NumPy常用方法总结
本文将从以下几个方面,简单介绍NumPy库的基本用法:
-
NumPy简介
-
NumPy常用方法
1. NumPy简介
NumPy是Python数值计算中最为重要的基础包,能对矩阵中的所有数据进行快速的矩阵运算,且无需编写循环,因此可以在很大程度上减少计算时间成本。另外,因为NumPy的算法库是用C语言写的,所以NumPy数组使用的内存量也小于其它Python内荐序列。
2. NumPy常用方法总览
2.1. NumPy数组的创建
数组的创建方法有很多种,可以通过列表来创建数组,也可以创建指定大小和指定元素的数组,还可以通过读取文件中的数据创建。以下介绍几种常用的生成数组的方法。
(1)通过列表来创建数组,主要使用的是np.array()方法,创建过程如下:
import numpy as np # 标准的NumPy导入方式
vector_1 = np.array([9,7,5,3,1])
vector_2 = np.array([[1,2,3,4,5],[6,7,8,9,10]])每个数组都有具有形状大小,用来表征数组每一维度的数量。使用shape方法可以查看数组的形状,需要注意的是当数组是1维的时候,shape方法返回的值为(5,),其表示vector_1是一个有5个元素的一维数组。而如果一个数组返回的维度值为(5,1)则表示该数组是一个二维数组。每个数组都有一个dtype属性,用来描述数组的数据类型。

使用size方法可以查看数组中元素的数量。

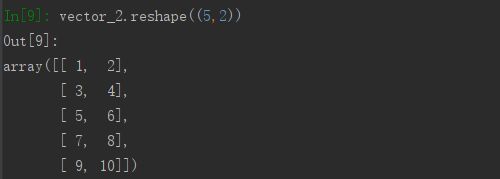
如需改变数组的形状,则可以使用reshape()方法,其接收的参数是一个元组(m,n)。该方法可以把现有数组变成(m,n)维,以vector_2为例,将一个(2,5)的矩阵变成一个(5,2)的矩阵:
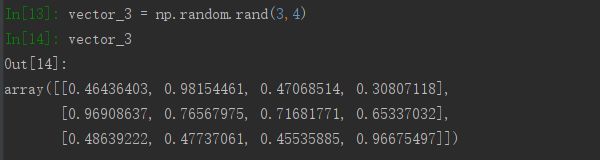
(2)使用np.random.rand(d0, d1, …, dn),产生[0,1)之间均匀分布的随机浮点数,其中d0,d1....表示传入的数组形状。
(3)np.arange(a,b,step)方法,可以根据指定的范围[a,b)以及设定的步长step生成一个一维数组,数据默认类型为float型。

(4)np.zeros((a,b)),可以创建一个指定大小元素全为 0 的数组。np.zeros常用的参数及说明:传入的参数为一个元组,返回指定维度的0矩阵,当传入参数为整形时,返回一个一维数组。
与np.zeros()类似的方法还有:np.empty()创建一个空矩阵、np.ones()创建一个元素全为1的矩阵、np.full()根据指定大小和数据类型生成指定数值的矩阵。另外,np.zeros_like()可以帮助我们创建一个与给定矩阵大小相同的0矩阵,类似的方法还有:np.empty_like()、np.ones_like()、np.full_like()其用法和np.zeros_like()是一样的,这里不再赘述。

(5)np.eye(N,M=None, k=0),用于生成一个N*N的特征矩阵(对角线的位置都是1,其余位置都是0),如果K为正整数,则表示右上方第k条对角线全“1”其余全“0”,k为负整数则在左下方第k条对角线全“1”其余全“0”。

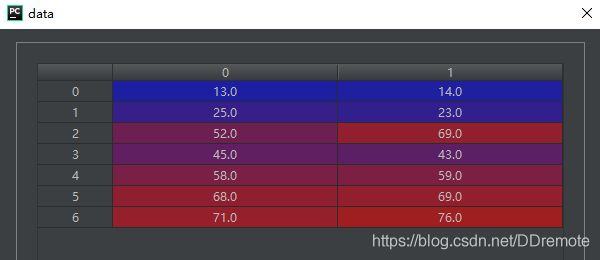
(6)如果需要批量处理大量的数据,通过手动输入肯定是不可行的。numpy模块中自带了一个loadtxt()方法,可以直接读取文本文件中的数据,但是文件中每一行必须含有相同的数据。np.loadtxt()和np.genfromtxt()函数都可以读取txt格式的文件,两者之间的区别是:genfromtxt能够考虑缺失的数据,虽然函数loadtxt不能考虑缺失值,但是更快、更简单。
# This is a test file
# A total of 7 rows of data
12,13,14
21,25,23
35,52,69
41,45,43
57,58,59
64,68,69
75,71,76
以loadtxt()函数读取一个test.txt文件为例(文件内容如上图所示),介绍该方法的使用,读取过程如以下代码清单所示:
import numpy as np
# loadtxt(fname, comments='#', delimiter=None, skiprows=0, usecols=None, unpack=False)
# fname 是指如要读取的文件路径
# comment 是指如果行的开头为#就会跳过该行
# delimiter 是指以什么分隔符来分割数据,本例中应选择 “,”
# skiprows 是指跳过前n行
# usecols 是指使用选择的几列
# unpack 是指会把每一列当成一个向量输出Ture or False
data = np.loadtxt(r"F:\test.txt", comments='#', delimiter=',', usecols=(1, 2))
# data = np.loadtxt(r"F:\test.txt", skiprows=2, delimiter=',', usecols=(1, 2)) 两种效果一样
# np.savetxt(r"F:\test.txt",data) # 将数据data保存到test.txt文件中,与loadtxt()操作相反加载数据为矩阵。
2.2. NumPy算术运算
矩阵的算术运算比较简单,带有标量的算术操作(加、减、乘、除,平方等)会把计算参数传递给数组的每一个元素。例如,将前面随机产生的[0,1)之间均匀分布的随机浮点数数组vector_3对应位置上的元素相乘,操作如下:

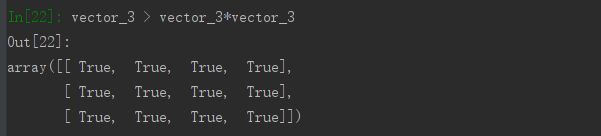
除了对矩阵中的每个对应元素进行加减乘除之外,还可以比较相同矩阵同一位置上的元素值之间的大小:
2.3. NumPy的点乘和叉乘,及数据统计
(1)矩阵的点乘np.dot()_
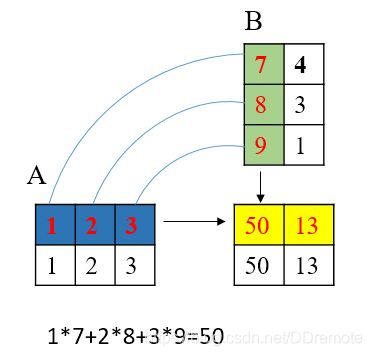
要实现矩阵的点乘只需要用到np.dot(a,b)方法,计算矩阵的点乘时,a矩阵的列要与b矩阵的行相等。

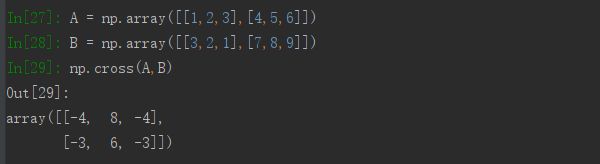
(2)矩阵的叉乘np.cross()
与点乘不同,矩阵的叉乘要求两个矩阵必须维数相等,即矩阵A、矩阵B及叉乘的结果维度都是相同的。
(3)统计矩阵中的最大值、最小值、求和、平均值、标准差和方差
np.max()、np.min()、np.sum()、np.mean()、np.std()、np.var()等函数可以接收一个可选参数,对于二维矩阵axis=0或1。其中axis=0表示对每一行操作,axis=1表示对每一列操作。以统计一个(3,2)大小的矩阵的最大值、最小值、求和、平均值、标准差和方差为例,介绍这些方法的使用,代码如下:
import numpy as np
vector_4 = np.arange(5,17,2).reshape(3,2) # 生成一个(3,2)大小的矩阵
np.max(vector_4) # 统计矩阵中的最大值
np.max(vector_4,axis=0) # 统计矩阵每一行的最大值
np.max(vector_4,axis=1) # 统计矩阵每一列的最大值
np.min(vector_4,axis=0) # 统计矩阵每一行的最小值
np.sum(vector_4) # 统计矩阵中所有元素的和
np.sum(vector_4,axis=0) # 计算矩阵每一行元素的和
np.mean(vector_4) # 计算矩阵中所有元素的平均值
np.std(vector_4) # 计算矩阵的标准差
np.std(vector_4,axis=0) # 计算矩阵每一行的标准差
np.var(vector_4) # 计算矩阵的方差部分统计结果输出:

2.4. NumPy的索引
(1)矩阵的索引
如果我们想对矩阵中的某些元素进行操作,这时候就需要用到矩阵的索引。如电影院的座位号一样,矩阵中的每一个元素都有一个编号,我们可以很轻松地通过行列号来定位矩阵中的每一个元素。

以二维矩阵为例,如果想取出矩阵中的5,以下两种方式都可以实现。

如果想取出矩阵的第二行或者第二列,先选择需要的某一行或某一列,再使用":"操作符就可以实现。单独一个":"进行索引,那么表示选择整个轴上的数组。

以上是矩阵索引的基本操作 ,矩阵索引还有很多种方式。现在假如我想找出矩阵中大于5 的元素,那么可以使用一个简单的索引就可以实现。

要是我现在想交换矩阵的第一行和第二行那么该怎么实现呢?很简单,也只需要使用索引就可以实现。

(2)矩阵的拼接
上面的矩阵索引都是对一个矩阵进行的操作,如果要想将两个矩阵拼接成一个矩阵,显然用索引的方法是不行的,这时候就需要使用矩阵的拼接方法了。np.concatenate()方法可以沿一个轴向连接矩阵。

对于矩阵的拼接这里只介绍这一个方法,像np.vstack()、np.hstack()等都可以实现矩阵的拼接,这里不详细介绍。
(3)np.where函数
最后我想介绍的是np.where()函数。np.where()函数的用法有点类似C语言中的三目运算符:?即x>y?0:1,或者与以下语句功能类似:
if condition:
a
else:
b如果条件为真,输出a,否则输出b。假如我现在想把矩阵中小于10的元素全替换为0,那么我可以这样做:

输出矩阵中大于10的数:

俗话说,授授之以鱼不如授之以渔。要想更加全面系统地了解NumPy,还可以在自己的IDE->Python Console下使用help()函数来查看自己想要查询的函数的使用方法。以numpy为例,先import numpy,输入help(numpy)后回车,即可查看numpy库下的所有方法的使用说明。