Towards Unsupervised Deep Image EnhancementWith Generative Adversarial Network借助生成对抗网络实现无监督的深度图像增强
Abstract
Improving the aesthetic quality of images is challenging and eager for the public. To address this problem, most existing algorithms are based on supervised learning methods to learn an automatic photo enhancer for paired data, which consists of low-quality photos and corresponding expert retouched versions. However, the style and characteristics of photos retouched by experts may not meet the needs or preferences of general users. In this paper, we present an unsupervised image enhancement generative adversarial network (UEGAN), which learns the corresponding image-to-image mapping from a set of images with desired characteristics in an unsupervised manner, rather than learning on a large number of paired images. The proposed model is based on single deep GAN which embeds the modulation and attention mechanisms to capture richer global and local features.Based on the proposed model, we introduce two losses to deal with the unsupervised image enhancement: (1) fidelity loss,whichis defined as L2 regularization in the feature domain of a pretrained VGG network to ensure the content between the enhanced image and the input image is the same, and (2) quality loss that is formulated as a relativistic hinge adversarial loss to endow the input image the desired characteristics. Both quantitative and qualitative results show that the proposed model effectively improves the aesthetic quality of images. Our code is available at: https://github.com/eezkni/UEGAN.
Abstract
对于公众而言,提高图像的美学质量是充满挑战和渴望的。为了解决这个问题,大多数现有算法都基于监督学习方法来学习用于配对数据的自动照片增强器,该照片增强器由低质量的照片和相应的专家修饰版本组成。但是,专家修饰的照片的样式和特征可能无法满足一般用户的需求或偏好。在本文中,我们提出了一种无监督的图像增强生成对抗网络(UEGAN),该网络以无监督的方式从一组具有所需特征的图像中学习相应的图像到图像的映射,而不是学习大量的成对图像.所提出的模型基于单个深层GAN,它嵌入了调制和注意力机制以捕获更丰富的全局和局部特征。在所提出的模型的基础上,我们引入了两种损失来应对无监督图像增强:(1)保真度损失,其定义为在预训练的VGG网络的特征域中进行L2 正则化,以确保增强图像和输入图像之间的内容相同,以及(2)质量损失,表示为相对论铰链对抗性损失赋予输入图像所需的特性。定性和定量结果均表明该模型有效地提高了图像的美学质量。我们的代码位于:https://github.com/eezkni/UEGAN。
I. INTRODUCTION
With the rapid development of mobile Internet, smart electronic devices, and social networks, it is becoming Manuscript received March 16, 2020; revised August 6, 2020; accepted September 1, 2020. Date of publication September 22, 2020; date of currentversion September 29, 2020. This work was supported in part by the Natural Science Foundation of China under Grant 61772344 and Grant 61672443,in part by the Hong Kong Research Grants Council (RGC) General Research Funds under Grant 9042816 (CityU 11209819) and Grant 9042957 (CityU 11203220), in part by the Hong Kong Research Grants Council (RGC) Early Career Scheme under Grant 9048122 (CityU 21211018), and in part by theKey Project of Science and Technology Innovation 2030 supported by the Ministry of Science and Technology of China under Grant 2018AAA0101301.The associate editor coordinating the review of this manuscript and approving it for publication was Dr. Nikolaos Mitianoudis.(Corresponding authors:Shiqi Wang; Sam Kwong.) Zhangkai Ni, Wenhan Yang, and Shiqi Wang are with the Departmentof Computer Science, City University of Hong Kong, Hong Kong (e-mail:[email protected]; [email protected]; [email protected]).Lin Ma is with the Meituan-Dianping Group, Beijing 100102, China(e-mail: [email protected]).Sam Kwong is with the Department of Computer Science, City University of Hong Kong, Hong Kong, and also with the City University of Hong Kong, Shenzhen Research Institute, Shenzhen 518057, China (email:[email protected]).This article has supplementary downloadable material available at http://ieeexplore.ieee.org, provided by the authors.Digital Object Identifier 10.1109/TIP.2020.3023615. more and more popular to record and upload the wonderful lives of people through social media and online sharing communities. However, due to the high cost of highquality hardware devices and the lack of professional photo graphy skills, the aesthetic quality of photos taken by the general public is often unsatisfactory. Professional image editing is expensive, and it is hard to provide such services in an auto-mated manner as aesthetic feelings and preferences are usually a personal issue. Therefore, the automatic image enhancement techniques providing the user-oriented image beautification are preferred.
I. INTRODUCTION
随着移动互联网,智能电子设备和社交网络的飞速发展,它已成为2020年3月16日收到的《手稿》;修订于2020年8月6日;接受日期为2020年9月1日。发布日期为2020年9月22日;日期为2020年9月29日。这项工作部分得到中国自然科学基金会的资助,资助金为61772344和61672443,部分得到香港研究资助局(RGC)普通研究基金的资助,资助金为9042816(CityU 11209819)拨款9042957(CityU 11203220),部分由香港研究资助局(RGC)早期职业计划资助9048122(CityU 21211018),部分由科学部支持的2030年科技创新重点项目授予2018AAA0101301的中国技术。协调该稿件的审查并批准出版的副编辑是Nikolaos Mitianoudis博士(通讯作者:王世奇;;三Sam)。倪张凯,杨文汉和王诗琪在香港城市大学计算机科学系工作(e-mail:[email protected]; [email protected]; [email protected] )。林琳(Lin Ma)在美团点评集团(Meituan-Dianping Group),北京100102(电子邮件:[email protected])。三w(Sam Kwong)在香港城市大学计算机科学系,香港和也与香港城市大学深圳研究所联系,深圳518057(email:[email protected])。本文提供了可下载的补充材料,网址为http://ieeexplore.ieee.org,由作者提供。 。数字对象标识符10.1109 / TIP.2020.3023615 通过社交媒体和在线共享社区越来越受欢迎地记录和上传人们的精彩生活。然而,由于高质量硬件设备的高成本以及缺乏专业的摄影技术,普通公众拍摄的照片的美学质量常常不能令人满意。专业的图像编辑非常昂贵,并且很难以自动方式提供此类服务,因为审美和喜好通常是个人问题。因此,优选的是提供面向用户的图像美化的自动图像增强技术。
Compared with high-quality images, low-quality images usually suffer from multiple degradations in visual quality,such as poor colors, low contrast, and intensive noises et al. Therefore, the image enhancement process needs to address this degradation with a series of enhancement operations,such as contrast enhancement,color correction, and details adjustment et al. The earliest conventional image enhancement approaches mainly focused on contrast enhancement of low-quality image. The most common histogram adjustment transfers the luminance histogram of a low quality image to a given distribution (may be provided by other reference images) to stretch the contrast of the low-quality image. According to the transformation scope, this kind of method can be further classified into two categories:global histogram equalization (GHE) and local histogram equalization (LHE). The former uses a single his-togram transformation function to adjust all pixels of the entire image. It may lead to improper enhancement results in some local regions, such as under-exposure, over exposure,color distortion,et al. To address this issue, the LHE derives the content adaptive transform functions based on the statistical information in local region and applies these transforms locally. However, the LHE is comput ationally complex and not always powerful because the extracted transformation depends on the dominating information in the local region. Therefore,they are also easy to generate visually unsatisfactory texture details, dull or over-saturated color .
与高质量图像相比,劣质图像通常会遭受视觉质量的多次降级,例如色彩差,对比度低以及强烈的噪点等。因此,图像增强过程需要通过一系列增强操作来解决这种退化,例如对比度增强,色彩校正和细节调整等。最早的传统图像增强方法主要集中在低质量图像的对比度增强上。最常见的直方图调整将低质量图像的亮度直方图转移到给定的分布(可能由其他参考图像提供)以拉伸低质量图像的对比度。根据转换范围,这种方法可以进一步分为两类:全局直方图均衡(GHE)和局部直方图均衡(LHE)。前者使用单个直方图变换功能来调整整个图像的所有像素。这可能会导致某些局部区域的增强效果不当,例如曝光不足,曝光过度,色彩失真等。为了解决这个问题,LHE基于局部区域中的统计信息来推导内容自适应变换函数,并在本地应用这些变换。但是,LHE在计算上很复杂,而且并不总是那么强大,因为提取的变换取决于局部区域中的主要信息。因此,它们也容易产生视觉上不令人满意的纹理细节,暗淡或过饱和的颜色。
For the past few years, deep convolutional neural net-works (CNN) have made significant progress in low-level vision tasks. In order to improve the modeling capacity and adaptivity, deep learning based models are built to introduce the excellent expressive power of deep networks to facilitate image enhancement with the knowledgeof big data. Ignatov et al. designed an end-to-end deep learning network that improves photos from mobile devices to the quality of digital single-lens reflex (DSLR) photos Ren et al. present a hybrid loss to optimize the frame work from three aspects (i.e.,color, texture, and content) to produce more visually pleasing results. Inspired by bilateral grid processing, Gharbiet al. made real-time image enhancement possible, which dynamically generates the image transformation based on local and global information. To deal with low-light image enhancement, Wang et al. established a large-scale under-exposed image dataset and learned an image-to-illumination mapping based on the Retinex model to enhance extremely low-light images.
在过去的几年中,深度卷积神经网络(CNN)在低级视觉任务中取得了重大进展。为了提高建模能力和适应性,构建了基于深度学习的模型,以引入深度网络的出色表达能力,从而借助大数据知识促进自动图像增强。伊格纳托夫等。设计了一个端到端的深度学习网络,该网络可以将移动设备中的照片改进为数字单镜头反射(DSLR)照片的质量。提出了一种混合损失,从三个方面(即颜色,纹理和内容)优化了框架,以产生视觉上更令人愉悦的结果。受双边网格处理的启发,Gharbiet等人。使实时图像增强成为可能,它可以根据本地和全局信息动态生成图像转换。为了应对弱光图像增强,Wang等人。我们建立了一个大规模的曝光不足的图像数据集,并学习了基于Retinex模型的图像到照明的映射,以增强超弱光图像。
However, these methods follow the route of fully supervised learning relying on large-scale datasets with paired low/high-quality images. First, paired data is usually expensive, and sometimes it takes a lot of effort and resources to build the dataset by professional photographers. Second, the judgment of image quality is usually closely related to the personality,aesthetics, taste, and experience of a person. “There are a thousand Hamlets in a thousand people’s eyes.” In otherwords, everyone has his/her different attitude towards thequality of the photography. To demonstrate this, a typical low-quality photo in MIT-Adobe FiveK Dataset and itscorresponding five high-qualityversions retouched by five different experts in photo beautification, are shown in Fig. 1,respectively. It can be observed that the images processed by one expert are very different from the image retouched by another expert. Consequently, it is impractical to create alarge-scale dataset with paired low and high-quality images to meets the preference of everyone. On the contrary, a more feasible way is to express the personal preferences of a user by providing a set of image collections that he/she loves. Therefore, an urgent demand is needed to build an enhancement model to learn the enhancement mapping from the low-quality dataset to a high-quality one even without the specific paired images. In this way, we can get rid of the burden of creating one-to-one paired data and rely only on the target dataset with the desired characteristics preferred by someone.
但是,这些方法遵循完全监督学习的方法,该方法依赖于具有配对的低/高质量图像的大规模数据集。首先,成对的数据通常很昂贵,有时由专业摄影师建立数据集需要花费大量的精力和资源。其次,对图像质量的判断通常与一个人的性格,审美,品味和经验密切相关。 “在一千个人眼中有一千个哈姆雷特。”换句话说,每个人对摄影质量都有不同的态度。为了证明这一点,图1分别显示了MIT-Adobe FiveK数据集中的一张典型的低质量照片,以及由五位不同的照片美化专家润饰的相应的五个高质量版本。可以看出,一个专家处理的图像与另一位专家修饰的图像有很大的不同。因此,用成对的低质量和高质量图像创建大型数据集以满足每个人的偏好是不切实际的。相反,一种更可行的方式是通过提供他/她喜欢的一组图像集来表达用户的个人喜好。因此,迫切需要建立一种增强模型,以学习从低质量数据集到高质量图像的增强映射,即使没有特定的配对图像也是如此。通过这种方式,我们可以摆脱创建一对一配对数据的负担,而仅依靠具有某人期望的所需特征的目标数据集。
Benefit from the development of generative adversariallearning and reinforcement learning (RL), some works make attempts to handle the image enhancementtasks only with the help of unpaired data. The milestone work of transferring image style between unpaired data is CycleGAN. It employs two generators and two discriminators and uses cycle consistency loss to achieve visually impressive results. Chenet al. proposes to constructa bi-directional GAN with three improvements to transferlow-quality images into corresponding high-quality ones, and the experimental results show that this model is significantly better than CycleGAN. Hu et al design the first RL-based framework to train an effective photo post-processing model. Jiang et al carry out the first study on the task of low-light enhancement with an unsupervised framework. The method applies a self regularized attention generator and dual discriminators to guide the generator globally and locally.
受益于生成式对抗学习和强化学习(RL)的发展,一些作品仅在未配对数据的帮助下尝试处理图像增强任务。在未配对的数据之间传输图像样式的里程碑式工作是CycleGAN。它使用两个生成器和两个鉴别器,并使用循环一致性损失来获得视觉上令人印象深刻的结果.Chenet al建议用三种改进构建双向GaN,将质量图像转换为相应的高质量图像,实验结果表明,该模型明显优于CycleGAN。HU等设计了第一个基于RL的框架,用于培训有效的照片后处理模型。江等人开展了一项关于低轻增强与无监督框架的任务的一项研究。该方法采用自正规化的注意力发生器和双鉴别器来引导发生器全球和本地。
Rather than utilizing a cyclic generative adversarial network (GAN) to learn bidirectional mappings between the low-quality photos and high-quality ones, we build a unidirectional GAN to address the image aesthetic quality enhancement task, called the unsupervised image enhancement GAN(UEGAN). spired by the properties as mentioned above, our network consists of a joint global and local generator and a multi-scale discriminator with effective constraints. 1) The generator consists of an encoder and decoder with a global attention module and a modulation module embedded, which adjusts the features at different scales locally and globally.The multi-scale discriminator also inspects the results at different levels of granularity and guides the generator to produce better results to obtain global consistency and finer details. 2) To keep the content invariance, a fidelity loss is introduced to regularize the consistency between the input content and resulting content. 3) The global features extracted from the entire image reveal high-level information such as lighting conditions and color distributions. To capture these properties, the global attention module is designed to adjust pixels according to the information of a local neighborhood to meet both local adaptivity and global consistency. 4) For preventing over-enhancement, an identity loss is introduced to constrain the consistency between the enhanced result of the input high-quality image and the input one. This benefits controlling the enhancement procedure to be more quality-free and thus prevents over-enhancement. The main contributions of this work are summarized as follows:
而不是利用循环生成的对抗网络(GaN)来学习低质量照片和高质量的双向映射,而是建立一个单向GAN 来解决图像美学质量增强任务,称为无监督的图像增强GaN(Uegan) 。由上述属性的需求,我们的网络包括一个联合全局和本地发电机和具有有效限制的多尺度鉴别器。1)生成器由具有全局注意模块和嵌入的调制模块的编码器和解码器组成,该调制模块嵌入,其在本地和全球范围内调整不同尺度的特征。多尺度鉴别器还检查了不同级别的粒度的结果,并指导发电机以产生更好的结果,以获得全球一致性和更精细的细节。2)为了保持内容不变性,引入保真损失以规范输入内容与结果内容之间的一致性。 3)从整个图像中提取的全局特征显示了诸如照明条件和颜色分布之类的高级信息。4)为了防止过度增强,引入的身份损失来限制输入高质量图像和输入的增强结果之间的一致性。这种益处控制增强过程更具质量,从而防止增强。这项工作的主要贡献概括如下:
We design a single GAN framework that gets rid of the needs of paired training data for image aesthetic quality enhancement. To the best of our knowledge, this is the first trial to employ a unidirectional GAN framework to apply unsupervised learning to enhance the aesthetic quality of images (instead of low-light image enhancement).
We propose a global attention module and a modulation module to construct the joint global and local generator to capture global features and adaptively adjust the local features. Together with the proposed multi-scale discriminator to inspect the quality of the generated results at different scales, well-enhanced results in perception and aesthetics are produced with both global consistency and finer details.
We propose to jointly use quality loss,fidelity loss,and identity loss to train our model to make it towards extracting quality-free features and controlling the enhancement procedure to be more robust to the quality change. Thus, our method can obtain more reasonable results and prevent over-enhancement. Extensive experimental results on various datasets demonstrate the superiority of the proposed model quantificationally and qualitatively.
我们设计了一个GAN框架,该框架摆脱了配对训练数据对图像美学质量增强的需求。据我们所知,这是首次采用单向GAN框架进行无监督学习以增强图像的美学质量(而不是弱光图像增强)的试验。
我们提出了一个全球关注模块和一个调制模块,以构造联合的全局和局部生成器,以捕获全局特征并自适应地调整局部特征。与提议的多尺度鉴别器一起使用,以在不同尺度上检查生成结果的质量,在感知和美学方面都得到了增强的结果,同时具有全局一致性和更精细的细节。
我们建议共同使用损失,保真性损失和身份损失,以培养我们的模型,使其成为提取无质量的特征,并控制增强程序更加强大地改变。因此,我们的方法可以获得更合理的结果并防止过度增强。各种数据集上的广泛实验结果证明了所提出的模型的优越性,其定量和定性。
The remaining of this paper is organized as follows.In Section II, the related work is succinctly described.In Section III, the proposed unsupervised image aesthetic quality enhancement model is presented in detail. In Section IV,extensive experimental results of the proposed are reported.In Section V, the ablation studies and analysis are presented.Finally, Section VI draws the conclusion.
本文的剩余部分组织如下。在第二节中,相关工作简洁地描述。第三部分,详细介绍了所提出的无监督的图像美学质量增强模型。在第四节中,提出的广泛实验结果报告了。在第五节中,介绍了消融研究和分析。最后,VI部分得出结论。

Fig. 1. An illustration of different expert-retouched versions of a low-qualityphoto in MIT-Adobe FiveK dataset [11]. (a) is the low-quality photo and (b) to (f) are different high-quality counterparts retouched by different experts. Theobvious perceptual differences exist among different high-quality versions.
图1. MIT-Adobe FiveK数据集中[11]的低质量照片的不同专家修饰版本的图示。 (a)是劣质照片,(b)至(f)是由不同专家修饰的不同高质量对应物。不同的高质量版本之间存在明显的感知差异。
II. RELATEDWORK
A. Traditional Image Enhancement
Extensive research has been conducted over the past few decades to improve the quality of photos. Most existing conventional image enhancement algorithms aim to stretch contrast and improve sharpness. The following three types of approaches are the most representative: histogram adjustment, unsharp masking, and Retinex based approaches. These approaches are succinctly described as follows.
- Histogram Adjustment:Based on the basic idea of mapping the luminance histogram to a specific distribution, many methods estimate the mapping function based on the statistical information of the entire image, while the details usually tend to be over-enhanced due to the dominance of some high-frequency information. Instead of estimating a single mapping function for the entire image, other approachesdynamically adjust the histogram based onlocalstatisticalinformation. However, higher computationalcomplexity limits the applicability of this method.
在过去的几十年中,已经进行了广泛的研究来改善照片的质量。大多数现有的常规图像增强算法旨在扩展对比度并提高清晰度。以下三种类型的方法最具代表性:直方图调整,锐化蒙版和基于Retinex的方法。这些方法简述如下。
1)直方图调整:基于将亮度直方图映射到特定分布的基本思想,许多方法基于整个图像的统计信息来估计映射函数,而细节通常由于优势而往往被过度增强一些高频信息。其他方法不是根据整个图像估算单个映射函数,而是根据局部统计信息动态调整直方图。但是,较高的计算复杂度限制了该方法的适用性。 - Unsharp Masking:Unsharp masking (UM) aims to improve image sharpness. The framework of the UM approach can be summarized into the following two phases: First, the input image is decomposed into abase layer and a detail layer by applying a low or high pass filter. Second,all pixels in the detail layer are scaled by a single global weighting factor, or different pixels are adaptively scaled by pixel-wise weighting factors, and then added back to the base layer to obtain an enhanced version. Various works have been proposed to improve the performance of UM from two aspects: 1) design a more reasonable layer decomposition method to decouple different frequency bands; and 2) propose a better estimation algorithm for the adjustment scaling factor.
- Retinex-Based Approaches:Many researchers are working on Retinex-based image enhancement due to clear physical meaning. The basic assumption of the Retinex model is that the observed photo can be decomposed into reflection and illumination . The enhanced image depends on the decomposed layer, i.e., illumination and reflectance layers.Therefore, the Retinex-based model is usually approached as an illumination estimation problem. However, such approaches might generate unnatural results due to the ambi-guity and difficulty in accurately estimating the illumination and reflection map.
2)锐化蒙版:锐化蒙版(UM)旨在提高图像清晰度。 UM方法的框架可以概括为以下两个阶段:首先,通过应用低通或高通滤波器将输入图像分解为基础层和细节层。其次,详细信息层中的所有像素都按单个全局加权因子缩放,或者不同像素按像素加权因子自适应缩放,然后再添加回基础层以获得增强版本。从两个方面提出了许多改善UM性能的工作:1)设计一种更合理的层分解方法来解耦不同的频带; 2)提出了一种针对调整比例因子的更好的估计算法。
3)基于Retinex的方法:由于清晰的物理含义,许多研究人员正在研究基于Retinex的图像增强。 Retinex模型的基本假设是观察到的照片可以分解为反射和照明,增强图像取决于分解层,即照明和反射层,因此,通常将基于Retinex的模型作为照明估计问题。然而,由于模糊性和难以准确估计照明和反射图,这种方法可能会产生不自然的结果。
B. Learning-Based Image Enhancement - Supervised Learning Approaches: Given the explosive growth of CNN, image enhancement models based on learning methods have emerged in large numbers with impressive results. Yanet al took the first step in exploring the use of CNN for photo editing. Ignatov et al build a large-scale DSLR Photo Enhancement Dataset (i.e.,DPED),which consists of 6K photos captured simultaneously by a DSLR camera and three smart phones, respectively. With the paired data, it is easy to learn a mapping function between the low-quality photos captured by smart phones and the high-quality photos captured by the professional DSLR camera. Renet al proposed a hybrid framework to address the low-light enhancement problem by jointly considering the content and structure. However, the promising performance of these models is inseparable from the premise of a large number of pairs of degraded images and corresponding high-quality counter parts.
1)有监督的学习方法:鉴于CNN的爆炸式增长,基于学习方法的图像增强模型已经大量涌现,并取得了令人瞩目的成果。Yanet al迈出了探索使用CNN进行照片编辑的第一步。 Ignatov等人建立了大型DSLR照片增强数据集(DPED),该数据集由分别由DSLR相机和三台智能手机同时捕获的6K照片组成。利用配对的数据,很容易学习智能手机拍摄的低质量照片和专业数码单反相机拍摄的高质量照片之间的映射功能。Renet al提出了一种混合框架,通过共同考虑内容和结构来解决弱光增强问题。但是,这些模型的有前途的性能离不开大量降级图像对和相应的高质量配对部件的前提。
2 ) Unsupervised Learning Approaches: Different from super-resolution, deraining, and denoising, the high-quality images are usually already present, and their low-quality versions can be easily generated by degrading them. In most cases, the image enhancement requires generating high-quality counter parts from low-quality images if need paired low-high-quality during the training phase. High-quality photos are usually obtained by experts using professional photo editing programs (i.e., Adobe Photoshop and Lightroom)to retouch low-quality photos. This is expensive, time-consuming, and the editing style might depend heavily on the expert rather than the real users. In order to get rid of paired training data, a few works attempted to address the image enhancement issue with unsupervised learning. Inspired by the well-known CycleGAN, Chen et al designed a dual GAN model to learn a bi-directional mapping between the source domain and target domain. Specifically, the learned transformation from the source domain to the target domain is first used to generate the high-quality image, and then the inverse mapping from the target domain to the source domain is learned to translate the generated high-quality image back to the source domain. The cycle consistency loss is con-strained to enforce the closeness between the input low-quality photos and those generated by the reverse translation. The cycle consistency works well if both bi-directional generators provide an ideal mapping between the two domains. However,the instability of GAN increases training difficulty and risk to local minima when the cycle consistency is applied.
2 ) 无监督学习方法:与超分辨率,去雨和去噪不同,通常已经存在高质量图像,并且可以通过对其进行降级来轻松生成其低质量版本。在大多数情况下,如果在训练阶段需要成对的低质量图像,则图像增强需要从低质量图像生成高质量对应图像。这是昂贵,费时的,并且编辑风格可能在很大程度上取决于专家而不是实际用户。为了摆脱成对的训练数据,一些工作试图通过无监督学习来解决图像增强问题。受著名的CycleGAN的启发,Chen等人设计了一个双GAN模型来学习源域和目标域之间的双向映射。具体而言,首先使用从源域到目标域的学习转换生成高质量图像,然后学习从目标域到源域的逆映射将生成的高质量图像转换回源图像领域。受著名的CycleGAN的启发,Chen等人设计了一个双GAN模型来学习源域和目标域之间的双向映射。具体来说,首先将学习到的从源域到目标域的转换用于生成高质量图像,然后学习从目标域到源域的逆映射,将生成的高质量图像转换回原始图像源域。循环一致性损耗被配置为强制执行输入低质量照片与反向翻译产生的那些之间的接近。如果双向生成器在两个域之间提供理想的映射,则循环一致性很好。然而,GaN的不稳定性增加了当循环一致性时局部最小值的训练难度和风险。
III. PROPOSED UNSUPERVISED GAN FOR IMAGE ENHANCEMENT
A. Motivations and Objectives
We observe that professional photographer usually follows these instincts when performing image editing:
Combination of global transformation and local adjustment. The content and intrinsic semantic information should be kept the same between the low-quality and retouched versions. The expert might first perform a global transformation based on the overall lighting conditions (e.g., well-exposure or under/over-exposure) and tone (e.g., cool or warm colors) in the scenes. The local corrections then make finer adjustments based on the joint consideration of both global information and local content.
Over-enhancement prevention.The trade-off between fidelity and quality is crucial. Over-enhancement donates the visual effects caused by excessively enhancing the properties of images related to the aesthetic feeling, such as very warm colors, high contrast, and over-exposure,etc. However, this can also make the results to deviate from fidelity and produce unnatural results. That is, a good automatic photo enhancer should be aware of over-enhancement while producing good visual effects.
Base on the observations mentioned above, we are dedicated to learning an image-to-image mapping function F to generate the high-quality counter part Xg of a given low-quality photo Xl, which can be modeled as follows.
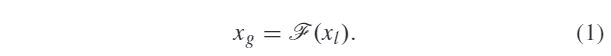
One critical issue in image enhancement tasks is how to define quality as well as high quality. Any user can easily provide a collection of images expressing their personal preferences without explicitly stating the quality he/she loves.Therefore, rather than defining F as various clearly defined rules, it is better to formulate it as a process of transforming low-quality image distribution under the guidance of the desired high-quality image distribution. This promotes us to learn a user-oriented photo enhancer based on unpaired data in an unsupervised manner. Based on this consideration, we make efforts in utilizing the set-level supervision of GAN to achieve our goals through adversarial learning.
III.建议使用未经监督的GAN进行图像增强
我们观察到专业摄影师在进行图像编辑时通常会遵循以下本能:
全局转换与局部调整相结合。在低质量版本和修饰版本之间,内容和固有语义信息应保持相同。专家可能首先根据场景中的整体光照条件(例如,曝光良好或曝光不足/过度)和色调(例如,冷色或暖色)执行全局转换。然后,基于对全局信息和本地内容的共同考虑,本地更正会进行更精细的调整。
过度增强预防:保真度与质量之间的权衡至关重要。过度增强会产生由于过度增强与美感相关的图像特性而引起的视觉效果,例如非常暖和的色彩,高对比度和过度曝光等。但是,这也会使结果偏离保真度并产生不自然的结果。也就是说,一个好的自动照片增强器应该在产生良好视觉效果的同时注意过度增强。
基于上述观察,我们致力于学习图像到图像映射函数F 来生成给定低质量照片Xg的高质量计数器部分Xl,可以将其建模如下:
图像增强任务中的一个关键问题是如何定义质量以及高质量。任何用户都可以轻松提供表达个人喜好的图像集合,而无需明确说明他/她所钟爱的质量,因此与其将F 定义为各种清晰定义的规则,不如将其表述为转化低质量图像的过程更好在期望的高质量图像分布的指导下进行分布。这促使我们以无监督的方式基于未配对的数据学习面向用户的照片增强器。基于这种考虑,我们努力利用GAN的级别监督来通过对抗学习实现我们的目标。
B. Network Architecture
- Joint Global and Local Generator:The generator plays a crucial role in our proposed UEGAN as it directly affects the quality of the final generated photos. The expert might first perform a global transform based on the overall lighting conditions or tone in the scenes. Therefore, the global features act as an image prior to guiding the generation and adjusting the local features. Based on this observation, we first propose a global attention module(GAM) to exploit the global attention of local features. Each channel of feature maps is extracted from the local neighborhood by the convolution layer. The focus of global attention is the ‘holistic’ understanding of each channel. In order to model the global attention of the intermediate features z∈RC×H×W, our proposed method can be summarized as the following three steps as shown in Fig. 3: 1) extracting global statistics information fmpool(·) of each channel via Eqn (2);. 2) digging the inter-channel relationship ρ using the extracted gmean via the multi-layer perceptron fFC(·) in Eqn (3);3) fusing global and localfeatures via Eqn (4).
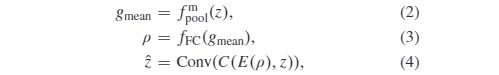
where fmpool(·) means the average pooling operation,fFC(·) is two fully-connected layers, E(·) represents expanding the spatial dimension of ρ to that of z ,C(·) is the concatenation operation, and CCCONC is a convolution layer.
Fig. 2 shows the proposed modulation module(MM) in the joint global and local generator. In particular, we use skip connections between encoder and decoder at different scales locally and globally to prevent the information loss caused by resolution change. Unlike traditional U-Net, the features of the encoder are concatenated to those of the symmetric decoder at each stage (i.e., four stages in our model). Our proposed modulation module learns to generate two branches of features and then merge them to gether with the multiplication operation. In our model, to further reuse the features, the learned modulation layer multiples the features of the first stage of the encoder and those of the penultimate layer by element-wise multiplication. Learning global features and feature modulation can effectively enhance the visual effect of the resulting image. The global features can also guide to penalize some low-quality features that might lead to visual artifacts or poorly reconstructed details. Complex image processing can be approximated by a set of simple local smoothing curves, the proposed joint global and local generator G is more capable than traditional U-Net for learning complex mappings from low-quality images to high-quality ones.
1)全球和本地联合生成器:生成器在我们提议的UEGAN中起着至关重要的作用,因为它直接影响最终生成的照片的质量。专家可能会首先根据整体照明条件或场景中的色调执行全局转换。因此,在指导生成和调整局部特征之前,全局特征将作为图像。基于这种观察,我们首先提出了一个全局注意力模块(GAM)来利用局部特征的全局注意力。卷积层从局部邻域中提取特征图的每个通道。全局关注的焦点是对每个渠道的“全面”理解。为了对中间特征z∈RC×H×W的全局注意力进行建模,我们提出的方法可以概括为以下三个步骤,如图3所示:1)通过Eqn(2);提取每个通道的全局统计信息fmpool(·)。2)通过等式(3)中的多层感知器 fFC(·) 使用提取的gmean来挖掘信道间关系ρ;3)通过等式(4)融合全局和局部特征。
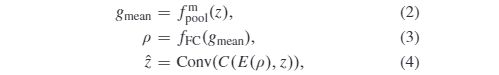
其中 fmpool(·) 表示平均池化操作,*fFC(·)*是两个完全连接的层,E(·)表示将ρ的空间维扩展到 z的空间维,*C(·)*是连接操作,Conv(·) 是卷积层。
图2显示了联合全局和局部生成器中提出的调制模块(MM)。特别是,我们在本地和全局使用不同规模的编码器和解码器之间的跳过连接,以防止由于分辨率变化而导致的信息丢失。与传统的U-Net不同,编码器的功能在每个阶段(即我们模型中的四个阶段)都与对称解码器的特征串联在一起。我们提出的调制模块学习生成特征的两个分支,然后通过乘法运算将它们合并到一起。在我们的模型中,为了进一步重用特征,学习的调制层通过逐元素相乘将编码器第一级的特征和倒数第二层的特征相乘。学习全局特征和特征调制可以有效增强所得图像的视觉效果。全局特征还可以指导对一些低质量的特征进行惩罚,这可能会导致视觉伪像或重建不良的细节。复杂的图像处理可以通过一组简单的局部平滑曲线来近似,所提出的全局和局部联合生成器G比传统的U-Net更具有能力来学习从低质量图像到高质量图像的复杂映射。
2) Multi-Scale Discriminator: In order to distinguish between real high-quality image and generated “pseudo” high-quality image, the discriminator requires a large receptive field to capture the global characteristics. This directly leads to the need for deeper networks or larger convolution kernels.The last layer of the discriminator usually captures the information from a larger region of the image and can guide the generator to produce the image with better global consistency.However, the intermediate layer of the discriminator with a smaller receptive field can force the generator to pay more attention to finer details. Based on this observation, as shown in Fig. 2, we propose a multi-scale discriminator D that uses multi-scale features to guide the generator to produce images with both global consistency and finer details.
2)多尺度鉴别器:为了区分真实的高质量图像和生成的“伪”高质量图像,鉴别器需要较大的接收场才能捕获全局特征。这直接导致需要更深的网络或更大的卷积核。鉴别器的最后一层通常从图像的较大区域捕获信息,并可以指导生成器生成具有更好的全局一致性的图像。但是,鉴别器的中间层具有较小的接收场,可能会迫使生成器更加关注更精细的细节。基于此观察结果,如图2所示,我们提出了一种多尺度鉴别器D,该鉴别器D使用多尺度特征来指导生成器生成具有全局一致性和更精细细节的图像。
C. Loss Function
- Quality Loss:We use quality loss to adapt the distribution of enhanced results to that of high-quality images. The quality loss guides the generator to produce more visually pleasing results. In the previous GAN frameworks, the discriminator aims at distinguishing between real samples and the generated ones. However, we observe that simply applying the discriminator D to separate generated images and realhigh-quality images is not enough to obtain a good generator that transfers low-quality images into high-quality ones. The reason might be lies in that the quality ambiguity between low/high-quality images, some images in the low-quality image set are better than those in the high-quality image set. To address this issue, we also train the discriminator to distinguish between real low-quality images and real high-quality images as shown in Fig. 2.
1)质量损失:我们使用质量损失使增强结果的分布适应于高质量图像的分布。质量损失引导发生器产生视觉上更令人愉悦的结果。在以前的GAN框架中,区分器旨在区分真实样本和生成的样本。但是,我们观察到仅将鉴别符D应用于分离生成的图像和真实高质量的图像并不足以获得获得将低质量的图像转换为高质量的图像的良好生成器。原因可能在于低/高质量图像之间的质量歧义,低质量图像集中的某些图像比高质量图像集中的图像好。为了解决这个问题,我们还训练了鉴别器来区分真实的低质量图像和真实的高质量图像,如图2所示。
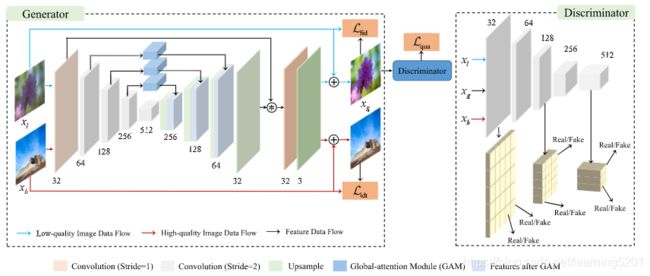
Fig. 2. The framework of the proposed UEGAN for image enhancement. The blue, red, and black lines indicate the low-quality images data flow, high-qualityimages data flow, and features data flow, respectively. The generator only inputs low-quality or high-quality images at a time.
图2.提议的UEGAN的图像增强框架。蓝色,红色和黑色线分别指示低质量图像数据流,高质量图像数据流和特征数据流。生成器一次只输入低质量或高质量图像。

Fig. 3. The structure of the global attention module, where E and C denote the expanding and concatenation operations, respectively.
图3.全局注意模块的结构,其中E和C分别表示扩展和连接操作。
Specifically, our proposed discriminator is based on the recently proposed relativistic discriminator structure, which not only assesses the probability that the real data (i.e.,real high-quality image) is more authentic than the fake data (i.e., generated high-quality image or real low-quality image),but also guides the generator to produce high-quality images more realistic than real high-quality images. In addition,we employ an improved form of the relativistic discriminator, Relativistic average Hinge GAN (RaHingeGAN) as follows:
具体而言,我们提出的鉴别器基于最近提出的相对论鉴别器结构,该结构不仅评估了真实数据(即,真实高质量图像)比伪数据(即,生成的高质量图像或真实的低质量图像),而且还指导生成器生成比真实的高质量图像更真实的高质量图像。此外,我们采用了相对论鉴别符的改进形式,相对论平均Hinge GAN(RaHingeGAN)如下:
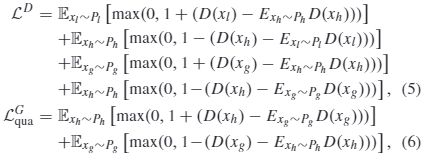
where xl,xh,and xg denote the real low-quality image,real high-quality image, and generated high-quality image,respectively. - Fidelity Loss: Since we train our model for image enhancement in an unsupervised manner, the quality loss itself might not ensure that the generated image has similar content to that of the input low-quality image. The simplest way is to measure the distance between the input and output images in the pixel domain. However, we cannot employ this strategy because the generated high-quality image is typically different from the input low-quality image in the pixel domain due to contrast stretching and color rendering. Therefore, we use fidelity loss to constrain the training of the generator, so as to achieve the purpose of generated high-quality images and inputting low-quality images with similar content. The fidelity loss is defined as the L2 norm between the feature maps of the input low-quality image and those of the generated high-quality images extracted by the pre-trained VGG net-work as follows:
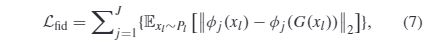
where φj(·) indicates the process of extracting the feature maps obtained by the j layer of the VGG network and J is the total number of layers used. Specifically, the Relu_1_1,Relu_2_1,Relu_3_1,Relu_4_1, and Relu_5_1 layers of VGG-19 network are adopted in this work.
2)保真度损失:由于我们以无人监督的方式训练了用于图像增强的模型,因此质量损失本身可能无法确保所生成的图像具有与输入的低质量图像相似的内容。最简单的方法是测量像素域中输入图像和输出图像之间的距离。但是,由于对比度扩展和色彩渲染,生成的高质量图像通常在像素域中与输入的低质量图像不同,因此我们无法采用此策略。因此,我们利用保真度损失来约束生成器的训练,以达到生成高质量图像和输入内容相似的低质量图像的目的。保真度损失定义为输入的低质量图像的特征图与通过预训练的VGG网络提取的生成的高质量图像的特征图之间的L2范数,如下所示:
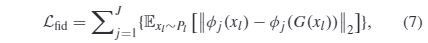
其中,φj(·) 表示提取由VGG网络的j层获得的特征图的过程,而J是使用的层总数。具体而言,在这项工作中采用了VGG-19网络的Relu_1_1,Relu_2_1,Relu_3_1,Relu_4_1和Relu_5_1层。 - Identity Loss:The identity loss is defined as l1 distance between the input high-quality image and the corresponding output of the generator G as follows:
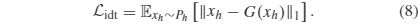
The identity loss is calculated based on high-quality input images. Therefore, if the color distribution and contrast of the input image meet the characteristics of the high-quality image set, the identity loss intends to encourage preservation of the color distributions and contrast between the input and output. It ensures that the generator should make almost no changes to the image in content, contrast, and color during the image enhancement process. As a result, the identity loss makes it possible to simultaneously maintain the content, colorrendering, and contrast ofthe input high-quality image.
3)身份损失:身份损失定义为输入的高质量图像与生成器G的相应输出之间的l1距离,如下所示:
![]()
身份损失是根据高质量的输入图像计算得出的。因此,如果输入图像的颜色分布和对比度满足高质量图像集的特征,则身份损失旨在鼓励保持输入和输出之间的颜色分布和对比度。它确保生成器在图像增强过程中几乎不对图像的内容,对比度和颜色进行任何更改。结果,身份丢失使得可以同时保持输入的高质量图像的内容,显色性和对比度。
3) Total Loss:By jointly considering quality loss,fidelityloss,andidentity loss, our final loss is defined as the weightedsum of these losses which as follows:
![]()
where λqua,λfid,and λidt are weighting parameters to balancethe relative importance of LGqua,Lfid and Lidt
separate :动词: 分离, 分开, 隔开, 分, 隔离, 间, 别, 隔, 割裂, 脱离, 隔绝, 隔断, 拆开, 阻隔, 析, 解, 披, 闲,异 形容词: 另外, 另, 个别的 名词: 抽印本
ambiguity :/ˌambəˈɡyo͞owədē/名词: 双关, 双关语 歧义
relativistic :相对论的
employ :/əmˈploi/ 动词: 采用, 使用, 雇用, 应用, 录用, 聘用, 雇佣, 运用, 采取, 雇, 动用, 施用, 收录, 录
名词: 雇佣, 雇
strategy :/ˈstradəjē/ 名词: 战略, 略, 谋, 筹略
render:/ˈrendər/ 动词: 给予, 粉刷, 呈送, 译, 给以 名词: 交纳
摘要单词:
aesthetic :形容词: 美的, 美学的, 审美的, 艺术的
corresponding :形容词: 相应, 对应的, 通信的
retouched :修饰的
characteristics :特征
preferences :首选项
adversarial :对抗的
desired :想要的
embeds :动词: 嵌, 镶嵌, 镶
the modulation and attention mechanisms:调节和注意机制
fidelity :名词: 忠诚, 忠实, 保真度
defined :定义的
content :名词: 内容, 含量, 满足, 物, 事由, 容度 动词: 满足, 邃 形容词: 怿, 逌, 安, 满意的
is formulated as:制定为
relativistic :相对论的
endow :动词: 赋予, 赋, 牺, 牺牲, 赋与, 输将
quantitative and qualitative:定量和定性
available :形容词: 可得到, 合宜的, 可用的
介绍单词:
Manuscript :名词: 手稿, 稿, 草 形容词: 手写的
revised :修改
Research Grants Council:研究补助金理事会
associate:动词: 关联, 联想, 联合 名词: 联想, 合作者, 合伙人, 合夥人 形容词: 副的
coordinating :协调
supplementary:形容词: 补充, 异
downloadable material:可下载资料
communities:社区
hardware:名词: 硬件, 铁器, 金属制品
the lack of:缺乏
expensive:形容词: 昂贵, 贵, 高价, 高昂, 高, 昂, 悬, 费用浩大, 花钱多, 嶢, 禕
multiple degradations:多次降级
correction:名词: 更正, 改正, 纠正
The earliest conventional:最早的常规
luminance :名词: 亮度
categories:类别
equalization :均等化
improper :形容词: 不当, 不合适, 失当, 不端, 苟且, 偷
under-exposure:曝光不足
distortion:名词: 失真, 畸变, 扭曲
dominating information:主导信息
visually unsatisfactory texture:视觉上不令人满意的纹理
dull or over-saturated color:暗淡或过饱和的颜色
the excellent expressive:优秀的表现力
facilitate :动词: 促进, 便利, 促成, 便, 纾, 济, 使 … 容易, 纾缓
hybrid loss:混合损失
Inspired :启发
dynamically :动态地
bilateral :形容词: 双边, 双方, 双向, 两岸
illumination:名词: 照明, 光照, 照亮
extremely :副词: 非常, 极其, 极, 万分, 很, 异常, 绝顶, 太, 不得了, 甚, 不堪, 殊, 不胜, 绝, 死, 万般, 不亦乐乎, 酷, 郅, 要命, 穷, 痛, 綦, 至, 万, 极了
the route of:的路线
effort :名词: 功夫, 工夫, 成就, 气力
professional photographers:专业摄影师
judgment :名词: 判断, 判决, 判定, 裁判, 论断, 意见, 报应, 裁, 意思, 眼力, 报, 定案, 该判决书
personality,aesthetics, taste, and experience:个性,审美,品味和经验
To demonstrate this:为了证明这一点
retouched :修饰的
Consequently:副词: 所以, 于是
On the contrary:副词: 反之, 反而, 反
feasible :形容词: 可行, 切实, 可能的
urgent demand :紧急需求
get rid of the burden:摆脱负担
bidirectional :/ˌbīdəˈrekSH(ə)n(ə)l/ 双向
aesthetic:/esˈTHedik/ 形容词: 美的, 美学的, 审美的, 艺术的
spired by the properties as mentioned above:由上述属性的需求
constraints:名词: 约束, 强制, 局促, 拘禁
adjusts :动词: 调整, 调节, 调, 调剂, 拨, 调弄
finer details:更好的细节
the content invariance:内容不变性
a fidelity loss:保真损失
neighborhood :/ˈnābərˌho͝od/ 名词: 附近, 邻里, 邻近, 街道, 街坊, 里弄, 里, 方圆
preventing :预防
an identity loss:一个身份损失
prevents :防止
contributions :贡献
summarized :总结
gets rid of:摆脱
To the best of our knowledge:据我们所知
trial :/ˈtrī(ə)l/ 名词: 审讯, 考验, 诉讼 形容词: 试验的, 作试验用的
construct:构造
perception :/pərˈsepSH(ə)n/ 名词: 知觉, 感觉
propose to :建议
quality loss,fidelity loss,and identity loss:质量损失,保真性损失和身份损失
robust :/rōˈbəst/ 形容词: 健壮, 健全, 强壮, 壮, 壮实, 刚健, 仡
various :/ˈverēəs/ 形容词: 各个, 诸, 杂, 异, 列
demonstrate :/ˈdemənˌstrāt/ 动词: 演示, 表明, 示范, 显示, 论证, 示威, 表演, 指明, 示例
superiority :/səˌpirēˈôrədē/ 名词: 优势, 优越
quantificationally and qualitatively:量化和定性
remaining :/rəˈmāniNG/ 其余的
reinforcement :名词: 加强, 救兵, 后援
milestone :名词: 里程碑
employs 雇用
consistency :名词: 一致性, 一致, 浓度, 论理, 合理性, 一贯性
visually :视觉上
carry out :动词: 进行, 执行, 贯彻, 实施, 履行, 实行, 落实, 推行, 执, 售, 履, 践, 施, 演
RELATEDWORK单词
Extensive :形容词: 广泛, 粗放, 广, 大规模, 广大, 广博, 宽广, 泛, 辽阔, 恢, 恢恢, 博, 溥, 摦
has been conducted over:已经进行了
stretch contrast and improve sharpness:拉伸对比度并提高清晰度
representative:/ˌreprəˈzen(t)ədiv/ 名词: 代表, 众议员, 议员 形容词: 典型
histogram adjustment, unsharp masking, and Retinex based approaches:直方图调整,锐化蒙版和基于Retinex的方法。
luminance:/ˈlo͞omənəns/ 名词: 亮度
sharpness:锐度 清晰度
summarized into:总结成
is decomposed:分解了
assumption :/əˈsəm§SH(ə)n/ 名词: 臆测, 采取, 臆说
illumination :/iˌlo͞oməˈnāSH(ə)n/名词: 照明, 光照, 照亮
reflection :/rəˈflekSH(ə)n/ 名词: 反射, 影子, 影, 鉴
explosive :/ikˈsplōsiv/ 名词: 爆炸物 形容词: 爆破的, 爆炸的, 激烈的, 热烈的
have emerged in:已经出现在
simultaneously :/ˌsīməlˈtānēəslē/ 副词: 同时, 并, 齐, 载, 蒹, 一边 … 一边
hybrid:/ˈhīˌbrid/ 名词: 混血
jointly considering:共同考虑
promising :/ˈpräməsiNG/形容词: 有为, 光明, 前途有望的, 有希望
inseparable :/inˈsep(ə)rəb(ə)l/ 形容词: 形影不离, 紧密, 不可分离
premise :/ˈpreməs/ 名词: 前提 动词: 提论, 预述
corresponding :/ˌkôrəˈspändiNG/ 形容词: 相应, 对应的, 通信的
present:/ˈprez(ə)nt/ 形容词: 当前, 现在, 现, 当今, 今, 这次, 斯 动词: 介绍, 呈, 表达, 上, 呈递, 给, 赠, 送, 馈, 递交, 送礼, 献, 呈送, 捐赠, 瞄准, 捐献, 齎, 摆供 名词: 当代, 礼物, 礼品, 瞄准, 仪
retouch :修饰
time-consuming:耗时
attempted to:尝试做
minima :最小
the instability of:不稳定
第III部分单词
instincts :本能
retouched :修饰的
intrinsic:固有
overall:形容词: 总体, 整体, 总, 全面, 全盘, 通盘 副词: 总之, 老是 名词: 罩衫, 外罩, 罩袍
exposure :/ikˈspōZHər/ 名词: 曝光, 曝露, 暴光, 拆穿
prevention:/prəˈven(t)SH(ə)n/ 名词: 预防, 阻止, 警告, 抵制
crucial:/ˈkro͞oSHəl/ 形容词: 关键, 紧要, 临界
properties :名词: 属性, 性能, 财产, 特性, 产权, 性质, 资产, 财物, 产业, 财产权, 产, 所有权, 财, 业, 家当, 所有物
deviate :动词: 偏离, 背离, 离开
be aware of :动词: 知道, 意识, 知, 审, 谂, 意会
observation:/ˌäbzərˈvāSH(ə)n/ 名词: 意见, 注目, 望诊
mention:/ˈmen(t)SH(ə)n/ 动词: 提到, 提, 提起, 谈起, 议论, 隐射, 挂齿, 齿及 名词: 发言, 意, 挂齿
proposed :建议的
neighborhood:/ˈnābərˌho͝od/ 名词: 附近, 邻里, 邻近, 街道, 街坊, 里弄, 里, 方圆
holistic:整体的
branches :分行,分支
multiplication:/ˌməltəpləˈkāSH(ə)n/ 名词: 乘法, 繁殖
penalize:/ˈpēn(ə)lˌīz/ 动词: 惩罚, 处罚, 惩处, 罚, 罚款, 惩, 罚金
approximated :动词: 近似
curves:曲线
capable:/ˈkāpəb(ə)l/ 形容词: 能, 能力, 能干, 得力, 有才干, 成, 行, 有本领, 有资格
distinguish :/dəˈstiNGɡwiSH/ 动词: 区分, 区别, 鉴别, 辨别, 识别, 辨, 分别, 辨明, 判明, 判別
pseudo /ˈso͞odō/ 形容词: 冒充的名词: 欺人者
requires :要求
receptive :/rəˈseptiv/ 形容词: 感受的, 感受性敏锐的
consistency:/kənˈsistənsē/ 名词: 一致性, 一致, 浓度, 论理, 合理性, 一贯性
intermediate :/ˌin(t)ərˈmēdēət/ 形容词: 中间, 中级 动词: 调解
smaller :较小的