用openCV和TensorFlow完成实时手势识别
项目中用到的object-detection-api的git地址为:https://github.com/tensorflow/models
项目中提到的代码的git地址为:https://github.com/aspirinone/Tensorflow-Practice
该项目分为以下几个步骤:
一、利用OpenCV收集手势数据并标注
二、制作VOC2012数据集并导出tf.record文件
三、配置config文件并进行训练
四、将训练模型导出、用tensorboard查看训练过程
-
手势数据收集
方法:使用摄像头和OpenCV完成数据收集
具体代码:video_handset.py
import cv2 as cv
import numpy as np
capture = cv.VideoCapture(0)
index = 5
nn = 578
while True:
ret,frame = capture.read()
if ret is True:
cv.imshow("frame",frame)
index += 1
if index % 5 == 0 :
nn = nn+1
cv.imwrite("D:/day_02/"+str(nn)+".jpg",frame)
c = cv.waitKey(50)
if c == 27:
break
else:
break
cv.destroyAllWindows()
1、运行代码后在文件夹中挑选图片,将不标准的图片删除,否则会影响训练后的效果。(注意图片格式为jpg,且按顺序命名。如果后续标注的时候再删除,可能会有xml文件对应错误的情况。所以这一步筛查图片一定要仔细。)

2、下载标注工具labelImg,并在他的predefined_classes.txt进行修改,加入我们要识别的手势的标注,这里的标注必须没有空格号,比如,我打算识别的是以下四种手势:“Yeah”、“Fist”、“PalmsForward”、“OK”
-
制作VOC数据格式
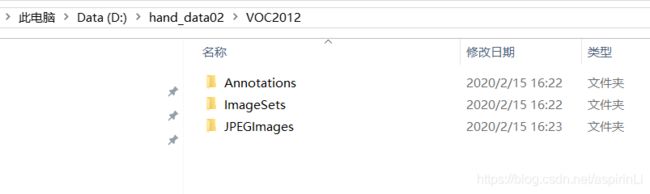
注意:VOC数据的文件夹有严格的命名与放置,如下:

- 新建一个文件夹,并按照上面的摆放新建各个文件夹,将收集到的图片放到JPGImages下。
- 执行test.py中的change_to_num()函数,该函数可以将图片重新排序。如果之前的图片是png,也可在此时改成jpg。
def change_to_num():
files = os.listdir(root_dir)
index = 0
for img_file in files:
if os.path.isfile(os.path.join(root_dir,img_file)):
index += 1
image_path = os.path.join(root_dir,img_file)
print(image_path)
image = cv.imread(image_path)
#print(image_path.replace("png","jpg"))
cv.imwrite("D:/hand_data02/VOC2012/JPEGImages/"+ str(index) +".jpg",image)
- 接下来开始数据标注:w是选定区域的快捷键。数据标注是一个漫长的过程……
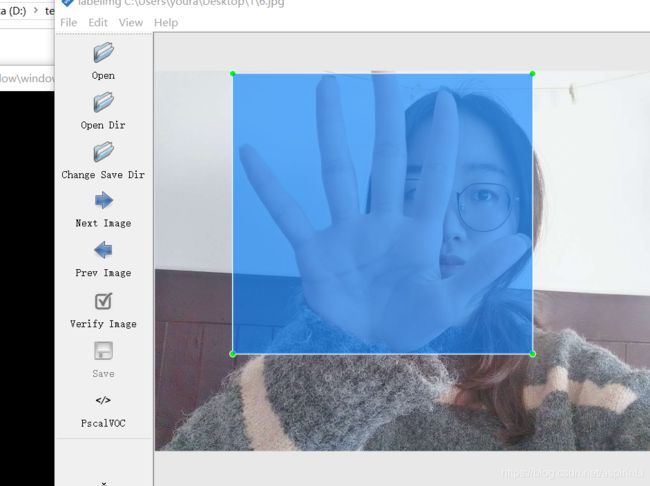
需要注意的是生成的xml文件有严格的要求。
我们现在得到的xml文件里的内容是这样的:
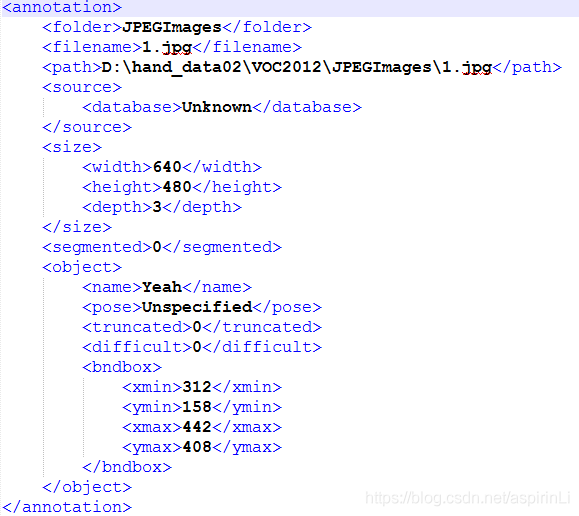
标注大约花了两个小时(773张图)。由于
def xml_modification():
ann_dir = "D:/hand_data02/VOC2012/Annotations"
files = os.listdir(ann_dir)
for xml_file in files:
if os.path.isfile(os.path.join(ann_dir,xml_file)):
xml_path = os.path.join(ann_dir,xml_file)
tree = ET.parse(xml_path)
root = tree.getroot()
for elem in root.iter('folder'):
elem.text = 'VOC2012'
#for elem in root.iter('name'):
#name = elem.text
#elem.text = name.replace(" ","")
tree.write(xml_path)最后必须是下面这样的格式(校对一下
在D:\hand_data02\VOC2012\ImageSets\Main路径下新建8个文本文档,因为我们要识别4个种类,每个类型都有一个train和一个val (需要把随机一个种类命名为aeroplane,否则后续可能会报错)

运行test.py中的generate_clasess_text()函数:
def generate_classes_text():
print("start to generate classes text:")
ann_dir = "D:/hand_data02/VOC2012/Annotations/"
aeroplane_train = open("D:/hand_data02/VOC2012/ImageSets/Main/aeroplane_train.txt",'w')
aeroplane_val = open("D:/hand_data02/VOC2012/ImageSets/Main/aeroplane_val.txt", 'w')
fist_train = open("D:/hand_data02/VOC2012/ImageSets/Main/fist_train.txt", 'w')
fist_val = open("D:/hand_data02/VOC2012/ImageSets/Main/fist_val.txt", 'w')
yeah_train = open("D:/hand_data02/VOC2012/ImageSets/Main/yeah_train.txt", 'w')
yeah_val = open("D:/hand_data02/VOC2012/ImageSets/Main/yeah_val.txt", 'w')
ok_train = open("D:/hand_data02/VOC2012/ImageSets/Main/ok_train.txt", 'w')
ok_val = open("D:/hand_data02/VOC2012/ImageSets/Main/ok_val.txt", 'w')
files = os.listdir(ann_dir)
for xml_file in files:
if os.path.isfile(os.path.join(ann_dir,xml_file)):
xml_path = os.path.join(ann_dir,xml_file)
tree = ET.parse(xml_path)
root = tree.getroot()
for elem in root.iter('filename'):
filename = elem.text
for elem in root.iter('name'):
name = elem.text
if name =="PalmsForward":
aeroplane_train.write(filename.replace(".jpg"," ")+str(1)+"\n")
aeroplane_val.write(filename.replace(".jpg", " ") + str(1) + "\n")
fist_train.write(filename.replace(".jpg", " ") + str(-1) + "\n")
fist_val.write(filename.replace(".jpg", " ") + str(-1) + "\n")
yeah_train.write(filename.replace(".jpg", " ") + str(-1) + "\n")
yeah_val.write(filename.replace(".jpg", " ") + str(-1) + "\n")
ok_train.write(filename.replace(".jpg", " ") + str(-1) + "\n")
ok_val.write(filename.replace(".jpg", " ") + str(-1) + "\n")
if name == "Fist":
aeroplane_train.write(filename.replace(".jpg", " ") + str(-1) + "\n")
aeroplane_val.write(filename.replace(".jpg", " ") + str(-1) + "\n")
fist_train.write(filename.replace(".jpg", " ") + str(1) + "\n")
fist_val.write(filename.replace(".jpg", " ") + str(1) + "\n")
yeah_train.write(filename.replace(".jpg", " ") + str(-1) + "\n")
yeah_val.write(filename.replace(".jpg", " ") + str(-1) + "\n")
ok_train.write(filename.replace(".jpg", " ") + str(-1) + "\n")
ok_val.write(filename.replace(".jpg", " ") + str(-1) + "\n")
if name == "Yeah":
aeroplane_train.write(filename.replace(".jpg", " ") + str(-1) + "\n")
aeroplane_val.write(filename.replace(".jpg", " ") + str(-1) + "\n")
fist_train.write(filename.replace(".jpg", " ") + str(-1) + "\n")
fist_val.write(filename.replace(".jpg", " ") + str(-1) + "\n")
yeah_train.write(filename.replace(".jpg", " ") + str(1) + "\n")
yeah_val.write(filename.replace(".jpg", " ") + str(1) + "\n")
ok_train.write(filename.replace(".jpg", " ") + str(-1) + "\n")
ok_val.write(filename.replace(".jpg", " ") + str(-1) + "\n")
if name == "OK":
aeroplane_train.write(filename.replace(".jpg", " ") + str(-1) + "\n")
aeroplane_val.write(filename.replace(".jpg", " ") + str(-1) + "\n")
fist_train.write(filename.replace(".jpg", " ") + str(-1) + "\n")
fist_val.write(filename.replace(".jpg", " ") + str(-1) + "\n")
yeah_train.write(filename.replace(".jpg", " ") + str(-1) + "\n")
yeah_val.write(filename.replace(".jpg", " ") + str(-1) + "\n")
ok_train.write(filename.replace(".jpg", " ") + str(1) + "\n")
ok_val.write(filename.replace(".jpg", " ") + str(1) + "\n")
aeroplane_train.close()
aeroplane_val.close()
fist_train.close()
fist_val.close()
yeah_train.close()
yeah_val.close()
ok_train.close()
ok_val.close()得到这8个文本的内容格式是这样的(第一个数代表编号,第二个数代表是否为识别的手势):
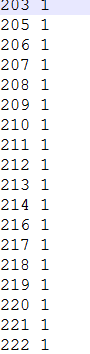
- 生成tf.record文件
在VOC2012同级目录下新建一个hand_label_map.pbtxt。内容如下:

在D:\tensorflow\handset02路径下新建三个文件夹,用来放导出的模型

在控制台执行下列语句,于是得到tf.record文件:

-
配置文件修改及模型训练
将hand_label_map.pbtxt文件拷贝至于record文件同级目录
我们用的训练模型是SSD v1 将这个config文件拷贝到D:\tensorflow\handset02\model路径下,并进行修改。需要修改的地方如下:
识别的种类:

迁移学习使用的模型:
![]()
Record文件的路径和map路径(前面已经将pbtxt文件拷贝过来)

Eval处同样需要修改这两处路径:

改好后保存。
-
训练
在控制台执行以下命令:

就会开始训练了。
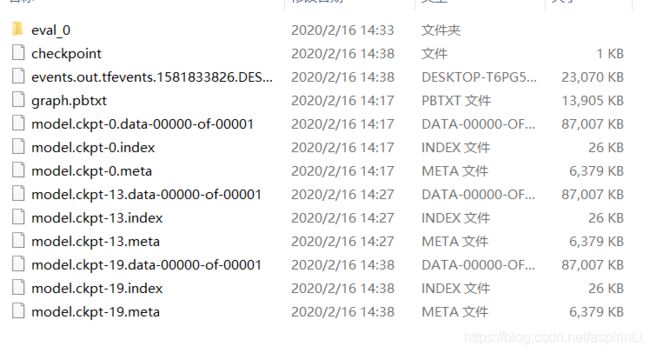
训练过程中会不断地在D:\tensorflow\handset02\model\train路径下生成以下模型文件:
-
模型导出
在控制台执行下面的命令

模型导出后得到如下文件:
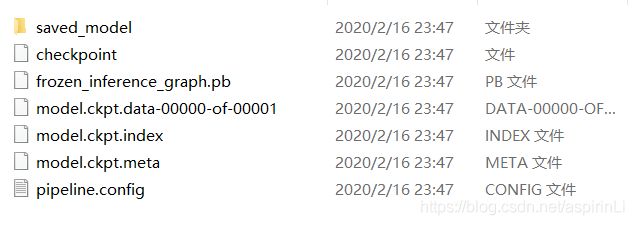
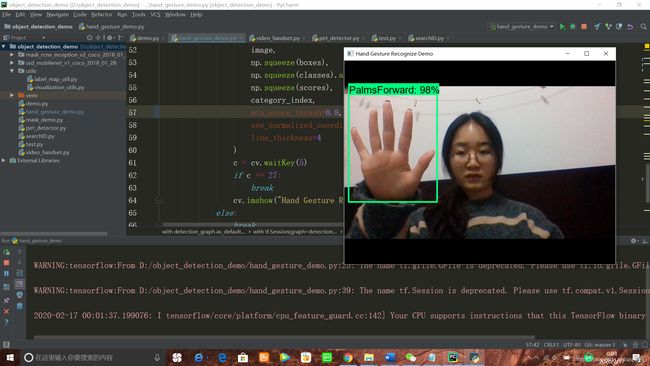
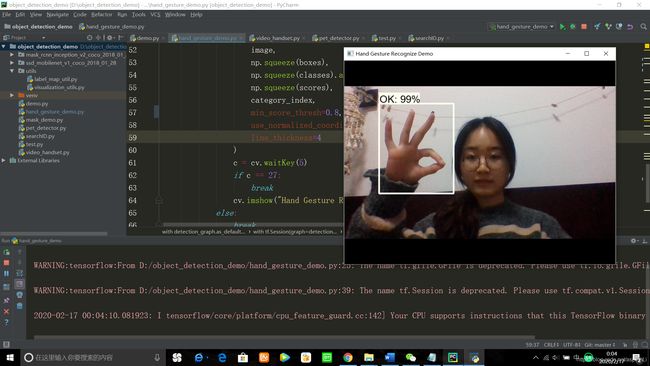
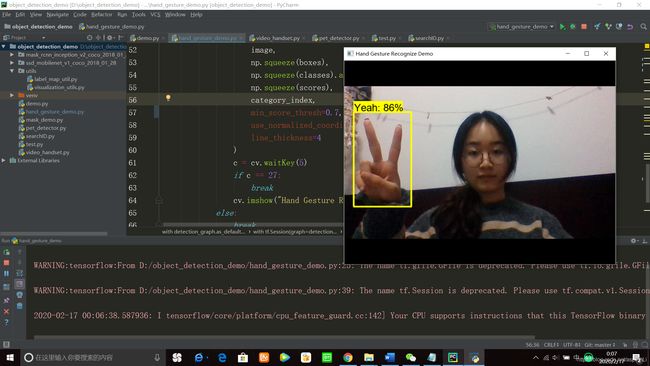
接下来就可以用我们的冻结推断图来识别啦!执行的代码如下:
import os
import sys
import tarfile
import cv2 as cv
import numpy as np
import tensorflow as tf
from utils import label_map_util
from utils import visualization_utils as vis_util
PATH_TO_FROZEN_GRAPH = 'D:/tensorflow/handset02/export/frozen_inference_graph.pb'
PATH_TO_LABELS = os.path.join('D:/tensorflow/handset02/data','hand_label_map.pbtxt')
NUM_CLASSES = 4
detection_graph = tf.Graph()
capture = cv.VideoCapture(0)
#capture.set(cv.CAP_PROP_FRAME_WIDTH,640)
#capture.set(cv.CAP_PROP_FRAME_HEIGHT,480)
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_FROZEN_GRAPH,'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def,name = '')
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categorys = label_map_util.convert_label_map_to_categories(label_map,max_num_classes=NUM_CLASSES,use_display_name=True)
category_index = label_map_util.create_category_index(categorys)
def load_image_into_numpy(image):
(im_w,im_h) = image.size
return np.array(image.getdata()).reshape(im_h,im_w,3).astype(np.uint8)
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
while True:
ret,image = capture.read()
if ret is True:
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
scores = detection_graph.get_tensor_by_name('detection_scores:0')
classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
image_np_expanded = np.expand_dims(image,axis=0)
(boxes,scores,classes,num_detections) = sess.run([boxes,scores,classes,num_detections],
feed_dict={image_tensor:image_np_expanded})
vis_util.visualize_boxes_and_labels_on_image_array(
image,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
min_score_thresh=0.5,
use_normalized_coordinates=True,
line_thickness=4
)
c = cv.waitKey(5)
if c == 27:
break
cv.imshow("Hand Gesture Recognize Demo", image)
else:
break
capture.release()
cv.waitKey(0)
cv.destroyAllWindows()出来的效果还是不错滴,其中两个手势效果非常好,握拳的手势检测效果不太好就不放上来啦(忽略我睡前丑颜…)