ResNet网络复现
ResNet
本篇实现的是基于2015年和2016年何凯明推出的ResNet,比较下效果。
学习流程
- 阅读ResNet论文原文
- 搜集学习资源:视频讲解-博客资源
- 熟悉ResNet网络结构
- 代码复现,清楚网络结构中层与层之间的操作
ResNet论文
原论文:2015-Deep Residual Learning for Image Recognition
2016-Identity Mappings in Deep Residual Networks
论文翻译:ResNet论文翻译——中文版
学习资源
博客资源
- 本人写的一篇关于ResNet残差结构的深入理解ResNet之残差结构的理解
- 卷积层后面跟batch normalization层时为什么不要偏置b
- 深度残差网络RESNET
- 主干网络系列(2) -ResNet V2:深度残差网络中的恒等映射
- ResNet 残差、退化等细节解读
- ResNet详解——通俗易懂版
视频资源
- ResNet网络结构,BN以及迁移学习详解
- 使用pytorch搭建ResNet并基于迁移学习训练
- 使用tensorflow搭建ResNet网络并基于迁移学习的方法进行训练
ResNet网络结构
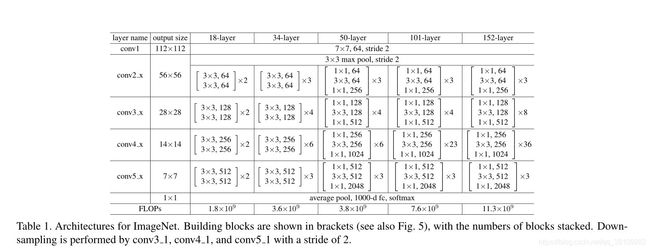
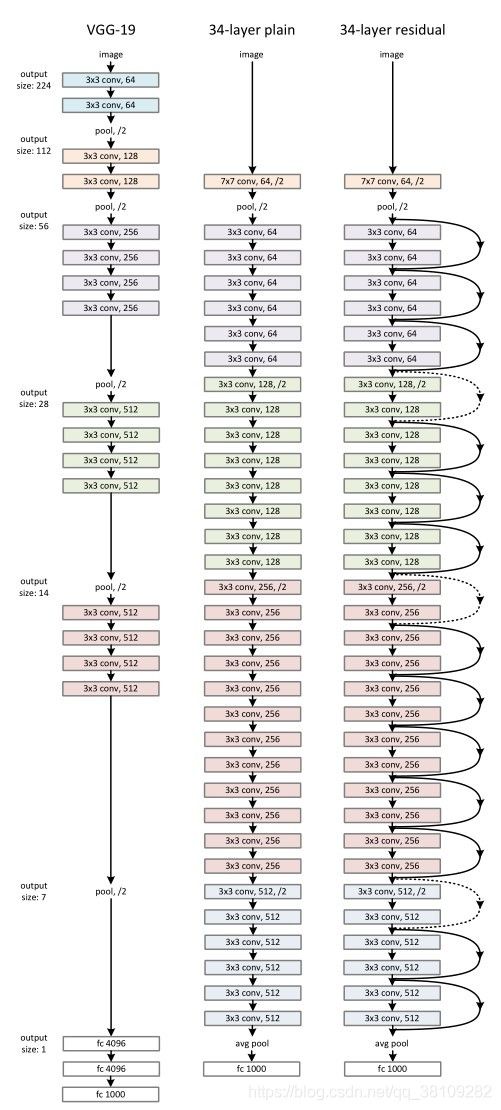
代码复现
设备:RTX3090
网络结构:ResNet50
训练方式:正常训练
数据集:3700多张5类别的花朵数据集
训练集:验证集=10:1
batch_size:64
epochs:60
分别采用了何凯明在2015年和2016年提出新残差结构,并加以比较两者的效果:
文件目录
代码链接:WZMIAOMIAO-deep-learning-for-image-processing
代码说明:
- 以上链接的ResNet是基于2015ResNet的代码实现,且实现的全连接部分并没有严格按照论文的代码进行,我在以上代码基础上将全连接层更改为论文的结构,并且实现了2016和2015两种模型,并加以比较,其中绘制训练图的代码也已在train_GPU.py文件给出,改进的代码贴出:
- 链接代码基于官方的迁移学习实现
model.py:
from tensorflow.keras import layers, Model, Sequential
# resnet-18,34的结构
class BasicBlock(layers.Layer):
expansion = 1
# downsample 下采样函数
def __init__(self, out_channel, strides=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__(**kwargs)
self.conv1 = layers.Conv2D(out_channel, kernel_size=3, strides=strides,
padding="SAME", use_bias=False)
self.bn1 = layers.BatchNormalization(momentum=0.9, epsilon=1e-5)
# -----------------------------------------
self.conv2 = layers.Conv2D(out_channel, kernel_size=3, strides=1,
padding="SAME", use_bias=False)
self.bn2 = layers.BatchNormalization(momentum=0.9, epsilon=1e-5)
# -----------------------------------------
self.downsample = downsample
self.relu = layers.ReLU()
self.add = layers.Add()
def call(self, inputs, training=False):
identity = inputs
if self.downsample is not None:
identity = self.downsample(inputs)
x = self.conv1(inputs)
x = self.bn1(x, training=training)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x, training=training)
x = self.add([identity, x])
x = self.relu(x)
return x
# 瓶颈类,瓶颈两头大中间小,大小区分在深度,输入深度大(一头大),传入之后被压缩(中间小),输出被扩展(另一头大)
class Bottleneck(layers.Layer):
expansion = 4
# init好层的操作,这里均基于resnet-50,101,152的结构设计,这三层结构一致,只是这三层的组合数量不同
def __init__(self, out_channel, strides=1, downsample=None, **kwargs):
super(Bottleneck, self).__init__(**kwargs)
self.conv1 = layers.Conv2D(out_channel, kernel_size=1, use_bias=False, name="conv1") # 默认步长1
self.bn1 = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name="conv1/BatchNorm")
# -----------------------------------------
self.conv2 = layers.Conv2D(out_channel, kernel_size=3, use_bias=False,
strides=strides, padding="SAME", name="conv2") # 从网络结构看,步长为2
self.bn2 = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name="conv2/BatchNorm")
# -----------------------------------------
self.conv3 = layers.Conv2D(out_channel * self.expansion, kernel_size=1, use_bias=False, name="conv3") # 默认步长1
self.bn3 = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name="conv3/BatchNorm")
# -----------------------------------------
self.downsample = downsample
self.add = layers.Add()
self.relu = layers.ReLU()
# 调用层的操作顺序
# 2015ResNet
# def call(self, inputs, training=False):
#
# # 如果该层需要快捷连接,即需要下采样
# identity = inputs
# if self.downsample is not None:
# identity = self.downsample(inputs)
#
# x = self.conv1(inputs)
# x = self.bn1(x, training=training)
# x = self.relu(x)
#
# x = self.conv2(x)
# x = self.bn2(x, training=training)
# x = self.relu(x)
#
# x = self.conv3(x)
# x = self.bn3(x, training=training)
#
# x = self.add([x, identity])
# x = self.relu(x)
#
# return x
# 2016ResNet
def call(self, inputs, training=False):
# 如果该层需要快捷连接,即需要下采样
identity = inputs
if self.downsample is not None:
identity = self.downsample(inputs)
x = self.bn1(inputs, training=training)
x = self.relu(x)
x = self.conv1(x)
x = self.bn2(x, training=training)
x = self.relu(x)
x = self.conv2(x)
x = self.bn3(x, training=training)
x = self.conv3(x)
x = self.add([x, identity])
x = self.relu(x)
return x
# block对应basic和bottle类,resnet18/34对应basic,resnet50/101/152对应bottle
# in_channel表示上一层卷积的输出深度,channel表示这一个block的第一层卷积的卷积深度,block_num对应_resnet函数blocks_num列表的元素,表示第几个block
# name的命名作迁移学习识别层位置用,strides是每个block的stride
def _make_layer(block, in_channel, channel, block_num, name, strides=1):
downsample = None
# strides!=1表示输入会被降维,即输,或者输入in_channel和该层卷积最终输出深度channel*block.expansion不相等,则需要快捷连接
if strides != 1 or in_channel != channel * block.expansion:
downsample = Sequential([
layers.Conv2D(channel * block.expansion, kernel_size=1, strides=strides,
use_bias=False, name="conv1"),
layers.BatchNormalization(momentum=0.9, epsilon=1.001e-5, name="BatchNorm")
], name="shortcut")
layers_list = []
# 虚线残差结构,block的第一层卷积,名为unit_1
layers_list.append(block(channel, downsample=downsample, strides=strides, name="unit_1"))
# 实线残差结构
for index in range(1, block_num):
layers_list.append(block(channel, name="unit_" + str(index + 1)))
return Sequential(layers_list, name=name)
# 构造resnet网络框架
# block表示构建的是basic还是bottle类的残差结构,block_num列表表示残差结构的结构的每一层的数量
# include_top表示全连接层和max_pool是否需要定义,作迁移学习用
def _resnet(block, blocks_num, im_width=224, im_height=224, num_classes=1000, include_top=True):
# tensorflow中的tensor通道排序是NHWC
# (None, 224, 224, 3)
input_image = layers.Input(shape=(im_height, im_width, 3), dtype="float32")
# 第一层卷积conv1
x = layers.Conv2D(filters=64, kernel_size=7, strides=2,
padding="SAME", use_bias=False, name="conv1")(input_image)
# 第一层BN
x = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name="conv1/BatchNorm")(x)
# 第一层relu
x = layers.ReLU()(x)
# 第二层输入前最大池化下采样,高宽减半
x = layers.MaxPool2D(pool_size=3, strides=2, padding="SAME")(x)
# x.shape对应上一层输出特征矩阵的shpae,值为[batch,height,weight,channel]
# 这里4个_make_layer对应论文网络结构中的conv2_x,conv3_x,conv4_x,conv5_x
x = _make_layer(block, x.shape[-1], 64, blocks_num[0], name="block1")(x)
x = _make_layer(block, x.shape[-1], 128, blocks_num[1], strides=2, name="block2")(x)
x = _make_layer(block, x.shape[-1], 256, blocks_num[2], strides=2, name="block3")(x)
x = _make_layer(block, x.shape[-1], 512, blocks_num[3], strides=2, name="block4")(x)
# 顶层网络构建,即全连接层和max_pool层
if include_top:
x = layers.GlobalAvgPool2D()(x) # pool + flatten
x = layers.Dense(num_classes, name="logits")(x)
predict = layers.Softmax()(x)
else:
predict = x
model = Model(inputs=input_image, outputs=predict)
return model
def resnet34(im_width=224, im_height=224, num_classes=1000, include_top=True):
return _resnet(BasicBlock, [3, 4, 6, 3], im_width, im_height, num_classes, include_top)
def resnet50(im_width=224, im_height=224, num_classes=1000, include_top=True):
return _resnet(Bottleneck, [3, 4, 6, 3], im_width, im_height, num_classes, include_top)
def resnet101(im_width=224, im_height=224, num_classes=1000, include_top=True):
return _resnet(Bottleneck, [3, 4, 23, 3], im_width, im_height, num_classes, include_top)
train_GPU.py:
import matplotlib.pyplot as plt
from model import resnet50
import tensorflow as tf
import json
import os
import time
import glob
import random
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
def main():
gpus = tf.config.experimental.list_physical_devices("GPU")
if gpus:
try:
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
except RuntimeError as e:
print(e)
exit(-1)
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
train_dir = os.path.join(image_path, "train")
validation_dir = os.path.join(image_path, "val")
assert os.path.exists(train_dir), "cannot find {}".format(train_dir)
assert os.path.exists(validation_dir), "cannot find {}".format(validation_dir)
# create direction for saving weights
if not os.path.exists("save_weights"):
os.makedirs("save_weights")
im_height = 224
im_width = 224
_R_MEAN = 123.68
_G_MEAN = 116.78
_B_MEAN = 103.94
batch_size = 64
epochs = 60
# class dict
data_class = [cla for cla in os.listdir(train_dir) if os.path.isdir(os.path.join(train_dir, cla))]
class_num = len(data_class)
class_dict = dict((value, index) for index, value in enumerate(data_class))
# reverse value and key of dict
inverse_dict = dict((val, key) for key, val in class_dict.items())
# write dict into json file
json_str = json.dumps(inverse_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
# load train images list
random.seed(0)
train_image_list = glob.glob(train_dir + "/*/*.jpg")
random.shuffle(train_image_list)
train_num = len(train_image_list)
assert train_num > 0, "cannot find any .jpg file in {}".format(train_dir)
train_label_list = [class_dict[path.split(os.path.sep)[-2]] for path in train_image_list]
# load validation images list
val_image_list = glob.glob(validation_dir + "/*/*.jpg")
random.shuffle(val_image_list)
val_num = len(val_image_list)
assert val_num > 0, "cannot find any .jpg file in {}".format(validation_dir)
val_label_list = [class_dict[path.split(os.path.sep)[-2]] for path in val_image_list]
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
def process_train_img(img_path, label):
label = tf.one_hot(label, depth=class_num)
image = tf.io.read_file(img_path)
image = tf.image.decode_jpeg(image)
# image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [im_height, im_width])
image = tf.image.random_flip_left_right(image)
# image = (image - 0.5) / 0.5
image = image - [_R_MEAN, _G_MEAN, _B_MEAN]
return image, label
def process_val_img(img_path, label):
label = tf.one_hot(label, depth=class_num)
image = tf.io.read_file(img_path)
image = tf.image.decode_jpeg(image)
# image = tf.image.convert_image_dtype(image, tf.float32)
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [im_height, im_width])
# image = (image - 0.5) / 0.5
image = image - [_R_MEAN, _G_MEAN, _B_MEAN]
return image, label
AUTOTUNE = tf.data.experimental.AUTOTUNE
# load train dataset
train_dataset = tf.data.Dataset.from_tensor_slices((train_image_list, train_label_list))
train_dataset = train_dataset.shuffle(buffer_size=train_num) \
.map(process_train_img, num_parallel_calls=AUTOTUNE) \
.repeat().batch(batch_size).prefetch(AUTOTUNE)
# load train dataset
val_dataset = tf.data.Dataset.from_tensor_slices((val_image_list, val_label_list))
val_dataset = val_dataset.map(process_val_img, num_parallel_calls=tf.data.experimental.AUTOTUNE) \
.repeat().batch(batch_size)
# 实例化模型
feature = resnet50(num_classes=5, include_top=True)
# pre_weights_path = '../tf_resnet50_weights/pretrain_weights.ckpt'
# assert len(glob.glob(pre_weights_path + "*")), "cannot find {}".format(pre_weights_path)
# feature.load_weights(pre_weights_path)
# feature.trainable = False
#
# model = tf.keras.Sequential([feature,
# tf.keras.layers.GlobalAvgPool2D(),
# tf.keras.layers.Dropout(rate=0.5),
# tf.keras.layers.Dense(1024, activation="relu"),
# tf.keras.layers.Dropout(rate=0.5),
# tf.keras.layers.Dense(5),
# tf.keras.layers.Softmax()])
model = feature
model.summary()
# using keras low level api for training
loss_object = tf.keras.losses.CategoricalCrossentropy(from_logits=False)
optimizer = tf.keras.optimizers.Adam(learning_rate=0.0005)
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.CategoricalAccuracy(name='train_accuracy')
test_loss = tf.keras.metrics.Mean(name='test_loss')
test_accuracy = tf.keras.metrics.CategoricalAccuracy(name='test_accuracy')
@tf.function
def train_step(images, labels):
with tf.GradientTape() as tape:
output = model(images, training=True)
loss = loss_object(labels, output)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_accuracy(labels, output)
@tf.function
def test_step(images, labels):
output = model(images, training=False)
t_loss = loss_object(labels, output)
test_loss(t_loss)
test_accuracy(labels, output)
best_test_loss = float('inf')
train_step_num = train_num // batch_size
val_step_num = val_num // batch_size
train_time = 0
train_loss_print = []
val_loss_print = []
train_accuracy_print = []
val_accuracy_print = []
for epoch in range(1, epochs + 1):
train_loss.reset_states() # clear history info
train_accuracy.reset_states() # clear history info
test_loss.reset_states() # clear history info
test_accuracy.reset_states() # clear history info
t1 = time.perf_counter()
for index, (images, labels) in enumerate(train_dataset):
train_step(images, labels)
if index + 1 == train_step_num:
break
print(time.perf_counter() - t1, "second")
train_time += time.perf_counter() - t1
for index, (images, labels) in enumerate(val_dataset):
test_step(images, labels)
if index + 1 == val_step_num:
break
template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print(template.format(epoch,
train_loss.result(),
train_accuracy.result() * 100,
test_loss.result(),
test_accuracy.result() * 100))
# 输出汇总
train_loss_print.append(train_loss.result())
val_loss_print.append(test_loss.result())
train_accuracy_print.append(train_accuracy.result() * 100)
val_accuracy_print.append(test_accuracy.result() * 100)
if test_loss.result() < best_test_loss:
model.save_weights("./2016save_weights/myResNet.ckpt", save_format='tf')
print("训练花费:", train_time, "second")
# 绘制损失图
plt.figure()
plt.plot(range(epochs), train_loss_print, label='train_loss')
plt.plot(range(epochs), val_loss_print, label='val_loss')
plt.legend()
plt.xlabel('epochs')
plt.ylabel('loss')
# 绘制精确率图
plt.figure()
plt.plot(range(epochs), train_accuracy_print, label='train_accuracy')
plt.plot(range(epochs), val_accuracy_print, label='val_accuracy')
plt.legend()
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.show()
if __name__ == '__main__':
main()
2015残差结构
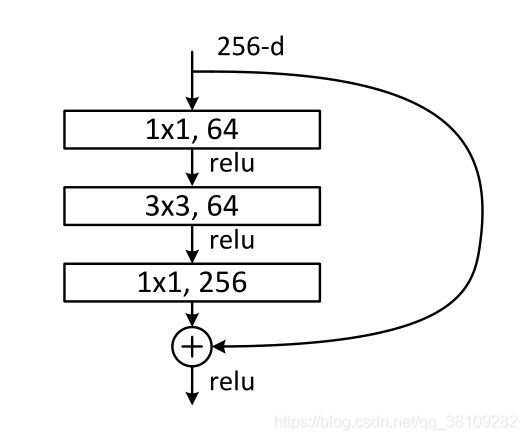
2015年使用的残差块,这里每个卷积层的后面接着一个BN层,图中没画出来,前两层卷积层后面经过BN层之后还跟着ReLU层。
2016残差结构
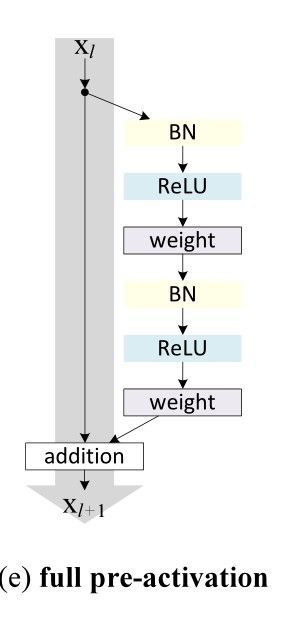
论文的想法是,新残差结构每个卷积层前都跟着一个BN层和一个ReLU层。
我自己的实验由于疏忽了最后一层卷积层,残差块的前两个卷积层都跟着BN层和ReLU层,最后一层卷积层前面只跟着一个BN层(少加了一个ReLU层,不过应该影响不大,因为ReLU的作用只是平滑整个训练过程(懒得跑多一次实验了))
这个结构在何凯明的实验中得到了最好的结果:

实验总结
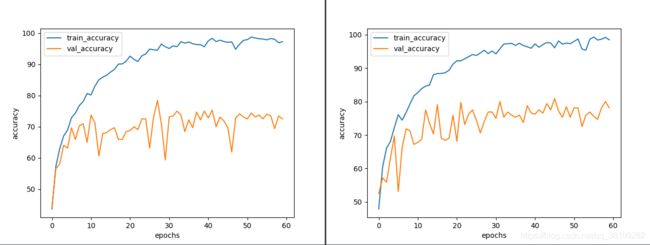
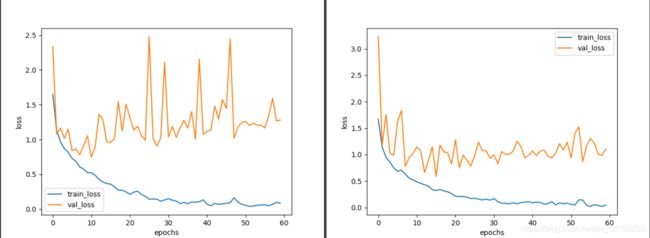
上面两张图中,左边是2015ResNet,右边是2016ResNet
总体来看,3700张的花分类数据集对这个网络来说太小了,使训练严重过拟合,但我们关注的不是过拟合,关注的是结构差异带来的增益,2016年的残差结构确实比2015的残差结构有了明显的提升,验证集准确率提升,浮动也轻微,验证集的loss浮动非常小,2015年的验证集loss非常大,同时整体的验证集loss比较低。
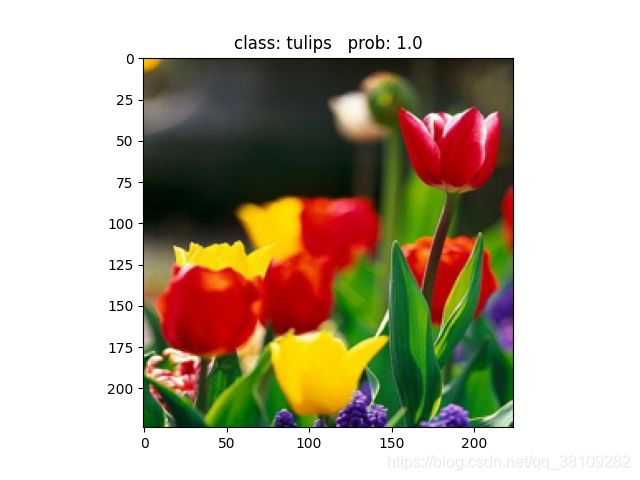
两个网络对网上找的一张郁金香的预测效果都一样,概率100%识别郁金香。
我也使用了官方的迁移学习效果,验证集的准确率能达到90以上,如果我本地使用大量的数据集,我想也是可以达到相同的效果。