简化Mybatis的使用——通用Mapper
使用通用Mapper的目的是为了替我们生成常用增删改查操作的SQL语句,并能够简化对于Mybatis的操作。
一、快速入门
1.1 数据库表的创建
CREATE TABLE `tabple_emp` (
`emp_id` INT NOT NULL AUTO_INCREMENT,
`emp_name` VARCHAR ( 500 ) NULL,
`emp_salary` DOUBLE ( 15, 5 ) NULL,
`emp_age` INT NULL,
PRIMARY KEY ( `emp_id` )
);
INSERT INTO `tabple_emp` ( `emp_name`, `emp_salary`, `emp_age` )
VALUES
( 'tom', '1254.37', '27' );
INSERT INTO `tabple_emp` ( `emp_name`, `emp_salary`, `emp_age` )
VALUES
( 'jerry', '6635.42', '38' );
INSERT INTO `tabple_emp` ( `emp_name`, `emp_salary`, `emp_age` )
VALUES
( 'bob', '5560.11', '40' );
INSERT INTO `tabple_emp` ( `emp_name`, `emp_salary`, `emp_age` )
VALUES
( 'kate', '2209.11', '22' );
INSERT INTO `tabple_emp` ( `emp_name`, `emp_salary`, `emp_age` )
VALUES
( 'justin', '4203.15', '30' );
1.2 对应实体类的创建
基本数据类型在Java类中都有默认值,会导致Mybatis在执行相关操作时很难判断当前字段是否为Null。因此,在Mybatis环境下使用Java实体类时尽量不要使用基本数据类型,都使用对应的包装类型。
public class Employee implements Serializable {
private Integer empId;
private String empName;
private Double empSalary;
private Integer empAge;
public Employee() {
}
public Employee(Integer empId, String empName, Double empSalary, Integer empAge) {
this.empId = empId;
this.empName = empName;
this.empSalary = empSalary;
this.empAge = empAge;
}
// 省略了getter、setter以及toString()方法的展示
}
1.3 Spring-SpringMVC-Mybatis的整合
整合步骤见此文ssm框架的整合。
二、通用Mapper的MBG
原生的MBG和通用的MBG做对比。
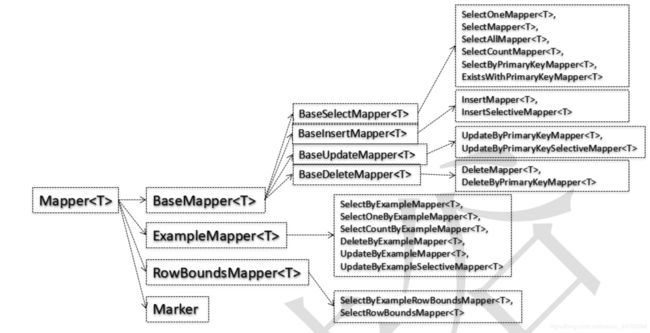
通用Mapper的逆向工程,通过其特点的插件,同样的生成Java实体类对象,带有注解(@Id、@Column等注解);在dao接口层,即mapper接口继承通用Mapper中核心的接口Mapper;生成的实体类Mapper文件(XXxMapper文件)没有SQL语句标签。
当通用Mapper与Spring或SpringBoot整合完以后,通用Mapper的MBG可参考官方文档使用Maven执行MBG的方式。
2.1 自定义Mapper接口
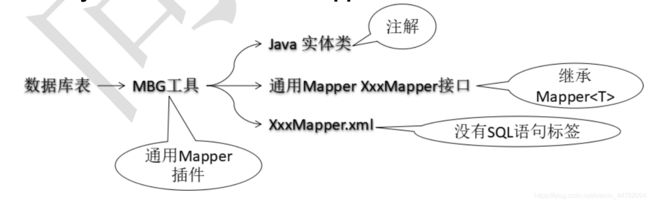
其自己的Mapper接口层次结构如上所示。
作用,根据我们自身的需要,继承上方的层级结构中的mapper接口,供我们自身开发。
举例:
自定义接口:
自定义的Mapper不能和原有的实体类Mapper放在同一级的目录下。
public interface MyInterface<T> extends BaseMapper<T>, ExampleMapper<T> {
}
@Repository
public interface EmployeeMapper extends MyMapper<Employee> {
}
配置MapperScannerConfigurer注册MyMapper,或者在我们自定义的Mapper接口中加入注解@RegisterMapper
!-- 配置扫描器,将mybatis接口的实现加入到ioc容器中 -->
<bean class="tk.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="cn.lizhi.dao">property>
<property name="properties">
<value>
mapper=cn.lizhi.myInterface.MyMapper
value>
property>
bean>
其中value值默认的是原生mapper的值。
2.2 通用Mapper接口扩展
其扩展用来指增加通用Mapper中没有提供的功能。
示例:批量更新。
思路:当我们写SQL语句时,如何能做到批量更新呢?即用;分割我们需要更新的SQL语句。
UPDATE table_emp SET emp_name=?,emp_age=?,emp_salary=? WHERE emp_id=?;
UPDATE table_emp SET emp_name=?,emp_age=?,emp_salary=? WHERE emp_id=?;
UPDATE table_emp SET emp_name=?,emp_age=?,emp_salary=? WHERE emp_id=?;
UPDATE table_emp SET emp_name=?,emp_age=?,emp_salary=? WHERE emp_id=?;
...
那么Mybatis又是如何做到上面这种形式的呢?即,通过foreach标签达到语句的拼接。
UPDATE table_emp
SET
emp_name=#{record.empName},
emp_age=#{record.empAge},
emp_salay=#{record.empSalary}
WhERE emp_id=#{record.empId}
即我们需要使用通用Mapper能够做到动态的生成上面的SQL语句,供我们使用,即可做到接口的扩展。
2.2.1 需要提供的接口和实现类

在我们自定义的MyMapper接口中除了需要继承Mapper中下方层次结构的接口,它还需要继承我们自己自定义功能的Mapper接口,这里是MyBatchUpdateProvider。
其中MyBatchUpdateProvider是我们自己编写的类(需要继承模板),用于解析xml的SQL语句。
代码示例:
首先编写我们自定义的接口MyBatchUpdateMapper。
@RegisterMapper
public interface MyBatchUpdateMapper<T> {
@UpdateProvider(type=MyBatchUpdateProvider.class, method="dynamicSQL")
void batchUpdateMapper(List<T> list);
}
这里的batchUpdateMapper就是我们后续需要生成模板代码的方法。
编写MyBatchUpdateProvider类,继承MapperTemplate
public class MyBatchUpdateProvider extends MapperTemplate {
public MyBatchUpdateProvider(Class<?> mapperClass, MapperHelper mapperHelper) {
super(mapperClass, mapperHelper);
}
/** 下方的函数目的是为了拼接此字符串,但是需要能做到通用性,又不仅仅局限于下面的单一情况
*
UPDATE table_emp
emp_name=#{record.empName},
emp_age=#{record.empAge},
emp_salay=#{record.empSalary},
WhERE emp_id=#{record.empId},
*/
public String batchUpdateMapper(MappedStatement ms) {
final Class<?> entityClass = super.getEntityClass(ms); // 用于获取实体类对象
final String tableName = super.tableName(entityClass); // 用于获取实体类对应的表名
// 修改返回值类型为实体类型
super.setResultType(ms, entityClass);
// 拼接动态SQL语句
StringBuilder sql = new StringBuilder(); // 用于生成最终的SQL语句
sql.append("" ); // foreach的开标签
String updateClause = SqlHelper.updateTable(entityClass, tableName); // 设置实体类对象、表的映射
sql.append(updateClause); // 生成 UPDATE 部分
sql.append("" );
Set<EntityColumn> columns = EntityHelper.getColumns(entityClass); // 获取实体属性对象
String Id_column = null;
String Id_columnHolder = null;
for (EntityColumn entityColumn : columns) {
boolean flag = entityColumn.isId();
if (flag) { // 判断是否是主键
Id_column = entityColumn.getColumn(); // 主键实体类名
Id_columnHolder = entityColumn.getColumnHolder("record");
} else {
String column = entityColumn.getColumn(); // 对应属性的名称
String columnHolder = entityColumn.getColumnHolder("record"); // 通过record进行引用,和foreach中相同
sql.append(column).append("=").append(columnHolder).append(",");
}
}
sql.append("");
sql.append("where ").append(Id_column).append("=").append(Id_columnHolder);
sql.append(""); // foreach的闭标签
return sql.toString();
}
}
这里通用代码编写的方法要和我们前面接口中定义的方法名相同,这个方法就是最后我们使用接口时,需要使用的方法。
最后,编写我们自定义的Mapper。
@RegisterMapper
public interface MyMapper<T> extends Mapper<T>,MyBatchUpdateMapper<T> {
}
在使用时,我们实体类Mapper接口中的用法为:
@Repository
public interface EmployeeMapper extends MyMapper<Employee> {
}
即,只需要继承我们自定义的Mapper即可。
测试类编写:
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:applicationContext.xml")
public class MapperTest {
@Autowired
private EmployeeService employeeService;
@Test
public void batchUpdateEmployeeTest() {
List<Employee> list = new ArrayList<Employee>();
Employee emp01 = new Employee(1, "小明", 120000d, 18);
Employee emp02 = new Employee(2, "小红", 130000d, 19);
Employee emp03 = new Employee(3, "小黑", 140000d, 20);
Employee emp04 = new Employee(4, "小娜", 150000d, 21);
list.add(emp01);
list.add(emp02);
list.add(emp03);
list.add(emp04);
employeeService.batchUpdateEmployee(list);
}
}
主要需要在dbConfig.xml中的url里配置上批量查询的请求参数,即:
jdbc.url=jdbc:mysql://localhost:3306/mybatis_mapper?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true
2.3 通用Mapper的二级缓存方式
对同一内容查询两次,其查询两次数据库,默认并没有将第一次查询的内容进行缓存。
@Test
public void findAll() {
List<Employee> employees = employeeService.findAll();
for (Employee employee : employees) {
System.out.println(employee);
}
System.out.println("----");
List<Employee> employeeList = employeeService.findAll();
for (Employee employee : employeeList) {
System.out.println(employee);
}
}
加入二级缓存方式:
- 在
Mybatis全局配置文件mybatis-config.xml中开启二级缓存。
<configuration>
<settings>
<setting name="cacheEnabled" value="true"/>
settings>
configuration>
- 实体类的Mapper接口加入
@CacheNamespace注解
@Repository
@CacheNamespace
public interface EmployeeMapper extends MyMapper<Employee> {
}
2.4 实体类中含有复杂类型的注入
2.4.1 简单类型和复杂类型
- 基本数据类型:
byte、char、short、int、float、double、boolean - 引用类型:
类、接口、数据、枚举... - 简单类型:
只有一个值的类型 - 复杂类型:
多个简单类型组合起来
2.4.2 准备工作 —— 相关类的创建
创建复杂类型的类。即创建一张表table_user,表的每个字段对应下面User实体类的属性,并没有进行主从表的建设,而是直接使用一张表进行操作。其对应的实体类如下:
@Table(name="table_user")
public class User {
@Id
@Column(name = "user_id")
private Integer userId;
private String userName;
private Address address;
private SeasonEnum season;
// 省略个无参数、有参数构造器以及getter、setter和toString方法
}
Address类:
public class Address {
private String province;
private String city;
private String street;
public Address() {
// TODO Auto-generated constructor stub
}
public Address(String province, String city, String street) {
this.province = province;
this.city = city;
this.street = street;
}
// 省略getter、setter以及toString()方法
}
SeasonEnum类:
public enum SeasonEnum {
SPRING("spring @_@"),SUMMER("summer @_@"),AUTUMN("autumn @_@"),WINTER("winter @_@");
private String seasonName;
private SeasonEnum(String seasonName) {
this.seasonName = seasonName;
}
public String getSeasonName() {
return this.seasonName;
}
public String toString() {
return this.seasonName;
}
}
数据库表的建立:
DROP TABLE if EXISTS table_user;
CREATE TABLE table_user(
user_id INT NOT NULL AUTO_INCREMENT,
user_name VARCHAR(32) NULL,
address VARCHAR(32) NULL,
season ENUM("summer @_@","spring @_@","autumn @_@","winter @_@") NULL,
PRIMARY KEY (user_id)
)
当使用通用mapper对其进行表的查询时,例如:
@Test
public void testQueryUser() {
Integer userId = 1;
User user = userService.findById(userId);
System.out.println(user);
}
返回结果:
User [userId=1, userName=Justin, address=null, season=null]
自动忽略复杂类型的属性注入。对复杂类型不进行"从类到表"的映射。
解决办法:采用typeHandler。设定一种规则,实现复杂类型中的字段和实体类属性的映射。即自定义类型转换器。这里举例,针对Address对象。
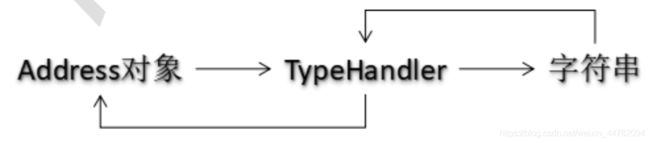
首先顶级接口:TypeHandler,其实现接口为:
public abstract class BaseTypeHandler是一个抽象类,其抽象方法:
// 将parameter对象转换为字符串存入到ps对象的i位置上,此方法对应从Address转换为字符串
public abstract void setNonNullParameter(PreparedStatement ps, int i, T parameter, JdbcType jdbcType) throws SQLException;
// 从结果集中获取数据库中对应查询结果;分别从列名、列索引、CallableStatement中获取
// 将字符串还原为原始的T类型对象
// 此三种方法对应从字符串转换为Address对象
public abstract T getNullableResult(ResultSet rs, String columnName) throws SQLException;
public abstract T getNullableResult(ResultSet rs, int columnIndex) throws SQLException;
public abstract T getNullableResult(CallableStatement cs, int columnIndex) throws SQLException;
2.4.3 自定义类型处理器的编写
接下来编写AddressHandler转换器的编写 —— 各个值之间使用,分开
public class AddressHandler extends BaseTypeHandler<Address> {
@Override
public void setNonNullParameter(PreparedStatement ps, int i, Address parameter, JdbcType jdbcType) throws SQLException {
// 对象为空则直接返回
if (parameter == null) {
return;
}
// 定义以 , 进行分割、拼接字符串
StringBuilder builder = new StringBuilder();
String province = parameter.getProvince();
String city = parameter.getCity();
String street = parameter.getStreet();
builder.append(province)
.append(",")
.append(city)
.append(",")
.append(street);
ps.setString(i, builder.toString());
}
@Override
public Address getNullableResult(ResultSet rs, String columnName) throws SQLException {
String parameter = rs.getString(columnName);
// Address字段中不含值或者没有按规则存放,则返回Null
if (parameter == null || parameter.length() == 0 || !parameter.contains(",")) {
return null;
}
Address address = new Address();
address.setProvince(parameter.split(",")[0]);
address.setCity(parameter.split(",")[1]);
address.setStreet(parameter.split(",")[2]);
return address;
}
@Override
public Address getNullableResult(ResultSet rs, int columnIndex) throws SQLException {
String parameter = rs.getString(columnIndex);
// Address字段中不含值或者没有按规则存放,则返回Null
if (parameter == null || parameter.length() == 0 || !parameter.contains(",")) {
return null;
}
Address address = new Address();
address.setProvince(parameter.split(",")[0]);
address.setCity(parameter.split(",")[1]);
address.setStreet(parameter.split(",")[2]);
return address;
}
@Override
public Address getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {
String parameter = cs.getString(columnIndex);
// Address字段中不含值或者没有按规则存放,则返回Null
if (parameter == null || parameter.length() == 0 || !parameter.contains(",")) {
return null;
}
Address address = new Address();
address.setProvince(parameter.split(",")[0]);
address.setCity(parameter.split(",")[1]);
address.setStreet(parameter.split(",")[2]);
return address;
}
}
2.4.4 注册自定义类型处理器
2.4.4.1 方法一、字段级别:@ColumnType注解
即在对应的实体类中的属性上加入@ColumnType(typeHandler=AddressTypeHandler.class)注解进行标定。
这里是在User中的Address属性上加入此注解。
2.4.4.2 方法二、全局级别:在Mybatis配置文件中配置typeHandlers
<typeHandlers>
<typeHandler handler="cn.lizhi.Handler.AddressHandler" javaType="cn.lizhi.domain.Address"/>
typeHandlers>
此时对Address类复杂类型的注入进行测试,查询的返回结果:
@Test
public void testQueryUser() {
Integer userId = 1;
User user = userService.findById(userId);
System.out.println(user);
}
/**
User [userId=1, userName=Justin, address=Address{province='aaa', city='bbb', street='ccc'}, season=null]
**/
2.4.5 枚举类型的转换
方法一:让通用Mapper把枚举类型作为简单类型处理
增加一个通用mapper的配置项,即在通用mapper的配置项中配置enumAsSimpleType=true,其本质是使用了EnumTypeHandler处理器。
方法二:为枚举类型配置对应的类型处理器
思路同Address转换为String,和String转化为Address思路相同。可以将枚举对象和String相互转换。
配置类型处理器
-
内置
org.apache.ibatis.type.EnumTypeHandler:在数据库中配置的是枚举值本身org.apache.ibatis.type.EnumOrdinalTypeHandler:在数据库中存的是枚举类型的索引值(因为在枚举类型中,值是固定的)
-
自定义
-
内置处理器使用说明
不能使用
@ColumnType注解注册Mybatis原生注解;只能在Mybatis全局配置文件中进行属性配置,并在属性上使用@Column注解。如:<typeHandler handler="org.apache.ibatis.type.EnumTypeHandler" javaType="cn.lizhi.domain.SeasonEnum"/>
附
通用Mapper官方文档