoder::decode 方法的源码:
// 只保留了最重要的部分
String TextResourceDecoder::decode(const char* data, size_t length)
{
...
// 如果是HTML文件,就从head标签中寻找字符集
if ((m_contentType == HTML || m_contentType == XML) && !m_checkedForHeadCharset) // HTML and XML
if (!checkForHeadCharset(data, length, movedDataToBuffer))
return emptyString();
...
// m_encoding存储者从HTML文件中找到的编码名称
if (!m_codec)
m_codec = newTextCodec(m_encoding); // 创建具体的编码器
...
// 解码并返回
String result = m_codec->decode(m_buffer.data() + lengthOfBOM, m_buffer.size() - lengthOfBOM, false, m_contentType == XML && !m_useLenientXMLDecoding, m_sawError);
m_buffer.clear(); // 清空存储的原始未解码的HTML字节流
return result;
}
从源码中可以看到,TextResourceDecoder 首先从 HTML 的 标签中去找编码方式,因为 标签可以包含 标签, 标签可以设置 HTML 文件的字符集:
DOM Tree
如果能找到对应的字符集,TextResourceDeocder 将其存储在成员变量 m_encoding 当中,并且根据对应的编码创建真正的解码器存储在成员变量 m_codec 中,最终使用 m_codec 对字节流进行解码,并且返回解码后的字符串。如果带有字符集的 标签没有找到,TextResourceDeocder 的 m_encoding 有默认值 windows-1252(等同于ISO-8859-1)。
下面看一下 TextResourceDecoder 寻找 标签中字符集的流程,也就是上面源码中第8行对 checkForHeadCharset 函数的调用:
// 只保留了关健代码
bool TextResourceDecoder::checkForHeadCharset(const char* data, size_t len, bool& movedDataToBuffer)
{
...
// This is not completely efficient, since the function might go
// through the HTML head several times.
size_t oldSize = m_buffer.size();
m_buffer.grow(oldSize + len);
memcpy(m_buffer.data() + oldSize, data, len); // 将字节流数据拷贝到自己的缓存m_buffer里面
movedDataToBuffer = true;
// Continue with checking for an HTML meta tag if we were already doing so.
if (m_charsetParser)
return checkForMetaCharset(data, len); // 如果已经存在了meta标签解析器,直接开始解析
....
m_charsetParser = makeUnique(); // 创建meta标签解析器
return checkForMetaCharset(data, len);
}
上面源代码中第11行,类 TextResourceDecoder 内部存储了需要解码的 HTML 字节流,这一步骤很重要,后面会讲到。先看第17行、21行、22行,这3行主要是使用标签解析器解析字符集,使用了懒加载的方式。下面看下 checkForMetaCharset 这个函数的实现:
bool TextResourceDecoder::checkForMetaCharset(const char* data, size_t length)
{
if (!m_charsetParser->checkForMetaCharset(data, length)) // 解析meta标签字符集
return false;
setEncoding(m_charsetParser->encoding(), EncodingFromMetaTag); // 找到后设置字符编码名称
m_charsetParser = nullptr;
m_checkedForHeadCharset = true;
return true;
}
上面源码第3行可以看到,整个解析 标签的任务在类 HTMLMetaCharsetParser::checkForMetaCharset 中完成。
// 只保留了关健代码
bool HTMLMetaCharsetParser::checkForMetaCharset(const char* data, size_t length)
{
if (m_doneChecking) // 标志位,避免重复解析
return true;
// We still don't have an encoding, and are in the head.
// The following tags are allowed in :
// SCRIPT|STYLE|META|LINK|OBJECT|TITLE|BASE
//
// We stop scanning when a tag that is not permitted in
// is seen, rather when is seen, because that more closely
// matches behavior in other browsers; more details in
// .
//
// Additionally, we ignore things that looks like tags in , <script>
// and <noscript>; see <http://bugs.webkit.org/show_bug.cgi?id=4560>,
// <http://bugs.webkit.org/show_bug.cgi?id=12165> and
// <http://bugs.webkit.org/show_bug.cgi?id=12389>.
//
// Since many sites have charset declarations after <body> or other tags
// that are disallowed in <head>, we don't bail out until we've checked at
// least bytesToCheckUnconditionally bytes of input.
constexpr int bytesToCheckUnconditionally = 1024; // 如果解析了1024个字符还未找到带有字符集的<meta>标签,整个解析也算完成,此时没有解析到正确的字符集,就使用默认编码windows-1252(等同于ISO-8859-1)
bool ignoredSawErrorFlag;
m_input.append(m_codec->decode(data, length, false, false, ignoredSawErrorFlag)); // 对字节流进行解码
while (auto token = m_tokenizer.nextToken(m_input)) { // m_tokenizer进行分词操作,找meta标签也需要进行分词,分词操作后面讲
bool isEnd = token->type() == HTMLToken::EndTag;
if (isEnd || token->type() == HTMLToken::StartTag) {
AtomString tagName(token->name());
if (!isEnd) {
m_tokenizer.updateStateFor(tagName);
if (tagName == metaTag && processMeta(*token)) { // 找到meta标签进行处理
m_doneChecking = true;
return true; // 如果找到了带有编码的meta标签,直接返回
}
}
if (tagName != scriptTag && tagName != noscriptTag
&& tagName != styleTag && tagName != linkTag
&& tagName != metaTag && tagName != objectTag
&& tagName != titleTag && tagName != baseTag
&& (isEnd || tagName != htmlTag)
&& (isEnd || tagName != headTag)) {
m_inHeadSection = false;
}
}
if (!m_inHeadSection && m_input.numberOfCharactersConsumed() >= bytesToCheckUnconditionally) { // 如果分词已经进入了<body>标签范围,同时分词数量已经超过了1024,也算成功
m_doneChecking = true;
return true;
}
}
return false;
}
</code></pre>
<p>上面源码第29行,类 HTMLMetaCharsetParser 也有一个解码器 m_codec,解码器是在 HTMLMetaCharsetParser 对象创建时生成,这个解码器的真实类型是 TextCodecLatin1(Latin1编码也就是ISO-8859-1,等同于windows-1252编码)。之所以可以直接使用 TextCodecLatin1 解码器,是因为 标签如果设置正确,都是英文字符,完全可以使用 TextCodecLatin1 进行解析出来。这样就避免了为了找到 标签,需要对字节流进行解码,而要解码就必须要找到 标签这种鸡生蛋、蛋生鸡的问题。</p>
<p>代码第37行对找到的 标签进行处理,这个函数比较简单,主要是解析 标签当中的属性,然后查看这些属性名中有没有 charset。</p>
<pre><code>bool HTMLMetaCharsetParser::processMeta(HTMLToken& token)
{
AttributeList attributes;
for (auto& attribute : token.attributes()) { // 获取meta标签属性
String attributeName = StringImpl::create8BitIfPossible(attribute.name);
String attributeValue = StringImpl::create8BitIfPossible(attribute.value);
attributes.append(std::make_pair(attributeName, attributeValue));
}
m_encoding = encodingFromMetaAttributes(attributes); // 从属性中找字符集设置属性charset
return m_encoding.isValid();
}
</code></pre>
<p>上面分析 TextResourceDecoder::checkForHeadCharset 函数时,讲过第11行 TextResourceDecoder 类存储 HTML 字节流的操作很重要。原因是可能整个 HTML 字节流里面可能确实没有设置 charset 的 标签,此时 TextResourceDecoder::checkForHeadCharset 函数就要返回 false,导致 TextResourceDecoder::decode 函数返回空字符串,也就是不进行任何解码。是不是这样呢?真实的情况是,在接收HTML字节流整个过程中由于确实没有找到带有 charset 属性的 标签,那么整个接收期间都不会解码。但是完整的 HTML 字节流会被存储在 TextResourceDecoder 的成员变量 m_buffer 里面,当整个 HTML 字节流接收结束的时,会有如下调用栈:</p>
<p><a href="http://img.e-com-net.com/image/info8/d1eb96a567a9491d82fb77585d6277d4.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/d1eb96a567a9491d82fb77585d6277d4.jpg" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第7张图片" width="650" height="295" style="border:1px solid black;"></a></p>
<p>从调用栈可以看到,当 HTML 字节流接收完成,最终会调用 TextResourceDecoder::flush 方法,这个方法会将 TextResourceDecoder 中有 m_buffer 存储的 HTML 字节流进行解码,由于在接收 HTML 字节流期间未成功找到编码方式,因此 m_buffer 里面存储的就是所有待解码的 HTML 字节流,然后在这里使用默认的编码 windows-1252 对全部字节流进行解码。因此,如果 HTML 字节流中包含汉字,那么如果不指定字符集,最终页面就会出现乱码。解码完成后,会将解码之后的字符流存储到 HTMLDocumentParser 中。</p>
<pre><code>void DecodedDataDocumentParser::flush(DocumentWriter& writer)
{
String remainingData = writer.decoder().flush();
if (remainingData.isEmpty())
return;
writer.reportDataReceived();
append(remainingData.releaseImpl()); // 解码后的字符流存储到HTMLDocumentParser
}
</code></pre>
<h3><strong>2.1.3 解码总结</strong></h3>
<p>整个解码过程可以分为两种情形: 第一种情形是 HTML 字节流可以解析出带有 charset 属性的 标签,这样就可以获取相应的编码方式,那么每接收到一个 HML 字节流,都可以使用相应的编码方式进行解码,将解码后的字符流添加到 HTMLInputStream 当中;第二种是 HTML 字节流不能解析带有 charset 属性的 标签,这样每接收到一个 HTML 字节流,都缓存到 TextResourceDecoder 的 m_buffer 缓存,等完整的 HTML 字节流接收完毕,就会使用默认的编码 windows-1252 进行解码。</p>
<p><a href="http://img.e-com-net.com/image/info8/76b9a327ce0d41cca4cb9f404e79e1d7.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/76b9a327ce0d41cca4cb9f404e79e1d7.jpg" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第8张图片" width="650" height="258" style="border:1px solid black;"></a></p>
<p><a href="http://img.e-com-net.com/image/info8/137ad145f13e4b75bba321b3500d3bd9.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/137ad145f13e4b75bba321b3500d3bd9.jpg" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第9张图片" width="650" height="211" style="border:1px solid black;"></a></p>
<h2><strong>2.2 分词</strong></h2>
<p>接收到的 HTML 字节流经过解码,成为存储在 HTMLInputStream 中的字符流。分词的过程就是从 HTMLInputStream 中依次取出每一个字符,然后判断字符是否是特殊的 HTML 字符’ <’、’/’、’>’、’=’ 等。根据这些特殊字符的分割,就能解析出 HTML 标签名以及属性列表,类 HTMLToken 就是存储分词出来的结果。</p>
<h3><strong>2.2.1 分词类图</strong></h3>
<p><a href="http://img.e-com-net.com/image/info8/6fc26a770a66409ab103830a24c7379b.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/6fc26a770a66409ab103830a24c7379b.jpg" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第10张图片" width="650" height="267" style="border:1px solid black;"></a></p>
<p>从类图中可以看到,分词最重要的是类 HTMLTokenizer 和类 HTMLToken。下面是类 HTMLToken 的主要信息:</p>
<pre><code>// 只保留了主要信息
class HTMLToken {
public:
enum Type { // Token的类型
Uninitialized, // Token初始化时的类型
DOCTYPE, // 代表Token是DOCType标签
StartTag, // 代表Token是一个开始标签
EndTag, // 代表Token是一个结束标签
Comment, // 代表Token是一个注释
Character, // 代表Token是文本
EndOfFile, // 代表Token是文件结尾
};
struct Attribute { // 存储属性的数据结构
Vector<UChar, 32> name; // 属性名
Vector<UChar, 64> value; // 属性值
// Used by HTMLSourceTracker.
unsigned startOffset;
unsigned endOffset;
};
typedef Vector<Attribute, 10> AttributeList; // 属性列表
typedef Vector<UChar, 256> DataVector; // 存储Token名
...
private:
Type m_type;
DataVector m_data;
// For StartTag and EndTag
bool m_selfClosing; // Token是注入<img>一样自结束标签
AttributeList m_attributes;
Attribute* m_currentAttribute; // 当前正在解析的属性
};
</code></pre>
<h3><strong>2.2.2 分词流程</strong></h3>
<p><a href="http://img.e-com-net.com/image/info8/14511e832ee34cd8b4233173d27115bc.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/14511e832ee34cd8b4233173d27115bc.jpg" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第11张图片" width="650" height="339" style="border:1px solid black;"></a></p>
<p>上面分词流程中 HTMLDocumentParser::pumpTokenizerLoop 方法是最重要的,从方法名字可以看出这个方法里面包含循环逻辑:</p>
<pre><code>// 只保留关健代码
bool HTMLDocumentParser::pumpTokenizerLoop(SynchronousMode mode, bool parsingFragment, PumpSession& session)
{
do { // 分词循环体开始
...
if (UNLIKELY(mode == AllowYield && m_parserScheduler->shouldYieldBeforeToken(session))) // 避免长时间处于分词循环中,这里根据条件暂时退出循环
return true;
if (!parsingFragment)
m_sourceTracker.startToken(m_input.current(), m_tokenizer);
auto token = m_tokenizer.nextToken(m_input.current()); // 进行分词操作,取出一个token
if (!token)
return false; // 分词没有产生token,就跳出循环
if (!parsingFragment)
m_sourceTracker.endToken(m_input.current(), m_tokenizer);
constructTreeFromHTMLToken(token); // 根据token构建DOM树
} while (!isStopped());
return false;
}
</code></pre>
<p>上面代码中第7行会有一个 yield 退出操作,这是为了避免长时间处于分词循环,占用主线程。当退出条件为真时,会从分词循环中返回,返回值为 true。下面是退出判断代码:</p>
<pre><code>// 只保留关健代码
bool HTMLParserScheduler::shouldYieldBeforeToken(PumpSession& session)
{
...
// numberOfTokensBeforeCheckingForYield是静态变量,定义为4096
// session.processedTokensOnLastCheck表示从上一次退出为止,以及处理过的token个数
// session.didSeeScript表示在分词过程中是否出现过script标签
if (UNLIKELY(session.processedTokens > session.processedTokensOnLastCheck + numberOfTokensBeforeCheckingForYield || session.didSeeScript))
return checkForYield(session);
++session.processedTokens;
return false;
}
bool HTMLParserScheduler::checkForYield(PumpSession& session)
{
session.processedTokensOnLastCheck = session.processedTokens;
session.didSeeScript = false;
Seconds elapsedTime = MonotonicTime::now() - session.startTime;
return elapsedTime > m_parserTimeLimit; // m_parserTimeLimit的值默认是500ms,从分词开始超过500ms就要先yield
}
</code></pre>
<p>如果命中了上面的 yield 退出条件,那么什么时候再次进入分词呢?下面的代码展示了再次进入分词的过程:</p>
<pre><code>// 保留关键代码
void HTMLDocumentParser::pumpTokenizer(SynchronousMode mode)
{
...
if (shouldResume) // 从pumpTokenizerLoop中yield退出时返回值为true
m_parserScheduler->scheduleForResume();
}
void HTMLParserScheduler::scheduleForResume()
{
ASSERT(!m_suspended);
m_continueNextChunkTimer.startOneShot(0_s); // 触发timer(0s后触发),触发后的响应函数为HTMLParserScheduler::continueNextChunkTimerFired
}
// 保留关健代码
void HTMLParserScheduler::continueNextChunkTimerFired()
{
...
m_parser.resumeParsingAfterYield(); // 重新Resume分词过程
}
void HTMLDocumentParser::resumeParsingAfterYield()
{
// pumpTokenizer can cause this parser to be detached from the Document,
// but we need to ensure it isn't deleted yet.
Ref<HTMLDocumentParser> protectedThis(*this);
// We should never be here unless we can pump immediately.
// Call pumpTokenizer() directly so that ASSERTS will fire if we're wrong.
pumpTokenizer(AllowYield); // 重新进入分词过程,该函数会调用pumpTokenizerLoop
endIfDelayed();
}
</code></pre>
<p>从上面代码可以看出,再次进入分词过程是通过触发一个 Timer 来实现的,虽然这个 Timer 在0s后触发,但是并不意味着 Timer 的响应函数会立刻执行。如果在此之前主线程已经有其他任务到达了执行时机,会有被执行的机会。</p>
<p>继续看 HTMLDocumentParser::pumpTokenizerLoop 函数的第13行,这一行进行分词操作,从解码后的字符流中分出一个 token。实现分词的代码位于 HTMLTokenizer::processToken:</p>
<pre><code>// 只保留关键代码
bool HTMLTokenizer::processToken(SegmentedString& source)
{
...
if (!m_preprocessor.peek(source, isNullCharacterSkippingState(m_state))) // 取出source内部指向的字符,赋给m_nextInputCharacter
return haveBufferedCharacterToken();
UChar character = m_preprocessor.nextInputCharacter(); // 获取character
// https://html.spec.whatwg.org/#tokenization
switch (m_state) { // 进行状态转换,m_state初始值为DataState
...
}
return false;
}
</code></pre>
<p>这个方法由于内部要做很多状态转换,总共有1200多行,后面会有4个例子来解释状态转换的逻辑。</p>
<p>首先来看 InputStreamPreprocessor::peek 方法:</p>
<pre><code>// Returns whether we succeeded in peeking at the next character.
// The only way we can fail to peek is if there are no more
// characters in |source| (after collapsing \r\n, etc).
ALWAYS_INLINE bool InputStreamPreprocessor::peek(SegmentedString& source, bool skipNullCharacters = false)
{
if (UNLIKELY(source.isEmpty()))
return false;
m_nextInputCharacter = source.currentCharacter(); // 获取字符流source内部指向的当前字符
// Every branch in this function is expensive, so we have a
// fast-reject branch for characters that don't require special
// handling. Please run the parser benchmark whenever you touch
// this function. It's very hot.
constexpr UChar specialCharacterMask = '\n' | '\r' | '\0';
if (LIKELY(m_nextInputCharacter & ~specialCharacterMask)) {
m_skipNextNewLine = false;
return true;
}
return processNextInputCharacter(source, skipNullCharacters); // 跳过空字符,将\r\n换行符合并成\n
}
bool InputStreamPreprocessor::processNextInputCharacter(SegmentedString& source, bool skipNullCharacters)
{
ProcessAgain:
ASSERT(m_nextInputCharacter == source.currentCharacter());
// 针对\r\n换行符,下面if语句处理\r字符并且设置m_skipNextNewLine=true,后面处理\n就直接忽略
if (m_nextInputCharacter == '\n' && m_skipNextNewLine) {
m_skipNextNewLine = false;
source.advancePastNewline(); // 向前移动字符
if (source.isEmpty())
return false;
m_nextInputCharacter = source.currentCharacter();
}
// 如果是\r\n连续的换行符,那么第一次遇到\r字符,将\r字符替换成\n字符,同时设置标志m_skipNextNewLine=true
if (m_nextInputCharacter == '\r') {
m_nextInputCharacter = '\n';
m_skipNextNewLine = true;
return true;
}
m_skipNextNewLine = false;
if (m_nextInputCharacter || isAtEndOfFile(source))
return true;
// 跳过空字符
if (skipNullCharacters && !m_tokenizer.neverSkipNullCharacters()) {
source.advancePastNonNewline();
if (source.isEmpty())
return false;
m_nextInputCharacter = source.currentCharacter();
goto ProcessAgain; // 跳转到开头
}
m_nextInputCharacter = replacementCharacter;
return true;
}
</code></pre>
<p>由于 peek 方法会跳过空字符,同时合并 \r\n 字符为 \n 字符,所以一个字符流 source 如果包含了空格或者 \r\n 换行符,实际上处理起来如下图所示:</p>
<p><a href="http://img.e-com-net.com/image/info8/f1dd90b760d3477bac4826e680043dc8.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/f1dd90b760d3477bac4826e680043dc8.jpg" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第12张图片" width="650" height="173" style="border:1px solid black;"></a></p>
<p>HTMLTokenizer::processToken 内部定义了一个状态机,下面以四种情形来进行解释。</p>
<p><strong>Case1:标签</strong></p>
<pre><code>BEGIN_STATE(DataState) // 刚开始解析是DataState状态if (character == '&') ADVANCE_PAST_NON_NEWLINE_TO(CharacterReferenceInDataState);if (character == '<') {// 整个字符流一开始是'<',那么表示是一个标签的开始if (haveBufferedCharacterToken()) RETURN_IN_CURRENT_STATE(true); ADVANCE_PAST_NON_NEWLINE_TO(TagOpenState); // 跳转到TagOpenState状态,并取去下一个字符是'!" }if (character == kEndOfFileMarker)return emitEndOfFile(source); bufferCharacter(character); ADVANCE_TO(DataState);END_STATE()// ADVANCE_PAST_NON_NEWLINE_TO定义#define ADVANCE_PAST_NON_NEWLINE_TO(newState) \do { \if (!m_preprocessor.advancePastNonNewline(source, isNullCharacterSkippingState(newState))) { \ // 如果往下移动取不到下一个字符 m_state = newState; \ // 保存状态return haveBufferedCharacterToken(); \ // 返回 } \ character = m_preprocessor.nextInputCharacter(); \ // 先取出下一个字符 goto newState; \ // 跳转到指定状态 } while (false)BEGIN_STATE(TagOpenState)if (character == '!') // 满足此条件 ADVANCE_PAST_NON_NEWLINE_TO(MarkupDeclarationOpenState); // 同理,跳转到MarkupDeclarationOpenState状态,并且取出下一个字符'D'if (character == '/') ADVANCE_PAST_NON_NEWLINE_TO(EndTagOpenState);if (isASCIIAlpha(character)) { m_token.beginStartTag(convertASCIIAlphaToLower(character)); ADVANCE_PAST_NON_NEWLINE_TO(TagNameState); }if (character == '?') { parseError();// The spec consumes the current character before switching// to the bogus comment state, but it's easier to implement// if we reconsume the current character. RECONSUME_IN(BogusCommentState); } parseError(); bufferASCIICharacter('<'); RECONSUME_IN(DataState);END_STATE()BEGIN_STATE(MarkupDeclarationOpenState)if (character == '-') { auto result = source.advancePast("--");if (result == SegmentedString::DidMatch) { m_token.beginComment(); SWITCH_TO(CommentStartState); }if (result == SegmentedString::NotEnoughCharacters) RETURN_IN_CURRENT_STATE(haveBufferedCharacterToken()); } else if (isASCIIAlphaCaselessEqual(character, 'd')) { // 由于character == 'D',满足此条件 auto result = source.advancePastLettersIgnoringASCIICase("doctype"); // 看解码后的字符流中是否有完整的"doctype"if (result == SegmentedString::DidMatch) SWITCH_TO(DOCTYPEState); // 如果匹配,则跳转到DOCTYPEState,同时取出当前指向的字符,由于上面source字符流已经移动了"doctype",因此此时取出的字符为'>'if (result == SegmentedString::NotEnoughCharacters) // 如果不匹配 RETURN_IN_CURRENT_STATE(haveBufferedCharacterToken()); // 保存状态,直接返回 } else if (character == '[' && shouldAllowCDATA()) { auto result = source.advancePast("[CDATA[");if (result == SegmentedString::DidMatch) SWITCH_TO(CDATASectionState);if (result == SegmentedString::NotEnoughCharacters) RETURN_IN_CURRENT_STATE(haveBufferedCharacterToken()); } parseError(); RECONSUME_IN(BogusCommentState);END_STATE()#define SWITCH_TO(newState) \do { \if (!m_preprocessor.peek(source, isNullCharacterSkippingState(newState))) { \ m_state = newState; \return haveBufferedCharacterToken(); \ } \ character = m_preprocessor.nextInputCharacter(); \ // 取出下一个字符 goto newState; \ // 跳转到指定的state } while (false)#define RETURN_IN_CURRENT_STATE(expression) \do { \ m_state = currentState; \ // 保存当前状态return expression; \ } while (false)BEGIN_STATE(DOCTYPEState)if (isTokenizerWhitespace(character)) ADVANCE_TO(BeforeDOCTYPENameState);if (character == kEndOfFileMarker) { parseError(); m_token.beginDOCTYPE(); m_token.setForceQuirks();return emitAndReconsumeInDataState(); } parseError(); RECONSUME_IN(BeforeDOCTYPENameState);END_STATE()#define RECONSUME_IN(newState) \do { \ // 直接跳转到指定state goto newState; \ } while (false) BEGIN_STATE(BeforeDOCTYPENameState)if (isTokenizerWhitespace(character)) ADVANCE_TO(BeforeDOCTYPENameState);if (character == '>') { // character == '>',匹配此处,到此DOCTYPE标签匹配完毕 parseError(); m_token.beginDOCTYPE(); m_token.setForceQuirks();return emitAndResumeInDataState(source); }if (character == kEndOfFileMarker) { parseError(); m_token.beginDOCTYPE(); m_token.setForceQuirks();return emitAndReconsumeInDataState(); } m_token.beginDOCTYPE(toASCIILower(character)); ADVANCE_PAST_NON_NEWLINE_TO(DOCTYPENameState);END_STATE()inline bool HTMLTokenizer::emitAndResumeInDataState(SegmentedString& source){ saveEndTagNameIfNeeded(); m_state = DataState; // 重置状态为初始状态DataState source.advancePastNonNewline(); // 移动到下一个字符return true;}
</code></pre>
<p>DOCTYPE Token 经历了6个状态最终被解析出来,整个过程如下图所示:</p>
<p><a href="http://img.e-com-net.com/image/info8/dd63b25ed32648baa533444a8ed8765c.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/dd63b25ed32648baa533444a8ed8765c.jpg" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第13张图片" width="650" height="228" style="border:1px solid black;"></a></p>
<p>当 Token 解析完毕之后,分词状态又被重置为 DataState,同时需要注意的时,此时字符流 source 内部指向的是下一个字符 ‘<’。</p>
<p>上面代码第61行在用字符流 source 匹配字符串 “doctype” 时,可能出现匹配不上的情形。为什么会这样呢?这是因为整个 DOM 树的构建流程,并不是先要解码完成,解码完成之后获取到完整的字符流才进行分词。从前面解码可以知道,解码可能是一边接收字节流,一边进行解码的,因此分词也是这样,只要能解码出一段字符流,就会立即进行分词。整个流程会出现如下图所示:</p>
<p><a href="http://img.e-com-net.com/image/info8/3746d0740ec94cc9b8aa6b4da3919579.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/3746d0740ec94cc9b8aa6b4da3919579.jpg" alt="图片" width="650" height="72"></a></p>
<p>由于这个原因,用来分词的字符流可能是不完整的。对于出现不完整情形的 DOCTYPE 分词过程如下图所示:</p>
<p><a href="http://img.e-com-net.com/image/info8/01d338cabe1b4bb180ddecab0e8df315.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/01d338cabe1b4bb180ddecab0e8df315.jpg" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第14张图片" width="650" height="513" style="border:1px solid black;"></a></p>
<p>上面介绍了解码、分词、解码、分词处理 DOCTYPE 标签的情形,可以看到从逻辑上这种情形与完整解码再分词是一样的。后续介绍时都会只针对完整解码再分词的情形,对于一边解码一边分词的情形,只需要正确的认识 source 字符流内部指针的移动,并不难分析。</p>
<p><strong>Case2:标签</strong></p> 标签的分词过程和 类似,其相关代码如下:
<pre><code>BEGIN_STATE(TagOpenState)
if (character == '!')
ADVANCE_PAST_NON_NEWLINE_TO(MarkupDeclarationOpenState);
if (character == '/')
ADVANCE_PAST_NON_NEWLINE_TO(EndTagOpenState);
if (isASCIIAlpha(character)) { // 在开标签状态下,当前字符为'h'
m_token.beginStartTag(convertASCIIAlphaToLower(character)); // 将'h'添加到Token名中
ADVANCE_PAST_NON_NEWLINE_TO(TagNameState); // 跳转到TagNameState,并移动到下一个字符't'
}
if (character == '?') {
parseError();
// The spec consumes the current character before switching
// to the bogus comment state, but it's easier to implement
// if we reconsume the current character.
RECONSUME_IN(BogusCommentState);
}
parseError();
bufferASCIICharacter('<');
RECONSUME_IN(DataState);
END_STATE()
BEGIN_STATE(TagNameState)
if (isTokenizerWhitespace(character))
ADVANCE_TO(BeforeAttributeNameState);
if (character == '/')
ADVANCE_PAST_NON_NEWLINE_TO(SelfClosingStartTagState);
if (character == '>') // 在这个状态下遇到起始标签终止字符
return emitAndResumeInDataState(source); // 当前分词结束,重置分词状态为DataState
if (m_options.usePreHTML5ParserQuirks && character == '<')
return emitAndReconsumeInDataState();
if (character == kEndOfFileMarker) {
parseError();
RECONSUME_IN(DataState);
}
m_token.appendToName(toASCIILower(character)); // 将当前字符添加到Token名
ADVANCE_PAST_NON_NEWLINE_TO(TagNameState); // 继续跳转到当前状态,并移动到下一个字符
END_STATE()
</code></pre>
<p><a href="http://img.e-com-net.com/image/info8/9eb01b4a24e14b7592db9de6fbb6b8d5.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/9eb01b4a24e14b7592db9de6fbb6b8d5.jpg" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第15张图片" width="650" height="272" style="border:1px solid black;"></a></p>
<p><strong>Case3:带有属性的标签 </strong></p>
<div></div>
<p></p>
<p>HTML 标签可以带有属性,属性由属性名和属性值组成,属性之间以及属性与标签名之间用空格分隔:</p>
<pre><code><!-- div标签有两个属性,属性名为class和align,它们的值都带有引号 -->
<div class="news" align="center">Hello,World!</div>
<!-- 属性值也可以不带引号 -->
<div class=news align=center>Hello,World!</div>
</code></pre>
<p>整个 </p>
<div>
标签的解析中,标签名 div 的解析流程和上面的 标签解析一样,当在解析标签名的过程中,碰到了空白字符,说明要开始解析属性了,下面是相关代码:
</div>
<p></p>
<pre><code>BEGIN_STATE(TagNameState)if (isTokenizerWhitespace(character)) // 在解析TagName时遇到空白字符,标志属性开始 ADVANCE_TO(BeforeAttributeNameState);if (character == '/') ADVANCE_PAST_NON_NEWLINE_TO(SelfClosingStartTagState);if (character == '>')return emitAndResumeInDataState(source);if (m_options.usePreHTML5ParserQuirks && character == '<')return emitAndReconsumeInDataState();if (character == kEndOfFileMarker) { parseError(); RECONSUME_IN(DataState); } m_token.appendToName(toASCIILower(character)); ADVANCE_PAST_NON_NEWLINE_TO(TagNameState);END_STATE()#define ADVANCE_TO(newState) \do { \if (!m_preprocessor.advance(source, isNullCharacterSkippingState(newState))) { \ // 移动到下一个字符 m_state = newState; \return haveBufferedCharacterToken(); \ } \ character = m_preprocessor.nextInputCharacter(); \ goto newState; \ // 跳转到指定状态 } while (false)BEGIN_STATE(BeforeAttributeNameState)if (isTokenizerWhitespace(character)) // 如果标签名后有连续空格,那么就不停的跳过,在当前状态不停循环 ADVANCE_TO(BeforeAttributeNameState);if (character == '/') ADVANCE_PAST_NON_NEWLINE_TO(SelfClosingStartTagState);if (character == '>')return emitAndResumeInDataState(source);if (m_options.usePreHTML5ParserQuirks && character == '<')return emitAndReconsumeInDataState();if (character == kEndOfFileMarker) { parseError(); RECONSUME_IN(DataState); }if (character == '"' || character == '\'' || character == '<' || character == '=') parseError(); m_token.beginAttribute(source.numberOfCharactersConsumed()); // Token的属性列表增加一个,用来存放新的属性名与属性值 m_token.appendToAttributeName(toASCIILower(character)); // 添加属性名 ADVANCE_PAST_NON_NEWLINE_TO(AttributeNameState); // 跳转到AttributeNameState,并且移动到下一个字符END_STATE()BEGIN_STATE(AttributeNameState)if (isTokenizerWhitespace(character)) ADVANCE_TO(AfterAttributeNameState);if (character == '/') ADVANCE_PAST_NON_NEWLINE_TO(SelfClosingStartTagState);if (character == '=') ADVANCE_PAST_NON_NEWLINE_TO(BeforeAttributeValueState); // 在解析属性名的过程中如果碰到=,说明属性名结束,属性值就要开始if (character == '>')return emitAndResumeInDataState(source);if (m_options.usePreHTML5ParserQuirks && character == '<')return emitAndReconsumeInDataState();if (character == kEndOfFileMarker) { parseError(); RECONSUME_IN(DataState); }if (character == '"' || character == '\'' || character == '<' || character == '=') parseError(); m_token.appendToAttributeName(toASCIILower(character)); ADVANCE_PAST_NON_NEWLINE_TO(AttributeNameState);END_STATE()BEGIN_STATE(BeforeAttributeValueState)if (isTokenizerWhitespace(character)) ADVANCE_TO(BeforeAttributeValueState);if (character == '"') ADVANCE_PAST_NON_NEWLINE_TO(AttributeValueDoubleQuotedState); // 有的属性值有引号包围,这里跳转到AttributeValueDoubleQuotedState,并移动到下一个字符if (character == '&') RECONSUME_IN(AttributeValueUnquotedState);if (character == '\'') ADVANCE_PAST_NON_NEWLINE_TO(AttributeValueSingleQuotedState);if (character == '>') { parseError();return emitAndResumeInDataState(source); }if (character == kEndOfFileMarker) { parseError(); RECONSUME_IN(DataState); }if (character == '<' || character == '=' || character == '`') parseError(); m_token.appendToAttributeValue(character); // 有的属性值没有引号包围,添加属性值字符到Token ADVANCE_PAST_NON_NEWLINE_TO(AttributeValueUnquotedState); // 跳转到AttributeValueUnquotedState,并移动到下一个字符END_STATE()BEGIN_STATE(AttributeValueDoubleQuotedState)if (character == '"') { // 在当前状态下如果遇到引号,说明属性值结束 m_token.endAttribute(source.numberOfCharactersConsumed()); // 结束属性解析 ADVANCE_PAST_NON_NEWLINE_TO(AfterAttributeValueQuotedState); // 跳转到AfterAttributeValueQuotedState,并移动到下一个字符 }if (character == '&') { m_additionalAllowedCharacter = '"'; ADVANCE_PAST_NON_NEWLINE_TO(CharacterReferenceInAttributeValueState); }if (character == kEndOfFileMarker) { parseError(); m_token.endAttribute(source.numberOfCharactersConsumed()); RECONSUME_IN(DataState); } m_token.appendToAttributeValue(character); // 将属性值字符添加到Token ADVANCE_TO(AttributeValueDoubleQuotedState); // 跳转到当前状态END_STATE()BEGIN_STATE(AfterAttributeValueQuotedState)if (isTokenizerWhitespace(character)) ADVANCE_TO(BeforeAttributeNameState); // 属性值解析完毕,如果后面继续跟着空白字符,说明后续还有属性要解析,调回到BeforeAttributeNameStateif (character == '/') ADVANCE_PAST_NON_NEWLINE_TO(SelfClosingStartTagState);if (character == '>')return emitAndResumeInDataState(source); // 属性值解析完毕,如果遇到'>'字符,说明整个标签也要解析完毕了,此时结束当前标签解析,并且重置分词状态为DataState,并移动到下一个字符if (m_options.usePreHTML5ParserQuirks && character == '<')return emitAndReconsumeInDataState();if (character == kEndOfFileMarker) { parseError(); RECONSUME_IN(DataState); } parseError(); RECONSUME_IN(BeforeAttributeNameState);END_STATE()BEGIN_STATE(AttributeValueUnquotedState)if (isTokenizerWhitespace(character)) { // 当解析不带引号的属性值时遇到空白字符(这与带引号的属性值不一样,带引号的属性值可以包含空白字符),说明当前属性解析完毕,后面还有其他属性,跳转到BeforeAttributeNameState,并且移动到下一个字符 m_token.endAttribute(source.numberOfCharactersConsumed()); ADVANCE_TO(BeforeAttributeNameState); }if (character == '&') { m_additionalAllowedCharacter = '>'; ADVANCE_PAST_NON_NEWLINE_TO(CharacterReferenceInAttributeValueState); }if (character == '>') { // 解析过程中如果遇到'>'字符,说明整个标签也要解析完毕了,此时结束当前标签解析,并且重置分词状态为DataState,并移动到下一个字符 m_token.endAttribute(source.numberOfCharactersConsumed());return emitAndResumeInDataState(source); }if (character == kEndOfFileMarker) { parseError(); m_token.endAttribute(source.numberOfCharactersConsumed()); RECONSUME_IN(DataState); }if (character == '"' || character == '\'' || character == '<' || character == '=' || character == '`') parseError(); m_token.appendToAttributeValue(character); // 将遇到的属性值字符添加到Token ADVANCE_PAST_NON_NEWLINE_TO(AttributeValueUnquotedState); // 跳转到当前状态,并且移动到下一个字符END_STATE()
</code></pre>
<p>从代码中可以看到,当属性值带引号和不带引号时,解析的逻辑是不一样的。当属性值带有引号时,属性值里面是可以包含空白字符的。如果属性值不带引号,那么一旦碰到空白字符,说明这个属性就解析结束了,会进入下一个属性的解析当中。</p>
<p><a href="http://img.e-com-net.com/image/info8/b492d0814e7649a482700c56724a975e.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/b492d0814e7649a482700c56724a975e.jpg" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第16张图片" width="650" height="925" style="border:1px solid black;"></a></p>
<p><strong>Case4:纯文本解析</strong></p>
<p>这里的纯文本指起始标签与结束标签之间的任何纯文字,包括脚本文、CSS 文本等等,如下所示:</p>
<pre><code><!-- div标签中的纯文本 Hello,Word! -->
<div class=news align=center>Hello,World!</div>
<!-- script标签中的纯文本 window.name = 'Lucy'; -->
<script>window.name = 'Lucy';</script>
</code></pre>
<p>纯文本的解析过程比较简单,就是不停的在 DataState 状态上跳转,缓存遇到的字符,直到遇见一个结束标签的 ‘<’ 字符,相关代码如下:</p>
<pre><code>BEGIN_STATE(DataState)
if (character == '&')
ADVANCE_PAST_NON_NEWLINE_TO(CharacterReferenceInDataState);
if (character == '<') { // 如果在解析文本的过程中遇到开标签,分两种情况
if (haveBufferedCharacterToken()) // 第一种,如果缓存了文本字符就直接按当前DataState返回,并不移动字符,所以下次再进入分词操作时取到的字符仍为'<'
RETURN_IN_CURRENT_STATE(true);
ADVANCE_PAST_NON_NEWLINE_TO(TagOpenState); // 第二种,如果没有缓存任何文本字符,直接进入TagOpenState状态,进入到起始标签解析过程,并且移动下一个字符
}
if (character == kEndOfFileMarker)
return emitEndOfFile(source);
bufferCharacter(character); // 缓存遇到的字符
ADVANCE_TO(DataState); // 循环跳转到当前DataState状态,并且移动到下一个字符
END_STATE()
</code></pre>
<p>由于流程比较简单,下面只给出解析div标签中纯文本的结果:</p>
<p><a href="http://img.e-com-net.com/image/info8/a2db77ca588f424c93025819ce8f990f.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/a2db77ca588f424c93025819ce8f990f.jpg" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第17张图片" width="650" height="173" style="border:1px solid black;"></a></p>
<h3><strong>2.3 创建节点与添加节点</strong></h3>
<h3><strong>2.3.1 相关类图</strong></h3>
<p><strong><a href="http://img.e-com-net.com/image/info8/333ea5b648e640d089e2bf9224e39347.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/333ea5b648e640d089e2bf9224e39347.jpg" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第18张图片" width="650" height="354" style="border:1px solid black;"></a></strong></p>
<h3><strong>2.3.2 创建、添加流程</strong></h3>
<p>上面的分词循环中,每分出一个 Token,就会根据 Token 创建对应的 Node,然后将 Node 添加到 DOM 树上(HTMLDocumentParser::pumpTokenizerLoop 方法在上面分词中有介绍)。</p>
<p><a href="http://img.e-com-net.com/image/info8/e97a4286c6964227a741c15c7ff947d9.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/e97a4286c6964227a741c15c7ff947d9.jpg" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第19张图片" width="650" height="347" style="border:1px solid black;"></a></p>
<p>上面方法中首先看 HTMLTreeBuilder::constructTree,代码如下:</p>
<pre><code>// 只保留关健代码
void HTMLTreeBuilder::constructTree(AtomHTMLToken&& token)
{
...
if (shouldProcessTokenInForeignContent(token))
processTokenInForeignContent(WTFMove(token));
else
processToken(WTFMove(token)); // HTMLToken在这里被处理
...
m_tree.executeQueuedTasks(); // HTMLContructionSiteTask在这里被执行,有时候也直接在创建的过程中直接执行,然后这个方法发现队列为空就会直接返回
// The tree builder might have been destroyed as an indirect result of executing the queued tasks.
}
void HTMLConstructionSite::executeQueuedTasks()
{
if (m_taskQueue.isEmpty()) // 队列为空,就直接返回
return;
// Copy the task queue into a local variable in case executeTask
// re-enters the parser.
TaskQueue queue = WTFMove(m_taskQueue);
for (auto& task : queue) // 这里的task就是HTMLContructionSiteTask
executeTask(task); // 执行task
// We might be detached now.
}
</code></pre>
<p>上面代码中 HTMLTreeBuilder::processToken 就是处理 Token 生成对应 Node 的地方,代码如下所示:</p>
<pre><code>void HTMLTreeBuilder::processToken(AtomHTMLToken&& token)
{
switch (token.type()) {
case HTMLToken::Uninitialized:
ASSERT_NOT_REACHED();
break;
case HTMLToken::DOCTYPE: // HTML中的DOCType标签
m_shouldSkipLeadingNewline = false;
processDoctypeToken(WTFMove(token));
break;
case HTMLToken::StartTag: // 起始HTML标签
m_shouldSkipLeadingNewline = false;
processStartTag(WTFMove(token));
break;
case HTMLToken::EndTag: // 结束HTML标签
m_shouldSkipLeadingNewline = false;
processEndTag(WTFMove(token));
break;
case HTMLToken::Comment: // HTML中的注释
m_shouldSkipLeadingNewline = false;
processComment(WTFMove(token));
return;
case HTMLToken::Character: // HTML中的纯文本
processCharacter(WTFMove(token));
break;
case HTMLToken::EndOfFile: // HTML结束标志
m_shouldSkipLeadingNewline = false;
processEndOfFile(WTFMove(token));
break;
}
}
</code></pre>
<p>可以看到上面代码对7类 Token 做了处理,由于处理的流程都是类似的,这里分析5 个节点case的创建添加过程,分别是 <strong><!DOCTYPE> 标签, 起始标签, 起始标签,</strong> 文本,<strong><title> 结束标签,剩下的过程都使用图表示。</p>
<p>Case1:!DOCTYPE 标签</p>
<pre><code>// 只保留关健代码
void HTMLTreeBuilder::processDoctypeToken(AtomHTMLToken&& token)
{
ASSERT(token.type() == HTMLToken::DOCTYPE);
if (m_insertionMode == InsertionMode::Initial) { // m_insertionMode的初始值就是InsertionMode::Initial
m_tree.insertDoctype(WTFMove(token)); // 插入DOCTYPE标签
m_insertionMode = InsertionMode::BeforeHTML; // 插入DOCTYPE标签之后,m_insertionMode设置为InsertionMode::BeforeHTML,表示下面要开是HTML标签插入
return;
}
...
}
// 只保留关健代码
void HTMLConstructionSite::insertDoctype(AtomHTMLToken&& token)
{
...
// m_attachmentRoot就是Document对象,文档根节点
// DocumentType::create方法创建出DOCTYPE节点
// attachLater方法内部创建出HTMLContructionSiteTask
attachLater(m_attachmentRoot, DocumentType::create(m_document, token.name(), publicId, systemId));
...
}
// 只保留关健代码
void HTMLConstructionSite::attachLater(ContainerNode& parent, Ref<Node>&& child, bool selfClosing)
{
...
HTMLConstructionSiteTask task(HTMLConstructionSiteTask::Insert); // 创建HTMLConstructionSiteTask
task.parent = &parent; // task持有当前节点的父节点
task.child = WTFMove(child); // task持有需要操作的节点
task.selfClosing = selfClosing; // 是否自关闭节点
// Add as a sibling of the parent if we have reached the maximum depth allowed.
// m_openElements就是HTMLElementStack,在这里还看不到它的作用,后面会讲。这里可以看到这个stack里面加入的对象个数是有限制的,最大不超过512个。
// 所以如果一个HTML标签嵌套过多的子标签,就会触发这里的操作
if (m_openElements.stackDepth() > m_maximumDOMTreeDepth && task.parent->parentNode())
task.parent = task.parent->parentNode(); // 满足条件,就会将当前节点添加到爷爷节点,而不是父节点
ASSERT(task.parent);
m_taskQueue.append(WTFMove(task)); // 将task添加到Queue当中
}
</code></pre>
<p>从代码可以看到,这里只是创建了 DOCTYPE 节点,还没有真正添加。真正执行添加的操作,需要执行 HTMLContructionSite::executeQueuedTasks,这个方法在一开始有列出来。下面就来看下每个 Task 如何被执行。</p>
<pre><code>// 方法位于HTMLContructionSite.cpp
static inline void executeTask(HTMLConstructionSiteTask& task)
{
switch (task.operation) { // HTMLConstructionSiteTask存储了自己要做的操作,构建DOM树一般都是Insert操作
case HTMLConstructionSiteTask::Insert:
executeInsertTask(task); // 这里执行insert操作
return;
// All the cases below this point are only used by the adoption agency.
case HTMLConstructionSiteTask::InsertAlreadyParsedChild:
executeInsertAlreadyParsedChildTask(task);
return;
case HTMLConstructionSiteTask::Reparent:
executeReparentTask(task);
return;
case HTMLConstructionSiteTask::TakeAllChildrenAndReparent:
executeTakeAllChildrenAndReparentTask(task);
return;
}
ASSERT_NOT_REACHED();
}
// 只保留关健代码,方法位于HTMLContructionSite.cpp
static inline void executeInsertTask(HTMLConstructionSiteTask& task)
{
ASSERT(task.operation == HTMLConstructionSiteTask::Insert);
insert(task); // 继续调用插入方法
...
}
// 只保留关健代码,方法位于HTMLContructionSite.cpp
static inline void insert(HTMLConstructionSiteTask& task)
{
...
ASSERT(!task.child->parentNode());
if (task.nextChild)
task.parent->parserInsertBefore(*task.child, *task.nextChild);
else
task.parent->parserAppendChild(*task.child); // 调用父节点方法继续插入
}
// 只保留关健代码
void ContainerNode::parserAppendChild(Node& newChild)
{
...
executeNodeInsertionWithScriptAssertion(*this, newChild, ChildChange::Source::Parser, ReplacedAllChildren::No, [&] {
if (&document() != &newChild.document())
document().adoptNode(newChild);
appendChildCommon(newChild); // 在Block回调中调用此方法继续插入
...
});
}
// 最终调用的是这个方法进行插入
void ContainerNode::appendChildCommon(Node& child)
{
ScriptDisallowedScope::InMainThread scriptDisallowedScope;
child.setParentNode(this);
if (m_lastChild) { // 父节点已经插入子节点,运行在这里
child.setPreviousSibling(m_lastChild);
m_lastChild->setNextSibling(&child);
} else
m_firstChild = &child; // 如果父节点是首次插入子节点,运行在这里
m_lastChild = &child; // 更新m_lastChild
}
</code></pre>
<p>经过执行上面方法之后,原来只有一个根节点的 DOM 树变成了下面的样子:</p>
<p><a href="http://img.e-com-net.com/image/info8/0250e61b61d14ca7abd538f0b7c10408.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/0250e61b61d14ca7abd538f0b7c10408.jpg" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第20张图片" width="650" height="270" style="border:1px solid black;"></a></p>
<p><strong>Case2:html 起始标签</strong></p>
<pre><code>// processStartTag内部有很多状态处理,这里只保留关健代码
void HTMLTreeBuilder::processStartTag(AtomHTMLToken&& token)
{
ASSERT(token.type() == HTMLToken::StartTag);
switch (m_insertionMode) {
case InsertionMode::Initial:
defaultForInitial();
ASSERT(m_insertionMode == InsertionMode::BeforeHTML);
FALLTHROUGH;
case InsertionMode::BeforeHTML:
if (token.name() == htmlTag) { // html标签在这里处理
m_tree.insertHTMLHtmlStartTagBeforeHTML(WTFMove(token));
m_insertionMode = InsertionMode::BeforeHead; // 插入完html标签,m_insertionMode = InsertionMode::BeforeHead,表明即将处理head标签
return;
}
...
}
}
// 只保留关健代码
void HTMLConstructionSite::insertHTMLHtmlStartTagBeforeHTML(AtomHTMLToken&& token)
{
auto element = HTMLHtmlElement::create(m_document); // 创建html节点
setAttributes(element, token, m_parserContentPolicy);
attachLater(m_attachmentRoot, element.copyRef()); // 同样调用了attachLater方法,与DOCTYPE类似
m_openElements.pushHTMLHtmlElement(HTMLStackItem::create(element.copyRef(), WTFMove(token))); // 注意这里,这里向HTMLElementStack中压入了正在插入的html起始标签
executeQueuedTasks(); // 这里在插入操作直接执行了task,外面HTMLTreeBuilder::constructTree方法调用的executeQueuedTasks方法就会直接返回
...
}
</code></pre>
<p>执行上面代码之后,DOM 树变成了如下图所示:</p>
<p><a href="http://img.e-com-net.com/image/info8/b252c4d43d6448f7ba1920c572c9554a.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/b252c4d43d6448f7ba1920c572c9554a.jpg" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第21张图片" width="650" height="175" style="border:1px solid black;"></a></p>
<p><strong>Case3:title 起始标签</strong></p>
<p>当插入 起始标签之后,DOM 树以及 HTMLElementStack m_openElements 如下图所示:</p>
<p><a href="http://img.e-com-net.com/image/info8/9096ab52665d42009a47d9aa2f3f668e.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/9096ab52665d42009a47d9aa2f3f668e.jpg" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第22张图片" width="650" height="274" style="border:1px solid black;"></a></p>
<p><strong>Case4:title 标签文本</strong></p> 标签的文本作为文本节点插入,生成文本节点的代码如下:
<p><code>// 只保留关健代码 void HTMLConstructionSite::insertTextNode(const String& characters, WhitespaceMode whitespaceMode) { HTMLConstructionSiteTask task(HTMLConstructionSiteTask::Insert); task.parent = ¤tNode(); // 直接取HTMLElementStack m_openElements的栈顶节点,此时节点是title</code></p>
<p>unsigned currentPosition = 0;<br> unsigned lengthLimit = shouldUseLengthLimit(*task.parent) ? Text::defaultLengthLimit : std::numeric_limits::max(); // 限制文本节点最大包含的字符个数为65536</p>
<p>// 可以看到如果文本过长,会将分割成多个文本节点<br> while (currentPosition < characters.length()) {<br> AtomString charactersAtom = m_whitespaceCache.lookup(characters, whitespaceMode);<br> auto textNode = Text::createWithLengthLimit(task.parent->document(), charactersAtom.isNull() ? characters : charactersAtom.string(), currentPosition, lengthLimit);<br> // If we have a whole string of unbreakable characters the above could lead to an infinite loop. Exceeding the length limit is the lesser evil.<br> if (!textNode->length()) {<br> String substring = characters.substring(currentPosition);<br> AtomString substringAtom = m_whitespaceCache.lookup(substring, whitespaceMode);<br> textNode = Text::create(task.parent->document(), substringAtom.isNull() ? substring : substringAtom.string()); // 生成文本节点<br> }</p>
<pre><code> currentPosition += textNode->length(); // 下一个文本节点包含的字符起点
ASSERT(currentPosition <= characters.length());
task.child = WTFMove(textNode);
executeTask(task); // 直接执行Task插入
}
</code></pre>
<p>}</p>
<pre><code>
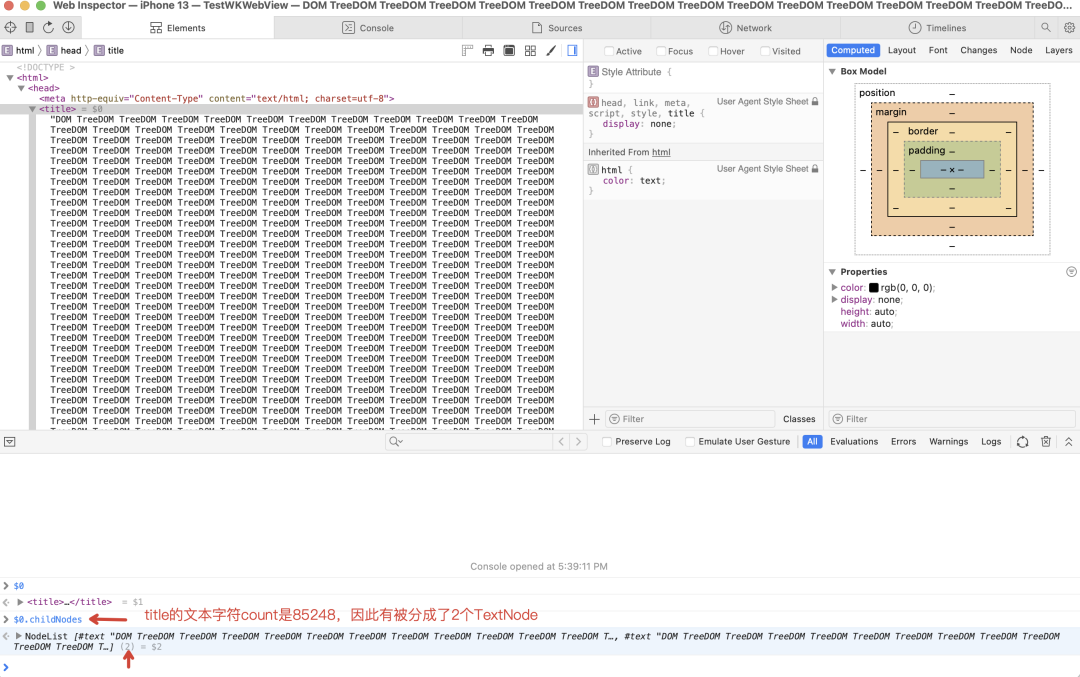
从代码可以看到,如果一个节点后面跟的文本字符过多,会被分割成多个文本节点插入。下面的例子将 <title> 节点后面的文本字符个数设置成85248,使用 Safari 查看确实生成了2个文本节点:
**Case5:结束标签**
当遇到 <title> 结束标签,代码处理如下:
</code></pre>
<p>// 代码内部有很多状态处理,这里只保留关健代码<br> void HTMLTreeBuilder::processEndTag(AtomHTMLToken&& token)<br> {<br> ASSERT(token.type() == HTMLToken::EndTag);<br> switch (m_insertionMode) {<br> …</p>
<p>case InsertionMode::Text: // 由于遇到title结束标签之前插入了文本,因此此时的插入模式就是InsertionMode::Text</p>
<pre><code> m_tree.openElements().pop(); // 因为遇到了title结束标签,整个标签已经处理完毕,从HTMLElementStack栈中弹出栈顶元素title
m_insertionMode = m_originalInsertionMode; // 恢复之前的插入模式
</code></pre>
<p>break;</p>
<p>}</p>
<p>每当遇到一个标签的结束标签,都会像上面一样将 HTMLElementStack m_openElementsStack 的栈顶元素弹出。执行上面代码之后,DOM 树与 HTMLElementStack 如下图所示:</p>
<p><a href="http://img.e-com-net.com/image/info8/541b80d72a7b41e4a0891763fd6d5e2b.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/541b80d72a7b41e4a0891763fd6d5e2b.jpg" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第23张图片" width="650" height="313" style="border:1px solid black;"></a></p>
<h1><strong>三、内存中的DOM树</strong></h1>
<p>当整个 DOM 树构建完成之后,DOM 树和 HTMLElementStack m_openElements 如下图所示:</p>
<p><a href="http://img.e-com-net.com/image/info8/c44fefaa6c6e4ea288a90b4e001e0028.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/c44fefaa6c6e4ea288a90b4e001e0028.jpg" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第24张图片" width="650" height="233" style="border:1px solid black;"></a></p>
<p>从上图可以看到,当构建完 DOM,HTMLElementStack m_openElements 并没有将栈完全清空,而是保留了2个节点: html 节点与 body 节点。这可以从 Xcode 的控制台输出看到:</p>
<p><a href="http://img.e-com-net.com/image/info8/98ba33c5773d4f53a58ee36210b6df16.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/98ba33c5773d4f53a58ee36210b6df16.jpg" alt="深入理解 WKWebView (渲染篇) —— DOM 树的构建_第25张图片" width="650" height="347" style="border:1px solid black;"></a></p>
<p>同时可以看到,内存中的 DOM 树结构和文章开头画的逻辑上的 DOM 树结构是不一样的。逻辑上的 DOM 树父节点有多少子节点,就有多少指向子节点的指针,而内存中的 DOM 树,不管父节点有多少子节点,始终只有2个指针指向子节点: m_firstChild 与 m_lastChild。同时,内存中的 DOM 树兄弟节点之间也相互有指针引用,而逻辑上的 DOM 树结构是没有的。</p>
<p>举个例子,如果一棵 DOM 树只有1个父节点,100个子节点,那么使用逻辑上的 DOM 树结构,父节点就需要100个指向子节点的指针。如果一个指针占8字节,那么总共占用800字节。使用上面内存中 DOM 树的表示方式,父节点需要2个指向子节点的指针,同时兄弟节点之间需要198个指针,一共200个指针,总共占用1600字节。相比逻辑上的 DOM 树结构,内存上并不占优势,但是内存中的 DOM 树结构,无论父节点有多少子节点,只需要2个指针就可以了,不需要添加子节点时,频繁动态申请内存,创建新的指向子节点的指针。</p>
<p>---------- END ----------</p>
<p>百度 Geek 说</p>
<p>百度官方技术公众号上线啦!</p>
<p>技术干货 · 行业资讯 · 线上沙龙 · 行业大会</p>
<p>招聘信息 · 内推信息 · 技术书籍 · 百度周边</p>
</div>
</div>
</div>
</div>
</div>
<!--PC和WAP自适应版-->
<div id="SOHUCS" sid="1590740338421637120"></div>
<script type="text/javascript" src="/views/front/js/chanyan.js"></script>
<!-- 文章页-底部 动态广告位 -->
<div class="youdao-fixed-ad" id="detail_ad_bottom"></div>
</div>
<div class="col-md-3">
<div class="row" id="ad">
<!-- 文章页-右侧1 动态广告位 -->
<div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_1"> </div>
</div>
<!-- 文章页-右侧2 动态广告位 -->
<div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_2"></div>
</div>
<!-- 文章页-右侧3 动态广告位 -->
<div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_3"></div>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="container">
<h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(百度,数据库,web)</h4>
<div id="paradigm-article-related">
<div class="recommend-post mb30">
<ul class="widget-links">
<li><a href="/article/1942290778567012352.htm"
title="基于python+flask框架的某图书馆书籍推荐系统的设计与实现(开题+程序+论文) 计算机毕设" target="_blank">基于python+flask框架的某图书馆书籍推荐系统的设计与实现(开题+程序+论文) 计算机毕设</a>
<span class="text-muted">zhihao502</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/flask/1.htm">flask</a><a class="tag" taget="_blank" href="/search/%E8%AF%BE%E7%A8%8B%E8%AE%BE%E8%AE%A1/1.htm">课程设计</a>
<div>本系统(程序+源码+数据库+调试部署+开发环境)带论文文档1万字以上,文末可获取,系统界面在最后面。系统程序文件列表开题报告内容研究背景在数字化时代,图书馆作为知识传播与积累的重要场所,面临着如何更有效地服务于广大读者的挑战。随着信息量的爆炸式增长,读者在浩瀚的书海中寻找符合个人兴趣和需求的书籍变得日益困难。传统的图书检索方式已难以满足读者快速、精准获取推荐书籍的需求。因此,开发一套智能化的图书馆</div>
</li>
<li><a href="/article/1942290526388678656.htm"
title="Spring Boot与MyBatisPlus集成实践:数据库操作简易化" target="_blank">Spring Boot与MyBatisPlus集成实践:数据库操作简易化</a>
<span class="text-muted"></span>
<div>本文还有配套的精品资源,点击获取简介:本项目"mybatisplus-01.zip"旨在探讨如何将SpringBoot与MyBatisPlus集成,以创建高效和便捷的数据库操作应用。MyBatisPlus是MyBatis的增强版,简化了SQL操作并提供了更多功能。SpringBoot则是一个用于快速开发微服务的框架,它预设了许多配置,减少了初始化项目和编写配置文件的工作。本项目详细介绍了Sprin</div>
</li>
<li><a href="/article/1942290016793325568.htm"
title="如何在YashanDB中实现灵活的数据建模?" target="_blank">如何在YashanDB中实现灵活的数据建模?</a>
<span class="text-muted"></span>
<a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a>
<div>随着信息技术的不断发展,数据量的快速增长使得数据建模成为数据库设计中的一个核心问题。尤其是在面对复杂的业务需求时,合理的数据模型能够有效支撑数据的存储、查询和管理。在这样的背景下,如何在YashanDB中实现灵活的数据建模,成为开发者和数据库管理员亟需解决的技术挑战。核心技术点分析支持多种存储结构YashanDB提供了多种存储结构的支持,包括行存(HEAP)、B树存储(BTREE)以及列存储(MC</div>
</li>
<li><a href="/article/1942290018169057280.htm"
title="如何制定YashanDB数据库的维护与管理计划" target="_blank">如何制定YashanDB数据库的维护与管理计划</a>
<span class="text-muted"></span>
<a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a>
<div>数据库在现代应用程序中扮演着至关重要的角色。然而,随着数据量的不断增加和复杂性的加剧,数据库的性能瓶颈、数据一致性问题、存储的高可用性等正成为技术管理者面临的共同挑战。为了确保数据库的高效运营,制定一份全面的数据库维护与管理计划是必要的。本文旨在帮助技术团队理清YashanDB的维护与管理步骤,为提升数据库的可用性和性能提供指导,目标读者包括DBA、系统管理员和IT管理人员。了解YashanDB架</div>
</li>
<li><a href="/article/1942288764084744192.htm"
title="Android 音频降噪 webrtc 去回声" target="_blank">Android 音频降噪 webrtc 去回声</a>
<span class="text-muted"></span>
<div>Android音频降噪webrtc去回声集成AECM模块集成NS模块需要源码请留言集成AECM模块1.通过webrtc官网下载需要模块\modules\audio_processing\aecm2.新建eclipse工程,新建jni文件夹将webrtcaecm模块拷贝到jni文件夹下3.编写本地接口packagecom.wrtcmy.webrtc.aecm;/***Thisclasssupport</div>
</li>
<li><a href="/article/1942288637274157056.htm"
title="Android音视频通话" target="_blank">Android音视频通话</a>
<span class="text-muted"></span>
<div>Android音视频通话前言一、准备工作1、编写Jni接口2、通过javah工具生成头文件3、集成speex、webrtc二、初始化工作三、开启socketudp服务四、判断socket是否可读五、发送数据到远端1、视频数据1.1、初始化MediaCodec1.2、通过MediaCodec进行H264编码2、音频数据2.1、webrtc消回声2.2、speex编码压缩六、断开连接前言Android</div>
</li>
<li><a href="/article/1942287126813011968.htm"
title="【Python】深入解析 Hydra 库" target="_blank">【Python】深入解析 Hydra 库</a>
<span class="text-muted">宅男很神经</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>第一章:混沌的终结:在配置泥潭中挣扎与Hydra的曙光在任何一个软件项目的生命周期中,无论是小型的个人脚本,还是大型的企业级分布式系统,我们都无法回避一个核心问题:如何管理配置。配置,是连接我们静态的代码逻辑与动态的运行环境之间的桥梁。它决定了我们的程序连接哪个数据库、使用哪个API密钥、以多大的批次处理数据、模型的学习率应该是多少、日志应该输出到哪里、以何种级别输出…可以说,配置定义了程序的行为</div>
</li>
<li><a href="/article/1942286999889178624.htm"
title="缓存雪崩、缓存穿透、缓存预热、缓存更新、缓存降级的理解" target="_blank">缓存雪崩、缓存穿透、缓存预热、缓存更新、缓存降级的理解</a>
<span class="text-muted"></span>
<div>一:缓存雪崩我们可以简单的理解为:由于原有缓存失效,新缓存未到期间(例如:我们设置缓存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期),所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。解决办法:大多数系统设计者考虑用加锁(最多的解决方案)或者队列的方式保证来保证不会有大量的线程对数据库一次性进</div>
</li>
<li><a href="/article/1942286241181528064.htm"
title="Redis之缓存雪崩、缓存穿透、缓存预热、缓存更新、缓存降级" target="_blank">Redis之缓存雪崩、缓存穿透、缓存预热、缓存更新、缓存降级</a>
<span class="text-muted">俺是农村的</span>
<a class="tag" taget="_blank" href="/search/Redis/1.htm">Redis</a><a class="tag" taget="_blank" href="/search/redis/1.htm">redis</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E7%BC%93%E5%AD%98/1.htm">缓存</a>
<div>Redis之缓存雪崩、缓存穿透、缓存预热、缓存更新、缓存降级1、缓存雪崩发生场景:当Redis服务器重启或者大量缓存在同一时期失效时,此时大量的流量会全部冲击到数据库上面,数据库有可能会因为承受不住而宕机解决办法:1)缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。2)给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存。3)一般并发量不是特别多的</div>
</li>
<li><a href="/article/1942284844365049856.htm"
title="MVVM和MVC区别" target="_blank">MVVM和MVC区别</a>
<span class="text-muted">秋恬意</span>
<a class="tag" taget="_blank" href="/search/mvc/1.htm">mvc</a><a class="tag" taget="_blank" href="/search/vue/1.htm">vue</a>
<div>MVVM(Model-View-ViewModel)和MVC(Model-View-Controller)是两种常见的软件架构模式,它们在处理用户界面与业务逻辑之间的交互时有一些不同的设计理念和实现方式。下面我将详细说明这两种模式的区别。1.架构概述MVC(Model-View-Controller)Model:表示应用的核心数据和业务逻辑,通常是与数据库交互的部分。View:用户界面,负责显示数</div>
</li>
<li><a href="/article/1942284086894718976.htm"
title="缓存雪崩、缓存穿透、缓存预热、缓存更新、缓存降级" target="_blank">缓存雪崩、缓存穿透、缓存预热、缓存更新、缓存降级</a>
<span class="text-muted"></span>
<div>1.缓存雪崩(CacheAvalanche)定义:缓存雪崩是指大量缓存中的数据在同一时间过期,导致大量请求同时访问数据库,造成数据库压力骤增,甚至可能导致数据库崩溃。原因:多个缓存的key在同一时间过期;当这些key不再命中缓存时,所有请求都会同时访问数据库。应对策略:设置过期时间加随机值:避免缓存的key在相同时间过期。比如,如果某个key设置过期时间为1小时,可以随机设置在59分钟到61分钟之</div>
</li>
<li><a href="/article/1942280683774865408.htm"
title="2025最新如何解决VSCode远程连接开发机失败/解决方案大全" target="_blank">2025最新如何解决VSCode远程连接开发机失败/解决方案大全</a>
<span class="text-muted">猫头虎</span>
<a class="tag" taget="_blank" href="/search/vscode/1.htm">vscode</a><a class="tag" taget="_blank" href="/search/ide/1.htm">ide</a><a class="tag" taget="_blank" href="/search/%E7%BC%96%E8%BE%91%E5%99%A8/1.htm">编辑器</a><a class="tag" taget="_blank" href="/search/html5/1.htm">html5</a><a class="tag" taget="_blank" href="/search/npm/1.htm">npm</a><a class="tag" taget="_blank" href="/search/chrome/1.htm">chrome</a><a class="tag" taget="_blank" href="/search/devtools/1.htm">devtools</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF%E6%A1%86%E6%9E%B6/1.htm">前端框架</a>
<div>前言在当下的混合开发环境中,VSCodeRemote-SSH、Remote-WSL、DevContainers等扩展极大地提升了本地编辑远程主机代码的体验。但复杂的网络、中间代理、系统配置、磁盘空间、版本兼容等多方面因素,也常常带来连接失败的烦恼。本文基于2025年最新实测,系统地整理了从通用“重启”到深度排查SSH、WebSocket、磁盘、WSL等层面的所有可能方案,帮助你在最短时间内恢复开发</div>
</li>
<li><a href="/article/1942278789526515712.htm"
title="java毕业设计图书馆座位预约管理系统维修端源码+lw文档+mybatis+系统+mysql数据库+调试" target="_blank">java毕业设计图书馆座位预约管理系统维修端源码+lw文档+mybatis+系统+mysql数据库+调试</a>
<span class="text-muted">木林网络</span>
<a class="tag" taget="_blank" href="/search/mybatis/1.htm">mybatis</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a>
<div>java毕业设计图书馆座位预约管理系统维修端源码+lw文档+mybatis+系统+mysql数据库+调试java毕业设计图书馆座位预约管理系统维修端源码+lw文档+mybatis+系统+mysql数据库+调试本源码技术栈:项目架构:B/S架构开发语言:Java语言开发软件:ideaeclipse前端技术:Layui、HTML、CSS、JS、JQuery等技术后端技术:JAVA运行环境:Win10、</div>
</li>
<li><a href="/article/1942272356730859520.htm"
title="Semtech 新的3.3V TVS RClamp3374N 在以太网上的雷击防护应用" target="_blank">Semtech 新的3.3V TVS RClamp3374N 在以太网上的雷击防护应用</a>
<span class="text-muted">_Nickelback</span>
<div>作者:JackChengSemtech上网日期:2012年04月16日评论[0]分享到:新浪微博qq空间qq微博人人网百度搜藏字号:关键字:RClamp2574NSemtech浪涌Semtech新的3.3VTVSRClamp3374N保护八线介绍Semtech的RClamp2574N可以被配置以保护高达8个高速线(四对线)应用,如机顶盒,服务器,笔记本,和台式电脑。这些应用通常不需要同一水平的闪电</div>
</li>
<li><a href="/article/1942268577843310592.htm"
title="查看mysql表_mysql怎么查看表" target="_blank">查看mysql表_mysql怎么查看表</a>
<span class="text-muted">碃凡瑶</span>
<a class="tag" taget="_blank" href="/search/%E6%9F%A5%E7%9C%8Bmysql%E8%A1%A8/1.htm">查看mysql表</a>
<div>mysql中查看表的方法:1、查看当前数据库中的表SHOWTABLES;2、查看表结构showcolumnsfrom表名;show命令可以提供关于数据库、表、列,或关于服务器的状态信息。常用show命令:#显示二进制文件以及文件大小(需要开启二进制日志记录功能)SHOW{BINARY|MASTER}LOGS#显示二进制文件的执行过程SHOWBINLOGEVENTS[IN'log_name'][FR</div>
</li>
<li><a href="/article/1942265551627808768.htm"
title="2022项目实训“异步分布式联邦学习”第五周报告" target="_blank">2022项目实训“异步分布式联邦学习”第五周报告</a>
<span class="text-muted"></span>
<div>一、本周工作进度我在本周的工作进度主要集中于两个技术要点——即Axios和WebSocket。这两种技术方法有着本质上的不同,因而具体实现出来之后的效果也有所不同,下面将会分别说明。1.Axios(Ajax封装)首先要谈的内容是Axios,Axios是一个基于promise的HTTP库,是目前前端最流行的ajax请求库。Axios的优势在于,相比传统的Ajax本身是针对MVC的编程,Axios更加</div>
</li>
<li><a href="/article/1942264289523986432.htm"
title="数据库迁移实战:如何零停机、零丢失迁移数据库?" target="_blank">数据库迁移实战:如何零停机、零丢失迁移数据库?</a>
<span class="text-muted">Leaton Lee</span>
<a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a>
<div>引言:一场没有硝烟的“数据大迁徙”想象一下,你正在为一家电商公司优化数据库架构,需要将MySQL迁移到分布式数据库TiDB。但问题来了:如何在业务高峰期不停止服务,同时确保数据零丢失?这不仅是技术挑战,更是一场精密的“数据芭蕾舞”。今天,我们就从理论到实战,手把手教你完成这场“不可能的任务”!一、迁移前的“战前沙盘推演”1.1数据摸底:绘制“数据地图”数据规模:统计表大小、索引、分区信息(示例:S</div>
</li>
<li><a href="/article/1942264290106994688.htm"
title="详解Binlog 和 Redo Log的区别和底层逻辑" target="_blank">详解Binlog 和 Redo Log的区别和底层逻辑</a>
<span class="text-muted"></span>
<div>引言:为什么你的数据库会“分身术”?想象这样一个场景:你的Java应用突然崩溃,重启后发现数据丢失了一半。这时,你会想起数据库的“时光机”——Binlog,或者它的“安全网”——RedoLog?Binlog(BinaryLog)Binlog是MySQL数据库中的一种日志文件,用于记录所有对数据库执行的数据修改操作(如INSERT、UPDATE、DELETE等)。它以二进制的形式存储,主要用于数据复</div>
</li>
<li><a href="/article/1942263028636512256.htm"
title="以下是基于 C# 的面向对象设计,抽象出公共接口和协议实现" target="_blank">以下是基于 C# 的面向对象设计,抽象出公共接口和协议实现</a>
<span class="text-muted">zhxup606</span>
<a class="tag" taget="_blank" href="/search/%E9%80%9A%E8%AE%AF%E5%8D%8F%E8%AE%AE/1.htm">通讯协议</a><a class="tag" taget="_blank" href="/search/c%23/1.htm">c#</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>以下是基于C#的面向对象设计,抽象出公共接口和协议实现,涵盖SerialPortProtocol、TcpProtocol、HttpProtocol、WebSocketProtocol、ModbusProtocol和MQTTProtocol。每个协议实现为单独的项目,公共接口定义在独立项目中,使用异步编程模式(async/await)确保高效和稳定,代码结构易于扩展。以下内容包含详细的代码示例、注释</div>
</li>
<li><a href="/article/1942262901440049152.htm"
title="上位机李工架构之一" target="_blank">上位机李工架构之一</a>
<span class="text-muted">zhxup606</span>
<a class="tag" taget="_blank" href="/search/%E6%9E%B6%E6%9E%84/1.htm">架构</a>
<div>本篇将围绕半导体可靠性测试机上位机开发,提供一个系统性教程与学习路线,结合C#高级编程(反射、接口、抽象类、泛型、设计模式、集合、特性、索引、委托事件、匿名方法、多线程、面向对象等)和异步/同步对比,深入讲解如何高效开发上位机系统。同时,基于前文的实时数据可视化(WPF、LiveCharts2、WebSocket)、AI异常检测(ML.NET隔离森林)和异步任务调度(DAG调度、PID控制),本篇</div>
</li>
<li><a href="/article/1942262773379559424.htm"
title="PHP 安装指南" target="_blank">PHP 安装指南</a>
<span class="text-muted">wjs2024</span>
<a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>PHP安装指南引言PHP是一种广泛使用的开源服务器端脚本语言,常用于Web开发。正确安装PHP是开始构建动态网站或应用程序的第一步。本文将详细介绍如何在各种操作系统上安装PHP,并指导您完成必要的配置步骤。安装环境准备在安装PHP之前,请确保您的系统满足以下条件:操作系统:PHP可以在多种操作系统上运行,包括Windows、Linux和macOS。Web服务器:虽然PHP主要用作服务器端脚本语言,</div>
</li>
<li><a href="/article/1942261638904213504.htm"
title="网络安全之注入攻击:原理、危害与防御之道" target="_blank">网络安全之注入攻击:原理、危害与防御之道</a>
<span class="text-muted"></span>
<div>网络安全之注入攻击:原理、危害与防御之道引言在OWASPTop10安全风险榜单中,注入攻击常年占据首位。2023年Verizon数据泄露调查报告显示,67%的Web应用漏洞与注入类攻击直接相关。本文从技术视角系统解析注入攻击的核心原理、典型场景及防御体系,揭示这一"网络安全头号杀手"的攻防博弈。一、注入攻击的本质与分类1.1基本定义当应用程序将非可信数据(UntrustedData)作为代码解析时</div>
</li>
<li><a href="/article/1942259620399607808.htm"
title="SpringBoot读取大体积Excel文件的最佳实践" target="_blank">SpringBoot读取大体积Excel文件的最佳实践</a>
<span class="text-muted">Ceramist</span>
<a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/boot/1.htm">boot</a><a class="tag" taget="_blank" href="/search/excel/1.htm">excel</a><a class="tag" taget="_blank" href="/search/%E5%90%8E%E7%AB%AF/1.htm">后端</a>
<div>SpringBoot读取大体积Excel文件的最佳实践:从上传到应用在Web应用程序中,尤其是使用SpringBoot构建的应用,处理大体积Excel文件的上传、读取、校验和应用是常见的需求。下面,我们将详细阐述一个完整的设计思路,包括接口设计、文件处理流程以及数据的有效性校验。接口设计首先,设计一个用于接收Excel文件的RESTfulAPI接口。这个接口应该能够接受multipart/form</div>
</li>
<li><a href="/article/1942254328924401664.htm"
title="JetBrains 2025 全家桶 11合1 Mac电脑" target="_blank">JetBrains 2025 全家桶 11合1 Mac电脑</a>
<span class="text-muted">2501_92680691</span>
<a class="tag" taget="_blank" href="/search/intellij-idea/1.htm">intellij-idea</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/macos/1.htm">macos</a><a class="tag" taget="_blank" href="/search/pycharm/1.htm">pycharm</a><a class="tag" taget="_blank" href="/search/datagrip/1.htm">datagrip</a><a class="tag" taget="_blank" href="/search/webstorm/1.htm">webstorm</a><a class="tag" taget="_blank" href="/search/phpstorm/1.htm">phpstorm</a>
<div>JetBrains2025全家桶11合1Mac电脑,11个包含:IDEA、WebStorm、DataSpell、DataGrip、Pycharm、RustRover、CLion、Rider、PhpStorm、RubyMine、GoLand。原文地址:JetBrains2025全家桶11合1含IDEA、PyCharm、DataGrip、WebStrom、GoLand、CLion、PhpStorm、D</div>
</li>
<li><a href="/article/1942251681668460544.htm"
title="《声音的变形记:Web Audio API的实时特效法则》" target="_blank">《声音的变形记:Web Audio API的实时特效法则》</a>
<span class="text-muted">程序猿阿伟</span>
<a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/php/1.htm">php</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>用户期待更丰富、更具沉浸感的听觉体验时,基于WebAudioAPI实现的实时音频特效,就像是为这片森林注入了灵动的精灵,让简单的声音蜕变为震撼人心的听觉盛宴。回声特效带来空间的深邃回响,变声效果赋予声音全新的个性面貌。接下来,我们将深入探索WebAudioAPI如何实现这些神奇的实时音频特效。WebAudioAPI是浏览器中用于处理音频的强大工具,它构建了一个完整的音频处理体系。不同于传统的HTM</div>
</li>
<li><a href="/article/1942247525167722496.htm"
title="Wizard全栈开发框架:轻松构建企业级应用" target="_blank">Wizard全栈开发框架:轻松构建企业级应用</a>
<span class="text-muted">GISer_Jinger</span>
<a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF%E5%9F%BA%E7%A1%80/1.htm">前端基础</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/javascript/1.htm">javascript</a>
<div>Wizard全栈开发框架详解Wizard是一个现代化的全栈开发框架,旨在简化企业级应用的开发流程,提供从前端到后端的完整解决方案。一、核心架构前端架构UI层:支持React、Vue等主流框架状态管理:集成Redux、Vuex等方案API客户端:自动生成类型安全的API调用代码生成器:基于模板自动生成页面组件后端架构Web服务器:支持Express、SpringBoot等多种实现ORM:内置多数据库</div>
</li>
<li><a href="/article/1942247272943251456.htm"
title="基于springboot的商业辅助决策系统的设计与实现" target="_blank">基于springboot的商业辅助决策系统的设计与实现</a>
<span class="text-muted">qq 79856539</span>
<a class="tag" taget="_blank" href="/search/javaweb/1.htm">javaweb</a><a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/boot/1.htm">boot</a><a class="tag" taget="_blank" href="/search/%E5%90%8E%E7%AB%AF/1.htm">后端</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>一、项目介绍商业辅助决策系统实现的功能包括收入信息管理与支出信息管理,员工销售订单信息管理,员工薪资管理,员工管理,公告管理等功能。该系统采用了Mysql数据库,Java语言,SpringBoot框架等技术进行编程实现。商业辅助决策系统可以提高收支信息和销售订单信息管理问题的解决效率,优化收支信息和销售订单信息处理流程,保证收支信息和销售订单信息数据的安全,它是一个非常可靠,非常安全的应用程序。关</div>
</li>
<li><a href="/article/1942240332641005568.htm"
title="手把手教你入门vue+springboot开发(九)--springboot后端实现与postman调试" target="_blank">手把手教你入门vue+springboot开发(九)--springboot后端实现与postman调试</a>
<span class="text-muted">段鸿潭</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/vue.js/1.htm">vue.js</a><a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a><a class="tag" taget="_blank" href="/search/boot/1.htm">boot</a><a class="tag" taget="_blank" href="/search/postman/1.htm">postman</a>
<div>文章目录前言一、后端代码实现1.实现pojo/User.java2.实现mapper/UserMapper.java3.实现service/UserService.java4.实现service/UserServiceImpl.java5.实现controller/UserController.java二、postman调试总结前言上篇我们已经定义好了数据库表users和用户管理功能的HTTP接口</div>
</li>
<li><a href="/article/1942239449261862912.htm"
title="Mybatis" target="_blank">Mybatis</a>
<span class="text-muted">微风粼粼</span>
<a class="tag" taget="_blank" href="/search/mybatis/1.htm">mybatis</a><a class="tag" taget="_blank" href="/search/tomcat/1.htm">tomcat</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>1、概述什么是mybatis?MyBatis是一个基于Java的持久层框架,它支持定制化SQL、存储过程以及高级映射。MyBatis消除了几乎所有的JDBC代码和参数的手动设置以及结果集的检索。MyBatis使用简单的XML或注解用于配置和原始映射,将接口和Java的POJOs(PlainOrdinaryJavaObjects,普通的Java对象)映射成数据库中的记录。它是一款半自动的ORM持久层</div>
</li>
<li><a href="/article/1942237407994769408.htm"
title="如何在YashanDB中使用SQL实现复杂查询" target="_blank">如何在YashanDB中使用SQL实现复杂查询</a>
<span class="text-muted"></span>
<a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a>
<div>在当今的数据驱动环境中,数据库查询性能至关重要,尤其是复杂查询的实现与优化。复杂查询通常涉及多表连接、聚集计算或者子查询,相对于简单查询,更高的计算要求极大地影响了执行速度。因此,了解如何在YashanDB中高效地实现复杂查询,不仅可以优化应用的性能,还能提升整体的数据处理效率。复杂查询的实现方法多表关联查询在YashanDB中,多表关联查询是复杂查询中最常用的形式之一。通过使用INNERJOIN</div>
</li>
<li><a href="/article/26.htm"
title="设计模式介绍" target="_blank">设计模式介绍</a>
<span class="text-muted">tntxia</span>
<a class="tag" taget="_blank" href="/search/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F/1.htm">设计模式</a>
<div>设计模式来源于土木工程师 克里斯托弗 亚历山大(http://en.wikipedia.org/wiki/Christopher_Alexander)的早期作品。他经常发表一些作品,内容是总结他在解决设计问题方面的经验,以及这些知识与城市和建筑模式之间有何关联。有一天,亚历山大突然发现,重复使用这些模式可以让某些设计构造取得我们期望的最佳效果。
亚历山大与萨拉-石川佳纯和穆雷 西乐弗斯坦合作</div>
</li>
<li><a href="/article/153.htm"
title="android高级组件使用(一)" target="_blank">android高级组件使用(一)</a>
<span class="text-muted">百合不是茶</span>
<a class="tag" taget="_blank" href="/search/android/1.htm">android</a><a class="tag" taget="_blank" href="/search/RatingBar/1.htm">RatingBar</a><a class="tag" taget="_blank" href="/search/Spinner/1.htm">Spinner</a>
<div>1、自动完成文本框(AutoCompleteTextView)
AutoCompleteTextView从EditText派生出来,实际上也是一个文本编辑框,但它比普通编辑框多一个功能:当用户输入一个字符后,自动完成文本框会显示一个下拉菜单,供用户从中选择,当用户选择某个菜单项之后,AutoCompleteTextView按用户选择自动填写该文本框。
使用AutoCompleteTex</div>
</li>
<li><a href="/article/280.htm"
title="[网络与通讯]路由器市场大有潜力可挖掘" target="_blank">[网络与通讯]路由器市场大有潜力可挖掘</a>
<span class="text-muted">comsci</span>
<a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%BB%9C/1.htm">网络</a>
<div>
如果国内的电子厂商和计算机设备厂商觉得手机市场已经有点饱和了,那么可以考虑一下交换机和路由器市场的进入问题.....
这方面的技术和知识,目前处在一个开放型的状态,有利于各类小型电子企业进入
&nbs</div>
</li>
<li><a href="/article/407.htm"
title="自写简单Redis内存统计shell" target="_blank">自写简单Redis内存统计shell</a>
<span class="text-muted">商人shang</span>
<a class="tag" taget="_blank" href="/search/Linux+shell/1.htm">Linux shell</a><a class="tag" taget="_blank" href="/search/%E7%BB%9F%E8%AE%A1Redis%E5%86%85%E5%AD%98/1.htm">统计Redis内存</a>
<div>#!/bin/bash
address="192.168.150.128:6666,192.168.150.128:6666"
hosts=(${address//,/ })
sfile="staticts.log"
for hostitem in ${hosts[@]}
do
ipport=(${hostitem</div>
</li>
<li><a href="/article/534.htm"
title="单例模式(饿汉 vs懒汉)" target="_blank">单例模式(饿汉 vs懒汉)</a>
<span class="text-muted">oloz</span>
<a class="tag" taget="_blank" href="/search/%E5%8D%95%E4%BE%8B%E6%A8%A1%E5%BC%8F/1.htm">单例模式</a>
<div>package 单例模式;
/*
* 应用场景:保证在整个应用之中某个对象的实例只有一个
* 单例模式种的《 懒汉模式》
* */
public class Singleton {
//01 将构造方法私有化,外界就无法用new Singleton()的方式获得实例
private Singleton(){};
//02 申明类得唯一实例
priva</div>
</li>
<li><a href="/article/661.htm"
title="springMvc json支持" target="_blank">springMvc json支持</a>
<span class="text-muted">杨白白</span>
<a class="tag" taget="_blank" href="/search/json+springmvc/1.htm">json springmvc</a>
<div>1.Spring mvc处理json需要使用jackson的类库,因此需要先引入jackson包
2在spring mvc中解析输入为json格式的数据:使用@RequestBody来设置输入
@RequestMapping("helloJson")
public @ResponseBody
JsonTest helloJson() {
</div>
</li>
<li><a href="/article/788.htm"
title="android播放,掃描添加本地音頻文件" target="_blank">android播放,掃描添加本地音頻文件</a>
<span class="text-muted">小桔子</span>
<div> 最近幾乎沒有什麽事情,繼續鼓搗我的小東西。想在項目中加入一個簡易的音樂播放器功能,就像華為p6桌面上那麼大小的音樂播放器。用過天天動聽或者QQ音樂播放器的人都知道,可已通過本地掃描添加歌曲。不知道他們是怎麼實現的,我覺得應該掃描設備上的所有文件,過濾出音頻文件,每個文件實例化為一個實體,記錄文件名、路徑、歌手、類型、大小等信息。具體算法思想,</div>
</li>
<li><a href="/article/915.htm"
title="oracle常用命令" target="_blank">oracle常用命令</a>
<span class="text-muted">aichenglong</span>
<a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/dba/1.htm">dba</a><a class="tag" taget="_blank" href="/search/%E5%B8%B8%E7%94%A8%E5%91%BD%E4%BB%A4/1.htm">常用命令</a>
<div>1 创建临时表空间
create temporary tablespace user_temp
tempfile 'D:\oracle\oradata\Oracle9i\user_temp.dbf'
size 50m
autoextend on
next 50m maxsize 20480m
extent management local</div>
</li>
<li><a href="/article/1042.htm"
title="25个Eclipse插件" target="_blank">25个Eclipse插件</a>
<span class="text-muted">AILIKES</span>
<a class="tag" taget="_blank" href="/search/eclipse%E6%8F%92%E4%BB%B6/1.htm">eclipse插件</a>
<div>提高代码质量的插件1. FindBugsFindBugs可以帮你找到Java代码中的bug,它使用Lesser GNU Public License的自由软件许可。2. CheckstyleCheckstyle插件可以集成到Eclipse IDE中去,能确保Java代码遵循标准代码样式。3. ECLemmaECLemma是一款拥有Eclipse Public License许可的免费工具,它提供了</div>
</li>
<li><a href="/article/1169.htm"
title="Spring MVC拦截器+注解方式实现防止表单重复提交" target="_blank">Spring MVC拦截器+注解方式实现防止表单重复提交</a>
<span class="text-muted">baalwolf</span>
<a class="tag" taget="_blank" href="/search/spring+mvc/1.htm">spring mvc</a>
<div>原理:在新建页面中Session保存token随机码,当保存时验证,通过后删除,当再次点击保存时由于服务器端的Session中已经不存在了,所有无法验证通过。
1.新建注解:
? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 </div>
</li>
<li><a href="/article/1296.htm"
title="《Javascript高级程序设计(第3版)》闭包理解" target="_blank">《Javascript高级程序设计(第3版)》闭包理解</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a>
<div>“闭包是指有权访问另一个函数作用域中的变量的函数。”--《Javascript高级程序设计(第3版)》
看以下代码:
<script type="text/javascript">
function outer() {
var i = 10;
return f</div>
</li>
<li><a href="/article/1423.htm"
title="AngularJS Module类的方法" target="_blank">AngularJS Module类的方法</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a><a class="tag" taget="_blank" href="/search/AngularJS/1.htm">AngularJS</a><a class="tag" taget="_blank" href="/search/Module/1.htm">Module</a>
<div> AngularJS中的Module类负责定义应用如何启动,它还可以通过声明的方式定义应用中的各个片段。我们来看看它是如何实现这些功能的。
一.Main方法在哪里
如果你是从Java或者Python编程语言转过来的,那么你可能很想知道AngularJS里面的main方法在哪里?这个把所</div>
</li>
<li><a href="/article/1550.htm"
title="[Maven学习笔记七]Maven插件和目标" target="_blank">[Maven学习笔记七]Maven插件和目标</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/maven%E6%8F%92%E4%BB%B6/1.htm">maven插件</a>
<div>插件(plugin)和目标(goal)
Maven,就其本质而言,是一个插件执行框架,Maven的每个目标的执行逻辑都是由插件来完成的,一个插件可以有1个或者几个目标,比如maven-compiler-plugin插件包含compile和testCompile,即maven-compiler-plugin提供了源代码编译和测试源代码编译的两个目标
使用插件和目标使得我们可以干预</div>
</li>
<li><a href="/article/1677.htm"
title="【Hadoop八】Yarn的资源调度策略" target="_blank">【Hadoop八】Yarn的资源调度策略</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/hadoop/1.htm">hadoop</a>
<div>1. Hadoop的三种调度策略
Hadoop提供了3中作业调用的策略,
FIFO Scheduler
Fair Scheduler
Capacity Scheduler
以上三种调度算法,在Hadoop MR1中就引入了,在Yarn中对它们进行了改进和完善.Fair和Capacity Scheduler用于多用户共享的资源调度
2. 多用户资源共享的调度 </div>
</li>
<li><a href="/article/1804.htm"
title="Nginx使用Linux内存加速静态文件访问" target="_blank">Nginx使用Linux内存加速静态文件访问</a>
<span class="text-muted">ronin47</span>
<div>Nginx是一个非常出色的静态资源web服务器。如果你嫌它还不够快,可以把放在磁盘中的文件,映射到内存中,减少高并发下的磁盘IO。
先做几个假设。nginx.conf中所配置站点的路径是/home/wwwroot/res,站点所对应文件原始存储路径:/opt/web/res
shell脚本非常简单,思路就是拷贝资源文件到内存中,然后在把网站的静态文件链接指向到内存中即可。具体如下: </div>
</li>
<li><a href="/article/1931.htm"
title="关于Unity3D中的Shader的知识" target="_blank">关于Unity3D中的Shader的知识</a>
<span class="text-muted">brotherlamp</span>
<a class="tag" taget="_blank" href="/search/unity/1.htm">unity</a><a class="tag" taget="_blank" href="/search/unity%E8%B5%84%E6%96%99/1.htm">unity资料</a><a class="tag" taget="_blank" href="/search/unity%E6%95%99%E7%A8%8B/1.htm">unity教程</a><a class="tag" taget="_blank" href="/search/unity%E8%A7%86%E9%A2%91/1.htm">unity视频</a><a class="tag" taget="_blank" href="/search/unity%E8%87%AA%E5%AD%A6/1.htm">unity自学</a>
<div>首先先解释下Unity3D的Shader,Unity里面的Shaders是使用一种叫ShaderLab的语言编写的,它同微软的FX文件或者NVIDIA的CgFX有些类似。传统意义上的vertex shader和pixel shader还是使用标准的Cg/HLSL 编程语言编写的。因此Unity文档里面的Shader,都是指用ShaderLab编写的代码,然后我们来看下Unity3D自带的60多个S</div>
</li>
<li><a href="/article/2058.htm"
title="CopyOnWriteArrayList vs ArrayList" target="_blank">CopyOnWriteArrayList vs ArrayList</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>package com.ljn.base;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.concurrent.CopyOnWriteArrayList;
/**
* 总述:
* 1.ArrayListi不是线程安全的,CopyO</div>
</li>
<li><a href="/article/2185.htm"
title="内存中栈和堆的区别" target="_blank">内存中栈和堆的区别</a>
<span class="text-muted">chicony</span>
<a class="tag" taget="_blank" href="/search/%E5%86%85%E5%AD%98/1.htm">内存</a>
<div>
1、内存分配方面:
堆:一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式是类似于链表。可能用到的关键字如下:new、malloc、delete、free等等。
栈:由编译器(Compiler)自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中</div>
</li>
<li><a href="/article/2312.htm"
title="回答一位网友对Scala的提问" target="_blank">回答一位网友对Scala的提问</a>
<span class="text-muted">chenchao051</span>
<a class="tag" taget="_blank" href="/search/scala/1.htm">scala</a><a class="tag" taget="_blank" href="/search/map/1.htm">map</a>
<div>本来准备在私信里直接回复了,但是发现不太方便,就简要回答在这里。 问题 写道 对于scala的简洁十分佩服,但又觉得比较晦涩,例如一例,Map("a" -> List(11,111)).flatMap(_._2),可否说下最后那个函数做了什么,真正在开发的时候也会如此简洁?谢谢
先回答一点,在实际使用中,Scala毫无疑问就是这么简单。</div>
</li>
<li><a href="/article/2439.htm"
title="mysql 取每组前几条记录" target="_blank">mysql 取每组前几条记录</a>
<span class="text-muted">daizj</span>
<a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a><a class="tag" taget="_blank" href="/search/%E5%88%86%E7%BB%84/1.htm">分组</a><a class="tag" taget="_blank" href="/search/%E6%9C%80%E5%A4%A7%E5%80%BC/1.htm">最大值</a><a class="tag" taget="_blank" href="/search/%E6%9C%80%E5%B0%8F%E5%80%BC/1.htm">最小值</a><a class="tag" taget="_blank" href="/search/%E6%AF%8F%E7%BB%84%E4%B8%89%E6%9D%A1%E8%AE%B0%E5%BD%95/1.htm">每组三条记录</a>
<div>一、对分组的记录取前N条记录:例如:取每组的前3条最大的记录 1.用子查询: SELECT * FROM tableName a WHERE 3> (SELECT COUNT(*) FROM tableName b WHERE b.id=a.id AND b.cnt>a. cnt) ORDER BY a.id,a.account DE</div>
</li>
<li><a href="/article/2566.htm"
title="HTTP深入浅出 http请求" target="_blank">HTTP深入浅出 http请求</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/http/1.htm">http</a>
<div> HTTP(HyperText Transfer Protocol)是一套计算机通过网络进行通信的规则。计算机专家设计出HTTP,使HTTP客户(如Web浏览器)能够从HTTP服务器(Web服务器)请求信息和服务,HTTP目前协议的版本是1.1.HTTP是一种无状态的协议,无状态是指Web浏览器和Web服务器之间不需要建立持久的连接,这意味着当一个客户端向服务器端发出请求,然后We</div>
</li>
<li><a href="/article/2693.htm"
title="判断MySQL记录是否存在方法比较" target="_blank">判断MySQL记录是否存在方法比较</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a>
<div>把数据写入到数据库的时,常常会碰到先要检测要插入的记录是否存在,然后决定是否要写入。
我这里总结了判断记录是否存在的常用方法:
sql语句: select count ( * ) from tablename;
然后读取count(*)的值判断记录是否存在。对于这种方法性能上有些浪费,我们只是想判断记录记录是否存在,没有必要全部都查出来。</div>
</li>
<li><a href="/article/2820.htm"
title="对HTML XML的一点认识" target="_blank">对HTML XML的一点认识</a>
<span class="text-muted">e200702084</span>
<a class="tag" taget="_blank" href="/search/html/1.htm">html</a><a class="tag" taget="_blank" href="/search/xml/1.htm">xml</a>
<div>感谢http://www.w3school.com.cn提供的资料
HTML 文档中的每个成分都是一个节点。
节点
根据 DOM,HTML 文档中的每个成分都是一个节点。
DOM 是这样规定的:
整个文档是一个文档节点
每个 HTML 标签是一个元素节点
包含在 HTML 元素中的文本是文本节点
每一个 HTML 属性是一个属性节点
注释属于注释节点
Node 层次
</div>
</li>
<li><a href="/article/2947.htm"
title="jquery分页插件" target="_blank">jquery分页插件</a>
<span class="text-muted">genaiwei</span>
<a class="tag" taget="_blank" href="/search/jquery/1.htm">jquery</a><a class="tag" taget="_blank" href="/search/Web/1.htm">Web</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/%E5%88%86%E9%A1%B5/1.htm">分页</a><a class="tag" taget="_blank" href="/search/%E6%8F%92%E4%BB%B6/1.htm">插件</a>
<div>//jquery页码控件// 创建一个闭包 (function($) { // 插件的定义 $.fn.pageTool = function(options) { var totalPa</div>
</li>
<li><a href="/article/3201.htm"
title="Mybatis与Ibatis对照入门于学习" target="_blank">Mybatis与Ibatis对照入门于学习</a>
<span class="text-muted">Josh_Persistence</span>
<a class="tag" taget="_blank" href="/search/mybatis/1.htm">mybatis</a><a class="tag" taget="_blank" href="/search/ibatis/1.htm">ibatis</a><a class="tag" taget="_blank" href="/search/%E5%8C%BA%E5%88%AB/1.htm">区别</a><a class="tag" taget="_blank" href="/search/%E8%81%94%E7%B3%BB/1.htm">联系</a>
<div>一、为什么使用IBatis/Mybatis
对于从事 Java EE 的开发人员来说,iBatis 是一个再熟悉不过的持久层框架了,在 Hibernate、JPA 这样的一站式对象 / 关系映射(O/R Mapping)解决方案盛行之前,iBaits 基本是持久层框架的不二选择。即使在持久层框架层出不穷的今天,iBatis 凭借着易学易用、</div>
</li>
<li><a href="/article/3328.htm"
title="C中怎样合理决定使用那种整数类型?" target="_blank">C中怎样合理决定使用那种整数类型?</a>
<span class="text-muted">秋风扫落叶</span>
<a class="tag" taget="_blank" href="/search/c/1.htm">c</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E7%B1%BB%E5%9E%8B/1.htm">数据类型</a>
<div>如果需要大数值(大于32767或小于32767), 使用long 型。 否则, 如果空间很重要 (如有大数组或很多结构), 使用 short 型。 除此之外, 就使用 int 型。 如果严格定义的溢出特征很重要而负值无关紧要, 或者你希望在操作二进制位和字节时避免符号扩展的问题, 请使用对应的无符号类型。 但是, 要注意在表达式中混用有符号和无符号值的情况。
&nbs</div>
</li>
<li><a href="/article/3455.htm"
title="maven问题" target="_blank">maven问题</a>
<span class="text-muted">zhb8015</span>
<a class="tag" taget="_blank" href="/search/maven%E9%97%AE%E9%A2%98/1.htm">maven问题</a>
<div>
问题1:
Eclipse 中 新建maven项目 无法添加src/main/java 问题
eclipse创建maevn web项目,在选择maven_archetype_web原型后,默认只有src/main/resources这个Source Floder。
按照maven目录结构,添加src/main/ja</div>
</li>
<li><a href="/article/3582.htm"
title="(二)androidpn-server tomcat版源码解析之--push消息处理" target="_blank">(二)androidpn-server tomcat版源码解析之--push消息处理</a>
<span class="text-muted">spjich</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/androdipn/1.htm">androdipn</a><a class="tag" taget="_blank" href="/search/%E6%8E%A8%E9%80%81/1.htm">推送</a>
<div>在 (一)androidpn-server tomcat版源码解析之--项目启动这篇中,已经描述了整个推送服务器的启动过程,并且把握到了消息的入口即XmppIoHandler这个类,今天我将继续往下分析下面的核心代码,主要分为3大块,链接创建,消息的发送,链接关闭。
先贴一段XmppIoHandler的部分代码
/**
* Invoked from an I/O proc</div>
</li>
<li><a href="/article/3709.htm"
title="用js中的formData类型解决ajax提交表单时文件不能被serialize方法序列化的问题" target="_blank">用js中的formData类型解决ajax提交表单时文件不能被serialize方法序列化的问题</a>
<span class="text-muted">中华好儿孙</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a><a class="tag" taget="_blank" href="/search/Ajax/1.htm">Ajax</a><a class="tag" taget="_blank" href="/search/Web/1.htm">Web</a><a class="tag" taget="_blank" href="/search/%E4%B8%8A%E4%BC%A0%E6%96%87%E4%BB%B6/1.htm">上传文件</a><a class="tag" taget="_blank" href="/search/FormData/1.htm">FormData</a>
<div>
var formData = new FormData($("#inputFileForm")[0]);
$.ajax({
type:'post',
url:webRoot+"/electronicContractUrl/webapp/uploadfile",
data:formData,
async: false,
ca</div>
</li>
<li><a href="/article/3836.htm"
title="mybatis常用jdbcType数据类型" target="_blank">mybatis常用jdbcType数据类型</a>
<span class="text-muted">ysj5125094</span>
<a class="tag" taget="_blank" href="/search/mybatis/1.htm">mybatis</a><a class="tag" taget="_blank" href="/search/mapper/1.htm">mapper</a><a class="tag" taget="_blank" href="/search/jdbcType/1.htm">jdbcType</a>
<div>
MyBatis 通过包含的jdbcType
类型
BIT FLOAT CHAR </div>
</li>
</ul>
</div>
</div>
</div>
<div>
<div class="container">
<div class="indexes">
<strong>按字母分类:</strong>
<a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a
href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a
href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a
href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a
href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a
href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a
href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a
href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a
href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a>
</div>
</div>
</div>
<footer id="footer" class="mb30 mt30">
<div class="container">
<div class="footBglm">
<a target="_blank" href="/">首页</a> -
<a target="_blank" href="/custom/about.htm">关于我们</a> -
<a target="_blank" href="/search/Java/1.htm">站内搜索</a> -
<a target="_blank" href="/sitemap.txt">Sitemap</a> -
<a target="_blank" href="/custom/delete.htm">侵权投诉</a>
</div>
<div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved.
<!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>-->
</div>
</div>
</footer>
<!-- 代码高亮 -->
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script>
<link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/>
<script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script>
</body>
</html>