通过Canal将MySQL数据同步到Elasticsearch
注:本文是以测试环境下使用一台机器部署,用docker-compose编排ES+KIbana,ES集群为一台master,mysql以及canal插件存放在宿主机上,机器最低配置要求2vcpu 4G,生产环境下根据具体要求配置相应的配置文件。
一、canal简介
Canal是阿里巴巴集团提供的一个开源产品,能够通过解析数据库的增量日志,提供增量数据的订阅和消费功能。当您需要将MySQL中的增量数据同步至阿里云Elasticsearch时,可通过Canal来实现。本文以MySQL为例,介绍具体的实现方法。
canal背景信息
Canal是Github中开源的ETL(Extract Transform Load)软件
canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
基于日志增量订阅和消费的业务包括
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
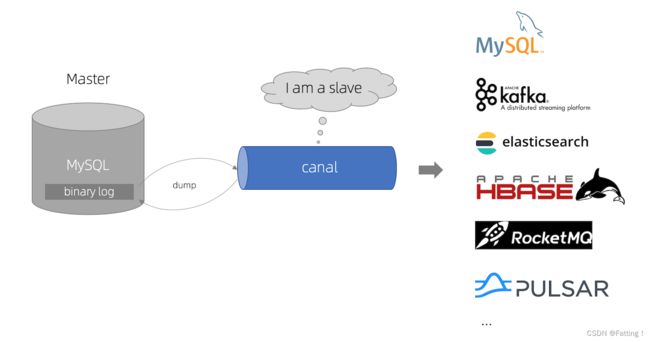
工作原理

- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
canal 工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
二、mysql相关配置
1、由于canal是通过订阅MySQL的binlog来实现数据同步的,所以我们需要开启MySQL的binlog写入功能,并设置binlog-format为ROW模式,我的配置文件为/mydata/mysql/conf/my.cnf,改为如下内容即可
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
log_bin=ON #开启bin-log日志
binlog_format=ROW #设置使用的二进制日志格式
server-id=1 #设置severid
log-bin=/var/lib/mysql/mysql-bin #设置logbin日志存放目录
symbolic-links=0
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
2、配置完成后需要重新启动MySQL,重启成功后通过如下命令查看binlog是否启用
SHOW VARIABLES LIKE '%log_bin%'; 
3、再查看下MySQL的binlog模式
SHOW VARIABLES LIKE 'binlog_format'; 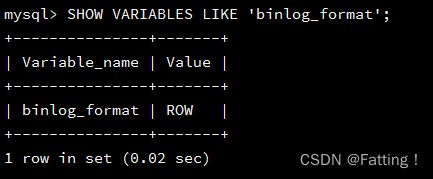
4、接下来需要创建一个拥有从库权限的账号,用于订阅binlog,这里创建的账号为canal:canal
GREAT USER canal IDENTIFIED BY 'canal';5、赋予canal用户权限
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;6、模拟数据
创建库
create database elasticsearch;创建表
create table es_test(id int auto_increment primary key,count text,name text,color text);插入数据
insert into es_test(count,name,color) values ('1','xh',red);三、canal的下载及使用
1、由于不同版本的MySQL、Elasticsearch和canal会有兼容性问题,下面介绍本文涉及到组件的版本
| 组件 | 端口 | 版本号 |
| elasticsearch | 9200 | 7.7.0 |
| kibana | 5601 | 7.7.0 |
| mysql | 3306 | 5.7.39 |
| canal-admin | 8089 | 1.1.5 |
| canal-server | 11111 | 1.1.5 |
| canal-adapter | 8081 | 1.1.5 |
2、由于canal组件必须依赖于java环境启动,这步安装jdk
2.1 、查看可用jdk软件包列表
yum search java | grep -i --color JDK2.2、选择合适的版本,安装JDK。
本文选择java-1.8.0-openjdk-devel.x86_64。
yum install java-1.8.0-openjdk-devel.x86_642.3、配置环境变量
a.打开etc文件夹下的profile文件。
vi /etc/profileb.在文件内添加如下的环境变量。
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.71-2.b15.el7_2.x86_64
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin注意 JAVA_HOME需要替换为您JDK的安装路径,可通过find / -name 'java'命令查看。
c.按下Esc键,然后使用:wq保存文件并退出vi模式,随后执行以下命令使配置生效。
source /etc/profile2.4、执行一下命令查看java是否安装成功
java -version 
3、下载canal的各个组件canal-server、canal-adapter、canal-admin,下载地址:
https://github.com/alibaba/canal/releases

4、canal各个组件功能介绍
canal-server(canal-deploy):可以直接监听MySQL的binlog,把自己伪装成MySQL的从库,只负责接收数据,并不做处理。
canal-adapter:相当于canal的客户端,会从canal-server中获取数据,然后对数据进行同步,可以同步到MySQL、Elasticsearch和HBase等存储中去。
canal-admin:为canal提供整体配置管理、节点运维等面向运维的功能,提供相对友好的WebUI操
作界面,方便更多用户快速和安全的操作。
5、canal-server的使用
将我们下载好的压缩包canal.deployer-1.1.5-SNAPSHOT.tar.gz上传到Linux服务器,然后解压到指定目录/home/server,可使用如下命令解压
tar xvzf canal.deployer-1.1.5-SNAPSHOT.tar.gz -C /home/server/canal-server工作目录如下

修改conf/example/instance.properties文件,主要注意以下几处:
canal.instance.master.address: #数据库地址,例如127.0.0.1:3306
canal.instance.dbUsername: #数据库用户
canal.instance.dbPassword: #数据库密码
完整内容如下
#################################################
## mysql serverId , v1.0.26+ will autoGen
# canal.instance.mysql.slaveId=0
# enable gtid use true/false
canal.instance.gtidon=false
# position info
canal.instance.master.address=127.0.0.1:3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=Liuzifeng123.
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=mysql\\.slave_.*
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=example
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6
#################################################
启动canal-server并查看日志
./bin/startup.sh
cat logs/canal/canal.log
6、canal-adapter的使用
将我们下载好的压缩包canal.adapter-1.1.5-SNAPSHOT.tar.gz上传到Linux服务器,然后解压到指定目录/home/adpter,解压完成后目录结构如下

修改conf/application.yml文件,主要注意如下内容,由于是yml文件,注意我这里说明的属性名称:
server.port: #canal-adapter端口号
canal.conf.canalServerHost: #canal-server地址和ip
canal.conf.srcDataSources.defaultDS.url: #数据库地址
canal.conf.srcDataSources.defaultDS.username: #数据库用户名
canal.conf.srcDataSources.defaultDS.password: #数据库密码
canal.conf.canalAdapters.groups.outerAdapters. #hosts:es主机地址,tcp端口
完整内容如下
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
flatMessage: true
zookeeperHosts:
syncBatchSize: 1000
retries: 0
timeout:
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
canal.tcp.server.host: 127.0.0.1:11111
canal.tcp.zookeeper.hosts:
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
# kafka consumer
kafka.bootstrap.servers: 127.0.0.1:9092
kafka.enable.auto.commit: false
kafka.auto.commit.interval.ms: 1000
kafka.auto.offset.reset: latest
kafka.request.timeout.ms: 40000
kafka.session.timeout.ms: 30000
kafka.isolation.level: read_committed
kafka.max.poll.records: 1000
# rocketMQ consumer
rocketmq.namespace:
rocketmq.namesrv.addr: 127.0.0.1:9876
rocketmq.batch.size: 1000
rocketmq.enable.message.trace: false
rocketmq.customized.trace.topic:
rocketmq.access.channel:
rocketmq.subscribe.filter:
# rabbitMQ consumer
rabbitmq.host:
rabbitmq.virtual.host:
rabbitmq.username:
rabbitmq.password:
rabbitmq.resource.ownerId:
srcDataSources:
defaultDS:
url: jdbc:mysql://127.0.0.1:3306/elasticsearch?useUnicode=true
username: canal
password: Liuzifeng123.
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
# - name: rdb
# key: mysql1
# properties:
# jdbc.driverClassName: com.mysql.jdbc.Driver
# jdbc.url: jdbc:mysql://127.0.0.1:3306/mytest2?useUnicode=true
# jdbc.username: root
# jdbc.password: 121212
# - name: rdb
# key: oracle1
# properties:
# jdbc.driverClassName: oracle.jdbc.OracleDriver
# jdbc.url: jdbc:oracle:thin:@localhost:49161:XE
# jdbc.username: mytest
# jdbc.password: m121212
# - name: rdb
# key: postgres1
# properties:
# jdbc.driverClassName: org.postgresql.Driver
# jdbc.url: jdbc:postgresql://localhost:5432/postgres
# jdbc.username: postgres
# jdbc.password: 121212
# threads: 1
# commitSize: 3000
# - name: hbase
# properties:
# hbase.zookeeper.quorum: 127.0.0.1
# hbase.zookeeper.property.clientPort: 2181
# zookeeper.znode.parent: /hbase
- name: es7
hosts: 192.168.44.128:9200 # 127.0.0.1:9200 for rest mode
properties:
mode: rest # or rest
# security.auth: test:123456 # only used for rest mode
cluster.name: elasticsearch-spring
# - name: kudu
# key: kudu
# properties:
# kudu.master.address: 127.0.0.1 # ',' split multi address
添加配置文件canal-adapter/conf/es7/product.yml,用于配置MySQL中的表与Elasticsearch中索引的映射关系
dataSourceKey: defaultDS
destination: example
groupId: g1
esMapping:
_index: es_test
_id: _id
sql: "SELECT t.id AS _id,
t.id,
t.count,
t.name,
t.color FROM es_test t"
commitBatch: 3000 | esMapping._index | 在Elasticsearch实例中所创建的索引的名称。本文使用es_test。 |
| esMapping._type | 在Elasticsearch实例中所创建的索引的类型。本文使用_doc。 |
| esMapping._id | 需要同步到Elasticsearch实例的文档的id,可自定义。本文使用_id。 |
| esMapping.sql | SQL语句,用来查询需要同步到Elasticsearch中的字段。本文使用select t.id as _id,t.id,t.count,t.name,t.color from es_test t |
启动Canal-adapter服务,并查看日志
./bin/startup.sh
cat logs/adapter/adapter.log 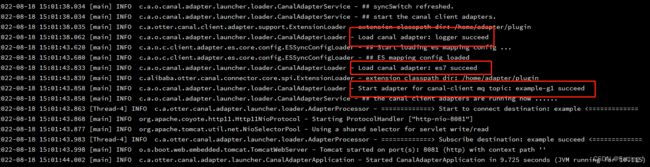
四、数据同步演示
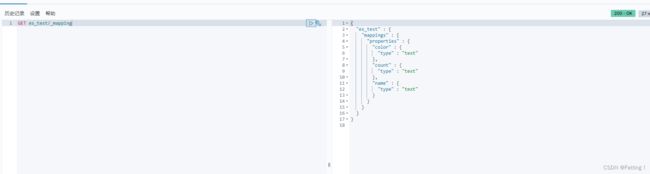
利用kibana dev-tools页面创建es的索引,创建成功后,确保得到如图所示的回显

创建完成后查看索引结构
在mysql数据库中插入一条数据
insert into es_test(count,name,color) values ('6','abc','pink');创建成功后,在Elasticsearch中搜索下,发现数据已经同步了
GET es_test/_search