MySQL数据库表的增删查改CRUD
CRUD:create,retrieve,update,delete
一、增加
语法:
insert into table_name[(column[,column...])] values (value [,value...]);举例:创建一个学生表,并且向表中输入数据
create table student(
id int primary key,
name varchar(32),
gender varchar(2),
score varchar(32),
email varchar(32) unique key
); ![]()
使用添加语句需要注意的细节:
1.插入的数据应与字段的数据类型相同。比如,将‘abc'插入到id列就不行
![]()
2.数据的大小应在规定的范围内,例如:不能将一个长度为80的字符串插入到长度为40的列中。

3.在values中列出的数据位置必须与被加入的列位置相对应。(下面是id与name写反了)
![]()
4.字符和日期类型应该包含在单引号中。
![]()
5.插入空值,不指定或指定为 null
insert into table student values (null);6.批量插入, insert into table values(),(),()
![]()
7.隐含列插入,给表中的所有字段添加数据,可以不写前面的字段名称(如果没有给出字段名称,values中必须给出所有字段值)
insert into student values(4,'D','男',79,'139.com');8.指定列插入,只给表的某几个字段赋值,则需要制定字段名
insert into student(id,name)values(5,'Jack');9.在数据插入的时候,假设主键对应的值已经存在:插入失败!
mysql>insert into student (id,name)values(4,'boy');
ERROR 1062 (23000): Duplicate entry '4' for key 'PRIMARY'当主键存在冲突的时候(duplicate key),可以选择性的进行处理:
(1)跟新操作:
insert into 表名(字段列表) values(值列表) on duplicate key update 字段=新值;(2)替换操作:
replace into 表名(字段列表) values (值列表);二.删除
语法:
delete from tbl_name [where condition];(1)删除id为1的数据

(2)拓展:复制表数据
步骤一:复制表结构
create table 表名 like 要复制的表的名字; 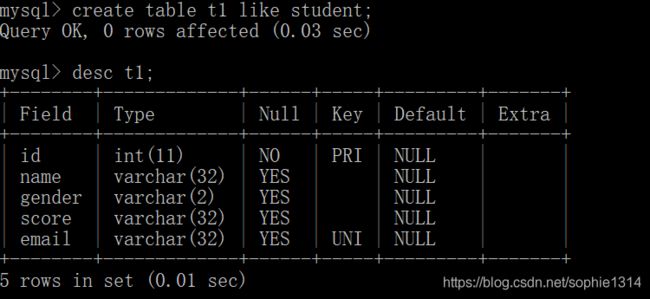
步骤二:复制数据
insert into 表名 select *from 要复制的表名; 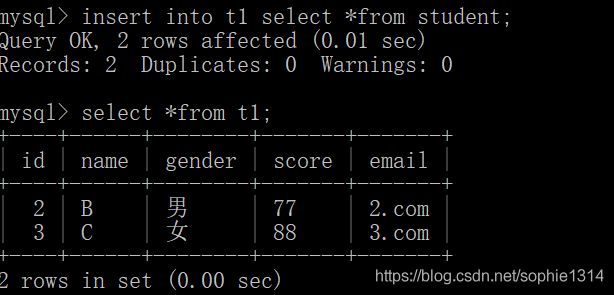
(3)删除表中所有记录
delete:删除整个表的数据,但是表的结构还在
delete from 表名: 
truncate:清空表中数据,这个指令也把整个表的记录删除

delete和truncate两种删除整表的区别 :
1.delete使用逐条删除,truncate是整体删除,效果一样,truncate速度快
2.delete返回被删除的记录数,而truncate返回0
3.清空表数据,建议使用truncate
4.TRUNCATE TABLE 删除表中的所有行,但表结构及其列、约束、索引等保持不变。新行标识所用的计数值重置为该列的种子。如果想保留标识计数值,请改用 DELETE。
delete使用细节:
1.配合where子句,可以灵活的删除满足条件的记录
2.delete语句不能删除某一列的值(可以用update置null)
3.使用delete语句仅删除记录,不删除表本身(drop table)
三.更新
语法:
update tbl_name set col_name1=expr1, [, col_name2=expr2 ...] [where conditon] [limit n]
update使用细节:
(1)update 语法可以用新值更新原有表中的各列值
(2)set子句指示要修改哪些列和要给予哪些值
(3)where子句指定应更新哪些行。如果没有where子句,则更新所有行
(4)where子句后面指定limit,更新限制数量的符合条件的行
四.查询
语法:
select [distinct] *| {column1,column2,...} from tbl_name [where condition];1.可以指定查询哪些列,比如:id,name等;*表示查询所有列;distinct表示如果结果中有重复行,则删掉重复行
2.在select语句中可以使用表达式对查询的列进行运算
select id+10 from student;3.在select语句中可以使用 as 起别名
select score+10 as new_score from student;4.在select中使用where子句,进行查询过滤,在where子句中经常使用的运算符:
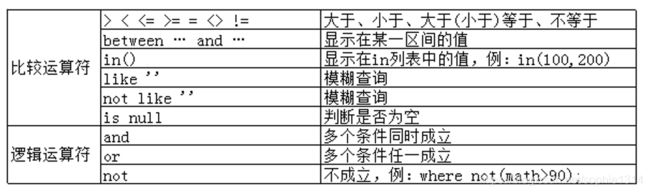
5.order by子句
在select语句中使用order by子句排序查询结果
select column1,column2,... from table order by column asc|desc,...; 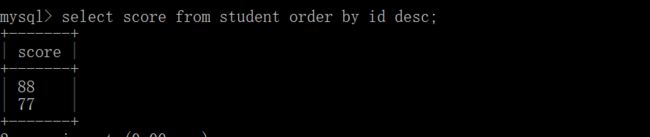
(1)order by 指定排序的列,排序的列可以使表中的列名,也可以是select语句后指定的别名
(2)asc升序(默认),desc降序
(3)order by 子句应该位于select语句的结尾
6.limit分页
语法:
select *from 表名 limit 起始位置 记录条数;
select *from 表名 limit 记录条数 offset 起始位置;
举例:

7.聚合函数
(1)count(列名)返回某一列,行的总数
select count(*)|count(列名) from tbl_name where condition;注意:count(*)会统计一共的记录数,count(列名)会排除为null的情况
(2)sum:sum函数返回满足where条件的行的和
select sum(列名) {,sum(列名)...} from tbl_name [where condition];注意:sum仅对数值起作用,否则结果无意义。
(3)avg:agv函数返回满足where条件的一列的平均值
select avg(列名) [,avg(列名),...] from tbl_name [where condition]; (4)max\min:max/min函数返回满足where条件的一列的大/小值
select max(列名) from tbl_name [where condition];8.group by 子句
在select中使用group by 子句可以对指定列进行分组查询
准备工作,创建一个雇员信息表(来自oracle 9i的经典测试表) EMP员工表 DEPT部门表 SALGRADE工资等级表
如何显示每个部门的平均工资和高工资:
select deptno,avg(sal),max(sal) from EMP group by deptno;
having和group by配合使用,对group by结果进行过滤
select avg(sal) as myavg from EMP group by deptno having myavg<2000;