数据挖掘可视化+机器学习初探
Hallo,各位小伙伴大家好啊!这个专栏是用来分享数据处理以及数据可视化的一些常见操作,以及自己的一些学习笔记,希望能给大家带来帮助呀!感兴趣的小伙伴也欢迎私信或者评论区交流呀!
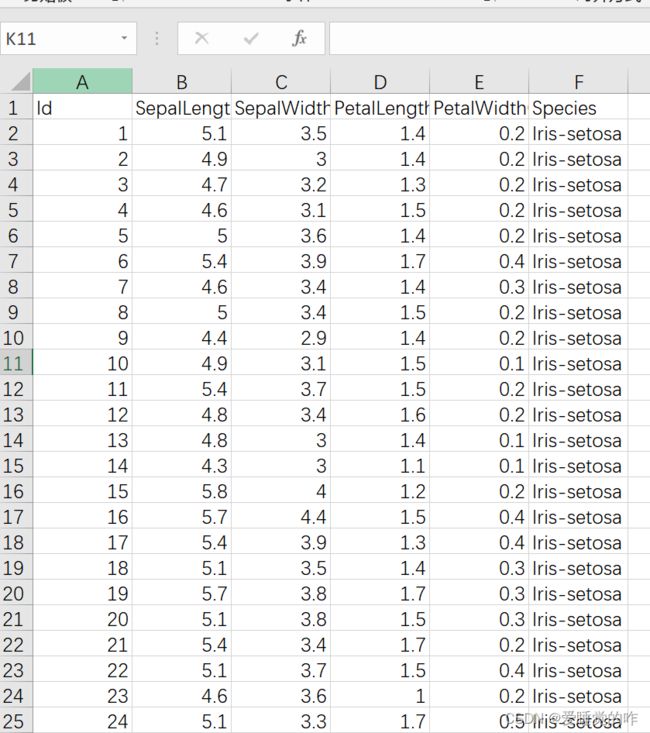
以下可视化的数据来源为名为“”的Excel文件,它有六列,分别是Id、SepalLengthCm、SepalWidthCm、PetalLengthCm、PetalWidthCm、Species。基于这个数据表,进行数据处理和可视化操作:
一、散点图
散点图是指在 回归分析 中,数据点在直角坐标系平面上的 分布图 ,散点图表示因变量随 自变量 而 变化 的大致趋势,据此可以选择合适的函数 对数 据点进行 拟合 。 用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式。
代码如下:
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
df = pd.read_csv("iris.csv")
SepalLengthCm = df["SepalLengthCm"]
SepalWidthCm = df["SepalWidthCm"]
PetalLengthCm = df["PetalLengthCm"]
PetalWidthCm = df["PetalWidthCm"]
x = [i for i in range(1,len(PetalWidthCm)+1)]
color = ['c', 'b', 'g', 'r', 'm', 'y', 'k', 'w']
def func(label,num,name):
plt.scatter(x,label, c=color[num], edgecolors='r')
plt.title(f"{name}散点图")
plt.savefig(f"{name}散点图.png")
plt.show()
func(SepalLengthCm,0,"SepalLengthCm")
func(SepalWidthCm,1,"SepalWidthCm")
func(PetalLengthCm,2,"PetalLengthCm")
func(PetalWidthCm,3,"PetalWidthCm")
效果如下:
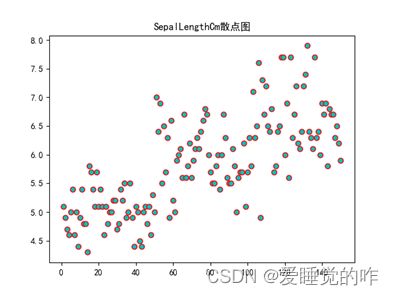
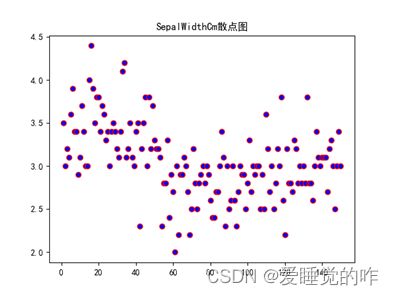
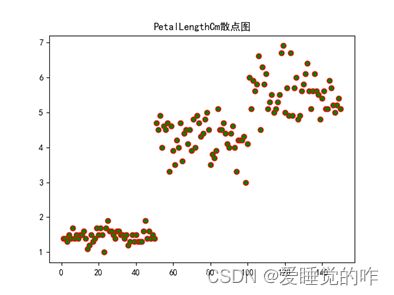
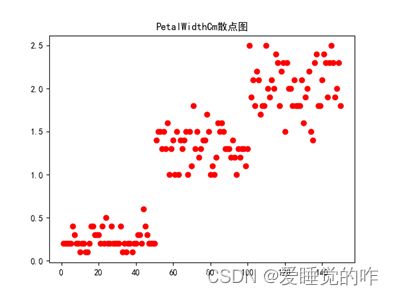
二、热力图
热力图是一种特殊的图表,它是一种通过对色块着色来显示数据的统计图表,在绘图时,需要指定每个颜色映射的规则(一般以颜色的强度或色调为标准);比如颜色越深的表示数值越大、程度越深;颜色越亮的数值越大、程度越深。 热力图适合用于查看总体的情况、观察特殊值或者显示多个变量之间的差异性、检测它们之间是否存在相关性等等。
代码如下:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
data = pd.read_csv('iris.csv',usecols=["SepalLengthCm","SepalWidthCm","PetalLengthCm","PetalWidthCm"])
df = pd.DataFrame(data)
cor = data.corr(method='pearson')
sns.heatmap(cor,
annot=True, # 显示相关系数的数据
center=0.5, # 居中
fmt='.2f', # 只显示两位小数
linewidth=0.5, # 设置每个单元格的距离
linecolor='blue', # 设置间距线的颜色
vmin=0, vmax=1, # 设置数值最小值和最大值
xticklabels=True, yticklabels=True, # 显示x轴和y轴
square=True, # 每个方格都是正方形
cbar=True, # 绘制颜色条
cmap='coolwarm_r', # 设置热力图颜色
)
plt.title("四列属性热力图")
plt.savefig("四列属性热力图.png",dpi=600)#保存图片,分辨率为600
plt.show() #显示图片
效果如下:
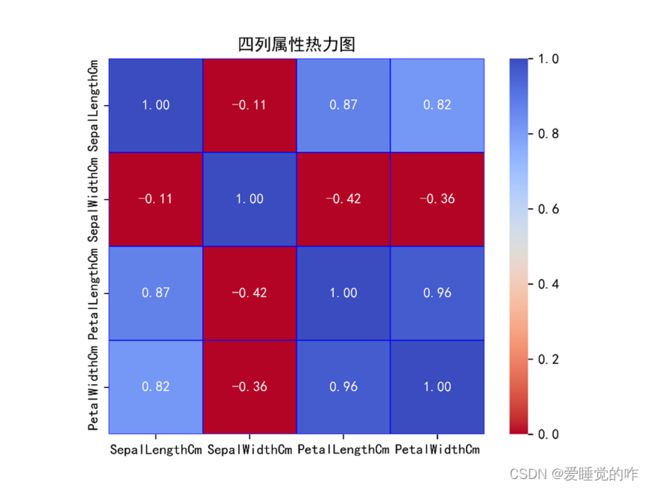
三、回归分析图
在统计学中,回归分析(regression analysis)指的是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。 回归分析按照涉及的变量的多少,分为一元回归和 多元回归分析 ;按照因变量的多少,可分为简单回归分析和多重回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和 非线性回归分析 。
代码如下:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
df = pd.read_csv("iris.csv")
Species = df["Species"]
PetalLengthCm = df["PetalLengthCm"]
PetalWidthCm = df["PetalWidthCm"]
PetalLengthCm_Iris_setosa = df.loc[df["Species"]=="Iris-setosa",["PetalLengthCm"]]
PetalLengthCm_Iris_versicolor = df.loc[df["Species"]=="Iris-versicolor",["PetalLengthCm"]]
PetalLengthCm_Iris_virginica = df.loc[df["Species"]=="Iris-virginica",["PetalLengthCm"]]
PetalWidthCm_Iris_setosa = df.loc[df["Species"]=="Iris-setosa",["PetalWidthCm"]]
PetalWidthCm_Iris_versicolor = df.loc[df["Species"]=="Iris-versicolor",["PetalWidthCm"]]
PetalWidthCm_Iris_virginica = df.loc[df["Species"]=="Iris-virginica",["PetalWidthCm"]]
pd_data = pd.read_csv("iris.csv") # 可用read_csv导入数据
def func(type_A,type_B,color,all_type):
# 划分x,y
exam_X = type_A
exam_Y = type_B
# 将原数据集拆分训练集和测试集
X_train, X_test, Y_train, Y_test = train_test_split(exam_X, exam_Y, train_size=.8)
model = LinearRegression() # 线性回归模型
model.fit(X_train, Y_train) # 模型的成员函数fit(X,y)以数组X和y为输入
a = model.intercept_ # 截距 判断是否有截据,如果没有则直线过原点
b = model.coef_ # 回归系数 模型的成员变量,存储线性模型的系数
# 训练数据预测值
y_train_pred = model.predict(X_train) # 预测
score = model.score(X_test, Y_test) # 可决系数 返回对于以X为samples,以y为target的预测效果评分
# 绘制最佳拟合线:标签用的是训练数据的预测值y_train_pred
plt.plot(X_train, y_train_pred, color='black', linewidth=3)
# 测试数据散点图
plt.scatter(X_test, Y_test, color=color)
plt.scatter(X_train, Y_train, color=color, label=all_type)
# 添加图标标签
plt.legend(loc=2)
def run():
func(PetalLengthCm_Iris_setosa,PetalWidthCm_Iris_setosa,'green',"Iris-setosa")
func(PetalLengthCm_Iris_versicolor,PetalWidthCm_Iris_versicolor,"red","Iris-versicolor")
func(PetalLengthCm_Iris_virginica,PetalWidthCm_Iris_virginica,"blue","Iris-virginica")
plt.gcf().set_facecolor(np.ones(3) * 240 / 255) # 生成画布的大小
plt.grid() # 生成网格
plt.xlabel("PetalLengthCm")
plt.ylabel("PetalWidthCm")
plt.title("PetalLengthCm与PetalWidthCm回归分析图")
plt.savefig("PetalLengthCm与PetalWidthCm回归分析图.png")
plt.show()
run()
效果如下:
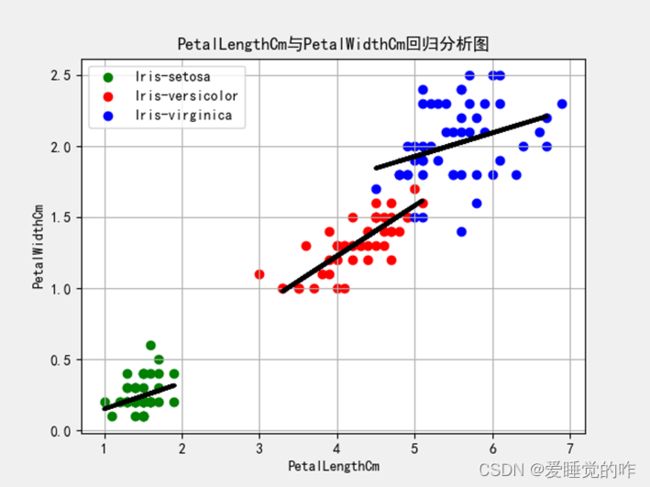
四、 K-means聚类分析图
k均值聚类算法(k-means clustering algorithm)是一种 迭代 求解的聚类分析算法,其步骤是,预将数据分为K组,则随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。
代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
import pandas as pd
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
df = pd.read_csv("iris.csv")
Species = df["Species"]
PetalLengthCm = df["PetalLengthCm"]
PetalWidthCm = df["PetalWidthCm"]
fin_list = []
for i in range(0,len(PetalWidthCm)):
fin_list.append([PetalLengthCm[i],PetalWidthCm[i]])
n_samples = len(PetalWidthCm)
X = np.array(fin_list)
X = StandardScaler().fit_transform(X) #标准化
Kmeans=KMeans(n_clusters=3,random_state=170)
Kmeans.fit(X)
plt.figure(figsize=(8,6))
plt.scatter(X[:,0],X[:,1],c=Kmeans.labels_)
plt.title("K-means聚类分析数据图")
plt.savefig("K-means聚类分析数据图.png")
plt.show()
效果如下:
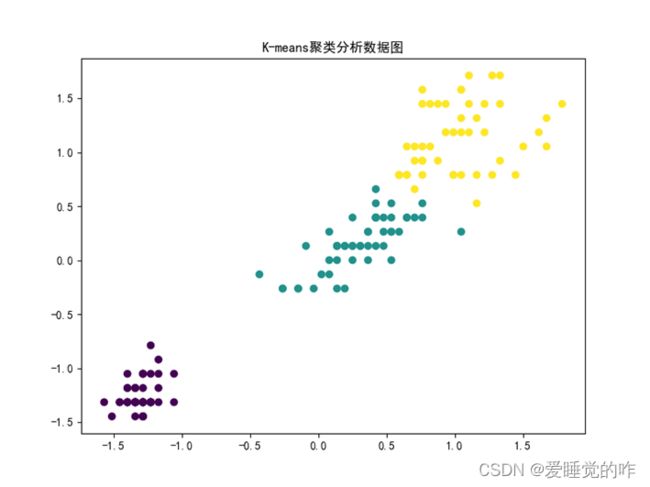
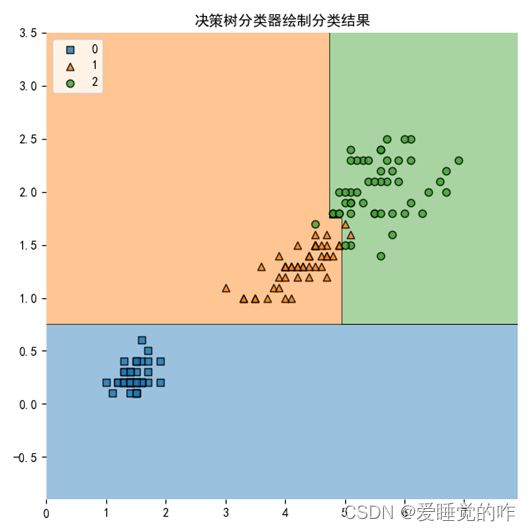
五、决策树分类图
分类树(决策树)是一种十分常用的分类方法。 它是一种监督学习,所谓监督学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。 这样的机器学习就被称之为监督学习
代码如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from mlxtend.plotting import plot_decision_regions
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
df = pd.read_csv("iris.csv")
Species = df["Species"]
PetalLengthCm = df["PetalLengthCm"]
PetalWidthCm = df["PetalWidthCm"]
fin_list = []
label_list = []
for i in range(0,len(PetalWidthCm)):
fin_list.append([PetalLengthCm[i],PetalWidthCm[i]])
n_samples = len(PetalWidthCm)
X = np.array(fin_list)
for i in range(0,len(PetalWidthCm)):
if Species[i] == "Iris-setosa":
label_list.append(0)
elif Species[i] == "Iris-versicolor":
label_list.append(1)
else:
label_list.append(2)
y = np.array(label_list)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y)
clf_tree = DecisionTreeClassifier(criterion='gini', max_depth=4, random_state=1)
clf_tree.fit(X_train, y_train)
X_combined = np.vstack((X_train, X_test))
y_combined = np.hstack((y_train, y_test))
fig, ax = plt.subplots(figsize=(6, 6))
plot_decision_regions(X_combined, y_combined, clf=clf_tree)
plt.legend(loc='upper left')
plt.title("决策树分类器绘制分类结果")
plt.tight_layout()
plt.savefig("决策树分类器绘制分类结果.png")
plt.show()
效果如下:
六、总结
①绘制四列属性SepalWidth、SepalLength、PetalWidth以及PetalLength的散点图:
- 绘制散点图第一想法是用plt.scatter来绘制,以SepalWidth为例:x为1-len(SepalWidth)+1的序列,y即为SepalWidth每个值。
- 因为这里要绘出四个属性的散点图,所以这里定义了一个函数func,参数为label:为四个属性;num:作为color列表的索引,使每个图都有不同的颜色,更加美观也便于区别;name:属性的名称,在最后出图的时候作为标题和图标的名称。
- 用pandas库将文件读取出来,再分别读取四个属性所在的列,因为四个属性的长度都是一样的,所以这里只需要定义一个x序列,再定义一个color列表。
- 函数func封装代码,起到画散点图的作用,最后再传入不同的实参,绘制四列属性SepalWidth、SepalLength、PetalWidth以及PetalLength的散点图。
②绘制四列属性SepalWidth、SepalLength、PetalWidth以及PetalLength的热力图:
- 绘制热力图,要求相关系数,想到用seaborn里面的sns.heatmap,需要设置相关系数的计算方法、位置、是否显示数字、颜色、最大最小值、方框形状等参数。
- 在读取数据时,ID列和标签列不能读入,所以这里用pd.read_csv时要限制读取列:data=pd.read_csv('iris.csv',usecols=["SepalLengthCm","SepalWidthCm","PetalLengthCm","PetalWidthCm"])
- 将数据用corr函数计算后,传入sns.heatmap中,最后加上标题保存后将图片显示出来。
③选取相关系数较大的属性进行回归分析:
- 由第二问可知,PetalLengthCm和PetalWidthCm相关系数最大,为0.96,故要对这两列数据进行回归分析。
- 由参考图可知,需要分类别进行回归分析,即Iris-setosa、Iris-versicolor、Iris-virginica三个属性要分别进行回归分析,这就要求在读取文件后,对数据进行预处理。用df.loc可以 指定列读取指定内容,例如:PetalLengthCm_Iris_setosa = df.loc[df["Species"]=="Iris-setosa",["PetalLengthCm"]]。
- 因为三个属性都要回归分析,所以这里再一次运用的函数封装的思想,定义func可以画出一个回归分析的图,再利用函数run,调用三次func函数,在一个图中将三次的回归分析表现出来。
- 函数func是利用数据集训练线性回归模型,首先将原数据集拆分训练集和测试集,定义一个线性回归模型,模型的成员函数fit(X,y)以数组X和y为输入,再判断是否有截据,如果没有则直线过原点,计算相关系数,并绘制最佳拟合曲线并绘制散点图。
- 函数run是调用三次func函数,每一次向其中传入不同的实参,达到绘制三个列表的回归分析图。
- 最后生成画布和王哥,使结果更加直观。添加标签和坐标、标题等元素,将图片保存后显示出来。
④绘制K-means聚类分析的结果:
- Kmeans聚类主要用的是sklearn.cluster里面的Kmeas,将两列数据读取进来,通过for循环转化为list嵌套列表,再通过np.array转化为矩阵,在进行一次标准化。
- Kmeans聚类,我这里n_clusters=3,即聚成三类,每一类用不同的颜色标注出来,最后加上标题,保存并显示出来。
⑤训练决策树分类器,绘制分类结果:
- 决策树分类主要用的是sklearn.model_selection里面的train_test_split函数以及sklearn.tree里面的DecisionTreeClassifier。
- 首先是数据预处理,读取文件,读取指定列,将PetalLengthCm与PetalWidthCm关联起来,存到一个嵌套列表中,用np.array转化为矩阵。通过类别添加标签0、1、2。用for循环遍历Species中的每一个值,用if语句进行判断,为其添加标签,便于训练决策树模型。
- 划分训练集、测试集:X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y)。
- 再进行决策树模型的训练:clf_tree = DecisionTreeClassifier(criterion='gini', max_depth=4, random_state=1)、plot_decision_regions(X_combined, y_combined, clf=clf_tree)。
- 最终将图例、标题等提示性信息添加到图表上,保存图片到本地,并将最终结果显示出来。